
| 项目 | 内容 |
|---|---|
| 课程班级博客链接 | https://edu.cnblogs.com/campus/xbsf/2018CST |
| 这个作业要求链接 | https://www.cnblogs.com/nwnu-daizh/p/14604444.html |
| 我的课程学习目标 | (1)对D{0-1}KP问题加深理解 (2)运用至少一门语言构造图形用户界面 (3)了解并熟悉遗传算法 (4)在结对合作过程中获得除知识外其他能力 |
| 这个作业在哪些方面帮助我实现学习目标 | (1)在结对合作的过程中认识自我的不足,积极吸取他人的长处 (2)通过对不了解的知识内容进行学习,提升自己的编程能力的同时也对自我学习的要求有高层次要求 |
| 结队方学号-姓名 | 于泽浩-201871030139 |
| 结对方本次博客作业链接 | https://www.cnblogs.com/yuzehao/p/14652203.html |
| 本项目Github的仓库链接地址 | https://github.com/xwt721/SoftwareProject |
任务1:阅读《现代软件工程——构建之法》
第3章 软件工程师的成长
3.2 软件工程师的思维误区
在阅读了《现代软件工程——构建之法》第三章第二节时,首先介绍的例子是以工程师果冻和项目经理大牛之间的对话为例:木桶有洞怎么办?修哇!怎么修?用粗麻绳堵住!绳子太粗怎么办?砍短!刀太钝怎么办?磨刀!磨刀石太干怎么办?用木桶取水!木桶有洞怎么办?......如此便陷入死循环,出现了“分析麻痹”的现象。
分析麻痹:一种极端情况是想弄清楚所有细节、所有依赖关系之后再动手,心理上过于悲观,不想修复问题,出来了问题都赖在相关问题上。分析太多,腿都麻了,没发起步前进,故得名“分析麻痹”(Analysis Paralysis)
-- 引用《现代软件工程——构建之法》3.2 软件工程师的思维误区(P53)
其次介绍的例子是小飞的故事,小飞要骑自行车上自习,但是最终导致的结果是追着牦牛跑这就产生了“部分主次,想解决所有依赖问题”。拿例子来说,小飞上自习一定要骑自行车去吗?大可不必!他可以不解决自行车没气的问题转而选择徒步去上自习。所以,这种解决问题真的可以”完美“达成与设定目标吗?恐怕不是,而是会造成更多不必要的麻烦。
不分主次,想解决所有依赖问题:另一种极端是过于积极,想马上动手修复所有主要和次要的依赖问题,然后就可以“完美地”达成最初设定的目标,而不是根据现有条件找到一个“足够好”的方案。
-- 引用《现代软件工程——构建之法》3.2 软件工程师的思维误区(P53)
接着还是以小飞同学为例,在上学的时候小飞的雨伞就很小,因为雨伞很小导致小李拒绝和小飞共同打伞,但是小飞的初心是希望离小李更近,而小李却觉得伞太小,所以没答应。几年后,误会解除,小飞才恍然大悟“过早优化是一切烦恼的根源”。这个例子是告诉我们不要先入为主,自以为是,最终导致的结果却是竹篮打水一场空。
过早优化:既然软件是“软”的,那它就有很大的可塑性,可以不断改进。放眼望去,一个复杂的软件似乎很多模块都可以变得更好。一个工程师在写程序的时候,经常容易在某一个局部问题上陷进去,花大量时间对其进行优化,无视这个模块对全局的重要性,甚至还不知道这个“全局”是怎么样的。这个毛病早就被归纳为“一切罪恶的根源”。
-- 引用《现代软件工程——构建之法》3.2 软件工程师的思维误区(P54)
最后一个例子不是以一个小故事刚展开,而是以侯宝林的经典相声——《画扇面》为例,《画扇面》大概讲的的内容是,甲买了一把白色扇子,乙帮忙画,结果从美女->张飞->山水->全黑,在经历了这些过程后,白扇子硬是变成了黑扇子。也就是说目标设定的过于宏大,并没有考虑自己是否可以真正的完成,结果一不小心,最初的目标都无法完成,造成更大的损失。
以《画扇面》与“做软件工程团队项目”做对比,对项目的期望值原本很高,不考虑实际情况,导致最终什么也没做出来,只能以写PPT结尾,项目烂尾。所以在一开始的时候就应该定一个切合实际的目标,在完成这项目标过后再逐步求精,一步一步完成,做到“上不封顶,下要保底”。
过早扩大化/泛化( Premature Generalization):软件的“软”还表现在它可以扩展。在写一个程序的时候,需要某个函数可以处理整数类型和字符串类型的信息,有的程序员往往灵光闪现——哎、能不能把类型抽象出来,让这个函数处理所有可能的类型?这样不就一劳永逸了么?有些软件本来是解决一个特定环境下的具体问题。有的程序员一想,我们能不能做一个平台,处理所有类似的问题,这样多好啊!这样的前景的确美妙,程序员的确需要这样的凌云壮志,但是要了解必要性、难度和时机。“画扇面”就是一个很好的例子。
-- 引用《现代软件工程——构建之法》3.2 软件工程师的思维误区(P54)
3.3 软件工程师的职业发展
人们对待职业的态度等级:
1.临时的寄托或工作(Temporary Work)
在大学里你会看到很多人选IT专业的原因和“热爱”没有什么关系,有些人是因为专业调剂来到这里,有些人是因为要拿一个文凭作为敲门砖(例如,跨专业考上软件专业的研究生、然后计划以硕士的资格去考公务员),有些人是临时找到这样一份工作,并不打算做长久。他们处于低动力、低技能的状态。
2.工作(Job)
这就是一个能挣钱养家的营生、如果别的营生更赚钱、那就会跳到别的地方去。一些人留在这个职业里。只不过是因为他不会做别的。这些人会经常问“软件开发做到35岁以后怎么办”这样的问题。当然,如果了解和体会了软件开发的投入和回报的关系,这些人的心态会进步到下一个阶段。
3.职业(Profession )
在工作的基础上,如果有足够的职业道德和职业规划、那么工作就是一个“职业”。只有在这个层次上可以开始谈有意义的“舆业发展”。职业人士对“30岁以后”、“35岁以后”都有一定的打算。
4,投身的事业( Commitment / vocation )
把软件项目相关的目标作为长期的承诺,碰到困难也不退缩,一直坚持到完成任务。
5.理想的呼唤( Calling )
一些人觉得这是理想的呼唤,通过软件可以改变世界,他们主动寻找机会,实现自己的理想。
-- 引用《现代软件工程——构建之法》3.3 软件工程师的职业发展(P57)
对于专业是否是自己的寄托、工作、职业、想要投身的事业或者理想呼唤这个问题只有自己清楚,也只有自己能感受到,如何从中转变也是依据自己的成长经历、社会阅历等方面,如果我们对职业有认真的态度,就能发现很多证明个人能力的方式。
3.4 技能的反面
作者以自己小学五年级玩魔方为例,通过熟背口诀在当时的学生界很受欢迎并且称得上“精通”。几年过去后,虽然口诀还记得,但是在转到最后一层魔方后却想不起来口诀。也就是说,在玩魔方方面,作者只是简单的记住口诀,并没有真正的理解,这就导致了只能“独立地还原一面,其他看口诀可搞定”。这还值得称为“技能”吗?
技能的反面是解决问题(Problem Solving)
-- 巴克斯顿
对于巴克斯顿所说的问题,再结合例子,我的理解是:在某个人表现为不精通某项技能时候会考虑如何让自己“精通”,这就涉及到了“解决问题”的过程,在解决的过程中又会涉及到先要解决最底层的问题,如果底层问题无法解决的话,那么如何解决更高层次的问题呢?“技能”与“精通”是一个相辅相成的两个词语,对于一个面试者来说,当他说他拥有某项技能,说明他对这项技能拥有很强的熟练程度,所以我建议在简历上还是不要在技能一栏中写自己不熟练的活动内容。
第四章 两人讨论
4.1 代码规范
如何判断一个代码是“好”还是“不好”。如下图所示代码

-- 引用《现代软件工程——构建之法》4.1 代码规范(P69)
读者在看上图所示代码时会感觉读不下去,这样的代码虽然机器可以识别,可以编译并且执行,但是读者在看的时候会感觉不太舒服,感觉很乱,这就要求在代码风格、设计上面下功夫。
4.2 代码风格规范
代码风格规范包含缩进、行宽、括号、断行与空白的{}行、分行、命名、下划线、大小写、注释。
-
缩进
如何缩进,缩进几个空格?这些是需要统一的,一般用Tab键缩进4个空格。
-
行宽
行宽必须限制,但是以前有些文档规定的80字符行宽太小了,现在时代不同了,可以限定为100字符。
-
括号
在复杂的条件表达式中,用括号清楚地表示逻辑优先级。
-
程序的结构风格
1.最简格式A
if (condition) DoSomething();
else DoSomethingElse();
2.断行结构B
if (condition)
DoSomething();
else
DoSomethingElse();
3.用“{“和”}”来判断程序的结构,改进的结构C
if (condition){
DoSomething();
}else{
DoSomethingElse();
}
4.“{”和“}”独占一行结构D
if (condition)
{
DoSomething();
}
else
{
DoSomethingElse();
}
-
分行
不要把多条语句放在一行上,如:
a = 1; b = 2; //bogus
if (fFoo) Bar(); //bogus
更严格地说,不要把多个变量定义在一行上,如:
Foo foo1, foo2; //bogus
-
命名
变量命名一般要符合的规则是“看名知意”,也就是说看到这个变量的命名,就可以知道这个变量名是做什么的。
命名的建议:
- 在变量名中不要提到类型或其他语法方面的描述。例如一个表示全年假日的列表变量,不用写arraylist0fHolidays,可以直接写holidays;
- 避免过多的描述。例如一个变量是游戏中最后出现的“大 boss”,不用写theFinalBattleMostDangerousBossMonster,可以直接写boss;
- 如果信息可以从上下文中得到,那么此类信息就不必写在变量名中。例如一个类叫EmployeeHealthRecord,它有一个员工姓名的变量,可以直接是“name”,而不必写employeeName;
- 避免可要可不要的修饰词。例如state,data,value,engine,entity,instance,object,manager,可以问自己.如果在变量名中把这些字都去掉,程序会更加难懂么?如果答案是否定的,那么可以把这些修饰词都去掉。
-
下划线
下划线用来分隔变量名字中的作用域标注和变量的语义,如:一个类型的成员变量通常用"m"表示,或者简单地用一个下划线“_”来做前缀。移山公司规定下划线一般不用在其他方面。
-
大小写
由多个单词组成的变量名,如果全部都是小写,很不易读,一个简单的解决方案就是用大小写区分它们。
Pascal——所有单词的第一个字母都大写。
Camel——第一个单词全部小写,随后单词随Pascal形式,这种方式也叫 lowerCamel。
一个通用的做法是:所有的类型/类/函数名都用Pascal 形式,所有的变量都用Camel形式。类/类型/变量:名词或组合名词,如 Member 、ProductInfo等。
函数则用动词或动宾组合词来表示、如l get/set 、RenderPage( )。
-
注释
复杂的注释应该放在函数头,很多函数头的注释都用来解释参数的类型等,如果程序正文已经能够说明参数的类型in/out,就不要重复!
注释也要随着程序的修改而不断更新,一个误导的(Misleading )注释往往比没有注释更糟糕。另外,注释(包括所有源代码)应该只用ASCII字符,不要用中文或其他特殊字符,否则会极大地影响程序的可移植性。
在现代编程环境中,程序编辑器可以设置各种美观得体的字体,我们可以使用不同的显示风格来表示程序的不同部分。
4.3 代码设计规范
不同的编程语言具有不同的设计规范,但是也有通用的原则。
-
函数
现代程序设计语言中的绝大部分功能,都在程序的函数( Function、Method )中实现。关于函数,最重要的原则是:只做一件事,并且要做好。
-
goto
函数最好有单一的出口,为了达到这一目的,可以使用goto。只要有助于程序逻辑的清晰体现,什么方法都可以使用,包括 goto。
-
错误处理
当程序的主要功能实现后,一些程序员会乐观地估计只需要另外20%的时间,给代码加一些错误处理就大功告成了,但是这20%的工作往往需要全部项目80%的时间。
- 参数处理
- 断言
4.4 代码复审
| 名称 | 形式 | 目的 |
|---|---|---|
| 自我复审 | 自己 vs. 自己 | 用同伴复审的标准来要求自己。不一定最有效,因为开发者对自己总是过于自信。如果能持之以恒,则对个人有很大好处 |
| 同伴复审 | 复审者 vs. 开发者 | 简便易行 |
| 团队复审 | 团队 vs. 开发者 | 有比较严格的规定和流程,适用于关键的代码、以及复审后不再更新的代码覆盖率高——有很多双眼睛盯着程序,但效率可能不高(全体人员都要到会) |
-- 引用《现代软件工程——构建之法》4.4 代码复审(P79)
4.5 结对编程
结对编程是指在编程过程中由两人组成一个团队,对软件项目进行分工编写。结对编程目的是实现“1+1>2”的效果,每个人在各自独立设计、实现软件的过程中可能会犯错,但是在结对编程的过程中通过交流和复审,程序各方面的质量提高,这样可以节省很多修改和测试的时间。
4.6 两人合作的不同阶段和技巧
1.萌芽期间(Forming)
这一阶段由于两人刚认识,有不同的期望值,彼此双方并不了解,需要更多的磨合。
2.磨合阶段(Storing)
刚开始合作时,总会出现这样那样的情况,但是只有这样才会加深彼此之间的认识。
3.规范阶段(Norming)
在经过了磨合阶段后,成员之间主键合拍,许多意见和建议取得一致,并且配合紧密。
4.创造阶段(Performing)
在经过上述三个阶段后,团队成员之间可以达到合二为一的效果,但是并不是所有的合作都能达到这一阶段,磨合太多后,可能进入“解体阶段”。
5.解体阶段(Deforming)
由于在“磨合阶段”一方无法接受另一方,导致失败,只能散伙或找其他合作伙伴。
在两人合作期间,因为每个人都是一个独立的个体,都有各自的意见和想法,那么在两个人平等合作的情况下,如何影响对方,如何说服对方。
| 方式 | 简介 | 逻辑/感情 | 推/拉 | 注释 |
|---|---|---|---|---|
| 断言(Assertion) | 解释这样吧,听我的,没错! | 感情 | 推——主动推动同伴做某事 | 感情很强烈,适用于有充分信任的同伴。语音、语调、肢体语言都能帮助传递强烈的信息。 |
| 桥梁(Bridge) | 能不能再给我讲讲你的理由...... | 逻辑 | 拉——吸引对方,建立共识 | 给双方充分条件互相了解 |
| 说服(Persuasion) | 如果我们这样做,根据我的分析,我们会有这样的好处,a,b,c...... | 逻辑 | 推——让对方思考 | 有条理,建立在逻辑分析的基础上。即使不能全部说服,对方也可能接受部分意见 |
| 吸引(Attraction) | 你想过舒适的生活么?你想在家里发财么?加入我们的传销队伍吧,几个月后就可以有上万元的收入...... | 感情 | 拉——描述理想状态,吸引对方加入 | 可以有效地传递信息,但是要注意信息的准确性。夸大的渲染会降低个人的可信度 |
-- 引用《现代软件工程——构建之法》4.6.1 两人的合作——如何影响对方(P90)
任务二:自由结对,对对方《实验二》的项目成果进行评价
1、代码复审核查表
(1)对结对方的博文进行阅读和评论
-
结对对象
于泽浩
-
评论内容
-
结构方面
1、我认为PSP内容应该放在任务2的内容中,因为任务2要求掌握PSP的流程,如果把个人PSP加到这部分会感觉结构更加完整。
2、任务3中的文字太多,而且我个人觉得段落之间稍微空一点距离可能更容易让读者解读。
-
内容方面
1、代码展示部分建议放算法,并且注释清楚放的这部分代码是做什么用的。
2、总结写的较为完善,分点罗列不仅思路清晰,逻辑也清楚。
3、从PSP的内容可以看出,计划完成需要的时间和实际完成需要的时间之间的时间差并不是很大,说明于泽浩同学时间管理能力较强,对时间的掌握和规划很准确。
![]()
-
(2)克隆结对方项目源码到本地机器,阅读并测试运行代码
结对方姓名:于泽浩
结对方Github的仓库链接:https://github.com/yuze-hao/OneProject/blob/main/背包问题.py
| 复审部分 | 提出问题 | 执行情况 |
|---|---|---|
| 概要部分 | 1)代码符合需求和规格说明么? 2)代码设计是否考虑周全? 3)代码可读性如何? 4)代码容易维护么? 5)代码的每一行都执行并检查过了吗? |
1)代码部分被分成了多个部分,代码注释稍显周全; 2)因为代码分模块完成,所以我认为在代码维护方面应该比较容易 3)代码的可读性稍显困难,在较为复杂的代码行后面没有增加注释 |
| 设计规范部分 | 1)设计是否遵从已知的设计模式或项目中常用的模式? 2)有没有硬编码或字符串/数字等存在? 3)代码有没有依赖于某一平台,是否会影响将来的移植(如Win32到 Win64 ) ? 4)开发者新写的代码能否用已有的Library/SDK/Framework中的功能实现?在本项目中是否存在类似的功能可以调用而不用全部重新实现? 5)有没有无用的代码可以清除? |
1)设计较为遵从常用模式 2)有字符串和数字存在 3)开发者新写的代码无法用已有的Library/SDK/Framework中的功能实现 4)基本没有无用代码,但是有些代码可以合并 |
| 代码规范部分 | 修改的部分符合代码标准和风格吗? | 修改的部分符合代码标准和风格 |
| 具体代码部分 | 1)有没有对错误进行处理?对于调用的外部函数,是否检查了返回值或处理了异常? 2)参数传递有无错误,字符串的长度是字节的长度还是字符(可能是单/双字节)的长度,是以0开始计数还是以1开始计数? 3)边界条件是如何处理的?switch语句的default分支是如何处理的?循环有没有可能出现死循环? 4)有没有使用断言(Assert)来保证我们认为不变的条件真的得到满足? 5)对资源的利用,是在哪里申请,在哪里释放的?有无可能存在资源泄漏(内存、文件、各种GUI资源、数据库访问的连接,等等)?有没有优化的空间? 6)数据结构中有没有用不到的元素? |
1)开发者对错误进行了处理,并且处理错误之后还进行了分析 2)字符串的长度是以0开始计数 3)循环没有出现死循环 |
| 效能 | 1)代码的效能( Performance )如何?最坏的情况是怎样的? 2)代码中,特别是循环中是否有明显可优化的部分(C++中反复创建类,C# 中 string的操作是否能用StringBuilder来优化)? 3)对于系统和网络的调用是否会超时?如何处理? |
1)代码最坏的情况是运行出错,并且出现了“list index out of range”,列表参数溢出范围 2)对于系统和网络的调用可能会超时,因为在运用回溯算法的时候耗时较长 |
| 可读性 | 代码可读性如何?有没有足够的注释? | 代码可读性较好,有足够的注释 |
| 可测试性 | 代码是否需要更新或创建新的单元测试? | 不需要 |
-- 引用《现代软件工程—构建之法》4.4.3 代码复审的核查表(P82)
任务三:采用两人结对编程方式,设计开发一款D{0-1}KP 实例数据集算法
需求分析陈述
目前,求解折扣{0-1}背 包 问 题(D{0-1}KP)的主要算法是基于动态规划的具有伪多项式时间的确定性算法,当D{0-1}KP实例中各项的价值系数与重量系数在大范围内取值时缺乏实用性。折扣{0-1}背包问题(Discounted {0-1} Knapsack Problem,D{0-1}KP)是比0-1背包还要难以求解的NP-hard问题。提出了一种求解D{0-1}KP的新遗传算法GADKP。
(1)平台基础功能:实验二 任务3
实验二任务3的链接:https://www.cnblogs.com/wentingxiong/p/14599087.html
(2)D{0-1}KP 实例数据集需存储在数据库
利用MySQL软件与Python数据库连接,将实验二的数据集中的一部分加入数据库,如图所示。
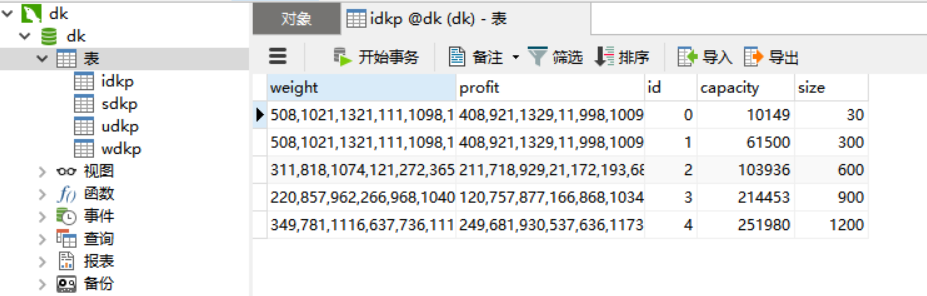
数据库连接
config = {
'host': 'localhost',
'port': 3307,
'user': 'root',
'password': '815490',
'db': 'dk',
'charset': 'utf8',
'cursorclass': pymysql.cursors.DictCursor,
}
connection = pymysql.connect(**config)
connection.autocommit(True)
cursor = connection.cursor()
def get_table_list():
results=[]
cursor.execute('show tables from dk;')
query_result = cursor.fetchall()
for i in query_result:
results.append(i['Tables_in_dk'])
return results
def get_data(sets_name):
sql='select * from '+sets_name+';'
cursor.execute(sql)
query_result = cursor.fetchall()
return query_result
(3)平台可动态嵌入任何一个有效的D{0-1}KP 实例求解算法,并保存算法实验日志数据
在实验二的基础上,加入实验日志数据,文件命名为“月-日-年.txt”,如图所示。

流程图
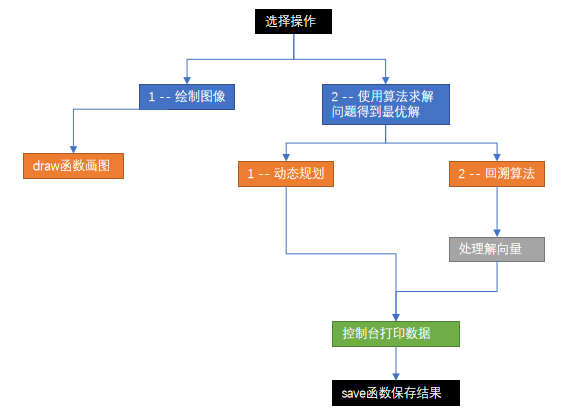
回溯算法并剪枝
def bound(self, k, caup): # 计算上界函数,功能为剪枝
ans = self.val
while k < self.size and caup >= self.items[k].pack[2].weight:
caup -= self.items[k].pack[2].weight
ans += self.items[k].pack[2].profit
k += 1
if k < self.size:
ans += self.items[k].pack[2].profit / self.items[k].pack[2].weight * caup
return ans
def Backtracking(self, k, i, caup): # 回溯算法
bound_val = self.bound(k + 2, caup)
if k == self.size - 1:
if self.max_val < self.val:
self.max_val = self.val
self.so_res = list.copy(self.so_tmp)
return
for j in range(3):
if caup >= self.items[k + 1].pack[j].weight:
self.val += self.items[k + 1].pack[j].profit
self.so_tmp.append((k + 1, j))
self.Backtracking(k + 1, j, caup - self.items[k + 1].pack[j].weight)
self.so_tmp.pop()
self.val -= self.items[k + 1].pack[j].profit
if bound_val > self.max_val:
self.Backtracking(k + 1, j, caup)
动态规划算法
def DP(self): # 动态规划算法
dp = [[[0 for k in range(self.cubage + 5)] for i in range(4)] for j in range(self.size + 5)] # 三维dp数组
for k in range(1, self.size + 1):
for i in range(1, 4):
for v in range(self.cubage + 1):
for j in range(1, 4):
dp[k][i][v] = max(dp[k][i][v], dp[k - 1][j][v])
if v >= self.items[k - 1].pack[i - 1].weight:
dp[k][i][v] = max(dp[k][i][v],dp[k - 1][j][v - self.items[k - 1].pack[i - 1].weight]+self.items[k - 1].pack[i - 1].profit)
self.max_val = max(self.max_val, dp[k][i][v])
(4)人机交互界面要求为GUI界面(WEB页面、APP页面都可)
利用python自带框架tkinter绘制GUI界面,如图所示。
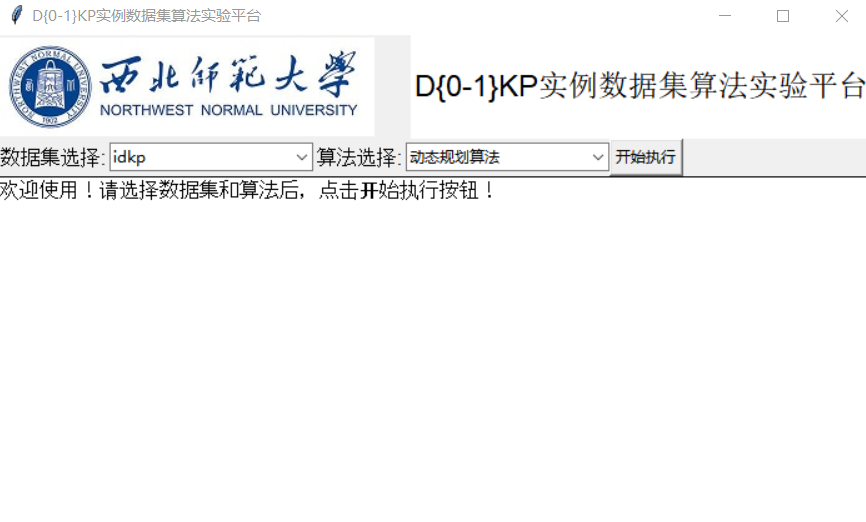
(5)查阅资料,设计遗传算法求解D{0-1}KP,并利用此算法测试要求(3)
参考文献:
[1]吴聪聪,贺毅朝,赵建立.求解折扣{0-1}背包问题的新遗传算法[J].计算机工程与应用,2020,56(07):57-66.
[2]杨洋,潘大志,刘益,谭代伦.折扣{0-1}背包问题的简化新模型及遗传算法求解[J].计算机应用,2019,39(03):656-662.
遗传算法伪代码,如下图所示。

运行结果图:

核心代码:
def select(self):
'''采用选择概率和累积概率来做选择,得出下一代种群(个数不变)
对环境适应度高的个体,后代多,反之后代少,最后只剩下强者'''
last_cho_feq = 0
for i in range(0, population_size, 1):
try:
self._gatype[i].cho_feq = self._gatype[i].fitness / float(self.total_fitness) # 选择概率
except:
# print('error', self.total_fitness)
pass
self._gatype[i].cum_feq = last_cho_feq + self._gatype[i].cho_feq # 累积概率
last_cho_feq = self._gatype[i].cum_feq
# _next = deepcopy(self._gatype) # 下一代种群,参与到后续的交叉和变异
_next = [GAType(self.obj_count) for x in range(0, population_size, 1)]
for i in range(0, population_size, 1):
choose_standard = random.randint(1, 100) / 100.0
# print('choose_standard: %f' % choose_standard)
if choose_standard < self._gatype[0].cum_feq: # 选出下一代种群
_next[i] = self._gatype[0]
else:
for j in range(1, population_size, 1):
if self._gatype[j-1].cum_feq <= choose_standard < self._gatype[j].cum_feq:
_next[i] = self._gatype[j]
self._gatype = deepcopy(_next)
self.avoid_zero() # 全零是不可避免的
(6)附加功能:除(1)-(5)外的任意有效平台功能实现
在问题(1)-(5)外的问题中,我们实现的其他功能有:
- 计算不同算法运行的时间
- 优化实验二中文件读取的功能
总结
本次实验是我结结实实的用三天时间完成的,第一次切实的体会到合作的重要性以及快乐感。在本次实验中,我要特别感谢我的结对对象——于泽浩,我和他虽然已经不是第一次结对,但是每一次都会有不一样的体验,在这次实验中,因为很多内容涉及到我们的知识盲区,所以我们的分工不是很明确,很多时候都是在一起做,一起讨论,如下表所示。
| 成员姓名 | 讨论日期 | 所做内容 |
|---|---|---|
| 熊文婷 | 2021.4.9 | 通过中国知网、万方等网站查找关于遗传算法资料 |
| 于泽浩 | 2021.4.10 | 设计GUI界面 |
| 熊文婷 | 2021.4.10 | 修改实验二代码,在此基础上为创建图形用户界面、连接数据库做准备 |
| 于泽浩 | 2021.4.11 | 设计遗传算法伪代码 |
| 熊文婷、于泽浩 | 2021.4.12 | 积极讨论在单人工作期间遇到的问题,展示这段时间的实验成果并且共同解决 |
| 熊文婷、于泽浩 | 2021.4.13 | 同上 |
在单人工作时会遇到很多意外,比如数据库软件下载有问题、数据库连接不上、设计的界面没有达到预期的目标等等,但是当两人见面后将彼此的问题告诉对方时,不仅仅可以获得建议还能互相学习,共同进步。我们在解决这些问题时也让其他的小伙伴帮我们拍了照片,如下所示。
-
设计页面
![]()
![]()
-
讨论图1
![]()
![]()
-
讨论图2
![]()
![]()






所以我认为,当遇到“合适”的合作者时,工作的效率确实能达到1+1>2的效果,而这个“合适”取决于这个人与你的”胃口“是否相对。两个人的共同努力才能最大程度的实现结对的真正意义和发挥结对的最大功效,让我们的项目成果就是比那些没有合作的同学完成度高。
结对PSP
| 任务内容 | 计划共完成的时间(min) | 实际完成时间(min) |
|---|---|---|
| 计划 | 30 | 40 |
| 结对成员认识 | 10 | 8 |
| 任务分工及初步讨论 | 20 | 32 |
| 开发(预计三天完成) | 490 | 590 |
| 图形用户界面设计 | 30 | 30 |
| 数据库设计 | 60 | 60 |
| 实验二代码修改 | 130 | 140 |
| 代码更改 | 120 | 170 |
| 遗产算法(查看资料) | 60 | 60 |
| 遗传算法传算法(伪代码编写) | 90 | 130 |
| 报告 | 155 | 230 |
| 阅读《构建之法》 | 80 | 100 |
| 博客园编写 | 60 | 100 |
| 反思及总结 | 15 | 30 |
通过与实验二的PSP对比,我觉得我对于我自己过于自信,计划时间始终短于实际完成时间,这就说明我自己的计划有问题,对实验过于自信。其实讨论时花费的时间较长,一方面在讨论的时候会出现讨论的话题突然转变,变成无关紧要的话题;另一方面,思考的时候会花费很多时间,比如考虑这样做好不好,对不对等等一些问题,所以对于PSP的估计中产生的误差还是需要改变。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号