协同过滤笔记
笔记
记录一下学习工作中遇到的一些知识,以防遗忘,不清楚的可以回来再看。
一些专有名词
embedding: 隐向量 非常重要 无处不在
召回: 粗略计算要返回结果,例如从100W商品中取比较可能的100个
负采样
负采样(Negative Sampling)是一种用于训练词嵌入模型的技术。在自然语言处理中,词嵌入模型被用于将词语表示为连续向量空间中的向量,以便于计算机处理和理解自然语言。
在传统的Skip-gram模型中,为了预测目标词语的上下文,需要对训练数据集中的每个词语生成一对(目标词语,上下文词语)。然而,这种全局计算上下文的方法会导致训练过程非常耗时,尤其是在大规模数据集上。
负采样通过减少训练样本的数量来加速训练过程。它的基本思想是对于每个目标词语和其上下文词语,只选取部分负面样本进行训练,而不是使用全部的上下文词语。具体来说,对于每个训练样本,我们会随机选取一些与目标词语不相关的词语作为负面样本。这些负面样本不仅能够加速训练过程,还能够帮助模型学习到更好的词嵌入表示。
负采样的过程通常涉及两个参数:采样数量和采样分布。采样数量决定了每个正样本应该选择多少个负面样本进行训练,而采样分布用于选择负面样本。常见的采样分布方法是根据词语的频率进行采样,即频率越高的词语被选中为负面样本的概率越大,这样可以更好地处理高频词语的训练。
通过负采样,可以显著减少训练时间,同时保持较好的词嵌入质量。这使得负采样成为了训练大规模词嵌入模型的常用技术。
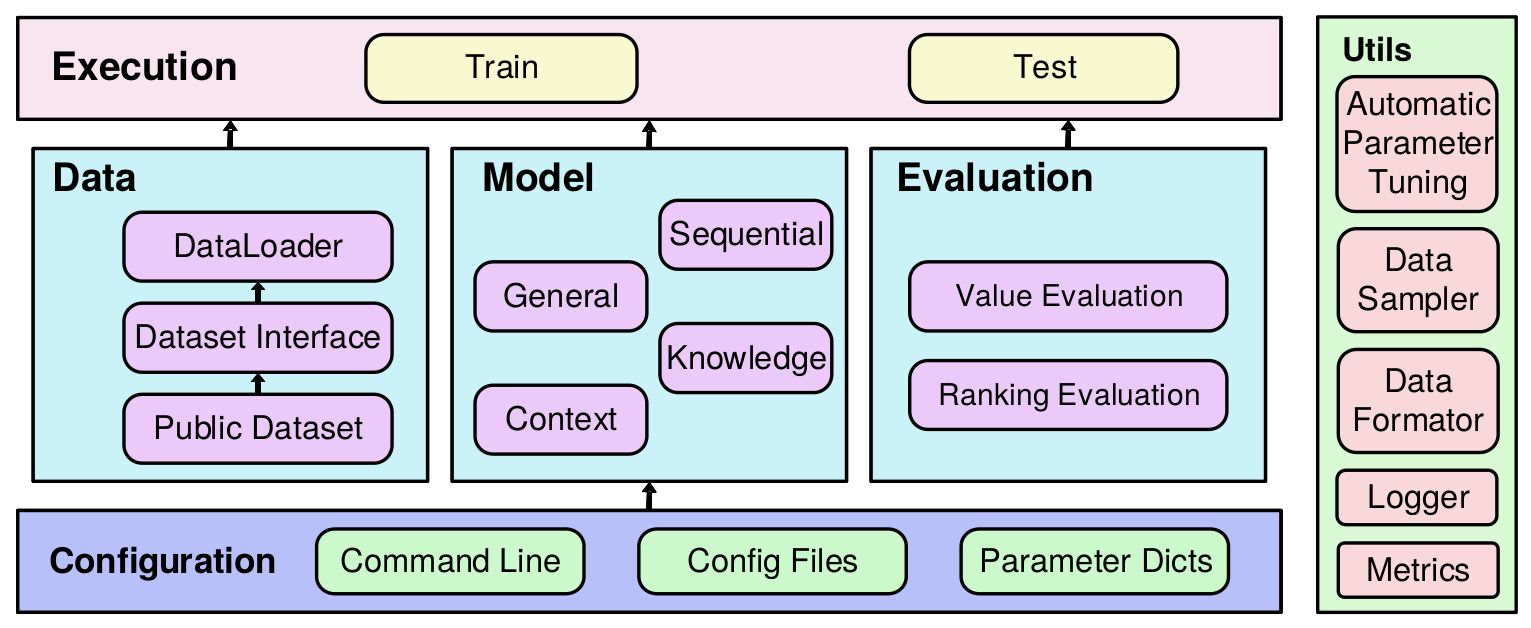
RecBole推荐平台总体架构
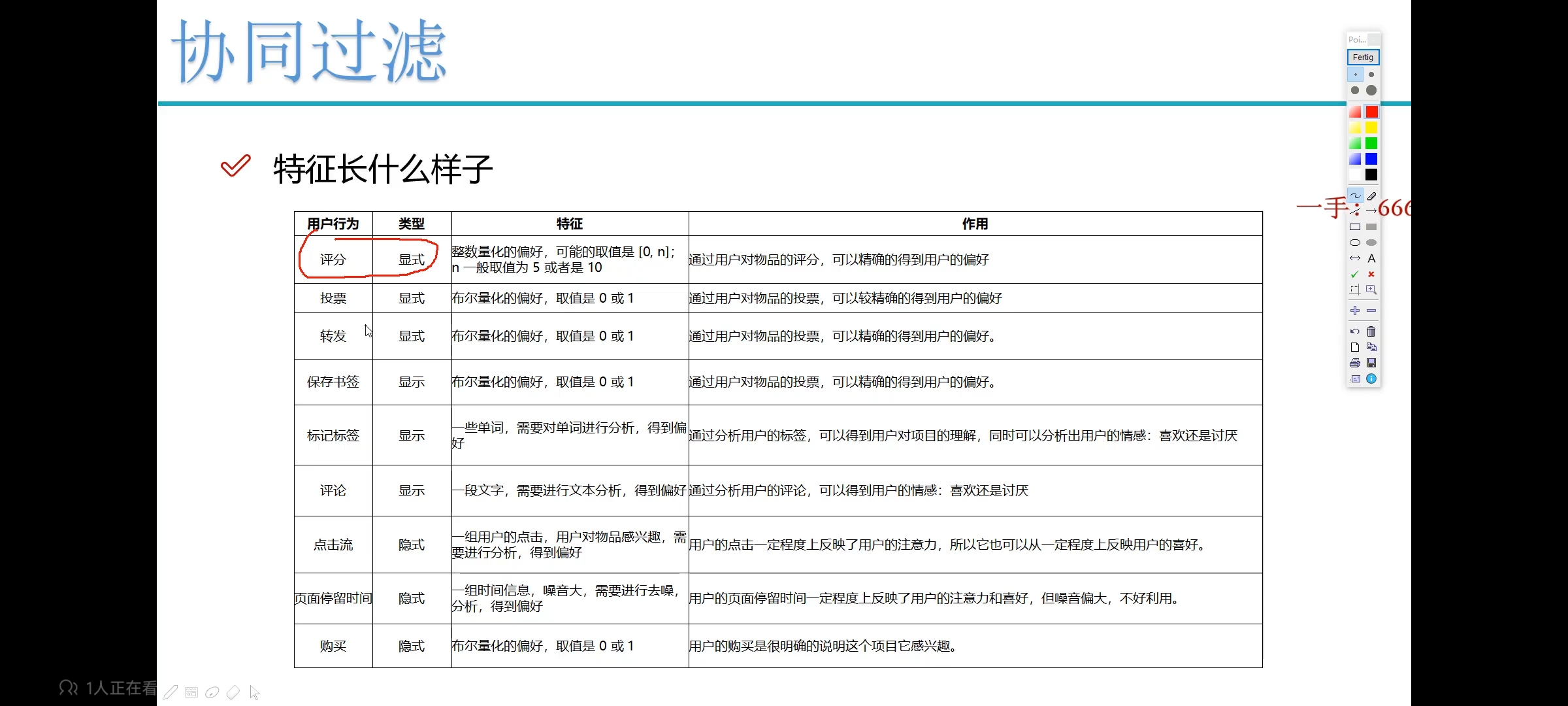
协同过滤
基于用户的协同过滤推荐算法 —— 计算量大 矩阵稀疏
- 首先找到用户相似度
- 属性特征,行为特征等都可以作为计算输入
- 计算两个用户的相似度,如果相似度较高,那么就可以将item推荐给用户
- 较难

基于物品的协同过滤推荐算法 —— 计算量大 矩阵稀疏
先得到用户和商品的交互数据,计算相关度。
不适合实时的内容。
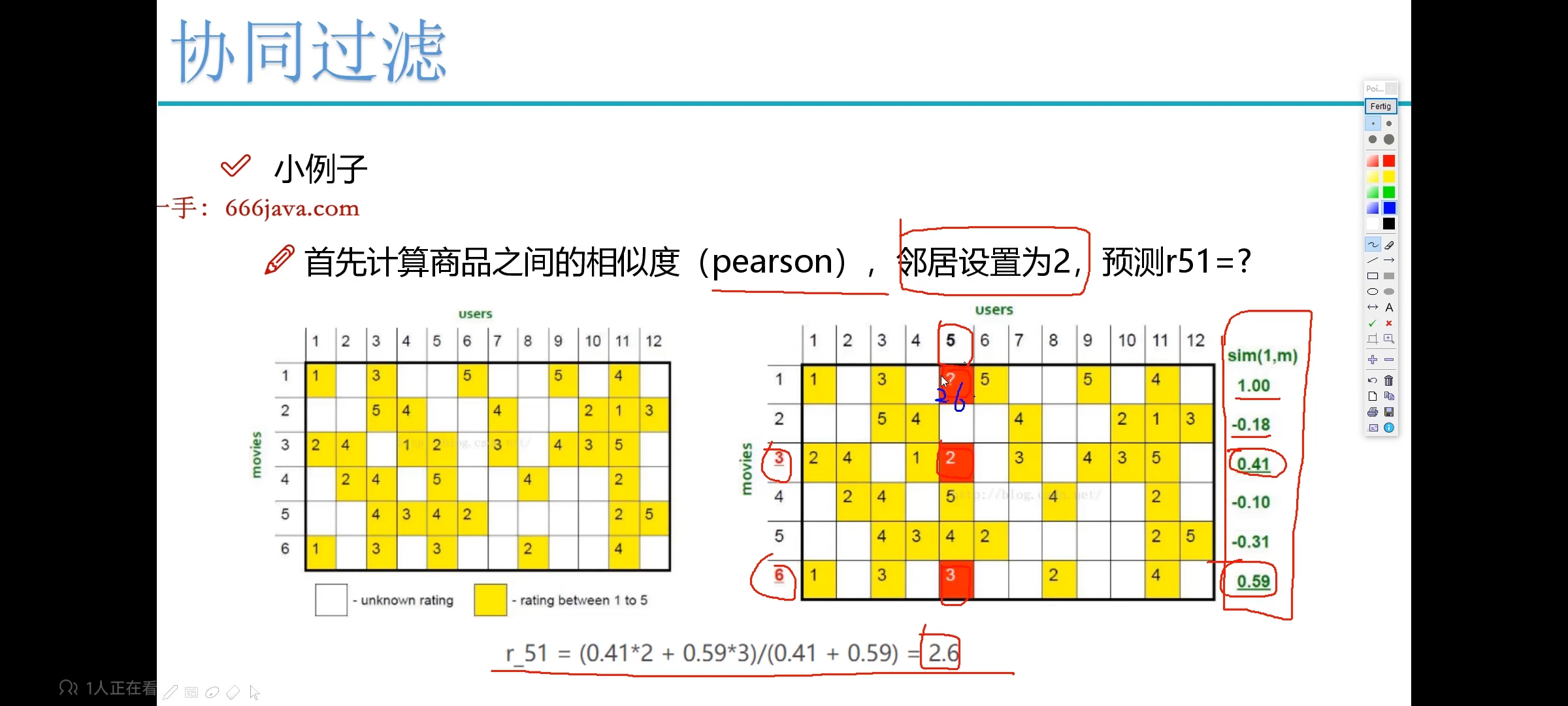
基于矩阵分解 —— 更快
最终目的是降低计算量,优化隐向量。
-
因为数据量大了以后,矩阵非常大,很难计算,那么如何计算呢?—— 矩阵分解:

-
只要近似就行,可以不用在数学上那么严谨。
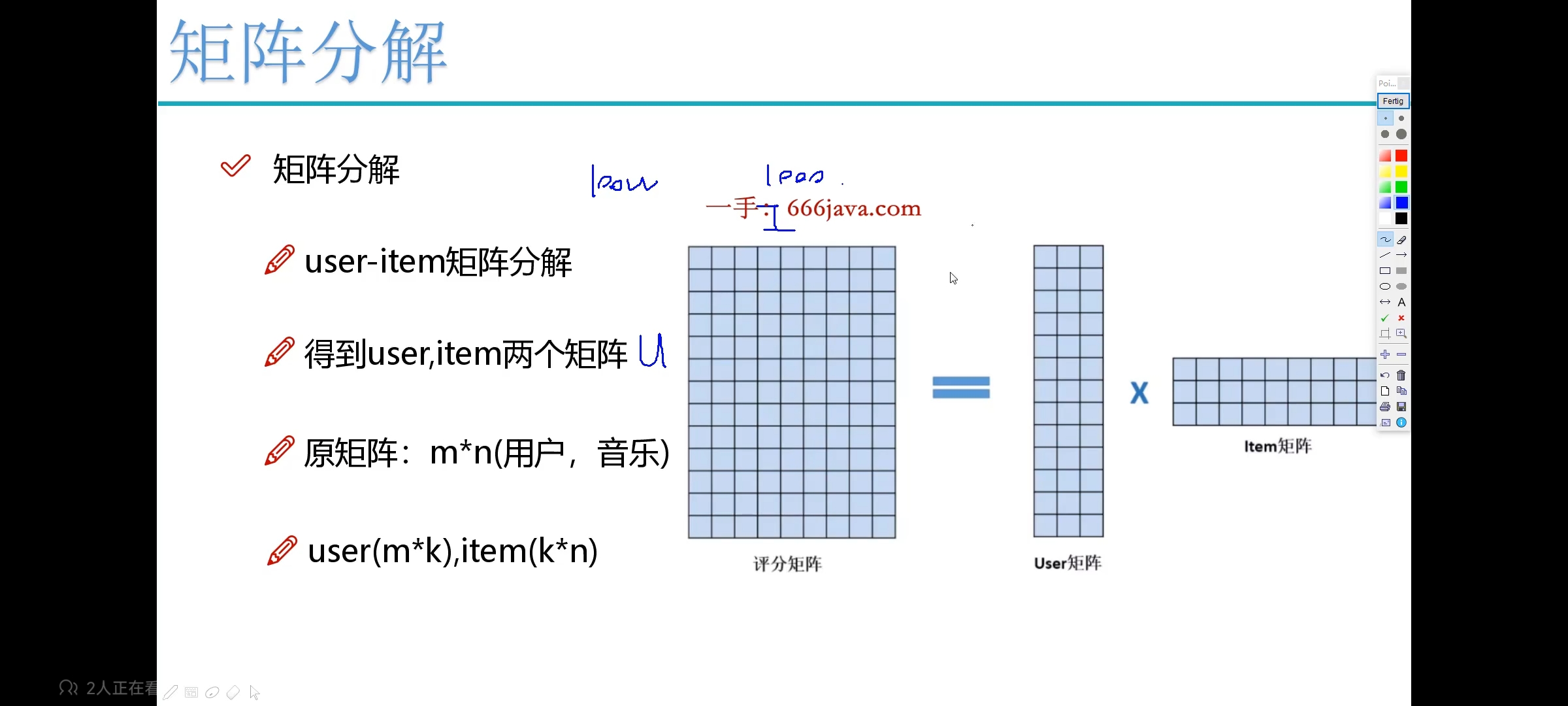
-
矩阵分解后:是有一些特点的!

-
矩阵还原:

-
怎样才能让矩阵分解更好?
需要不断实验进行调参

隐式



显式
目标函数


embedding
L2正则化限制
在防止过拟合的方法中有L1正则化和L2正则化,L1和L2是正则化项,又叫做惩罚项,是为了限制模型的参数,防止模型过拟合而加在损失函数后面的一项。
L2是模型各个参数的平方和的开方值。L2会选择更多的特征,这些特征都会接近于0。最优的参数值很小概率出现在坐标轴上,因此每一维的参数都不会是0。
SLIM(Spares Linear Methods)
SLIM对基于记忆的方法提出了一些改进,该算法从用户交互记录中为所有物品学习一个稀疏矩阵来同时实现高效率和高质量的推荐。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号