【论文随笔】多行为序列Transformer推荐(Multi-Behavior Sequential Transformer Recommender)
前言
今天读的论文为一篇于2022年7月发表在第45届国际计算机学会信息检索会议(SIGIR '22)的论文,文章主要为推荐系统领域提供了一个新的视角,特别是在处理用户多行为序列数据方面,提出了一种有效的Transformer模型框架。
要引用这篇论文,请使用以下格式:
[1]Yuan, Enming, et al. "Multi-behavior sequential transformer recommender." Proceedings of the 45th international ACM SIGIR conference on research and development in information retrieval. 2022.
摘要
在大多数现实世界的推荐系统中,用户以序列化和多行为的方式与物品互动。探索用户多行为互动背后的细粒度关系对于提高推荐系统的性能至关重要。尽管取得了巨大成功,现有方法在建模异构物品级别的多行为依赖性、捕获多样化的多行为序列动态或缓解数据稀疏问题方面似乎存在局限性。在本文中,我们展示了可以推导出一个框架来解决上述所有三个局限性。我们提出的框架MB-STR(多行为序列变换器推荐器),配备了多行为变换器层(MB-Trans)、多行为序列模式生成器(MB-SPG)和行为感知预测模块(BA-Pred)。与典型的变换器相比,我们设计MB-Trans来捕获多行为异构依赖性以及行为特定语义,提出MB-SPG来编码多种行为之间的多样化序列模式,并结合BA-Pred更好地利用多行为监督。在三个真实世界数据集上的全面实验表明,MB-STR通过显著提升推荐性能,与各种竞争性基线相比具有有效性。进一步的消融研究证明了MB-STR不同模块的优越性。
总结来说:
本文提出了一个名为MB-STR的推荐系统框架,旨在通过多行为变换器层、多行为序列模式生成器和行为感知预测模块,解决现有推荐系统在处理用户多行为序列数据时的局限性,包括异构物品依赖性建模、多行为序列动态捕获和数据稀疏问题。实验结果表明,MB-STR在提升推荐性能方面优于多个基线模型,并且通过消融研究验证了其各个组件的有效性。
引言
个性化推荐系统在许多在线服务平台上扮演着重要角色,从在线广告和在线零售到音乐和视频推荐。为了提供精确和定制化的服务,这些系统尝试基于用户的历史交互数据推荐用户可能感兴趣的产品。在大多数现实世界的推荐场景中,用户交互数据有两个重要特征:序列化和多行为化。用户以序列化的方式与物品互动,他们的兴趣模式本质上是多样化的并且不断发展。因此,考虑推荐模型中用户行为的有信息序列动态是很重要的。此外,用户以多行为方式与物品互动。例如,在电商平台上,互动包括点击、添加到收藏夹、添加到购物车和购买等多种行为。这种多行为特性给我们带来了两个重要的好处。首先,不同类型的行为,如点击和购买,反映了不同的用户意图。因此,多行为交互数据为我们提供了捕捉用户细粒度兴趣动态的机会。其次,目标行为数据(例如,在电商平台上的购买,通常是最关心的)通常非常稀疏。如果我们独立地对目标行为数据进行建模,将会出现严重的冷启动问题。幸运的是,如果我们合理地利用丰富的辅助行为数据,这个问题可以得到缓解。最近,已经提出了一些工作来从序列(例如,GRU4Rec、Caser、SASRec、BERT4Rec)或多行为(例如,NMTR、MATN、MB-GCN)的角度对用户交互数据进行建模。然而,尽管考虑用户行为的序列化和多行为化特性的潜在好处,多行为序列推荐问题仍然是一个未被充分探索的领域。具体来说,有三个主要挑战使其成为一个非平凡的问题:
多行为数据的一个重要特征是行为特定语义,因为不同行为反映了不同的用户意图。此外,与不同意图互动的物品将形成复杂的细粒度多行为依赖性。例如,在图1中,最终的购买决策受到来自不同方面的其他历史行为的影响,包括匹配短裤的购买(箭头1)、同一T恤的添加到购物车(箭头2)和最近点击的其他T恤(箭头3)。先前的工作(例如,MATN、MB-GCN、DIPN和DMT)遵循两阶段聚合范式,首先在每种行为下聚合物品以获得统一的表示,然后通过注意力或加权求和操作对所有行为的依赖性进行建模。然而,需要注意的是,这些工作只明确建模了行为级别的依赖性(箭头1),并且未能捕获多行为之间的细粒度物品到物品关系(箭头2和3),我们将其定义为物品级别的依赖性。此外,还应考虑物品关系的异构属性,因为如果我们对物品级别的依赖性进行建模,存在多种行为转换模式。因此,挑战1是:如何在细粒度的物品级别建模异构的多行为依赖性?
当我们考虑序列信息时,不同类型用户-物品互动之间的依赖性变得更加复杂。在图1中,以点击和购买为例。点击代表短期兴趣,所以最近点击的物品(箭头3)可能会影响当前的购买决策,而很久以前点击的物品通常对当前购买决策影响不大。然而,对于购买来说,很久以前购买的物品可能仍然强烈影响当前兴趣(箭头1)。这导致了多样化的多行为序列模式。然而,现有的多行为模型很少考虑序列信息。尽管DIPN和DMT以序列方式聚合特征,但多种行为类型之间的序列模式没有区分,具有固定的单一行为模式。因此,挑战2是:如何有效地建模多样化的多行为序列模式?
通过整合丰富的辅助行为数据,可以缓解目标行为数据的稀疏性问题。然而,如果我们只将辅助行为数据用作特征而不是训练信号(例如,MATN、MBGCN),则会忽略来自辅助行为的丰富监督信号。此外,简单地将辅助行为用作监督信号可能会导致性能下降和负迁移,因为行为之间存在复杂的相关性。因此,需要适当的设计。所以,挑战3是:如何有效地挖掘用户的多行为序列,利用多行为监督信号?
在本文中,为了解决上述挑战,我们提出了多行为序列变换器推荐器(MB-STR)框架。首先,为了在用户交互序列中建模细粒度的多行为依赖性(C1),我们设计了一个新颖的多行为变换器层(MB-Trans),它执行异构行为聚合和行为特定转换。其次,为了捕获多样化的多行为序列模式(C2),我们提出了多行为序列模式生成器(MB-SPG)。这个模块与MB-Trans模块配合,将多样化的多行为序列模式编码到注意力偏差矩阵中。最后,为了更好地利用辅助数据来促进目标行为预测(C3),我们提出了行为感知的遮蔽物品预测模块(BA-Pred),它可以有效地挖掘多行为交互序列。总之,这项工作的主要贡献如下:
我们强调了现实世界用户互动的序列化和多行为化特性,并总结了多行为序列推荐问题中的挑战。
为了解决多行为序列推荐问题,我们提出了一个新的框架,名为MB-STR,它有三个关键组件。通过新颖的多行为变换器(MB-Trans)层对异构物品级别的依赖性进行建模。此外,还结合了一个多行为序列模式生成器模块(MB-SPG),以编码多样化的多行为序列模式。此外,使用行为感知的遮蔽物品预测模块(BA-Pred)通过在目标行为和辅助行为数据上进行训练来促进目标行为的预测。
我们在三个真实世界的数据集上进行了广泛的实验。实验结果证明了MB-STR与几个基线模型相比的有效性。进一步的消融研究解释了我们设计的模块的优越性。
图1:多行为序列推荐的示例。用户通过不同的行为与物品互动。箭头表示最终购买决策的可能解释。
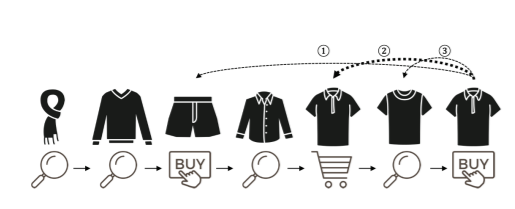
引言部分介绍了多行为序列变换器推荐器(MB-STR)框架,旨在解决现实世界推荐系统中用户多行为交互数据的序列化和多行为化特性带来的挑战。通过设计多行为变换器层、多行为序列模式生成器和行为感知预测模块,MB-STR能够有效地建模用户行为的细粒度依赖性、捕获多样化的序列模式,并利用辅助行为数据来缓解目标行为数据的稀疏性问题。实验结果表明,MB-STR在多个真实世界数据集上的性能优于现有方法,并通过消融研究验证了其设计的有效性。
RELATED WORK 相关工作
Sequential Recommendation(序列推荐)
序列推荐器旨在模拟用户行为中的序列动态,各种序列模型已被应用于此,包括循环神经网络(RNN)、卷积神经网络(CNN)和变换器(Transformer)。例如,Hidasi等人使用门控循环单元(GRU)网络来模拟用户点击序列。通过将序列嵌入矩阵视为图像,Caser模型应用CNN来提取用户在序列中的兴趣模式。由于模型容量高和有效的训练技术,许多基于Transformer的序列推荐方法被提出并取得了显著的改进,例如SASRec、TiSASRec和BERT4Rec。出于同样的原因,本文提出的模型也基于Transformer,同时为多行为建模做了许多改进。
Multi-Behavior Recommendation(多行为推荐)
多行为推荐利用多种类型的用户-物品互动来提高目标行为的性能。先前的工作可以分为三类。第一类工作考虑行为依赖性,仅使用目标行为数据作为监督信号,如注意力记忆网络MATN和图卷积模型MBGCN。另一类工作进一步考虑多任务学习,利用目标和辅助行为数据进行监督,包括级联预测模型NMTR和多任务图元网络MB-GMN。最后一类工作同时考虑了多种用户行为中的序列信息和监督信号,如多视图序列网络DIPN和基于MMoE的多序列模型DMT。如表1所示,我们简要比较了代表性的多行为模型和我们的MB-STR从三个方面:多行为建模、序列信息和行为特定预测。
多行为建模:像MATN、MBGCN、DIPN和DMT这样的模型遵循两阶段聚合范式,只建模粗粒度的行为级依赖性。不同地,我们的MB-STR可以通过多行为变换器建模异构的物品级多行为依赖性。
序列信息:像NMTR、MBGCN、MATN和MB-GMN这样的模型没有考虑序列信息。DIPN和DMT只捕获固定单一行为的序列模式。在MB-STR中,我们提出了MB-SPG组件来建模多样化的多行为序列模式。
行为特定预测:NMTR、MB-GMN、DIPN和DMT以多任务方式进行训练,利用辅助行为的丰富监督信号进行行为特定预测。然而,它们忽略了多行为推荐中存在的共享和任务特定知识。我们进一步明确区分共享组件和行为特定组件,以减轻不同行为之间的冲突参数干扰。
总结来说,这部分讨论了序列推荐和多行为推荐的研究进展,指出现有方法在处理用户行为的序列化和多行为化特性方面存在局限性。序列推荐方法如RNN、CNN和Transformer被用于捕捉用户行为的动态模式,而多行为推荐方法则通过结合目标行为和辅助行为数据来提高推荐性能。尽管已有研究取得了一定成果,但在建模细粒度的多行为依赖性、捕获多样化的序列模式以及有效利用辅助行为数据方面仍有待进一步探索。MB-STR框架的提出旨在通过多行为变换器层、多行为序列模式生成器和行为感知预测模块来解决这些挑战,以期在多行为序列推荐问题上取得更好的性能。
PRELIMINARY 预备知识
Problem Definition(问题定义)
设U = {u1, u2, ..., u|U|} 和 V = {v1, v2, ..., v|V|} 分别表示用户集合和物品集合,其中|U| 和 |V| 分别表示用户和物品的数量。假设有|B|种行为类型。行为集合表示为B = {B1, B2, ..., B|B|},其中一种行为类型被视为我们最关心的目标行为,其他类型的行为被称为辅助行为。对于每个用户,她的历史互动形成了一个多行为互动序列Xu,定义如下:
定义1. 多行为互动序列Xu。Xu由序列对(xu, bu)组成。每对(xu[i], bu[i])描述了一个用户互动,由物品xu[i] ∈ V 和相应的互动行为类型bu[i] ∈ B组成。互动动作按时间顺序排序。Xu进一步转换为固定长度n:如果序列长度小于n,特殊[padding]标记被填充到xu和bu的左侧作为虚拟过去互动。如果序列长度大于n,保留最近的n个动作。
然后,多行为序列推荐问题可以表述如下:给定所有用户的多行为互动序列X,用户集合U,物品集合V,和行为类型集合B,我们的目标是训练一个模型,该模型以用户u的多行为互动序列X(u)作为输入,并估计用户u在时间步n+1下与物品i在目标行为下互动的概率。
Transformer in Recommendation(推荐中的Transformer)
自然语言处理领域的进步推动了许多最近推荐系统的发展,特别是序列推荐。特别是,配备了更高模型容量和有效训练技术的Transformer架构显著提高了序列推荐的有效性。由于Transformer架构与我们的工作高度相关,我们在这里简要描述Transformer的关键组件,包括多头自注意力(MSA)和多层感知器(MLP)。对于序列输入,MSA和MLP分别执行整个序列的聚合和逐位置的转换。
MSA(多头自注意力)。
在MSA的每个头部,输入X ∈ Rn×d线性转换为三个隐藏表示,即查询Qi ∈ Rn×d^h,键Ki ∈ Rn×d^h和值Vi ∈ Rn×d^h,其中i表示特定的头部,n是序列长度,d是输入的维度,h是头部的总数。然后,计算缩放点积注意力如下:
Attn(Qi, Ki, Vi) = softmax(QiKi^T / sqrt(d^h)) * Vi
多头自注意力并行执行上述自注意力机制h次,然后将每个头部的输出连接起来并线性投影以获得最终输出:
MSA(X) = Concat(Attn(Q1, K1, V1), ..., Attn(Qh, Kh, Vh))Wo
MLP(多层感知器)。
MLP用于在MSA层之间引入非线性和特征转换:
MLP(X) = FC(σ(FC(X))), FC(X) = XW + b
其中b和W是全连接层的偏置和权重,σ(·)是激活函数,如ReLU。
总结来说,这部分定义了多行为序列推荐问题,即如何基于用户的历史多行为互动序列来预测用户在特定时间步对特定物品的目标行为。此外,介绍了Transformer架构在推荐系统中的应用,特别是多头自注意力(MSA)和多层感知器(MLP)组件,它们分别用于处理序列数据的聚合和特征转换。这部分内容为理解MB-STR框架的构建和其在多行为推荐中的应用提供了基础。

MB-STR(多行为序列变换器推荐器)
我们现在介绍MB-STR框架。如图2所示,有三个关键组件:(1)多行为变换器层(MB-Trans);(2)多行为序列模式生成器(MB-SPG);以及(3)行为感知遮蔽物品预测模块(BA-Pred)。如图2所示,我们首先通过嵌入矩阵E ∈ R|V |×𝑑将物品序列x转换为输入隐藏表示矩阵H(0)。然后,我们在每个MB-Trans层𝑙(第4.1节)迭代计算隐藏表示H(𝑙)。同时,MB-SPG模块与MB-Trans层耦合,以注入多行为序列模式(第4.2节)。最后,BA-Pred模块根据相应的行为类型预测遮蔽物品(第4.3节)。接下来,我们将详细阐述这三个组件。
多行为变换器层
通常,变换器的输入,无论是单词、音频片段还是图像块,本质上都是同质的。然而,在多行为序列推荐场景中,物品通过不同类型的行为进行互动。这导致了行为特定的语义和细粒度的异构依赖性,这是普通变换器无法捕捉的。在这里,我们提出了一个新颖的多行为变换器(MB-Trans)层,它通过多行为多头自注意力机制(MB-MSA)捕捉细粒度的异构依赖性,并通过行为特定的多层感知器(MLP)建模行为语义。
多行为多头自注意力
为了使MSA具有捕捉多行为异构依赖性的能力,我们将原始MSA推广到多行为多头自注意力(MB-MSA)。总体而言,MB-MSA与原始MSA在四个方面有所不同:(1)行为特定的线性投影应用于获取查询、键和值;(2)在计算注意力分数时考虑行为异质性;(3)将序列模式注入原始注意力矩阵;(4)在聚合值时考虑行为异质性。MB-MSA的详细信息在算法1中描述,并如图2所示。让H(𝑙−1) ∈ R𝑛×𝑑是第𝑙层的输入,其中𝑛是行为序列长度,𝑑是模型维度。
行为特定多层感知器
为了建模行为语义并执行特征转换,我们应用行为特定的多层感知器(BS-MLP)。具体来说,我们为每种行为类型指定一个不同的MLP层。BS-MLP定义如下:
H(𝑙) = BS-MLP(G(𝑙), b)
其中BS-MLP(·)是一个标准MLP层的包装器,每个对应于一种特定的行为类型。在每个位置𝑖,中间表示G(𝑙) [𝑖]使用由行为b[𝑖]指定的行为特定MLP进行处理。
多行为变换器层
最后,我们使用残差连接和层归一化将MB-MSA和BS-MLP模块连接起来,以获得MB-Trans层:
G(𝑙) = LayerNorm H(𝑙−1) + MB-MSA(H(𝑙−1), b, P(𝑙))
H(𝑙) = LayerNorm G(𝑙) + BS-MLP(G(𝑙), b)
多行为序列模式建模
用户互动序列的一个独特特征是多种行为之间的多样化序列模式。以点击和购买为例,点击通常表示短期兴趣,因此最近点击的物品可能强烈影响当前行为,而很久以前点击的物品通常对当前行为影响不大。然而,由于购买行为包含的长期兴趣,很久以前购买的物品可能仍然强烈影响当前兴趣。为了编码这种多样化的多行为序列模式,我们提出了多行为序列模式生成器(MB-SPG)。
MB-SPG的设计原理
在用户互动序列中,任何两个由𝑖, 𝑗索引的动作之间应该存在序列关系。直观地说,这种关系取决于两个动作及其相应行为类型b[𝑖]和b[𝑗]之间的时间距离。基于这种直觉,我们设计了多行为序列模式生成器(MB-SPG)来编码这种序列依赖性。如图2所示,MB-SPG模块与MBTrans层耦合,以产生注意力偏差项。具体来说,给定一个互动序列,MB-SPG模块生成多行为相对位置嵌入矩阵P ∈ Rℎ×𝑛×𝑛(与原始注意力分数相同的维度),其中每个元素P[𝑘,𝑖, 𝑗]衡量位置𝑖在考虑相对距离(𝑗 − 𝑖)和行为类型b[𝑖]和b[𝑗]时应该给予位置𝑗多少注意力。因此,MB-SPG的设计归结为设计|B| × |B|个编码函数𝑓(𝐵𝑖,𝐵𝑗) : R → R,从相对位置的集合R到实数强度项。每个编码函数𝑓(𝐵𝑖,𝐵)对应于一种行为类型对,并编码两种行为类型的时间关系。正式地,在头部𝑘,对于任何两个由𝑖和𝑗索引的动作,
P[𝑘,𝑖, 𝑗] = 𝑓(b[𝑖]b[𝑗]) (𝑗 − 𝑖),
其中(𝑗−𝑖)是𝑗相对于𝑖的距离,𝑓(b[𝑖]−b[𝑗]) (·)是由行为类型对(b[𝑖], b[𝑗])指定的编码函数。通过这种方式,多行为序列模式被捕获,并进一步用于注意力计算。接下来,我们将详细描述单个编码函数𝑓 (·)的实现。
相对位置编码函数
相对位置编码函数的一个直接实现是通过简单的嵌入查找表将相对位置映射到实数。然而,具有相同相对距离的位置对数量是不平衡的。例如,对于长度为50的序列,有49对{(0,1),(1,2), ... (48,49)}具有相对位置1,而只有1对(0,49)具有相对位置49。这种不平衡问题可能导致对长距离序列模式的学习不足。类似于自然语言处理中的T5,我们在相对位置编码函数中设计了一个启发式桶机制来缓解这种不平衡问题。具体来说,𝑓进一步表示为桶函数𝑏和嵌入查找表ℎ的组合。前者将相对位置映射到“桶”索引,后者将桶索引编码为偏差项。◦表示函数组合,其中ℎ ◦ 𝑏(𝑥) = ℎ(𝑏(𝑥))。首先,我们引入桶函数𝑏的设计。假设最大序列长度为𝑛,桶的数量为𝑁𝐵,索引从0到𝑁𝐵 − 1,其中𝑋 > 𝑁𝐵。对于输入的相对位置(𝑗 − 𝑖),桶函数𝑏(·)定义如下:
𝑏(𝑗 − 𝑖) =
{ 𝐵 (𝑗 − 𝑖) 如果 (𝑗 − 𝑖) ≥ 0
𝐵 (−(𝑗 − 𝑖)) + 𝑁𝐵/2 如果 (𝑗 − 𝑖) < 0
其中一半的桶用于正相对位置,另一半用于负相对位置。𝐵(𝑥)定义如下:
𝐵(𝑥) =
{ 𝑥 如果 0 ≤ 𝑥 < 𝑁𝐵/4
4 * min(log2(𝑋−log2(𝑁𝐵/2)), log2(𝑋−log2(𝑁𝐵/2)) * (𝑁𝐵/4), 𝑁𝐵/2 − 1 如果 𝑋 ≥ 𝑁𝐵/4
我们绘制了𝑁𝐵 = 32和𝑋 = 50的桶函数𝑏在图3中。然后,一个嵌入查找表ℎ将桶索引{0, 1, ..., 𝑁𝐵 −1}映射到实数。让E𝑏 ∈ R𝑁𝐵×ℎ表示桶嵌入矩阵,其中ℎ是头部的数量。E𝑏像一个普通的嵌入层,它是随机初始化的,并在训练期间不断更新。
行为感知遮蔽物品预测
MB-Trans层和MB-SPG模块作为模型的主干,可以对物品级别的多行为依赖性和序列模式进行建模。然而,一个新的挑战出现了:如何有效地从用户的多行为互动序列中挖掘信息?我们提出了一个行为感知预测模块(BA-Pred)和一个行为感知遮蔽物品预测目标来应对这个挑战。
行为感知预测模块
先前的工作表明,使用多行为监督信号而不是仅使用目标行为可以显著提高推荐性能。因此,多行为推荐通常被制定为一个多任务学习问题。然而,不同类型的行为可能是弱相关的,甚至可能是冲突的(例如,在评分网站上的喜欢和不喜欢),这可能导致性能下降,称为负迁移。因此,为了更好地捕捉行为特定信息并模拟不同行为之间的共性,我们进一步设计了一个行为感知预测模块(BA-Pred)。如图2所示,BA-Pred模块是一个参数共享结构,类似于多门控混合专家(MMoE)[27]。与MMoE中直接共享参数不同,我们明确地区分了共享专家和行为特定专家。这样,BA-Pred可以更好地减轻共享和行为特定信息之间的冲突参数干扰。
具体来说,在位置𝑖进行预测时,BA-Pred结构可以表示为:
𝑜𝑖 = 𝑔𝑘 (H(𝐿) [𝑖])⊤𝐸𝑘 (H(𝐿) [𝑖]),
其中H(𝐿)是MBTrans的最后层的隐藏表示,𝑔𝑘 (·)是门控函数,通过线性变换和softmax操作计算特定行为类型𝑘 = b[𝑖]的门控权重:
𝑔𝑘 (𝑥) = softmax(W𝑘𝑔𝑥),
其中W𝑘𝑔 ∈ R(𝑛𝑏+𝑛𝑠)×𝑑是门控参数,𝑋𝑏和𝑋𝑠分别是行为特定专家和共享专家的数量。𝐸𝑘 (·)是行为特定专家𝑒𝑘,𝑖 (·)和共享专家𝑒𝑠,𝑖 (·)的组合:
𝐸𝑘 (𝑥) = [𝑒𝑘,1(𝑥),𝑒𝑘,2(𝑥),...,𝑒𝑘,𝑛𝑏 (𝑥),𝑒𝑠,1(𝑥),𝑒𝑠,2(𝑥),...,𝑒𝑠,𝑛𝑠 (𝑥)],
每个专家是一个简单的线性层。最后,预测是通过最终行为特定表示𝑜和物品嵌入矩阵E ∈ R|V |×𝑑的点积来进行的,这个矩阵与输入物品嵌入矩阵共享,以减少模型大小并减轻过拟合:
p𝑖 (𝑣) = softmax(𝑜𝑖 · E⊤),
其中p𝑖 (𝑣) ∈ R|V |是在位置𝑖对所有物品𝑣 ∈ V的预测概率分布。
行为感知遮蔽物品预测目标
结合BA-Pred模块,我们提出了一个新的训练目标,以有效地挖掘多行为互动序列。具体来说,给定多行为互动序列𝑋 = (x, b),我们首先构造一个损坏的物品序列ˆx,通过随机将x中的部分(𝜌)物品设置为特殊掩码符号[MASK],同时保持行为序列b未掩码。让掩码物品为¯x。然后,行为感知遮蔽物品预测目标是基于ˆx和b重建¯x:
min 𝜃 − log𝑝𝜃 (x | ˆx, b) = −∑𝑖=1𝑛 𝑚𝑖 log𝑝𝜃 (x[𝑖] | ˆx, b),
其中𝑚𝑖 = 1表示x[𝑖]被掩码,𝜃是模型参数,概率𝑝𝜃 (x[𝑖] | ˆx, b)是根据方程12中的p𝑖 (𝑣 = x[𝑖])计算的。在特定的掩码位置𝑖,预测是基于位置𝑖周围的上下文动作和在位置𝑖执行的行为类型进行的。通过仅掩码物品并保持行为类型未掩码,模型执行行为感知预测,更好地捕捉不同类型行为下的多样化用户偏好。
模型学习和复杂性分析
训练。
通过优化方程13中定义的行为感知遮蔽物品预测目标来训练MB-STR。
测试。
给定多行为互动序列𝑋 = (x, b),我们在物品序列x的末尾附加特殊标记“[MASK]”,并在行为序列b的末尾附加目标行为类型。然后,我们基于历史多行为互动数据预测目标行为下的下一个物品。
空间复杂性。
我们模型中的可学习参数来自物品嵌入(𝑂(|V|𝑑))和MBTrans(𝑂(|B|𝑑2))、MB-SPG(𝑂(𝑛))和行为感知预测头(𝑂(|B|𝑑2))的参数。总参数数量是𝑂(|V|𝑑 + |B|𝑑2 + 𝑋),与其他方法(例如SASRec和BERT4Rec的𝑂(|V|𝑑 + 𝑑2 + 𝑋𝑑))相比是适度的,因为|B|和𝑑相对较小(分别为4和16)。
时间复杂性。
由于MB-SPG模块由硬编码的桶函数和嵌入查找表组成,而行为感知预测头仅由线性专家组成。因此,我们MB-STR的计算复杂性主要由MB-Trans层决定。具体来说,MB-MSA和BS-MLP需要𝑂(𝑋2𝑑 + 𝑋𝑑2),其中MB-MSA层的主导项通常是𝑋2𝑑。然而,我们模型的一个方便特性是每个自注意力层的计算是完全可并行化的,这适合GPU加速。
总结
这篇文章介绍了一个名为MB-STR(多行为序列变换器推荐器)的新型推荐系统框架,旨在通过结合多行为变换器层、多行为序列模式生成器和行为感知预测模块来提高推荐系统的性能。MB-STR能够捕捉用户行为的细粒度依赖性、多样化的序列模式,并有效利用辅助行为数据来缓解目标行为数据的稀疏性问题。实验结果表明,MB-STR在多个真实世界数据集上的性能优于现有方法,并通过消融研究验证了其设计的有效性。此外,文章还探讨了模型的可解释性,展示了通过MB-STR学习到的多行为序列模式。
写在结尾
好了,今天的论文就读到这了,明天见!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号