DQL基本语法2(查询)
下面的查询基于的表有:
- "Websites" 表:

- access_log表:

- students表:

1、多表查询
1.1、基本查询(笛卡尔积)
SELECT查询不但可以从一张表查询数据,还可以从多张表同时查询数据。
查询多张表的语法:
select * from 表1, 表2; # 示例: SELECT * FROM websites, access_log;
查询结果类似:

上面查询出来的将是 access_log 和 websites 表的笛卡尔积,也就是 access_log 表的每个记录分别跟 websites 表的所有记录的组合。 结果集的列数是 access_log 表和 websites 表的列数之和,行数是 access_log 表和 websites 表行数之积。比如 a 表有 2 条数据,每条数据有 3 个字段,b 表有 4 条数据,每条数据有 5 个字段,则笛卡尔积的结果将有 2*4 = 8 条数据,并且每条数据将有 3+5=8 个字段。
在多表查询时,不同表之间可能有相同的列名称,此时我们应该通过 “表名.列名” 的方式来区别不同表之间的列,或者也可以直接给表起别名,通过 “表别名.列名” 的方式来区分:
SELECT w.id, w.NAME, a.aid, a.site_id FROM websites w, access_log a;
查询结果类似:

JOIN的含义就如英文单词“join”一样,连接两张表,大致分为内连接,外连接,右连接,左连接,自然连接。

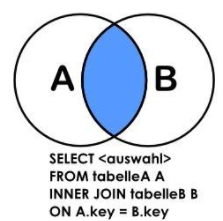
1.2、内连接(交集、INNER JOIN或JOIN)
内连接INNER JOIN是最常用的连接操作,从数学的角度讲就是求两个表的交集。实际上就是在两个表的笛卡尔积中,通过 on 条件过滤结果。
select 字段列表 from 表1 [inner] join 表2 on 条件 -- inner可省略不写
示例:
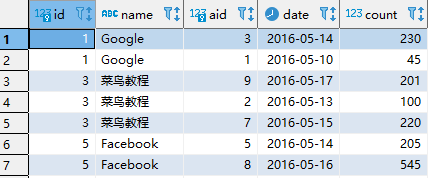
SELECT a.id, a.name, b.aid, b.date FROM websites a INNER JOIN access_log b ON a.id = b.site_id; -- 内连接语法可以用where替代,等价于上面语句,可以称为隐式内连接 SELECT a.id, a.name, b.aid, b.date FROM websites a, access_log b WHERE a.id = b.site_id;
查询结果:

1.2.1、内连接的 on 和 where 条件是等价的
实际上 inner join 中的 on 的条件都可以写在 where 里,两者的结果是一样的。这是因为使用 inner join 时需两表条件同时满足才能查询出来,跟写在 where 里效果是一样的。但需注意,left join 这么写两者的结果是不等价的。
-- inner join 条件都写在 on 后面 select a.id, a.name, b.aid, b.date, b.count from websites a inner join access_log b on a.id = b.site_id and b.count > 40 order by a.id asc; -- 等价于inner join 条件部分写在on后,部分写在where里 select a.id, a.name, b.aid, b.date, b.count from websites a inner join access_log b on a.id = b.site_id where b.count > 40 order by a.id asc -- 也等价于inner join 条件全部写在where里 select a.id, a.name, b.aid, b.date, b.count from websites a inner join access_log b where a.id = b.site_id and b.count > 40 order by a.id asc
以上三种写法查询结果均如下:
1.3、左连接(LEFT JOIN)
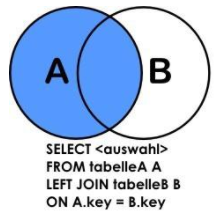
1.3.1、左外连接(常用)
左外连接LEFT JOIN的含义就是求两个表的交集外加左表剩下的数据。实际上就是从两个表的笛卡尔积中,先通过 on 条件过滤结果,然后再加上左表中所有剩余的记录即可。(也就是说,最终会将左表中不符合 on 条件的记录也一并加上,实际上也就是左表中的所有记录都会存在于最终结果中)
select 字段列表 from 左表 left join 右表 on 条件;
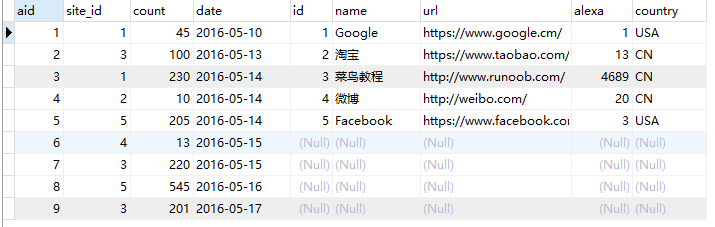
示例,下面以 access_log 为左表,websites 为右表:
SELECT * FROM access_log LEFT JOIN websites ON access_log.aid=websites.id;
查询结果:
1.3.2、左外连接的 on 和 where 条件非等价
在 left join中,条件写在 on 里和写在 where 里结果是不一样的。on 条件是先对表做过滤再关联,而 where 是先关联查询结果后再过滤,当使用左或右关联时,两者的结果是不一样的,这跟 inner join的表现不同。
示例如下:
-- 语句1
select * from access_log lg left join websites web on lg.aid = web.id and web.country = 'CN' order by lg.aid asc -- 并不等价于以下语句2 select * from access_log lg left join websites web on lg.aid = web.id where web.country = 'CN' order by lg.aid asc
- 语句1结果如下,可以看到是先过滤再关联,左表所有记录都会保留
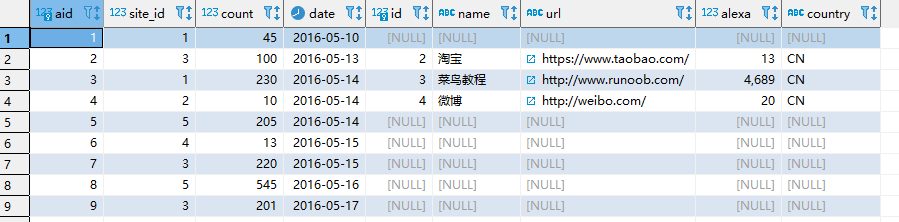
- 语句2结果如下,可以看到是先得到关联的查询结果后再做整体过滤,数据量少很多

1.3.3、左外连接转inner join
使用左外连接时,当where条件里对被关联表(右表)做了过滤,left join 有可能可被等价转换转成 inner join。比如对右表的某列做 != 'xx' 或 = 'xx' 的过滤条件,保证了右表记录非NULL,此时就可以用 inner join代替。
select * from access_log lg left join websites web on lg.aid = web.id where web.country != 'CN' order by lg.aid asc -- 等价于直接用 inner join select * from access_log lg inner join websites web on lg.aid = web.id and web.country != 'CN' order by lg.aid asc
注意,必须是在 where 条件里对右表做过滤时才可转为 inner join,如果是对左表做过滤则不能转换。
1.3.4、左连接(A LEFT JOIN B ON A.KEY = B.KEY WHERE B.KEY IS NULL)
左连接LEFT JOIN 是左外连接中,只保留那些不属于两个表的交集的数据。实际上就是从两个表的笛卡尔积中,先通过 on 条件过滤结果,然后再加上左表中所有剩余的记录,然后再去掉两表中交集的部分。
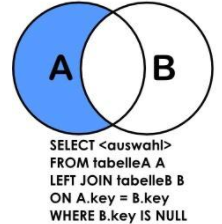
也就是相当于是上面的左外查询中只保留红框框起来的数据:
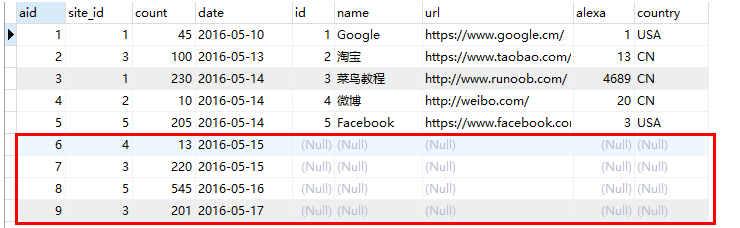
1.4、右连接(RIGHT JOIN)
1.4.1、右外连接(常用)
同理,右连接RIGHT JOIN就是求两个表的交集外加右表剩下的数据。实际上就是从两个表的笛卡尔积中,先通过 on 条件过滤结果,然后再加上右表中所有剩余的记录即可。(也就是说,最终会将右表中不符合 on 条件的记录也一并加上,实际上也就是右表中的所有记录都会存在于最终结果中)
select 字段列表 from 左表 right join 右表 on 条件
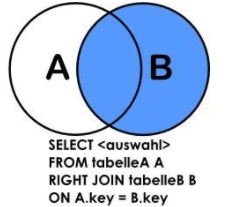
示例,下面以 websites 为左表,access_log 为右表:
SELECT * FROM websites RIGHT JOIN access_log ON access_log.aid=websites.id;
查询结果:
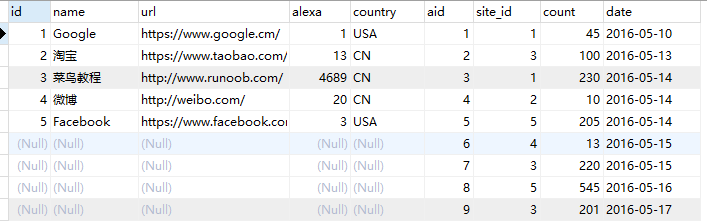
1.4.2、右连接(A RIGHT JOIN B ON A.KEY = B.KEY WHERE A.KEY IS NULL)
右连接RIGHT JOIN 是右外连接中,只保留那些不属于两个表的交集的数据。实际上就是从两个表的笛卡尔积中,先通过 on 条件过滤结果,然后再加上右表中所有剩余的记录,然后再去掉两表中交集的部分。
也就是上面的左外查询中只保留红框框起来的数据:
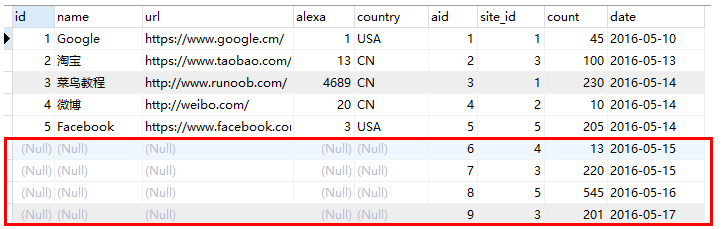
1.5、全外连接
全外连接:左表和右表都不做限制,所有的记录都显示,两表不足的地方用null 填充。全外连接= 左表全部记录+右表全部记录+相关联结果 = 左外连接+右外连接-相关联结果(即去除重复)
(请注意,图中 full outer join 语法在 mysql 中是不支持使用的)
在 mysql 里全外连接的sql语句就是 union 左外连接和右外连接的结果。请注意不是 union all,而是使用了 union,union 会自动去除重复结果。
SELECT * FROM table1 LEFT JOIN table2 ON (table1.id = table2.id) UNION SELECT * FROM table1 RIGHT JOIN table2 ON (table1.id = table2.id)
示例:
SELECT * FROM access_log LEFT JOIN websites ON access_log.aid=websites.id UNION SELECT * FROM access_log RIGHT JOIN websites ON access_log.aid=websites.id;
查询结果如下:(下面我额外给websites表添加了一条 id为15的记录,以便观察右外连接的结果)
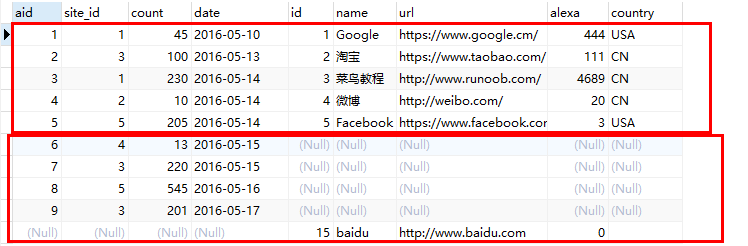
1.6、两表独有的数据集
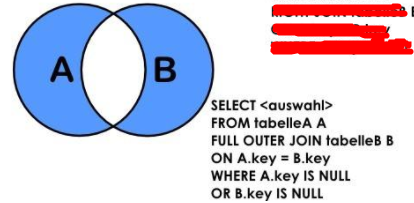
(请注意,图中 full outer join 语法在 mysql 中是不支持使用的)
在mysql中就是union了左连接和右连接
SELECT * FROM table1 LEFT JOIN table2 ON (table1.id = table2.id) WHERE table2.id IS NULL UNION SELECT * FROM table1 RIGHT JOIN table2 ON (table1.id = table2.id) WHERE table1.id IS NULL
示例:
SELECT * FROM access_log LEFT JOIN websites ON access_log.aid=websites.id where websites.id is null UNION SELECT * FROM access_log RIGHT JOIN websites ON access_log.aid=websites.id where access_log.aid is null;
查询结果如下:(下面额外给websites表添加了一条 id为15的记录,以便观察右连接的结果)

2、子查询
子查询允许把一个查询嵌套在另一个查询当中。
2.1、where型子查询
where 型子查询把内层查询结果当作外层查询的比较条件。
如果内层查询返回一个标量值(就一个值),那么外部查询就可以使用比较符,比如:=、>、<、>=、<=和<>符号进行比较判断。
比如下面查询 count 值最大的相关信息:
SELECT *
FROM access_log
WHERE count = (SELECT MAX(access_log.count) FROM access_log);
查询结果:

如果子查询返回的不是一个标量值,而是一个N行单列的结果集,但外部查询使用了比较符和子查询的结果集进行比较,此时会抛出异常。
如果子查询返回的不是一个标量值,而是一个N行单列的结果集,此时可以使用 IN、ANY、SOME 和 ALL 操作符,不能直接使用 = > < >= <= <> 这些比较标量结果的操作符。
SELECT * FROM websites WHERE id IN (SELECT id from websites WHERE country = 'CN');
2.2、from型子查询
from 型子查询把内层的查询结果当成临时表,供外层sql再次查询。当子查询返回的结果是多行多列时,子查询的结果集可以当成表看待,一般要给这个临时表起一个别名,否则临时表没有名称则无法访问临时表中的字段。
SELECT * FROM (SELECT id,`name`,alexa FROM websites WHERE country = 'CN') temp WHERE temp.alexa > 15;

