机器学习基本介绍
1、人工智能概述
人工智能发展必备三要素:
- 数据
- 算法
- 计算力
- CPU,GPU,TPU
计算力之CPU、GPU对比:
-
CPU主要适合I\O密集型的任务
-
GPU主要适合计算密集型任务
1.1、人工智能、机器学习和深度学习的关系

人工智能和机器学习,深度学习的关系:
-
机器学习是人工智能的一个实现途径
-
深度学习是机器学习的一个方法发展而来
1.2、人工智能发展历程
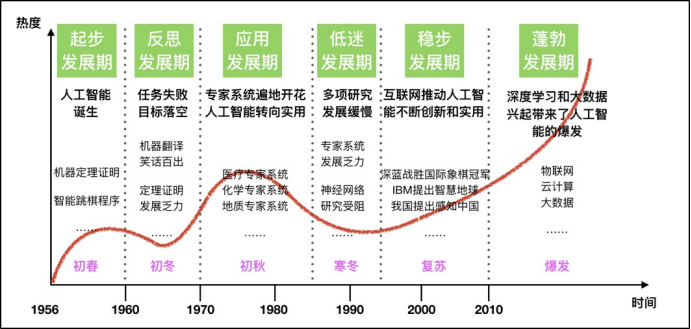
人工智能的起源:图灵测试。即测试者与被测试者(一个人和一台机器)隔开的情况下,通过一些装置(如键盘)向被测试者随意提问。多次测试(一般为5min之内),如果有超过30%的测试者不能确定被测试者是人还是机器,那么这台机器就通过了测试,并被认为具有人类智能。
人工智能充满未知的探索道路曲折起伏。如何描述人工智能自1956年以来60余年的发展历程,学术界可谓仁者见仁、智者见智。我们将人工智能的发展历程划分为以下6个阶段:
1.3、人工智能主要分支
通讯、感知与行动是现代人工智能的三个关键能力,在这里我们将根据这些能力/应用对这三个技术领域进行介绍:
- 计算机视觉(CV)
- 自然语言处理(NLP)
- 在 NLP 领域中,将覆盖文本挖掘/分类、机器翻译和语音识别。
- 机器人
-
计算机视觉
计算机视觉(CV)是指机器感知环境的能力。这一技术类别中的经典任务有图像形成、图像处理、图像提取和图像的三维推理。物体检测和人脸识别是其比较成功的研究领域。
当前阶段:计算机视觉现已有很多应用,这表明了这类技术的成就,也让我们将其归入到应用阶段。随着深度学习的发展,机器甚至能在特定的案例中实现超越人类的表现。但是,这项技术离社会影响阶段还有一定距离,那要等到机器能在所有场景中都达到人类的同等水平才行(感知其环境的所有相关方面)。
发展历史:

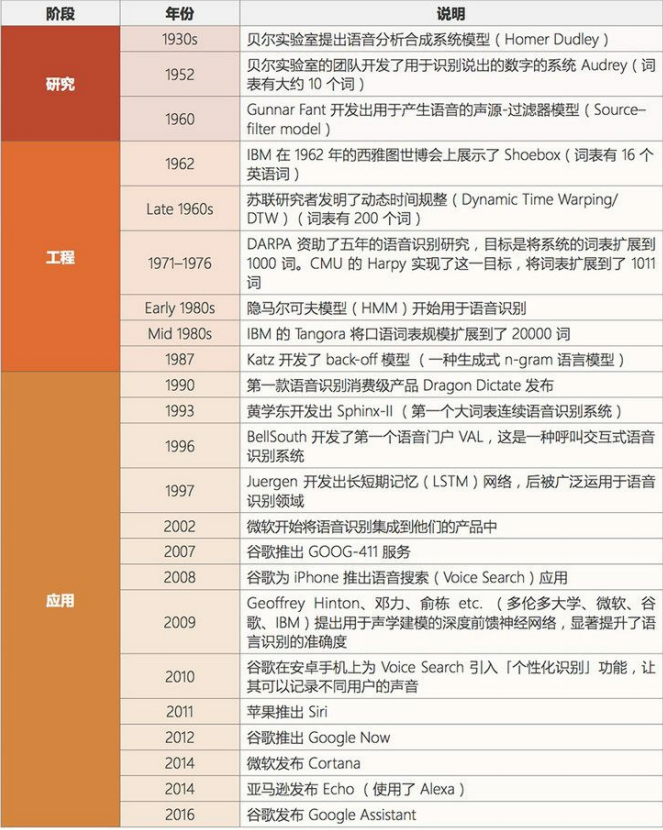
- 语音识别
语音识别是指识别语音(说出的语言)并将其转换成对应文本的技术。相反的任务(文本转语音/TTS)也是这一领域内一个类似的研究主题。
当前阶段:语音识别已经处于应用阶段很长时间了。最近几年,随着大数据和深度学习技术的发展,语音识别进展颇丰,现在已经非常接近社会影响阶段了。语音识别领域仍然面临着声纹识别和「鸡尾酒会效应」等一些特殊情况的难题。现代语音识别系统严重依赖于云,在离线时可能就无法取得理想的工作效果。
发展历史:
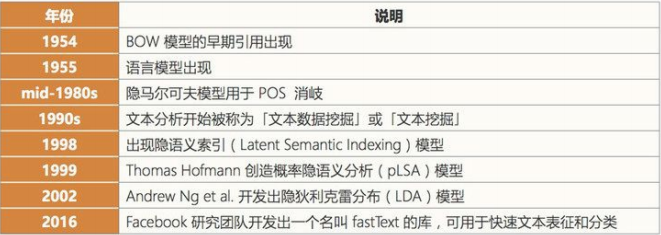
- 文本挖掘/分类
这里的文本挖掘主要是指文本分类,该技术可用于理解、组织和分类结构化或非结构化文本文档。其涵盖的主要任务有句法分析、情绪分析和垃圾信息检测。
当前阶段:我们将这项技术归类到应用阶段,因为现在有很多应用都已经集成了基于文本挖掘的情绪分析或垃圾信息检测技术。文本挖掘技术也在智能投顾的开发中有所应用,并且提升了用户体验。文本挖掘和分类领域的一个瓶颈出现在歧义和有偏差的数据上。
发展历史:
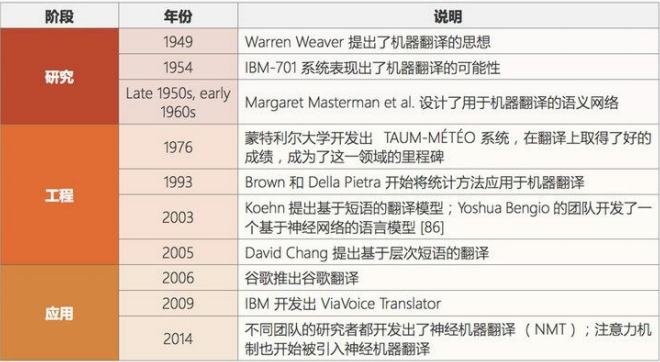
- 机器翻译
机器翻译(MT)是利用机器的力量自动将一种自然语言(源语言)的文本翻译成另一种语言(目标语言)。
当前阶段:机器翻译是一个见证了大量发展历程的应用领域。该领域最近由于神经机器翻译而取得了非常显著的进展,但仍然没有全面达到专业译者的水平;但是,我们相信在大数据、云计算和深度学习技术的帮助下,机器翻译很快就将进入社会影响阶段。在某些情况下,俚语和行话等内容的翻译会比较困难(受限词表问题)。专业领域的机器翻译(比如医疗领域)表现通常不好。
发展历史:
- 机器人
机器人学(Robotics)研究的是机器人的设计、制造、运作和应用,以及控制它们的计算机系统、传感反馈和信息处理。
机器人可以分成两大类:固定机器人和移动机器人。固定机器人通常被用于工业生产(比如用于装配线)。常见的移动机器人应用有货运机器人、空中机器人和自动载具。机器人需要不同部件和系统的协作才能实现最优的作业。其中在硬件上包含传感器、反应器和控制器;另外还有能够实现感知能力的软件,比如定位、地图测绘和目标识别。
当前阶段:
自上世纪「Robot」一词诞生以来,人们已经为工业制造业设计了很多机器人。工业机器人是增长最快的应用领域,它们在 20 世纪 80 年代将这一领域带入了应用阶段。在安川电机、Fanuc、ABB、库卡等公司的努力下,我们认为进入 21 世纪之后,机器人领域就已经进入了社会影响阶段,此时各种工业机器人已经主宰了装配生产线。此外,软体机器人在很多领域也有广泛的应用,比如在医疗行业协助手术或在金融行业自动执行承销过程。但是,法律法规和「机器人威胁论」可能会妨碍机器人领域的发展。还有设计和制造机器人需要相对较高的投资。
发展历史:
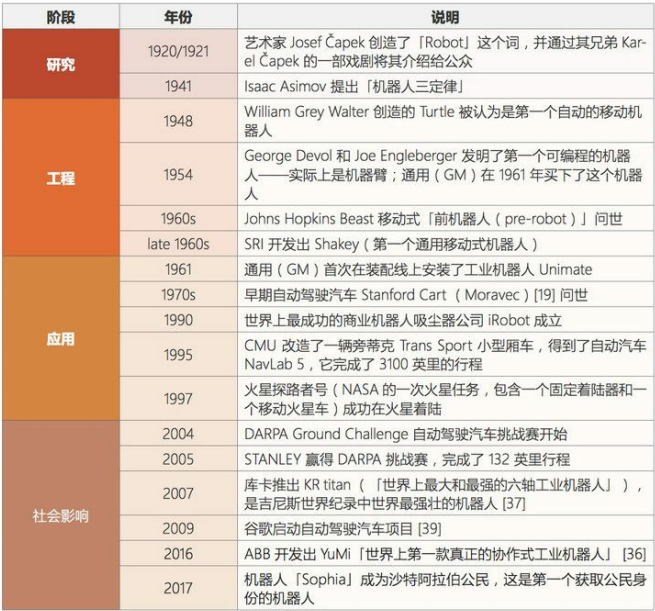
总的来说,人工智能领域的研究前沿正逐渐从搜索、知识和推理领域转向机器学习、深度学习、计算机视觉和机器人领域。大多数早期技术至少已经处于应用阶段了,而且其中一些已经显现出了社会影响力。一些新开发的技术可能仍处于工程甚至研究阶段,但是我们可以看到不同阶段之间转移的速度变得越来越快。
2、机器学习基本介绍
机器学习是从数据中自动分析获得模型,并利用模型对未知数据进行预测。
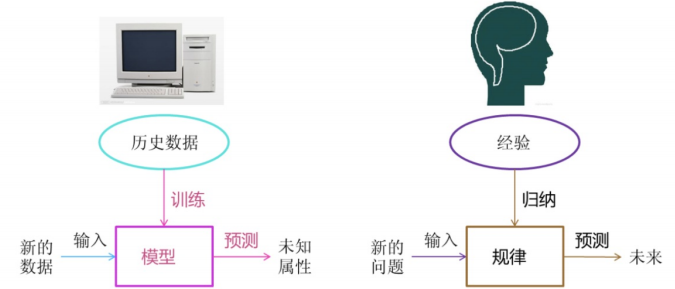
2.1、机器学习工作流程

机器学习工作流程总结
- 获取数据
- 数据基本处理
- 特征工程
- 机器学习(模型训练)
- 模型评估
结果达到要求,上线服务;没有达到要求,重新上面步骤。
2.1.1、数据集介绍
在数据集中一般:
- 一行数据我们称为一个样本
- 一列数据我们成为一个特征
- 有些数据有目标值(标签值),有些数据没有目标值(如上表中,电影类型就是这个数据集的目标值)
数据类型构成:
- 数据类型一:特征值+目标值(目标值是连续的和离散的)
- 数据类型二:只有特征值,没有目标值
数据分割:
- 机器学习一般的数据集会划分为两个部分:
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验时使用,用于评估模型是否有效
- 划分比例:
- 训练集:70% 80% 75%
- 测试集:30% 20% 25%
2.1.2、数据基本处理
即对数据进行缺失值、去除异常值等处理
2.1.3、特征工程
特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。意义:会直接影响机器学习的效果
机器学习领域的大神Andrew Ng(吴恩达)老师说“Coming up with features is difficult, time-consuming, requires expert knowledge.“Applied machine learning” is basically feature engineering. ” 译:业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
特征工程包含内容:
- 特征提取:将任意数据(如文本或图像)转换为可用于机器学习的数字特征。
- 特征预处理:通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程
- 特征降维:指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程
2.1.4、机器学习
2.1.5、模型评估
2.2、独立同分布
- 独立(Independent):如果随机变量相互独立,意味着对于任意的子集<span class="math-inline math-inline-g6LMoI">(其中<span class="math-inline math-inline-g6LMoI">),它们的联合概率分布等于各自概率分布的乘积。即<span class="math-inline math-inline-g6LMoI">。简单来说,一个随机变量的取值不会影响其他随机变量的取值。例如,多次抛硬币,每次抛硬币的结果(正面或反面)都不会受到之前抛硬币结果的影响。
- 同分布(Identically Distributed):这表示所有的随机变量都具有相同的概率分布函数。例如,每次抛同一枚均匀硬币,每次抛硬币出现正面或反面的概率分布都是相同的,即正面概率为<span class="math-inline math-inline-g6LMoI">,反面概率为<span class="math-inline math-inline-g6LMoI">。
在机器学习中的重要性:
- 训练数据假设:在许多机器学习算法中,通常假设训练数据是独立同分布的。例如在监督学习中,我们希望输入数据的每个样本(如数据集中的每一行数据)是独立的,并且它们都来自相同的分布。这是因为大多数机器学习模型的理论分析和性能保证都是基于这个假设的。
- 模型泛化:如果数据是独立同分布的,那么模型在训练数据上学习到的规律更有可能推广到测试数据上。因为模型假设未来遇到的数据(测试数据)和训练数据来自相同的分布,并且每个数据点之间相互独立。如果这个假设不成立,例如训练数据和测试数据的分布差异很大,那么模型在测试数据上的性能可能会很差。
- 统计推断基础:独立同分布是进行统计推断的重要基础。例如,在计算样本均值的期望和方差时,独立同分布的假设可以让我们推导出一些重要的性质。假设是独立同分布的随机变量,均值为<span class="math-inline math-inline-g6LMoI">,方差为<span class="math-inline math-inline-g6LMoI">,那么样本均值<span class="math-inline math-inline-g6LMoI">的期望<span class="math-inline math-inline-g6LMoI">,方差<span class="math-inline math-inline-g6LMoI">。这些性质在估计模型参数、评估模型的稳定性等方面都非常重要。
3、机器学习算法分类
根据数据集组成不同,可以把机器学习算法分为:
- 监督学习
- 无监督学习
- 半监督学习
- 强化学习
3.1、监督学习(Supervised Learning)
概念:监督学习使用标记的训练数据,即输入数据和对应的输出标签。算法的目标是学习输入和输出之间的映射关系,以便对新的未标记数据进行预测。
监督学习是机器学习中的一种重要范式。在监督学习中,我们有一个包含输入数据(通常表示为)和对应的输出标签(通常表示为<span class="math-inline math-inline-g6LMoI">)的训练数据集。模型的任务是学习从输入<span class="math-inline math-inline-g6LMoI">到输出<span class="math-inline math-inline-g6LMoI">的映射关系<span class="math-inline math-inline-g6LMoI">。例如,在一个房价预测任务中,输入是房屋的各种特征,如面积、房间数量、房龄等,输出<span class="math-inline math-inline-g6LMoI">是房屋的价格。模型需要通过学习这些带有价格标签的房屋特征数据,来建立一个能够根据新的房屋特征预测房价的函数。
3.2、无监督学习(Unsupervised Learning)
概念:无监督学习使用未标记的数据,算法需要自己发现数据中的结构和模式。
无监督学习是一种机器学习方法,它处理的是未标记的数据。在无监督学习中,没有给定明确的输出标签或目标值来指导模型的学习。相反,模型需要自己从数据的结构、分布和模式中发现有价值的信息。例如,想象有一堆形状、颜色各异的石头,无监督学习就像是在没有任何预先定义的类别(如 “圆形石头”“方形石头”)的情况下,尝试去找出这些石头可能存在的分组规律或者其他内在模式。
- 聚类算法:
- K - 均值聚类(K - Means Clustering):将数据划分为 K 个簇。首先随机选择 K 个中心点,然后将每个数据点分配到距离最近的中心点所在的簇,接着更新中心点,重复这个过程直到簇的划分不再变化。例如,将用户根据消费行为聚类为不同的群体。
- 层次聚类(Hierarchical Clustering):构建一个聚类层次结构,有凝聚式(从每个数据点作为一个单独的簇开始,逐步合并)和分裂式(从所有数据点在一个簇开始,逐步分裂)两种方式。可以用于生物分类等领域
- 降维算法:
3.3、半监督学习(Semi - supervised Learning)
概念:介于监督学习和无监督学习之间,同时使用少量的标记数据和大量的未标记数据来训练模型。例如,在图像分类任务中,只有少量图像有准确的类别标签,结合大量未标记图像来提高模型的性能。
算法示例:半监督支持向量机(Semi - supervised SVM),它利用未标记数据来帮助构建更好的决策边界,提高分类的准确性。
3.4、强化学习(Reinforcement Learning)
概念:智能体(agent)在环境(environment)中采取一系列行动(action),根据环境反馈的奖励(reward)信号来学习最优的行为策略。
算法示例:
- Q - 学习(Q - Learning):智能体通过学习一个 Q - 函数来估计在某个状态下采取某个行动的长期奖励。例如,在机器人导航中,机器人通过不断尝试不同的移动路径,根据是否到达目标位置获得奖励,从而学习最佳的导航策略。
- 深度 Q - 网络(Deep Q - Network,DQN):结合了深度学习和 Q - 学习,使用神经网络来近似 Q - 函数,用于处理高维的状态空间和复杂的决策问题,如游戏中的智能角色控制。
4、机器学习模型评估
定义:模型评估是指在机器学习和数据分析领域,使用各种定量和定性的方法来衡量模型性能的过程。其目的是了解模型在给定任务(如分类、回归、聚类等)上的有效性、准确性、稳定性和泛化能力等诸多方面的表现。
重要性:通过模型评估,可以确定模型是否达到了预期的性能标准,是否适合部署到实际应用场景中。同时,评估结果还可以为模型的选择、调整和优化提供依据,帮助开发人员和数据科学家提高模型的质量。
按照数据集的目标值不同,可以把模型评估分为分类模型评估、回归模型评估。
4.1、分类模型评估
分类模型的评估指标包括:准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1 - 分数(F1 - Score)
4.2、回归模型评估
回归模型的评估指标包括:均方误差(Mean Squared Error,MSE)、均方根误差(Root Mean Squared Error,RMSE)、平均绝对误差(Mean Absolute Error,MAE)
4.3、模型评价
模型评估用于评价训练好的的模型的表现效果,其表现效果大致可以分为两类:过拟合、欠拟合。
4.3.1、欠拟合
4.3.2、过拟合
5、深度学习基本介绍
深度学习是机器学习的一个分支领域,它是一种基于对数据进行表征学习的方法。通过构建具有很多层(包括输入层、隐藏层和输出层)的神经网络模型,自动从大量的数据中学习复杂的模式和特征表示。例如,在图像识别中,深度学习模型可以从大量的图像数据中学习到不同物体的特征,如猫的形状、颜色、纹理等,从而能够准确地判断一张新图像中是否有猫。
- 核心概念
