ElasticSearch的基本使用
1、ElasticSearch基本介绍
The Elastic Stack, 包括 Elasticsearch、Kibana、Beats 和 Logstash(也称为 ELK Stack)。能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。
Elasticsearch(简称 ES)是一个开源的、高扩展的、分布式的、提供多用户能力的全文搜索引擎,也是一个基于 Lucene 搜索的服务器,可以近乎实时地存储和搜索数据,是整个 Elastic Stack 技术栈的核心。ES 本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。
Elasticsearch 在 Java、.NET、PHP、Python、Apache Groovy、Ruby 等程序设计语言中都可以使用。
适用场景:
- ES适合数据量较大、复杂查询(查询自动可以是任意个字段,查询条件可以模糊或精确)的业务场景
- ES适合数据不频繁更新的业务场景,适合近实时的查询场景。
1.1、基本概念
1.1.1、集群(Cluster)
集群由一个或多个节点组成,共同提供索引和搜索功能。写请求由主分片处理,读请求主分片、副分片都可以处理。集群由唯一名称标识,默认情况下为“elasticsearch”。
1.1.2、节点(Node)
节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。一个节点是逻辑上独立的ES实例,表现为一个 ES 进程,它是集群的一部分。节点可分为多种角色,如主节点、数据节点、协调节点等。
- 主节点(Master node):主要 负责集群的元数据管理功能
- 数据节点(Data node):负责报错数据,执行数据的增删改查等操作
- 协调节点(Coordinating node):接收客户端请求,然后转发这些请求,收集数据并返回给客户端的节点
1.1.3、分片(Shard)
一个索引可以存储超出单个节点硬件限制的大量数据,比如,一个具有 10 亿文档数据的索引占据 1TB 的磁盘空间,而任一节点都可能没有这样大的磁盘空间,或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch 提供了将索引划分成多份的能力,每一份就称之为分片。
为了支持更大量的数据,索引一般会分成多个部分,每个部分就是一个分片。分片是 Elasticsearch 最小的工作单元。“分片”是Lucene的一个索引,它本身就是一个功能齐全的搜索引擎。分片被节点管理,一个节点一般会管理多个分片,这些分片可能是属于同一份索引,也有可能属于不同索引,但是为了可靠性和可用性,同一个索引的分片尽量分布在不同节点上。分片有两种,主分片和副本分片。
分片很重要,主要有两方面的原因:
- 允许你水平分割 / 扩展你的内容容量。
- 允许你在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量。
至于一个分片怎样分布,它的文档怎样聚合和搜索请求,是完全由 Elasticsearch 管理的, 对于作为用户的你来说,这些都是透明的,无需过分关心。
被混淆的概念是,一个 Lucene索引 我们在 Elasticsearch中称作分片,而一个 Elasticsearch 索引是分片的集合。 当 Elasticsearch 在索引中搜索的时候, 他发送查询到每一个属于索引的分片(Lucene 索引),然后合并每个分片的结果到一个全局的结果集。
1.1.4、副本(Replica)
副本是一个分片的备份数据,一个分片可能会有0个或多个副本,这些副本中的数据保证强一致或最终一致。
在一个网络 / 云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch 允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片(副本)。
复制分片之所以重要,有两个主要原因:
- 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与 原/主要(original/primary)分片置于同一节点上是非常重要的。
- 扩展你的搜索量/吞吐量,因为搜索可以在所有的副本上并行运行。
1.1.5、分段(segment)
每个分片包含多个“分段”,其中分段是倒排索引。分段内的doc数量上限是2的31次方。默认每秒都会生成一个segment文件。在分片中搜索将依次搜索每个片段,然后将其结果合并到该分片的最终结果中。
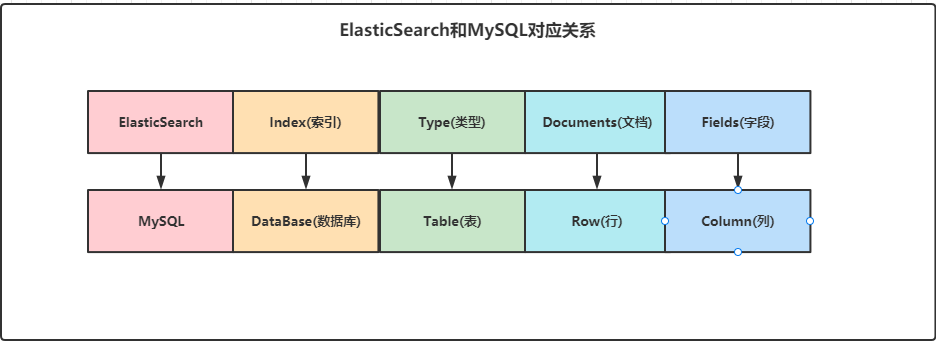
1.1.6、index(索引)
索引类似于 mysql 数据库中数据库的概念,数据库中有若干个表,那么ElasticSearch中则是创建一个索引。一个索引就是一个拥有几分相似特征的文档的集合。在一个集群中,可以定义任意多个索引。一个索引的数据文件可能会分布于一台机器,也有可能分布于多台机器。
一个索引就是一个拥有几分相似特征的文档的集合。比如说订单数据的索引,商品数据的索引。一个索引由一个名字来标识(必须全部是小写字母)。并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。
1.1.7、Type(类型,Elasticsearch 7.X 中该概念已被删除)
在一个索引中,你可以定义一种或多种类型。我们在ElasticSearch中存储数据时,是将数据存储在ElasticSearch中某个索引下的某个类型中的,对比MySQL的话就是我们将数据存储在MySQL某个库中的某个表中。在索引中可以定义多个Type。
(Types 的概念已经被逐渐弱化,Elasticsearch 6.X 中,一个 index 下已经只能包含一个type,Elasticsearch 7.X 中, Type 的概念已经被删除了。)

1.1.8、document(文档,json格式)
索引里单条记录称为文档,一个文档是一个可被索引的基础信息单元,也就是一条数据。文档以 JSON(Javascript Object Notation)格式来表示。在一个 index/type 里面,你可以存储任意多的文档。
文档类似于mysql数据库中的行,数据库插入一条数据和es插入一个JSON文档为相同概念。保存在ElasticSearch某个索引下的某个类型中的数据我们称为一个文档,文档的数据格式是JSON,类似于MySQL中某个数据库下某个表中的一条记录,是同一个意思。
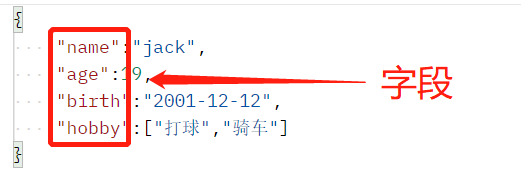
1.1.9、Field(字段,key)
数据表中的字段,即JSON键值对中的key,如下图:
1.1.10、映射(Mapping)
映射类似于关系型数据库中的表结构,定义了索引中字段的名称、类型等信息。
mapping 可以对处理数据的方式和规则方面做一些限制,如:某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的,其它就是处理 ES 里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
1.2、其他概念
1.2.1、分配(Allocation)
分配就是将分片分配给某个节点的过程,包括分配主分片或者副本。如果是副本,还包含从主分片复制数据的过程。这个过程是由 master 节点完成的。
1.2.2、低水位(Low watermark)
硬盘空间使用率阀值,达到这个值后,新索引的分片不会分配到这个节点 Node 上。
1.2.3、高水位(High watermark)
高水位硬盘空间使用率阀值,达到这个值后,会触发已分配到该节点的分片重平衡(rebalance)到其他节点上。
1.3、ES的默认分片副本数
总之,每个索引可以被分成多个分片,一个索引也可以被复制 0 次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定,在索引创建之后,你也可以在任何时候动态地改变复制的数量,但是在索引创建之后就无法再改变分片的数量。
(es7.0之前版本默认为一个索引创建5个分片,每个分片有1个副本。es7.0之后默认为一个索引创建1个分片,每个分片有1个副本。)
es7.0之前版本中,默认情况下,ES 会为每个索引分配5个主分片(即源数据分为5份)。对于每个主分片,Elasticsearch还会为其分配一个副本分片(replica shard)。这意味着,如果不进行任何配置,Elasticsearch会为每个索引分配5个主分片和5个副本分片,总共10个分片。这些分片会尽可能地分布在不同的节点上,以实现分布式存储和数据冗余。然而,实际情况取决于集群中的节点数量、索引的大小以及数据分布等因素,不一定总是能均匀地分布。需要注意的是,Elasticsearch的分片分配策略可以根据需要进行配置。可以通过修改Elasticsearch的配置文件或使用REST API来指定每个索引的主分片和副本分片数量。
PUT /my_index { "settings": { "number_of_shards": 3, "number_of_replicas": 2 } }
在上面例子中,我们创建了一个名为 my_index 的索引,并且设置了3个主分片,每个主分片2个副本,即总共 3*(2+1)副本 = 9 个分片。
1.4、Lucene和elasticsearch的区别
Lucene 是Apache 下的一个开源的全文检索引擎工具包,采用 Java 实现,它为软件开发人员提供一个简单易用的工具包(类库)。它提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene 的目的是为软件开发人员提供一个简单易用的工具包,以方便在目标系统中实现全文检索的功能。官方网站:http://lucene.apache.org/,下载地址:http://archive.apache.org/dist/lucene/java/
Elasticsearch 也是一个开源的搜索引擎,但它是一个分布式系统,能够处理大规模数据。它基于 Lucene 构建,但提供了更多的高级功能和更好的扩展性。Elasticsearch 通常与 Kibana 和 Logstash 一起使用,形成ELK堆栈,广泛应用于日志数据分析、实时监控等领域。
Lucene 和 Elasticsearch 的核心区别在于:Lucene是一个全文搜索引擎库,而Elasticsearch是一个基于Lucene构建的分布式搜索引擎。 Lucene是一个开源的全文索引与信息检索库,而Elasticsearch则是一个完整的搜索引擎系统,提供了更多的高级功能和更好的扩展性。
总结两者的优缺点:Lucene适合需要高度定制和控制的场景,因为它提供了底层的索引和搜索功能,但使用起来相对复杂。Elasticsearch则更适合需要快速部署和扩展的场景,因为它提供了更多的高级功能和更好的扩展性,但可能不如 Lucene 灵活。
2、ES的系统架构
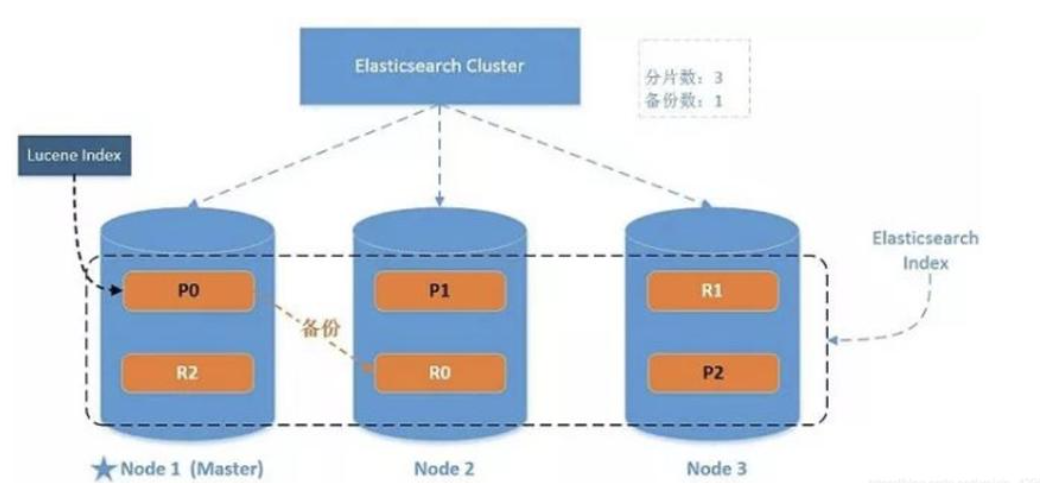
一个运行中的 Elasticsearch 实例称为一个节点,而集群是由一个或者多个拥有相同 cluster.name 配置的节点组成, 它们共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
当一个节点被选举成为主节点时, 它将负责管理集群范围内的所有变更,例如增加、 删除索引,或者增加、删除节点等,而主节点并不需要涉及到文档级别的变更和搜索等操作,所以当集群只拥有一个主节点的情况下,即使流量的增加它也不会成为瓶颈。 任何节点都可以成为主节点。
作为用户,我们可以将请求发送到集群中的任何节点 ,包括主节点。 每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。 无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回給客户端。 对于用户来说,Elasticsearch 这一切的管理都是透明的,无需关心。
3、Elasticsearch 下载安装
3.1、window版本单机下载安装
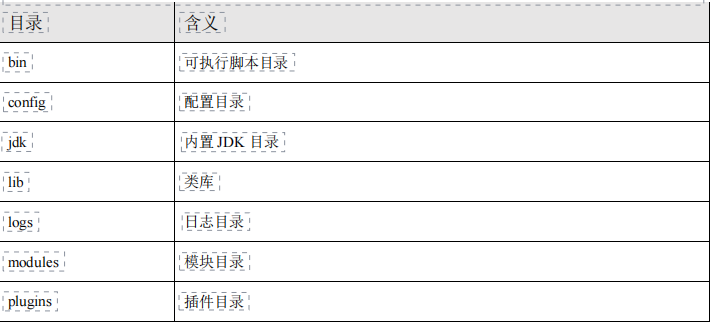
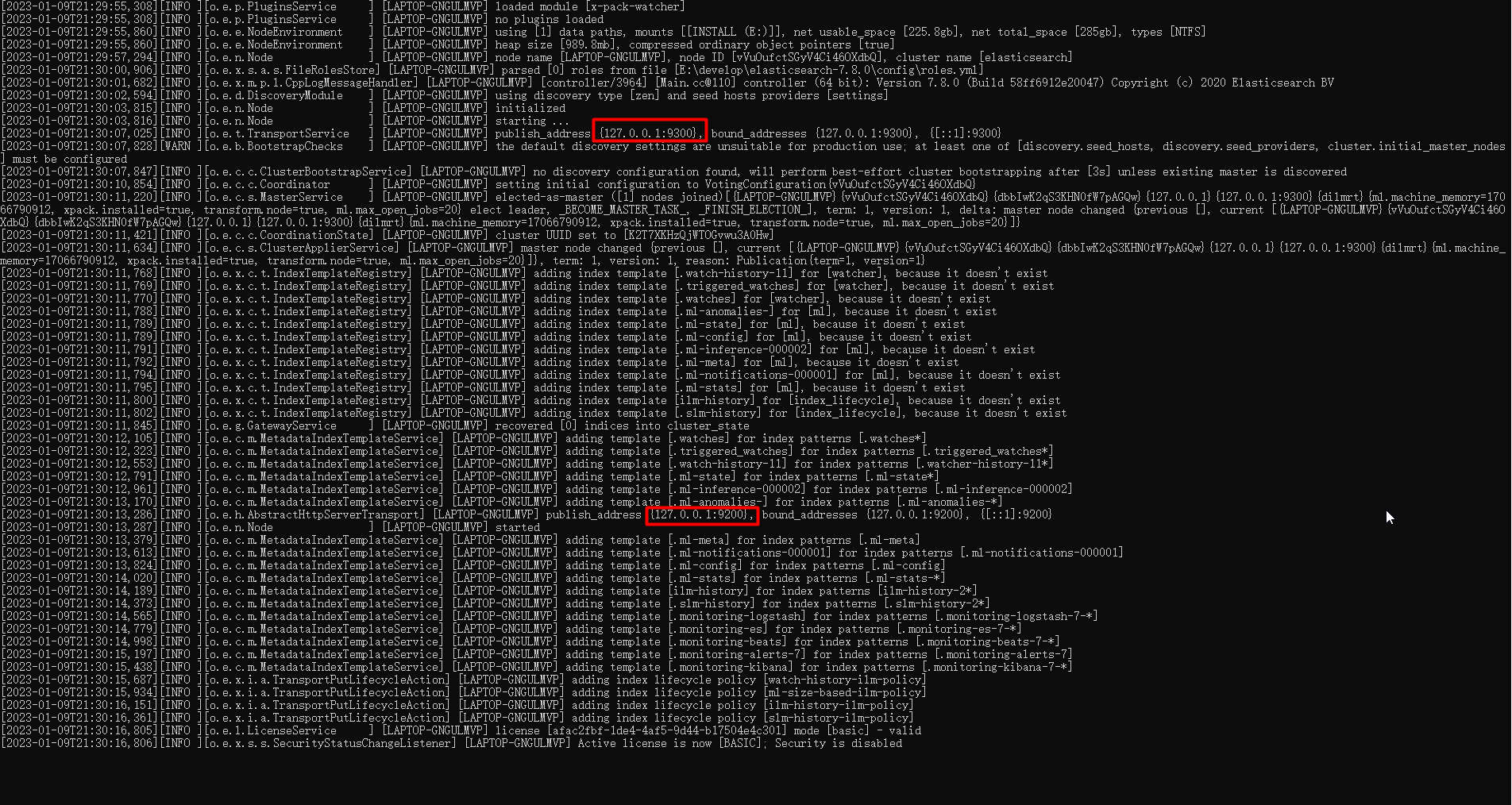
3.1.1、安装常见问题解决
- Elasticsearch 是使用 java 开发的,且 7.8 版本的 ES 需要 JDK 版本 1.8 以上,默认安装包带有 jdk 环境,如果系统配置 JAVA_HOME,那么使用系统默认的 JDK,如果没有配置使用自带的 JDK,一般建议使用系统配置的 JDK。
- 双击启动窗口闪退,通过路径访问追踪错误,如果是“空间不足”,请修改 config/jvm.options 配置文件。如下:
# 设置 JVM 初始内存为 1G。此值可以设置与-Xmx 相同,以避免每次垃圾回收完成后 JVM 重新分配内存 # Xms represents the initial size of total heap space # 设置 JVM 最大可用内存为 1G # Xmx represents the maximum size of total heap space -Xms1g -Xmx1g
3.2、Linux版本单机下载安装
先下载 window 的 7.8.0 版本使用。下载地址:https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-8-0
将下载的软件放到Linux系统并解压缩:tar -zxvf elasticsearch-7.8.0-linux-x86_64.tar.gz -C /opt/elasticsearch
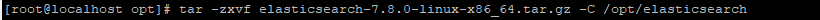
因为安全问题,Elasticsearch 不允许 root 用户直接运行,需使用其他用户启动 es,这里我们创建新用户 es。在 root 用户中创建新用户如下:
useradd es #新增 es 用户 passwd es #为 es 用户设置密码 userdel -r es #如果错了,可以删除再加 chown -R es:es /opt/elasticsearch/elasticsearch-7.8.0 #文件夹所有者
修改完目录所有者后可以看到目录的拥有者发生了变化,如下:

修改/opt/elasticsearch/elasticsearch-7.8.0/config/elasticsearch.yml 文件
# 加入如下配置 cluster.name: elasticsearch node.name: node-1 network.host: 0.0.0.0 http.port: 9200 cluster.initial_master_nodes: ["node-1"]
修改Linux系统的 /etc/security/limits.conf 文件
# 在文件末尾中增加下面内容 # 每个进程可以打开的文件数的限制 es soft nofile 65536 es hard nofile 65536
修改/etc/security/limits.d/20-nproc.conf
# 在文件末尾中增加下面内容 # 每个进程可以打开的文件数的限制 es soft nofile 65536 es hard nofile 65536 # 操作系统级别对每个用户创建的进程数的限制 * hard nproc 4096 # 注:* 带表 Linux 所有用户名称
修改/etc/sysctl.conf
# 在文件中增加下面内容 # 一个进程可以拥有的 VMA(虚拟内存区域)的数量,默认值为 65536 vm.max_map_count=655360
重新加载
sysctl -p
使用 ES 用户启动
#启动 /opt/elasticsearch/elasticsearch-7.8.0/bin/elasticsearch #后台启动 /opt/elasticsearch/elasticsearch-7.8.0/bin/elasticsearch -d
显示如下则表示启动成功:
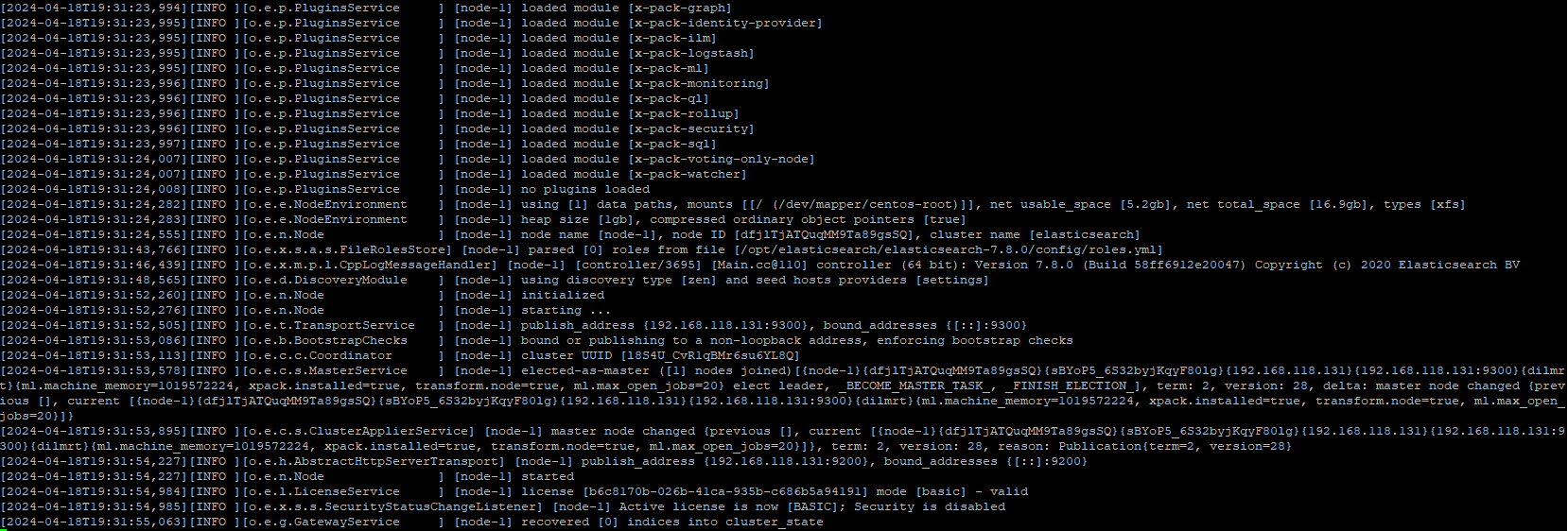
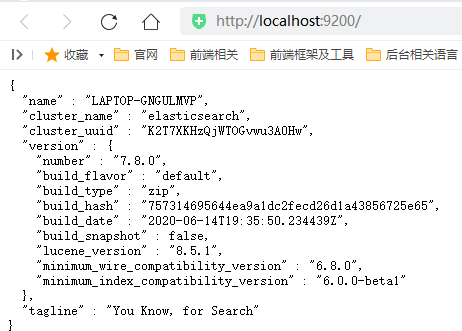
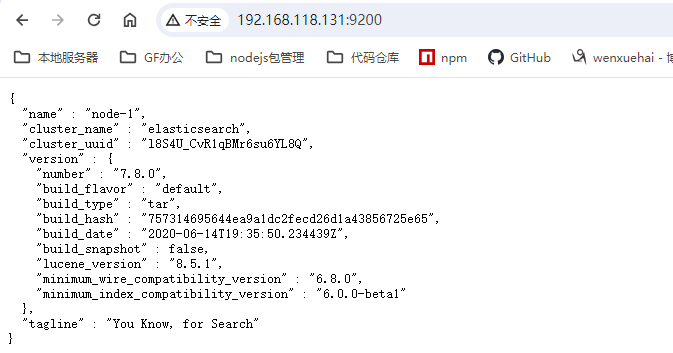
启动后可以在浏览器中输入地址:http://linux1:9200/ 访问,如下:(如果访问不通可能是端口未开通访问权限,可以临时关闭 Linux的防火墙:systemctl stop firewalld)
3.2.1、启动常见问题解决
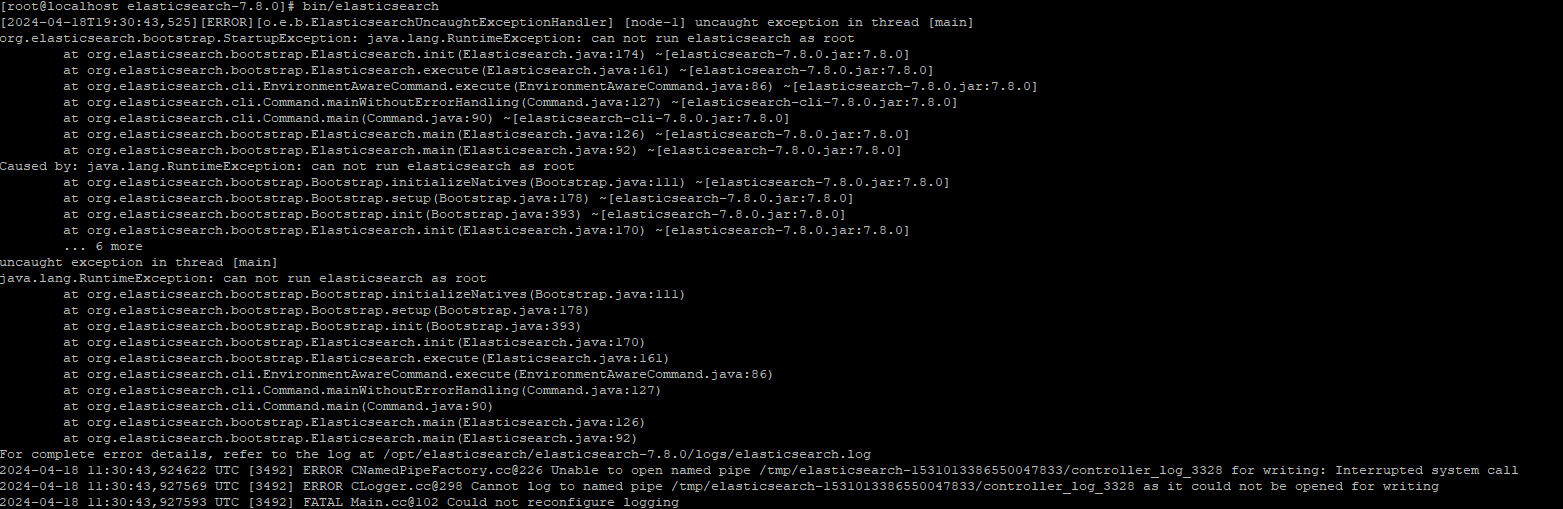
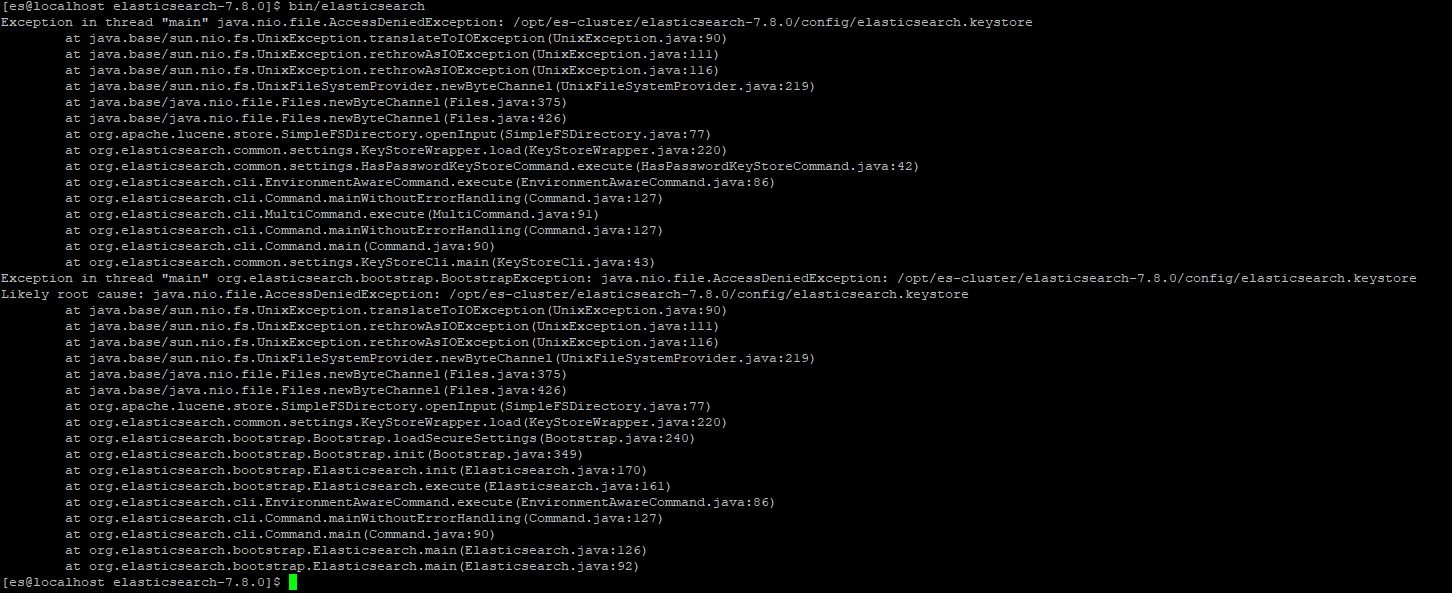
注意,如果以 root 用户启动会报错,如下,此时需切换为其他用户启动如 es 用户。
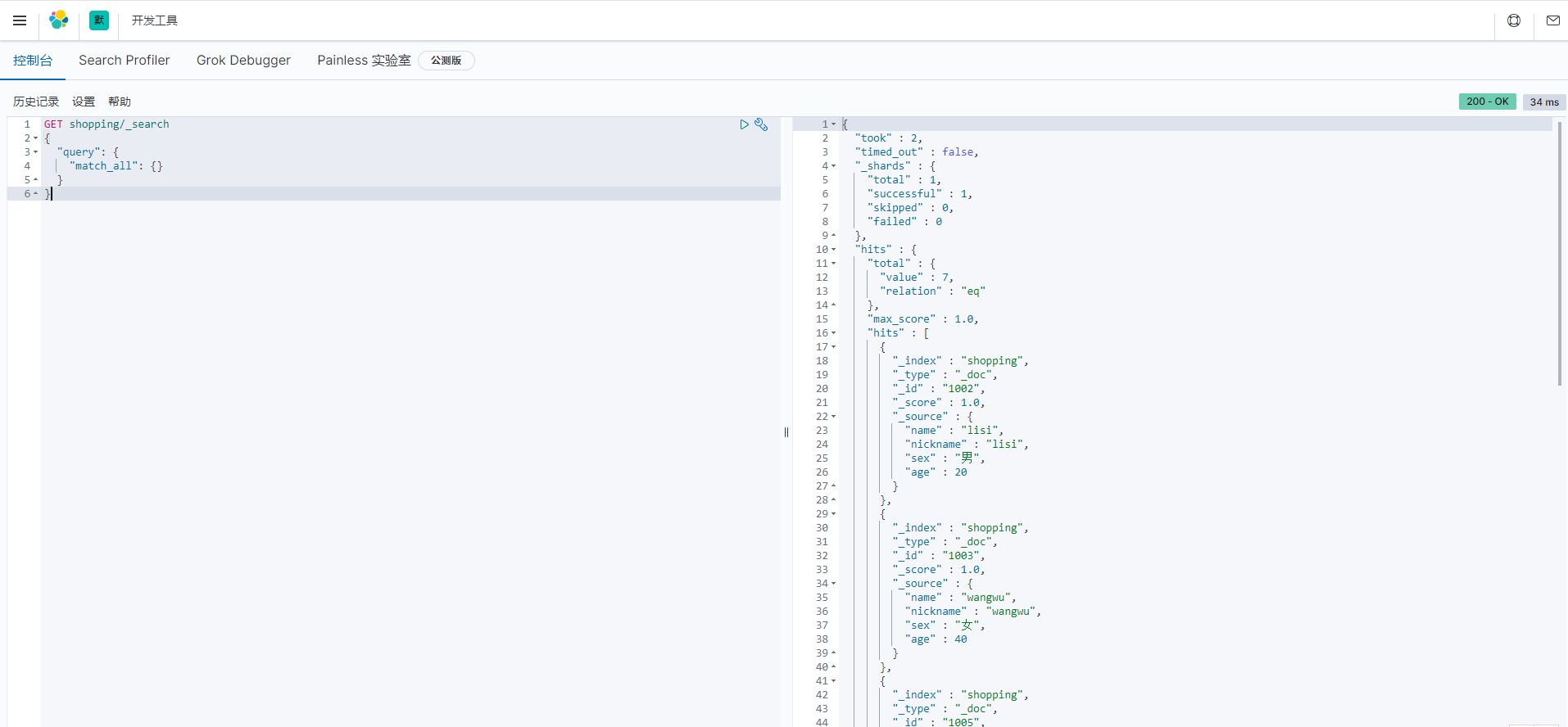
4、Kibana
4.1、安装使用
# 默认端口 server.port: 5601 # ES 服务器的地址 elasticsearch.hosts: ["http://localhost:9200"] # 索引名 kibana.index: ".kibana" # 支持中文 i18n.locale: "zh-CN"
3)Windows 环境下执行 bin/kibana.bat 文件。(首次启动有点耗时)
4)通过浏览器访问:http://localhost:5601 即可访问 kibana,如下: