TIDB执行计划
1、explain
使用 EXPLAIN 可查看 TiDB 执行某条语句时选用的执行计划。也就是说,TiDB 在考虑上数百或数千种可能的执行计划后,最终认定该执行计划消耗的资源最少、执行的速度最快。EXPLAIN 实际不会执行查询,EXPLAIN ANALYZE 可用于实际执行查询并显示执行计划,如果 TiDB 所选的执行计划非最优,可用 EXPLAIN 或 EXPLAIN ANALYZE 来进行诊断。
2、EXPLAIN返回结果介绍
EXPLAIN 的返回结果包含以下字段:
id:为算子名,或执行 SQL 语句需要执行的子任务。estRows:为显示 TiDB 预计会处理的行数。该预估数可能基于字典信息(例如访问方法基于主键或唯一键),或基于CMSketch或直方图等统计信息估算而来。task:显示算子在执行语句时的所在位置。access-object:显示被访问的表、分区和索引。显示的索引为部分索引。尤其是在有组合索引的情况下,该字段显示的信息很有参考意义。operator info:显示访问表、分区和索引的其他信息。
2.1、算子
算子是为返回查询结果而执行的特定步骤。真正执行扫表(读盘或者读 TiKV Block Cache)操作的算子有如下几类:
- TableFullScan:全表扫描。
- TableRangeScan:带有范围的表数据扫描。
- TableRowIDScan:根据上层传递下来的 RowID 扫描表数据。时常在索引读操作后检索符合条件的行。
- IndexFullScan(可相对提升效率):另一种“全表扫描”,扫的是索引数据,不是表数据。
- IndexRangeScan:带有范围的索引数据扫描操作。
TiDB 会汇聚 TiKV/TiFlash 上扫描的数据或者计算结果,这种“数据汇聚”算子目前有如下几类:
- TableReader:将 TiKV 上底层扫表算子 TableFullScan 或 TableRangeScan 得到的数据进行汇总。
- IndexReader(可相对提升效率):将 TiKV 上底层扫表算子 IndexFullScan 或 IndexRangeScan 得到的数据进行汇总。
- IndexLookUp(可相对提升效率):先汇总 Build 端 TiKV 扫描上来的 RowID,再去 Probe 端上根据这些
RowID精确地读取 TiKV 上的数据。Build 端是IndexFullScan或IndexRangeScan类型的算子,Probe 端是TableRowIDScan类型的算子。 - IndexMerge:和
IndexLookupReader类似,可以看做是它的扩展,可以同时读取多个索引的数据,有多个 Build 端,一个 Probe 端。执行过程也很类似,先汇总所有 Build 端 TiKV 扫描上来的 RowID,再去 Probe 端上根据这些 RowID 精确地读取 TiKV 上的数据。Build 端是IndexFullScan或IndexRangeScan类型的算子,Probe 端是TableRowIDScan类型的算子。 Point_Get和Batch_Point_Get:TiDB 直接从主键或唯一键检索数据时会使用Point_Get或Batch_Point_Get算子。这两个算子比IndexLookup更有效率。
2.1.1、算子的执行顺序
算子的结构是树状的,但在查询执行过程中,并不严格要求(但一般都是)子节点任务在父节点之前完成。TiDB 支持同一查询内的并行处理,即子节点“流入”父节点。父节点、子节点和同级节点可能并行执行查询的一部分。
Build 总是先于 Probe 执行,并且 Build 总是出现在 Probe 前面。即如果一个算子有多个子节点,子节点 ID 后面有 Build 关键字的算子总是先于有 Probe 关键字的算子执行。TiDB 在展现执行计划的时候,Build 端总是第一个出现,接着才是 Probe 端。

2.2、task
目前 TiDB 的计算任务分为两种不同的 task:cop task(TIKV执行) 和 root task(TIDB执行)。Cop task 是指使用 TiKV 中的 Coprocessor 执行的计算任务,root task 是指在 TiDB 中执行的计算任务。
SQL 优化的目标之一是将计算尽可能地下推到 TiKV 中执行。TiKV 中的 Coprocessor 能支持大部分 SQL 内建函数(包括聚合函数和标量函数)、SQL LIMIT 操作、索引扫描和表扫描。
2.3、operator info
EXPLAIN 返回结果中 operator info 列可显示诸如条件下推等信息。operator info 结果各字段解释如下:
range: [1,1]表示查询的WHERE字句 (a = 1) 被下推到了 TiKV,对应的 task 为cop[tikv]。keep order:false表示该查询的语义不需要 TiKV 按顺序返回结果。如果查询指定了排序(例如SELECT * FROM t WHERE a = 1 ORDER BY id),该字段的返回结果为keep order:true。stats:pseudo表示estRows显示的预估数可能不准确。
3、统计数据的健康度
EXPLAIN ANALYZE 执行时的 actRows 可能跟 estRows 差别很大,即跟实际值差别很大,可以先执行 ANALYZE TABLE 再执行 EXPLAIN ANALYZE,预估数与实际数会更接近。
ANALYZE TABLE xxx; EXPLAIN ANALYZE SELECT xxx;
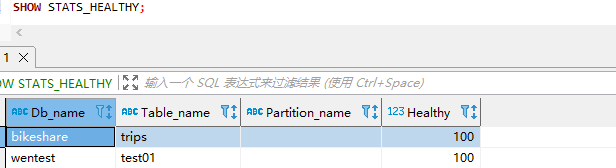
除 ANALYZE TABLE 外,达到 tidb_auto_analyze_ratio 阈值后,TiDB 会自动在后台重新生成统计数据。若要查看 TiDB 有多接近该阈值(即 TiDB 判断统计数据有多健康),可执行 SHOW STATS_HEALTHY 语句。
4、MPP模式(切分为多个 MPP片段进行查询)
TiDB 支持使用 MPP 模式来执行查询。在 MPP 执行模式下,SQL 优化器会生成 MPP 的执行计划。注意 MPP 模式仅对有 TiFlash 副本的表生效。
示例:
ALTER TABLE t1 set tiflash replica 1; ANALYZE TABLE t1; SET tidb_allow_mpp = 1;
7、Optimizer Hints控制执行计划
TiDB 支持 Optimizer Hints 语法,它基于 MySQL 5.7 中介绍的类似 comment 的语法,例如 /*+ HINT_NAME(t1, t2) */,当 TiDB 优化器选择的不是最优查询计划时,可以使用 Optimizer Hints 指定使用哪个执行计划。
7.1、语法
Optimizer Hints 不区分大小写,通过 /*+ ... */ 注释的形式跟在 SELECT、UPDATE 或 DELETE 关键字的后面,如果注释不是跟在指定的关键字后,会被当作是普通的 MySQL comment,注释不会生效。INSERT 关键字后不支持 Optimizer Hints。多个不同的 Hint 之间需用逗号隔开。
示例:
SELECT /*+ USE_INDEX(t1, idx1), HASH_AGG(), HASH_JOIN(t1) */ count(*) FROM t t1, t t2 WHERE t1.a = t2.b;
如果 Optimizer Hints 包含语法错误或不完整,查询语句不会报错,而是按照没有 Optimizer Hints 的情况执行。如果 Hint 不适用于当前语句,TiDB 会返回 Warning,用户可以在查询结束后通过 Show Warnings 命令查看具体信息。
7.2、 Hint分类
TiDB 目前支持的 Optimizer Hints 根据生效范围的不同可以划分为两类:
- 第一类是在查询块范围生效的 Hint,例如
/*+ HASH_AGG() */; - 第二类是在整个查询范围生效的 Hint,例如
/*+ MEMORY_QUOTA(1024 MB)*/。
每条语句中每一个查询和子查询都对应着一个不同的查询块,每个查询块有自己对应的名字。以下面这条语句为例:
SELECT * FROM (SELECT * FROM t) t1, (SELECT * FROM t) t2;
该查询语句有 3 个查询块,最外面一层 SELECT 所在的查询块的名字为 sel_1,两个 SELECT 子查询的名字依次为 sel_2 和 sel_3。其中数字序号根据 SELECT 出现的位置从左到右计数。TIDB规定 select 查询块以 sel 开头,DELETE 和 UPDATE 分别以 del、upd 开头,如果分别用 DELETE 和 UPDATE 查询替代上述第一个 SELECT 查询,则对应的查询块名字分别为 del_1 和 upd_1。
7.2.1、块范围生效的 Hint
这类 Hint 可以跟在查询语句中任意 SELECT、UPDATE 或 DELETE 关键字的后面。通过在 Hint 中使用查询块名字可以控制 Hint 的生效范围,以及准确标识查询中的每一个表(有可能表的名字或者别名相同),方便明确 Hint 的参数指向。若不显式地在 Hint 中指定查询块,Hint 默认作用于当前查询块。以如下查询为例:
SELECT /*+ HASH_JOIN(@sel_1 t1@sel_1, t3) */ * FROM (SELECT t1.a, t1.b FROM t t1, t t2 WHERE t1.a = t2.a) t1, t t3 WHERE t1.b = t3.b;
该 Hint 在 sel_1 这个查询块中生效,参数分别为 sel_1 中的 t1 表(sel_2 中也有一个 t1 表)和 t3 表。
如上例所述,在 Hint 中使用查询块名字的方式有两种:
- 第一种是作为 Hint 的第一个参数,与其他参数用空格隔开。除
QB_NAME外,本节所列的所有 Hint 除自身明确列出的参数外都有一个隐藏的可选参数@QB_NAME,通过使用这个参数可以指定该 Hint 的生效范围; - 第二种在 Hint 中使用查询块名字的方式是在参数中的某一个表名后面加
@QB_NAME,如上面的 t1@sel_1 用法,用以明确指出该参数是哪个查询块中的表。
7.3、QB_NAME(指定查询块的名称)
当查询语句是包含多层嵌套子查询的复杂语句时,识别某个查询块的序号和名字很可能会出错,Hint QB_NAME 可以方便我们使用查询块。QB_NAME 是 Query Block Name 的缩写,用于为某个查询块指定新的名字,同时查询块原本默认的名字依然有效。例如:
SELECT /*+ QB_NAME(QB1) */ * FROM (SELECT * FROM t) t1, (SELECT * FROM t) t2;
这条 Hint 将最外层 SELECT 查询块的命名为 QB1,此时 QB1 和默认名称 sel_1 对于这个查询块来说都是有效的。(注意,如果指定的 QB_NAME 为 sel_2,并且不给原本 sel_2 对应的第二个查询块指定新的 QB_NAME,则第二个查询块的默认名字 sel_2 会失效。)

