SC-FEGAN: Face Editing Generative Adversarial Network with User’s Sketch and Color
Abstract
- 本文提出了一个端到端训练的卷积网络来实现图像编辑系统,进而实现图片的生成。系统的输入为
free-form mask、sketch、color。 - 与现存的方法相比,作者的方法利用具有颜色和形状的
free-form的用户输入。 - 提出的网络结构称为
SC-FEGAN。
Introduction
- 即使在图像中存在擦除部分的情况下,只要给出草图和颜色输入的情况下,作者提出的系统具有轻松生成高质量人脸图像的能力。
- 最近的工作,深度学习在图像修复上展现了惊人的修复能力。
- 最典型的方法是采用矩形的
mask,修复这个mask采用一个encode-decode generator。然后通过global and local discriminator来评估这个生成的结果是真的还是假的。- 存在的问题:仅适用于低分辨率图片的修复;会在缺失区域生成明显的边界;缺失区域上合成的图像经常达不到用户的期望(因为从未向生成器提供任何用户输入来用作生成器)
- 一些方法试图解决以上问题:
Deeepfillv2,网络的输入有用户的sketch,但是未将颜色做为输入信息;GuidedInpating的方法是拿一个其它图像的一部分做为输入,来实现缺失部分的恢复,但是很难恢复细节信息。将颜色做为信息输入,合成图像中的颜色是根据从训练数据集中学习的先验分布推断得出的。Ideepcolor接受用户输入的颜色作为参考以创建用于黑白图像的彩色图像。但是不允许编辑对象结构或还原图像上已删除的部分。FaceShop允许用户输入Sketch和color,但是FaceShop作为合成图像生成的交互式系统有一些限制。
- 为解决上面的问题,作者提出了一端到端的训练方式的全卷积神经网络,即
SC-FEGAN。判别器采用SN-patchGAN,来解决和提高缺失部分明显的边界信息。训练的损失函数,不仅仅有GAN loss,还有Style loss等。网络的输入包括Input image、mask、Sketch、Color、Noise。 - 本文主要贡献:
- 提出了类似
Unet网络结构,网络中部分卷积层采用Gated convolution layer,这样的结构在训练和推理过程中容易、速度较快。 - 作者创造了一个
free-form domain data of masks,color and sketch.用于网络的训练。 - 采用
SN-patchGAN discriminator,训练网络时,附加了style loss。当缺失部分较大时,让能表现出较强的鲁棒性,还允许在所产生的图像上产生细节,例如高质量的合成发型和耳环。
- 提出了类似

Related Work
Image Translation
AA
Image Completion
Image completion存在两个难点:- 填充图像的已删除区域。
- 正确反映用户在恢复区域中的输入。
- 在之前的研究中,
GAN系统探索性的生成从具体缺失区域的图像到完整图像的可行性,它使用来自U-net结构的生成器,并且利用local and global discriminator。Discriminator分别确定在新填充的部分和完全重建的图像上生成的图像是真实的还是伪造的。Deepfillv1还使用矩形Mask以及local and global discriminator model来表明上下文关注层可以大大提高性能。 但是,the global and local discriminator仍然在恢复部分的边界处产生尴尬的区域。 - 在后续
DeepfillV2中,引入free-form mask and SN-patchGAN,a free-form mask and SN-patchGAN were introduced to replace the existing rectangular mask and global and local discriminator with single discriminator.In addition, the gated convolutional layer that learns the features of the masked region was also suggested. This layer can present masks automatically from data by training, which gives the network ability to reflect user sketch input on the results. - 作者提出的网络,不仅可以使用
Sketch,而且还可以使用color data做为输入来实现编辑图像。作者使用U-net结构,而不是使用Coarse-Refined net structure(DeepfillV1,2中采用的)。作者提出的网络能够生成高质量的结果,不需要复杂的训练计划或其他复杂层的要求。
Approach
- 3.1描述
Masking training data - 3.2描述
network structure和loss function
Training Data
- 数据集:
CelebA-HQ - 我们首先随机选择2组共29000张图片进行训练,1000张图片进行测试。在获得
Sketch和color数据集之前,我们将图像大小调整为512 ×512像素。 - 为了更好的表达眼部的复杂性,作者提出了一个基于眼睛位置的
free-from mask来做为训练神经网络的输入。同时,作者还使用free-from mask和人脸分割GFC(CVPR: Generative face completion)来创建Sketch domains和color domains。在输入的数据中,作者随机的将遮罩应用到头发区域,因为他与人脸其它部分相比具有不同的特性。
Free-form masking with eye-positions
- 使用与DeepfillV2相同的方法来实现缺失图像(incomplete images)的生成。然而,在对人脸进行训练时,我们随机的使用了一个以眼睛为起点的
free draw mask,来表达眼睛的复杂部分。同时还是要了GFC来对头发进行随机的缺失。眼睛free draw mask具体算法如下:

Sketch & Color domain
- 作者使用类似
FaceShop的方法,而不是采用AutoTrace的方法。(AutoTrace:converts bitmap to vector graphics for sketch data。) sketch data的生成:作者使用HED edge detector生成对应于用户输入修改的面部图像的sketch data。然后平滑曲线并删除小的边。color domain data的生成:首先使用大小为3的中值滤波,然后使用20个双边滤波来创建模糊图像,然后使用GFC来分割面部,每个分割部分替换为相应部分的中间色。- 注意:在为
color domain创建数据时,不应用直方图均衡化来避免光反射和阴影造成的颜色污染。然而,由于用户在sketch domain中表达人脸的所有部分,而不受光的干扰而产生模糊,因此在根据域数据生成素描时采用了直方图均衡化方法。更具体地说,在直方图均衡化之后,我们应用HED从图像中提取边缘。然后,我们平滑曲线并删除小对象。最后,与mask进行逐项乘机(采用类似于以前的free-form mask的生成过程)和对图像进行彩色化,得到color brushed图像。数据示例,如下:

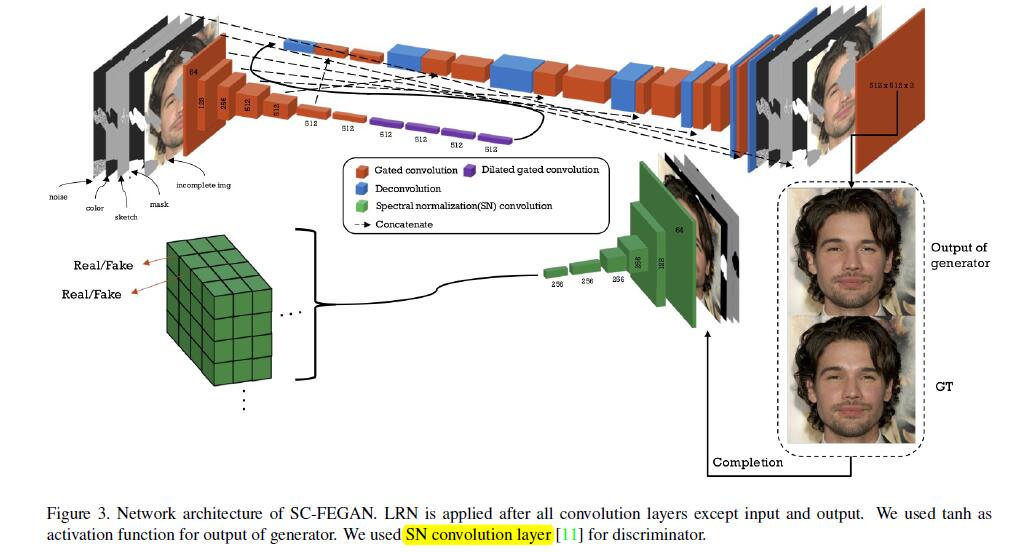
Network Architecture
- 作者的
completion network(即generator),采用了encoder-decoder architecture like the U-net。discrimination network是基于SN-patchGAN的。 trains generator and discriminator simultaneously。- 网络的输出结果为
512×512.(RGB channel) - 网络的处理过程:
- 将生成器网络输出图像的遮罩区域插入输入图像(
incomplete image)以创建complete image。 - 上面生成的
complete image和原始图片(original image (without masking) or ground truth)输入到判别器网络(discrimination network)来判别图片的真假。
- 将生成器网络输出图像的遮罩区域插入输入图像(
Generator