传统Item-Based协同过滤推荐算法改进
前言
今天要读的论文为一篇于2009年10月15日发表在《计算机研究与发展》的一篇会议论文,论文针对只根据相似性无法找到准确可靠的最近邻这个问题,提出了结合项目近部等级与相似性求取最近邻的新方法;此外针对系统中新加入的项目,因为其上评分信息的匾乏,求得的最近邻往往是不准确的,为此,提出了聚合最近邻和”集体评分”两种改进方法。
摘要
传统Item-Based协同过滤算法根据项目之间的相似性来选取最近邻居。然而,现存的几种相似性度量方法都存在相应的弊端,因此只根据相似性无法找到准确可靠的最近邻。根据对两项目共同评分的用户个数,建立项目近邻等级,提出了结合项目近部等级与相似性求取最近邻的新方法。另外,对于系统中新加入的项目,因为其上评分信息的匾乏,求得的最近邻往往是不准确的。为此,提出了聚合最近邻和”集体评分”两种改进方法。在MovieLens数据集上的实验结果表明,将上述改进应用于传统Item-Based协同过滤推荐算法,推荐质量有明显提升。
传统的item-based协同过滤推荐算法
推荐系统中,数据的核心是一个用户一项目评分矩阵A(m,n),它包含m个用户的集合U={u1, u2, ..., um},和n个项目的集合I={i1, i2, ..., in},元素Rui表示用户u对项目i的评分,若用户u未对项目i评分,则Rui=0.
项目的相似度度量方法
首先我们定义:
- 对于任意的i∈I,定义项目一评分矩阵A(m,n)中对应于i的列为项目i的评分向量,记为Ui。
- 对于任意的u∈U,定义项目一评分矩阵A(m,n)中对应于u的 行为用户u 的评分向量,记为Iu。
余弦相似度
-
标准的余弦相似度:

-
修正的余弦相似度
不同用户存在不同评分尺度的偏见,下面将采取减去对应项目上所有用户的平均评分的方法,来刻画用户对某一项目的评分与“公众意见”的偏差。

相关相似性
根据pearson提出的相关系数来度量项目之间的相似性,定义对项目i和j都有评分的用户集合为Uij。
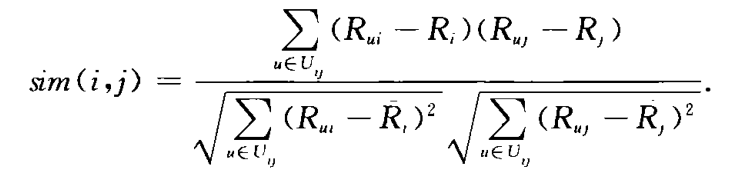
选择合适的相似性度量方法,求出项目集I中任意两项目之间的相似性,存入项目相似性矩阵Sim中,显然,Sim是对称矩阵。
最近邻的选取
中心最近邻
中心最近邻,是当前最常用也是最成功的最近邻选取方法。对于任意的i∈I,根据相似性矩阵Sim中其他项目与i的相似性,按从大到小顺序排列,将相应的项目编号存入最近邻矩阵TkNN的相应行中,构成项目i的最近邻集合;即第一最近邻与i的相似性最高,第二最近邻次之,依此类推。
聚合最近邻
聚合最近邻,对于某些新加人的项目,其评分向量与其他项目的评分向量的交集很小,不利于准确地计算相似性。比如说,已知当前项目i的第一最近邻为j,项目k和i被1个用户共同评分,项目t和i没有被共同评过分。这样,在i的最近邻列表中,k排在t前。但此时,若t是j的第一最近邻,那么t
也很有可能是i的最近邻。聚合最近邻的思想就是基于上述考虑。
算法改进
求取最近邻过程的改进—结合使用项目相似性与项目近邻等级
求取最近邻是整个协同过滤算法最关键的一步。最近邻越准确,其推荐结果就越可靠。因为最近邻根据项目相似性矩阵Sim来选取。
产生推荐过程的改进—集体评分
对于新加入的项目,集体评分是一个解决难以找到新加入项目最近邻的好方法。
结尾
好了,今天的论文就先读到这儿了,明天再见喽。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号