MySQL的自定义函数和存储过程
1、MySQL的自定义函数(FUNCTION)
1.1、创建函数
MySQL 数据库创建函数(Function)的语法:
- CREATE FUNCTION func_name ( [func_parameter] ) -- 括号是必须的,参数是可选的
- RETURNS type
- [ characteristic ...] routine_body
说明如下:
- CREATE FUNCTION:用来创建函数的关键字
- func_name:函数名
- func_parameters:函数的参数列表,参数列表的形式为:[IN | OUT | INOUT] param_name type。IN:表示输入参数;OUT:表示输出参数;INOUT:表示既可以输入也可以输出;param_name:表示参数的名称;type:表示参数的类型,该类型可以是MySQL数据库中的任意类型;
- RETURNS type:函数返回数据的类型
- characteristic:指定存储函数的特性,取值与存储过程时相同
- routine_body:函数体。函数体由SQL代码构成,可以是简单SQL查询语句或者是复合结构SQL语句。函数体若是复合结构(多行代码)时,必须使用 begin...end 语句。复合结构可以包含声明、流程控制,需结合使用 delimiter 来转换(;)结束标识符。
函数体必须得有 return 语句,如果没有就会报错。return 语句可以不放在函数体的最后,但不建议这么做。函数体中如果只有一条语句,则可以不使用 begin...end 语句。
下面示例分别创建一个随机生成字符串和随机生成编号的函数,代码如下:

- -- 随机产生字符串
- drop function if exists rand_string; -- 先判断是否已存在同名函数,如果已存在则先删除
- DELIMITER $$ -- 两个 $$ 表示结束
- create function rand_string(n int) returns varchar(255)
- begin
- declare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
- declare return_str varchar(255) default '';
- declare i int default 0;
- while i < n do
- set return_str = concat(return_str, substring(chars_str, floor(1+rand()*52), 1));
- set i=i+1;
- end while;
- return return_str;
- end $$
- DELIMITER ;
- -- 随机生成编号
- drop function if exists rand_num;
- DELIMITER $$
- create function rand_num()
- returns int(5)
- begin
- declare i int default 0;
- set i=floor(100+rand()*10);
- return i;
- end $$
- DELIMITER ;
自定义函数的调用和其他普通函数的调用一样,示例如下:
- select rand_string(5);
- select rand_num();
结果示例如下:
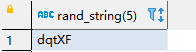
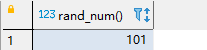
1.2、删除函数
删除函数的语句:
- drop function function_name;
- drop function [if exists] funcName; -- 可以加个判断,是否存在
- -- 示例:
- drop function if exists rand_num;
删除函数的语法只需写上函数名即可,函数的参数可以不用写出来。
1.3、delimiter(设置分隔符的关键字)
delimiter 是分隔符的意思,在 mysql 中默认的分隔符是分号(即 ; )。默认情况下,mysql 在遇到分号 ; 时,则认为该语句已结束,在回车后,mysql 就会执行该条语句。但有时候,可能我们并不希望这样。比如在创建自定义函数或者创建存储过程时,我们可能会输入多条语句,并且都带有分号,但此时我们并不希望 mysql 立即执行这些语句。此时我们可以通过 delimiter 关键字来将分隔符临时指定为其它符号,指定完后会在当前会话中有效。
语法为:
- DELIMITER 加你想指定为分隔符的字符
- -- 示例:
- DELIMITER $$ -- 指定 $$ 为分隔符
- DELIMITER // -- 指定 // 为分隔符
- DELIMITER ; -- 指定 ; 为分隔符
比如,创建自定义函数:
- DELIMITER $$ -- 先指定分隔符为 $$,其实可以指定为任意符号,比如 //、;;、@@等等
- create function rand_num()
- returns int(5)
- begin
- ...
- end $$ -- 以指定的分隔符结束
- DELIMITER ; -- 重新指定分号为分隔符
上面就是,先将分隔符设置为 $$, 直到遇到下一个 $$,才整体执行语句。执行完后在最后一行 delimiter ; 又重新将 mysql 的分隔符设置为分号,如果不修改的话,本次会话中的所有分隔符都以 $$ 为准。
1.4、创建函数时报错has none of DETERMINISTIC...
在创建函数时,MySQL可能会报以下错误:This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (you *might* want to use the less safe log_bin_trust_function_creators variable)
这是因为mysql 默认不允许创建自定义函数(安全性的考虑),此时我们需要将参数 log_bin_trust_function_creators 设置为开启状态。
可以通过以下命令查看 log_bin_trust_function_creators 参数:
- show variables like 'log_bin_trust_function_creators';
如下则为关闭状态:

执行以下命令将参数 log_bin_trust_function_creators 设置为开启状态:
- set global log_bin_trust_function_creators=1;
再次查看时即可以看到为开启状态:

但这样只是临时设置,重启终端后该设置即会失效。如果要配置永久的,需要在配置文件的 [mysqld] 上配置以下属性:
- log_bin_trust_function_creators=1
2、存储过程(procedure)
存储过程是一组可编程的函数,是为了完成特定功能的SQL语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数(需要时)来调用执行。
存储过程就是具有名字的一段代码,用来完成一个特定的功能。创建的存储过程保存在数据库的数据字典中。
使用存储过程的好处:
- 批量操作数据。存储过程可以将一些重复性很高的操作,比如批量插入数据、批量删除数据等,封装到一个存储过程中,简化了对这些SQL的调用。
- 批量处理:SQL+循环,减少流量,也就是“跑批”
- 统一接口,确保数据的安全
2.1、创建存储过程(create procedure)
创建语法:
- create procedure 存储过程名 ([params])
- BEGIN
- 存储过程体(一组合法的SQL语句)
- END
说明如下:
- 参数列表(params):如果有多个参数则用逗号 , 分隔开,一个参数包括三部分:参数模式、参数名、参数类型,如:in name varchar(20)。参数模式有:in 输入、out 输出、inout 输入输出参数。
- IN 参数:该参数作为输入,必须在调用存储过程时指定,在存储过程中修改该参数的值不能被返回,为默认值。仅需要将数据传入存储过程,并不需要返回计算后的该值。只能当做传入参数
- OUT 参数:该参数作为输出,该值可在存储过程内部被改变,并可返回。不接受外部传入的数据,仅返回计算之后的值。只能当做转出参数。也就是说,即使传值给 OUT 参数,该参数也无法得到你传的值,得到的会是一个 null 值。
- INOUT 参数:该参数即可作为输入,又可做为输出,也就是该参数既需要传入值,又可以返回值。可当做传入转出参数
如果存储过程体只有一条语句,则可以不用 begin...end。存储过程体中的每条 SQL 语句的结尾要求必须写分号。
示例如下:
- -- 创建一个循环往dept表插入数据的存储过程
- drop procedure if exists insert_dept;
- delimiter $$
- create procedure insert_dept(in start int(10),in max_num int(10)) -- start为起始,max_num为插入的数量
- begin
- declare i int default 0;
- set autocommit = 0;
- repeat
- set i = i+1;
- insert into dept(deptno,dname,loc) values((start+i),rand_string(10),rand_string(8));
- until i=max_num
- end repeat;
- commit; -- 循环之后,一次性commit,避免多次连接数据库。数据量太大的话可以改为多少条commit一次
- end $$
- DELIMITER ;
使用 call 关键字来调用存储过程,如下:
- CALL insert_dept(100, 5000);
2.2、删除存储过程(drop procedure)
删除语法如下:
- drop procedure [if exists] 存储过程名;
- -- 示例如下:
- drop procedure my_insert;
- drop procedure if exists my_insert; -- 先判断是否存在再删除
2.3、存储过程体的循环写法
存储过程体里面循环的写法主要有以下:
- -- 创建存储过程
- drop procedure if exists my_proc;
- delimiter $$
- create procedure my_proc()
- begin
- -- 第一种,while循环
- while i < 3 do
- select i;
- set i = i +1;
- end while;
- -- 第二种,repeat循环
- REPEAT
- select j;
- set j = j +1;
- UNTIL j > 3
- END REPEAT;
- -- 第三种,loop循环
- test_loop: LOOP
- select startDate;
- #开始时间加一天
- set startDate = DATE_FORMAT(date_add(startDate,interval 1 day),"%Y%m%d");
- IF startDate>endDate THEN
- LEAVE test_loop;
- END IF;
- END LOOP test_loop;
- end $$
- DELIMITER ;
如果有多个参数用","分割开


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
2020-02-24 Gerrit的基本使用