


分库分表
1、为什么要分库分表
当一张表的数据达到几千万时,查询一次所花的时间会变长。这时候,如果有联合查询的话,可能会卡死在那儿,甚至把系统给拖垮。
而分库分表的目的就在于此:减小数据库的负担,提高数据库的效率,缩短查询时间。另外,因为分库分表这种改造是可控的,底层还是基于RDBMS,因此整个数据库的运维体系以及相关基础设施都是可重用的。去中心化。
2、分库分表的手段有哪些?
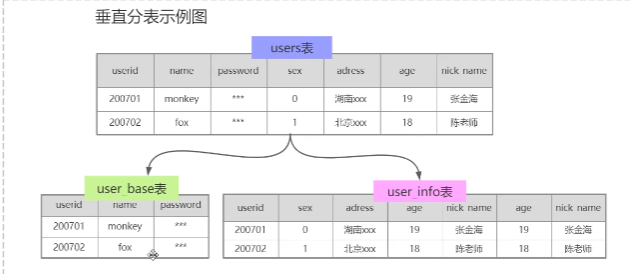
1)垂直分表,按照业务,比如一张user表,userbase表做登录用,userinfo表做个人信息修改用
2)垂直分库,按照业务来,订单信息都在一个库,用户信息都在一个库,商品信息都在一个库
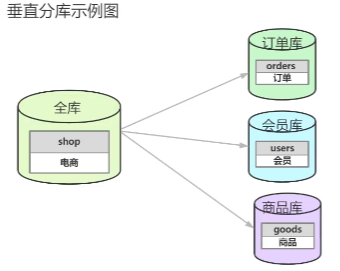
垂直拆分的特点:每个库每个表的结构都不一样;每个库每个表的数据至少一列一样;每个库每个表的并集是全量数据。
优点:拆分后业务清晰,数据维护简单,按照不同业务放到不同的机器上。
缺点:
一:如果的单表的数据量大,那么单表的读写压力依然比较大。
二:受某种业务的影响到库的瓶颈,比如双11,订单业务会大量新增,其他会员库和商品库查找多
三:部分业务无法直接关联join,只能通过java接口去调用,提供了开发的复杂度。比如双11订单表上面商品价格是20元,
然后过了双11商品表的价格是25,我们查订单信息不能直接join。
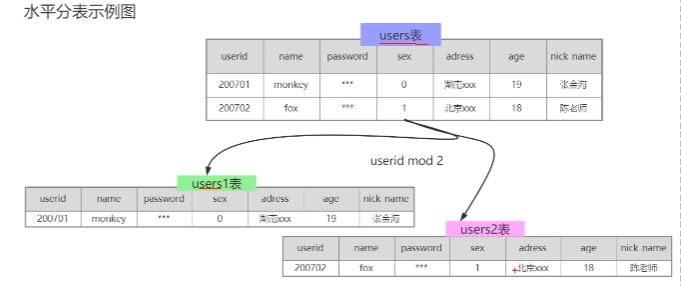
3)水平分表:将id通过运算,哈希,把数据分散在不同表。比如奇数id放在user1表,偶数id放在user2表。
4)水平分库:将id通过运算,哈希,把数据分散在不同库。比如奇数id放在user1表,偶数id放在user2表。
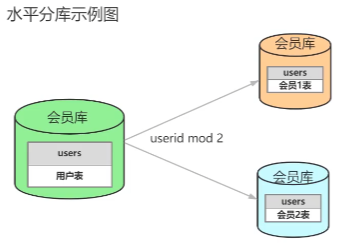
水平拆分特点:每个库(表)的结构都一样;每个库(表)的数据都不一样;每个库(表)并集是全部数据。
优点:一、单表的数据保有量减少,有助于性能的提高。
二、提高了系统的稳定性和负载能力。
三、拆分表的结构相同,程序代码改动的较少
缺点:一、数据扩容再新增库难度大
二、拆分规则很难抽象出来
三、分片事务的一致性问题部分业务无法关联join,只能通过java程序去调用。
3、分库分表带来的问题
1)分布式事务一致性,传统的acid
2)分布式全局唯一id
3)跨库join查询
4)开发成本大,对程序员要求高。
开源框架:
jdbc直连层:
shardingsphere.tddl
proxy代理层:可以跨语言
mycat、mysql-proxy(360)

