gj10 python socket编程
10.1 HTTP、Socket、TCP这几个概念
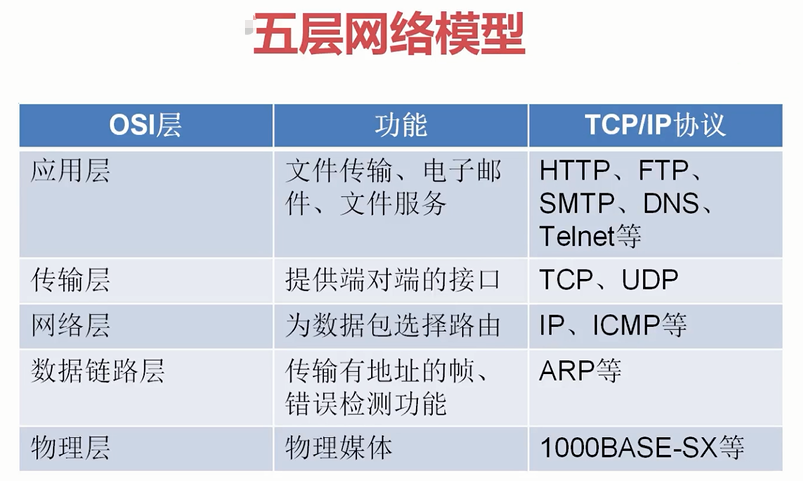
五层网络模型
socket 不属于任何协议,是一个API,通过socket 可以和传输层的打交道,然后在之上可以实现自己的功能和协议
10.2 client和server实现通信
Socket编程

http 是短连接无状态

10.3 socket实现聊天和多用户连接
import socket import threading server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) server.bind(('127.0.0.1', 8000)) server.listen(5) def handle_sock(sock, addr): while True: data = sock.recv(1024) print(data.decode("utf8")) re_data = input("s>>>") sock.send(re_data.encode("utf8")) # 获取从客户端发送的数据 # 一次获取1k的数据 while True: sock, addr = server.accept() # 用线程去处理新接收的连接(用户) client_thread = threading.Thread(target=handle_sock, args=(sock, addr)) client_thread.start() # data = sock.recv(1024) # print(data.decode("utf8")) # re_data = input() # sock.send(re_data.encode("utf8")) # server.close() # sock.close()
import socket client = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # ipv4 tcp client.connect(('127.0.0.1', 8000)) while True: re_data = input(">>>") client.send(re_data.encode("utf8")) data = client.recv(1024) print(data.decode("utf8")) # client.send("bobby".encode("utf8")) # data = client.recv(1024) # print (data.decode("utf8")) # client.close()
10.4 socket模拟http请求
#requests -> urlib -> socket import socket from urllib.parse import urlparse def get_url(url): #通过socket请求html url = urlparse(url) host = url.netloc path = url.path if path == "": path = "/" #建立socket连接 client = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # client.setblocking(False) client.connect((host, 80)) #阻塞不会消耗cpu #不停的询问连接是否建立好, 需要while循环不停的去检查状态 #做计算任务或者再次发起其他的连接请求 client.send("GET {} HTTP/1.1\r\nHost:{}\r\nConnection:close\r\n\r\n".format(path, host).encode("utf8")) data = b"" while True: d = client.recv(1024) if d: data += d else: break data = data.decode("utf8") html_data = data.split("\r\n\r\n")[1] print(html_data) client.close() if __name__ == "__main__": import time start_time = time.time() # for url in range(20): # # url = "http://www.baidu.com/?goods/{}/".format(url) # # get_url(url) url = "http://www.baidu.com" get_url(url) print(time.time()-start_time)
-
本文来自博客园,作者:元贞,转载请注明原文链接:https://www.cnblogs.com/yuleicoder/p/10374709.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号