FPN、PAN、BiFPN的区别
1. FPN
论文题目:Feature Pyramid Networks for Object Detection
论文地址:https://arxiv.org/abs/1612.03144
如果不讨论传统目标检测算法中的特征提取,深度学习算法流行以来图像金字塔的开端应该是SPPnet。为了解决RCNN中输入图片尺寸必须固定的问题,何凯明大神创新性的提出SPPnet以进行解决。
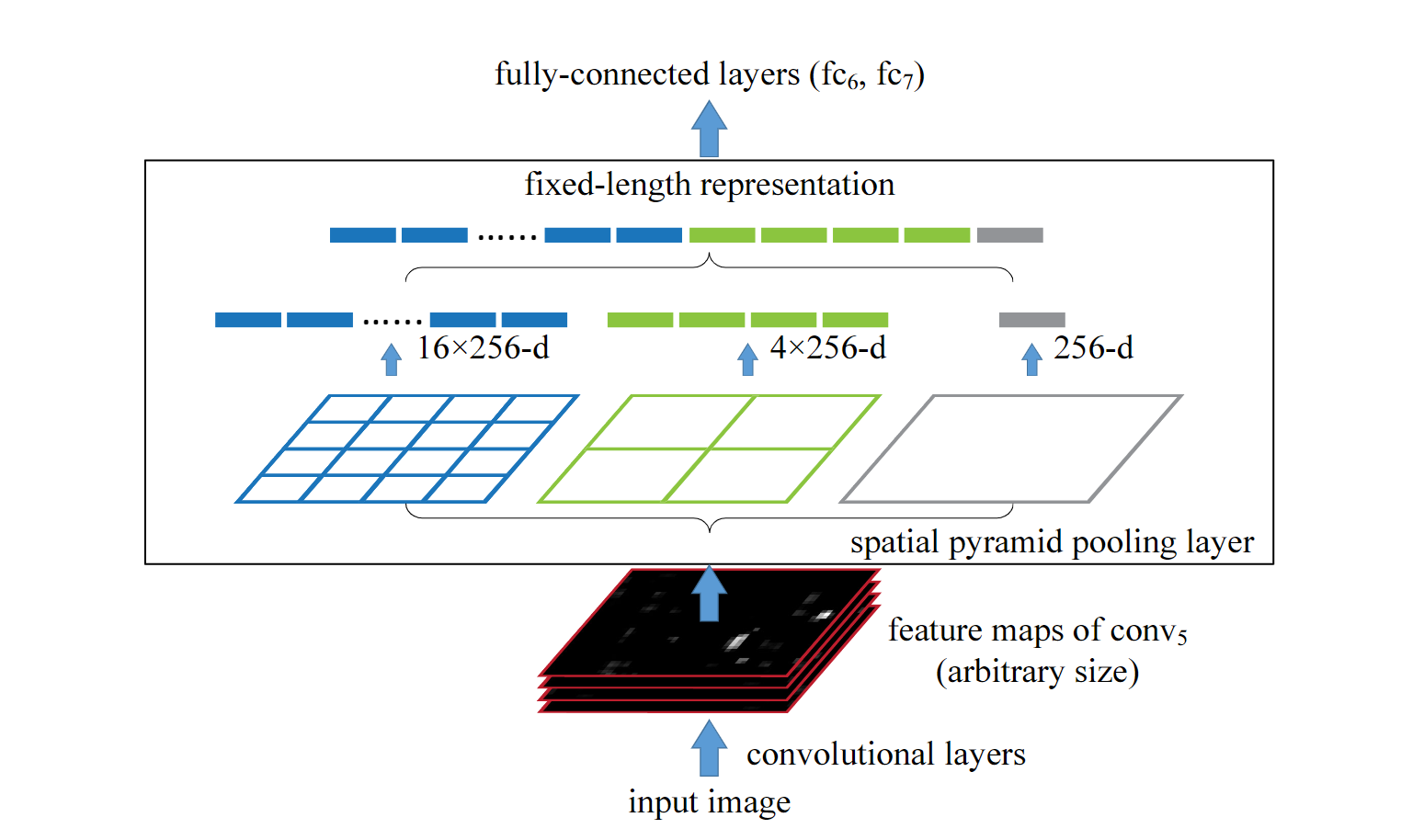
但FPN作者认为诸如此类算法(SPP、Fast RCNN、Faster RCNN)都是计算的网络的最后一层特征并未考虑多个尺度的特征;又如SDD虽然采用了多尺度融合,但由于没有上采样过程,导致对底层特征的使用不够充分。
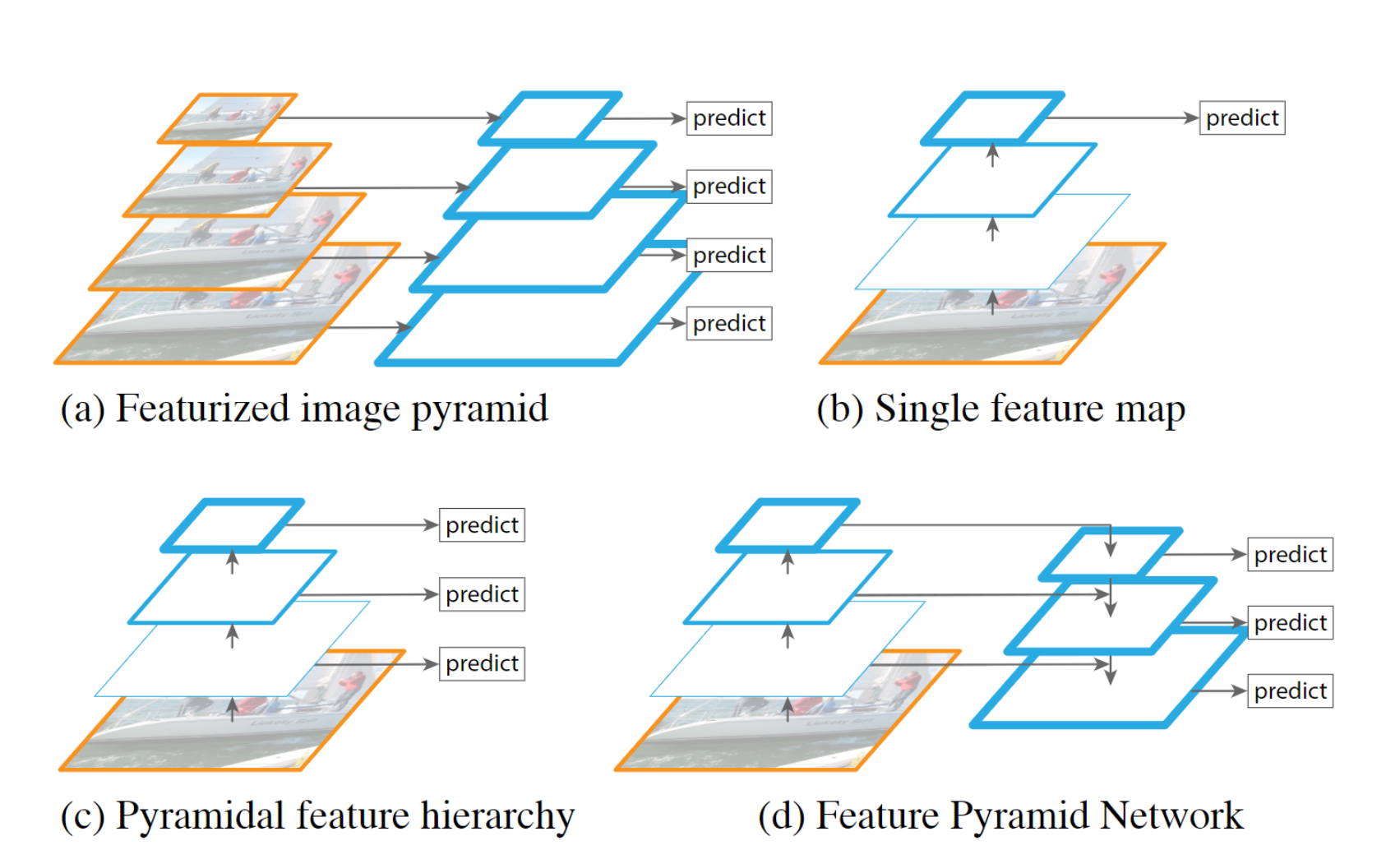
上图是作者在论文中画出的几种金字塔特征图。可以看出a)在每个尺度上进行计算,速度太慢。b)仅在顶层进项检测。c)有多尺度特征。d)有多尺度特征也有特征融合。
具体的网络结构如下图所示: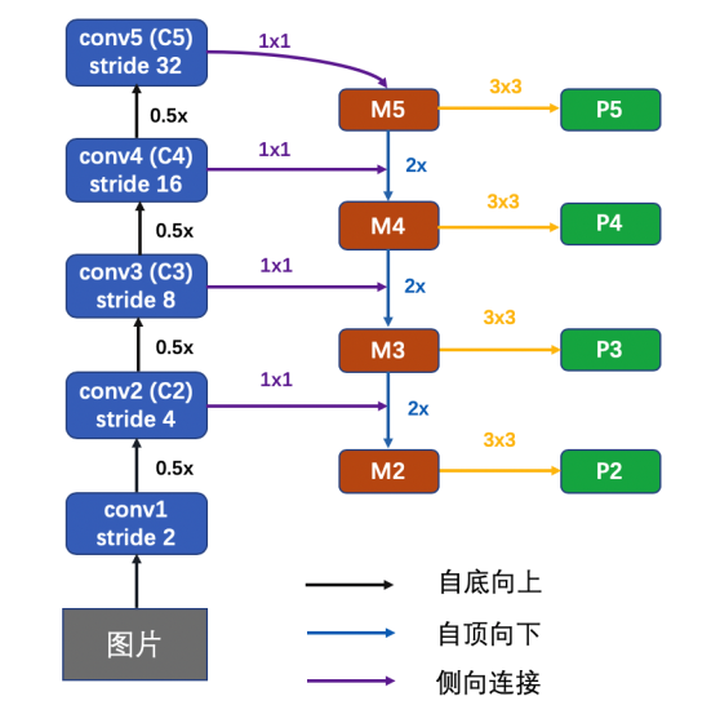
2. PAN
论文题目:Path Aggregation Network for Instance Segmentation
论文地址:https://arxiv.org/abs/1803.01534
具体来说,作者认为低级别的特征有助于大实例识别。但是从底层结构到顶层特征还有很长的路要走,这增加了获取准确定位信息的难度。此外,每个提议都是基于从一个特征级别汇集的特征网格来预测的,该特征级别是启发式分配的。这个过程可以更新,因为在其他级别丢弃的信息可能有助于最终预测。
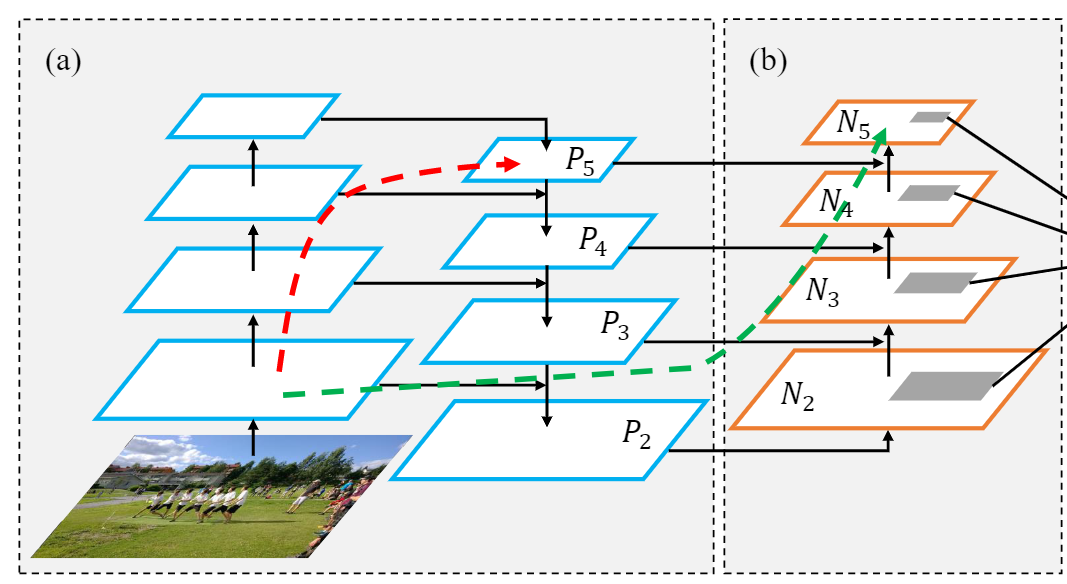
一句话概括,PAN就是在FPN后面加了一层自下向上的连接。
3.BiFPN
论文题目:EfficientDet: Scalable and Efficient Object Detection
论文地址:https://arxiv.org/abs/1911.09070
先放一张论文中的原图: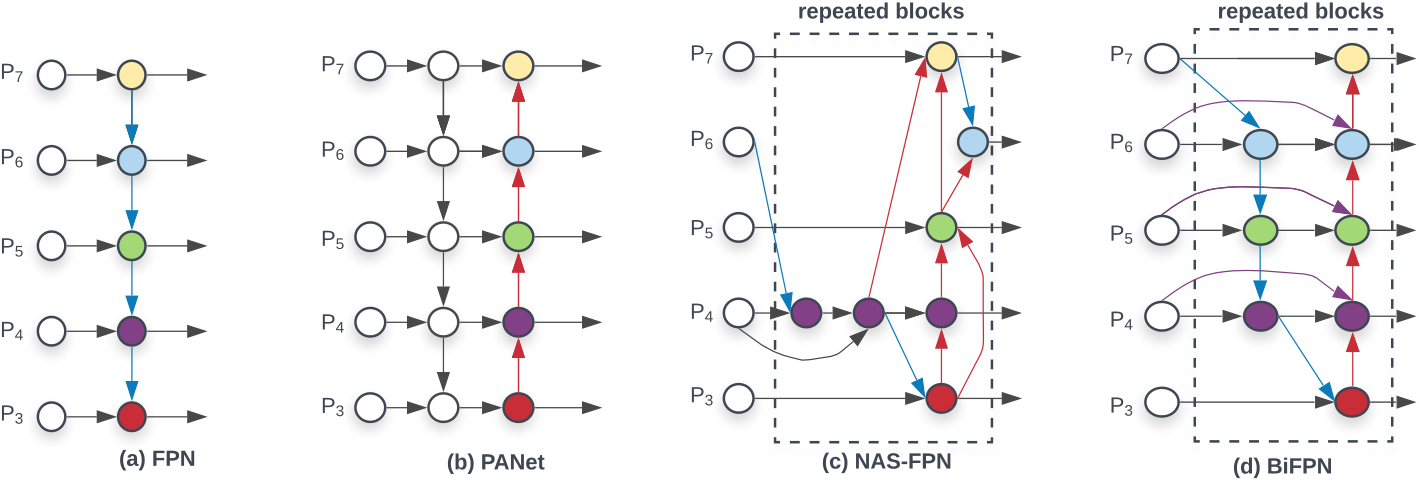
相较于其他特征融合网络,BiFPN的不同之处在于:首先,删除那些只有一个输入边的节点。我们的直觉很简单:如果一个节点只有一个输入边而没有特征融合,那么它将对旨在融合不同特征的特征网络的贡献较小。这导致了一个简化的双向网络;其次,如果它们处于同一级别,我们从原始输入到输出节点添加一条额外的边,以便在不增加太多成本的情况下融合更多特征;第三,与只有一条自顶向下和一条自底向上路径的 PANet不同,我们将每个双向(自顶向下和自底向上)路径视为一个特征网络层,并多次重复同一层以启用更高级的特征融合。
此外,作者还认为由于不同的输入特征具有不同的分辨率,它们通常对输出特征的贡献不均等。为了解决这个问题,文中建议为每个输入添加一个额外的权重,并让网络学习每个输入特征的重要性。
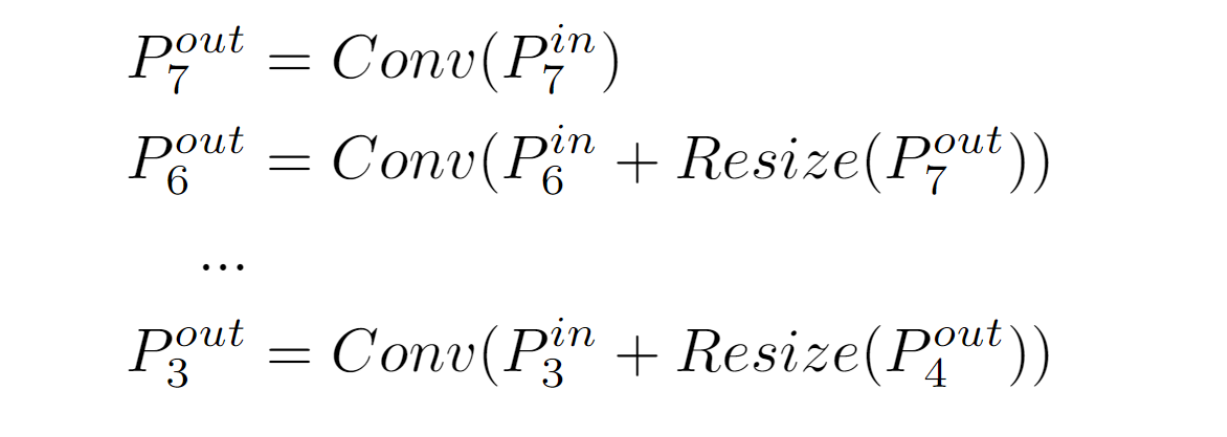
4.You only look one-level Feature
论文题目:You only look one-level Feature
论文地址:https://arxiv.org/abs/2103.09460
以往的观点认为,FPN变现好的原因是因为进行了多尺度的特征融合。但一个新的声音的出现打破了这个固有的认知:对于FPN而言,多尺度特征的好处远不及分而治之的好处。
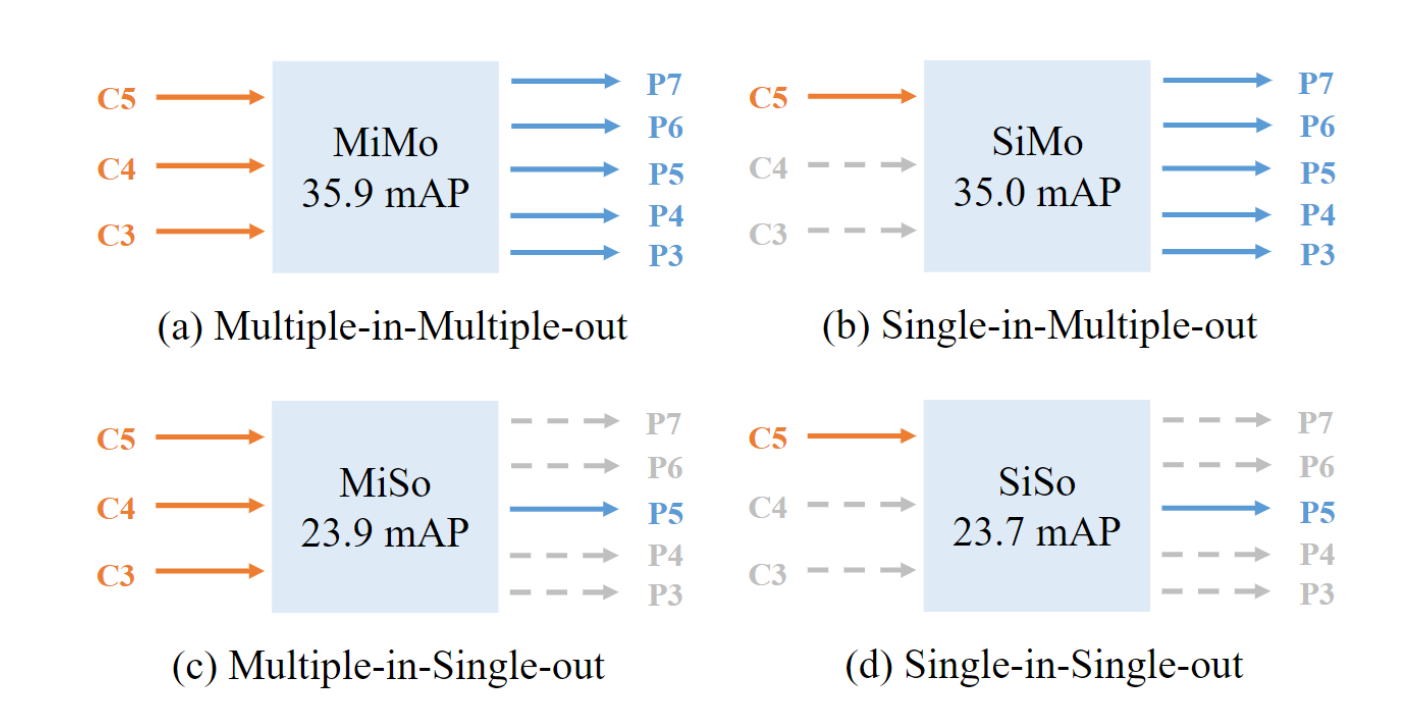
作者实验表明,由图a)和图b)相比,使用多尺度特征融合对于最后结果的提升是微小的。但观察a)和c),b)和d),由于没有使用分而治之在不同尺度进行后续处理,最后结果的下降是非常显著的。
但是分而治之的做法太迟计算资源了,有没有一种更加优雅的方法呢?作者采用的是SiSo的结果,但是从上面的结果不难看出,使用单输出的方法对于结果的下降是不言而喻的。作者发现 SiSo 编码器带来的两个问题是导致性能下降的原因。第一个问题是与C5特征的感受野匹配的尺度范围是有限的,这阻碍了对不同尺度对象的检测性能。第二个是单层特征中稀疏anchor引起的正anchor上的不平衡问题。
如何解决呢?
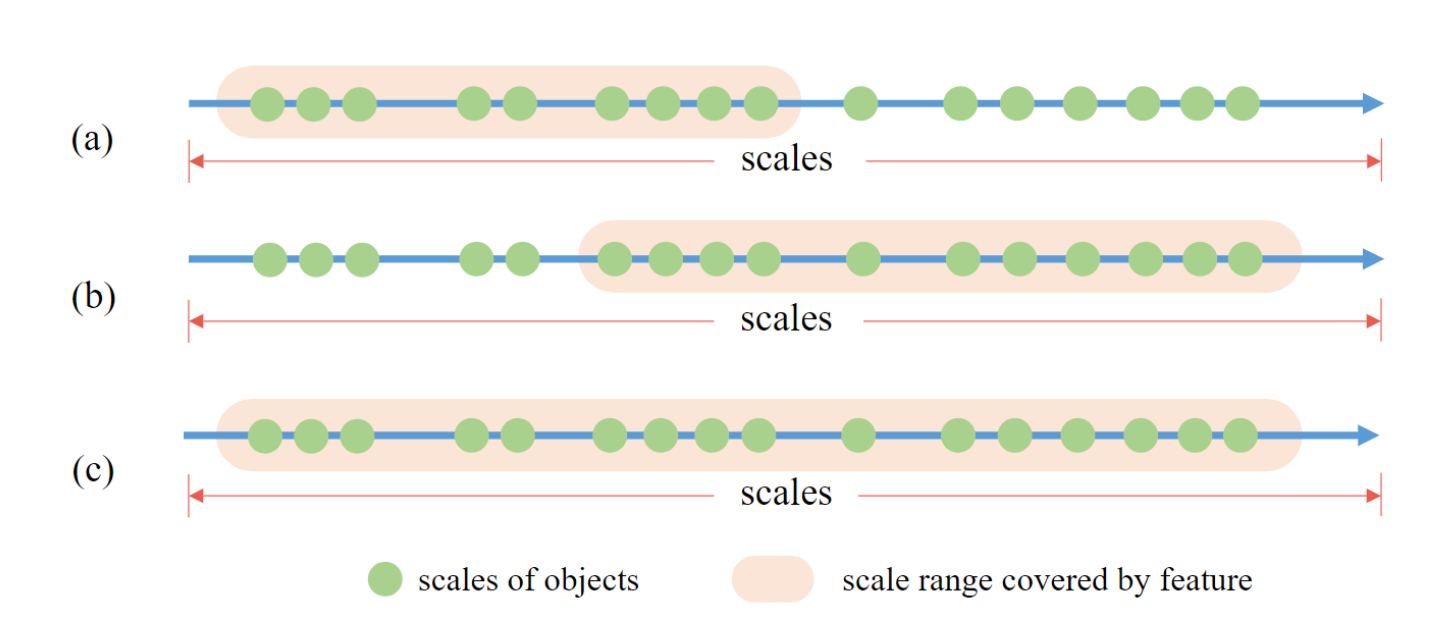
首先我们来看第一个问题,在多输入的情况下我们可以使用多个特征图扩充感受野。但对于单输入方法,大人,时代变了。一种可行的方法就是使用空洞卷积(膨胀卷积)来增大感受野。如下图b)所示,单纯的堆叠标准卷积和空洞卷积只会使感受野发生偏移和扩张,仍然不够覆盖所有尺度。但显而易见的是,如果我们将a)和b)的感受野合并,完美的事情出现了,这一合并后的结果是足以覆盖所有尺度。
由于仅仅关注一层特征,一个后果就是相比于MiMo,SiSo的anchor是稀疏的,这就导致对于大GT来说,其匹配的正样本的数量将远大于小GT的正样本。因此,作者设计了一个均衡匹配(Uniform Matching)策略,即对每个GT框而言,只采用最接近的k个anchor作为正anchor,这就能如上图一样保证每个GT框不论尺寸大小都有相同数目的正anchor。平衡的正样本确保所有的GT框平等地参与训练。根据轻松掌握 MMDetection 中常用算法(六):YOLOF的介绍,均衡匹配的步骤如下:
- 遍历每个 gt bbox,然后选择 topk 个距离最近的 anchor 作为其匹配的正样本
- 遍历每个 gt bbox,然后选择 topk 个距离最近的预测框作为补充的匹配正样本
- 计算 gt bbox 和预测框的 iou,在所有负样本点中,将 iou 高于 0.75 的负样本强制认为是忽略样本
- 计算 gt bbox 和 anchor 的 iou,在所有正样本点中,将 iou 低于 0.15 的正样本强制认为是忽略样本
相比于论文描述,实际上代码额外动态补充了一定量的正样本,同时也额外考虑了一些忽略样本。相比于纯粹采用 anchor 和 gt bbox 进行匹配,额外引入预测框,可以动态调整正负样本,理论上会更好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号