Image Inpainting for Irregular Holes Using Partial Convolutions
Partial Convolution layer Implement source code
摘要
现有的基于深度学习的图像修补方法在损坏的图像上使用标准卷积网络,使用以有效像素(非缺失部分的像素)和缺失部分填充适当的值(通常为平均值)为条件的进行卷积操作。 这通常会导致诸如颜色差异和模糊等伪影。 后处理通常用于减少这些工件,但代价很高,可能会失败。作者提出使用部分卷积Partial Convolutions,the convolution is masked and renormalized to be conditioned on only valid pixels。 还包含一个机制,可以为下一层自动生成更新的掩膜。 我们的模型胜过其他irregular masks的方法。 我们展示定性和定量比较与其他方法来验证我们的方法
Introduction
- 以前的深度学习方法主要集中在位于图像中心附近的矩形区域,并且通常依赖于昂贵的后期处理。本文提出的对不规则缺失也能很好的进行修补。不需要后期处理
post-processing和泊松图像混合操作blending operation。 - 最近图像修复方法:
- 不使用深度学习的方法主要是利用非缺失部分的图像统计信息来填充缺失部分,来实现修复图片。
PatchMatch - 使用深度学习的方法主要是用固定的值填充缺失部分的像素,然后在这些图片上使用卷积操作,这些方法受到依赖于初始孔值的影响,其通常表现为孔区域缺乏纹理,明显的颜色对比或围绕孔的人造边缘的现象。并且网络框架常采用
U-Net架构。 - 作者工作旨在实现与缺失部分初始化值无关并且没有任何额外的后处理的良好合并缺失部分预测。并且能够实现对不规则缺失的修复。
- 不使用深度学习的方法主要是利用非缺失部分的图像统计信息来填充缺失部分,来实现修复图片。
- 作者设计部分卷积层,
comprising a masked and renormalized convolution operation followed by a mask-update step.(masked and re-normalized convolution在图像分割中比较常见,也叫segmentation-aware convolutions,但是他们没有对mask进行修改。) - 作者设计部分卷积,
given a binary mask our convolutional results depend only on the non-hole regions at every layer.作者还扩展了automatic mask update step,原理removes any masking where the partial convolution was able to operate on an unmasked value.只要层数足够多,缺失部分将会在不断的更新的特征层中消失。这样就与缺失部分的内容无关(与缺失部分的初始化内容无关)。 - 本文的主要贡献:
- 提出了带有自动掩码更新步骤
automatic mask update的部分卷积层partial convolutions。 - 带有
skip links典型卷积的U-Net能够获得良好的修复效果,但我们证明用部分卷积和掩膜更新代替卷积层可以获得最新的修补结果。 - 据我们所知,我们首先证明了在形状不规则的孔上训练图像修复模型的功效.
- 我们提出了一个大型的不规则掩膜数据集,该数据集将公开发布,以便于未来的训练和评估工作修复模型。
- 提出了带有自动掩码更新步骤
Approach
我们提出的模型使用堆叠的部分卷积运算和掩膜更新步骤来执行图像修复。我们首先定义我们的卷积和掩膜更新机制,然后讨论模型架构和损失函数。
Partial Convolutional Layer
- 部分卷积层
Partial Convolutional Layer,包括部分卷积操作和掩码更新mask update操作。 - 设
W是卷积滤波器的权重,b是相应的偏差。X是当前卷积(滑动)窗口的特征值(像素值),M是相应的二进制掩膜mask。每个位置的部分卷积被表示为: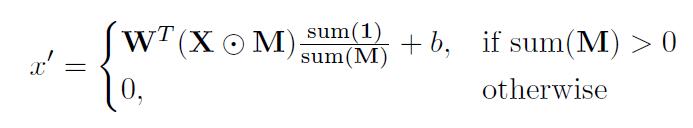 其中⊙表示逐像素乘法。 可以看出,输出值仅取决于非屏蔽输入。 比例因子1/sum(M)应用适当的缩放比例来调整有效(未屏蔽)输入的变化量。
其中⊙表示逐像素乘法。 可以看出,输出值仅取决于非屏蔽输入。 比例因子1/sum(M)应用适当的缩放比例来调整有效(未屏蔽)输入的变化量。 - 在部分卷积操作之后,更新掩码以一下规则:如果卷积能够以至少一个有效输入值作为条件的输出,那么我们将该位置标记为有效。
 在部分卷积层有足够的连续应用的情况下,如果输入包含任何有效像素,则任何掩膜将最终全部为1。
在部分卷积层有足够的连续应用的情况下,如果输入包含任何有效像素,则任何掩膜将最终全部为1。
Network Architecture and Implementation
-
Implementation
Partial convolution layer是基于pytorch扩展的。- 不基于
pytorch直接实现的方法是:定义形状为C×H×W的二值掩码binary masks,与相关的图片或者特征相同大小,然后使用一个固定的卷积层来实现掩码的更新操作,固定卷积层的大小和部分卷积层的大小一致,卷积核权重全为1,没有偏置。
-
Network Design
- 网络结构类似U-net,用所有的部分卷积代替所有的卷积层,并在解码阶段使用
nearest neighbor up-sampling。在编码阶段使用ReLu,在解码阶段使用alpha = 0.2的LeakyReLU。在第一和最后的卷积层之外的每个部分卷积和ReLu/LeakyReLU层之间使用批量归一化层。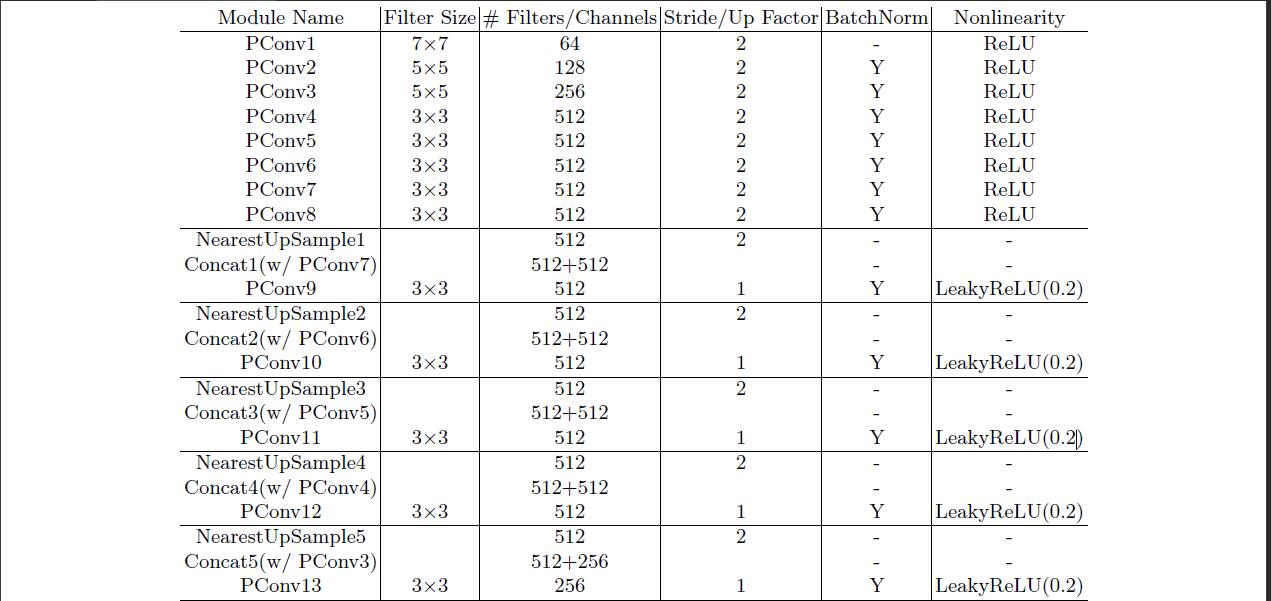
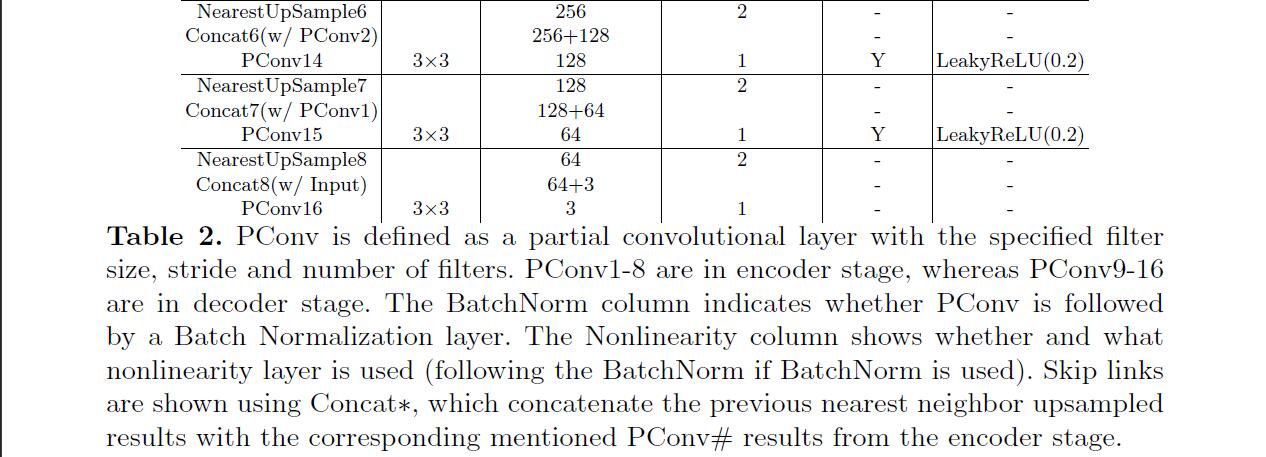
- 网络结构类似U-net,用所有的部分卷积代替所有的卷积层,并在解码阶段使用
-
Partial Convolution as Padding
- 我们使用部分卷积在图像边界处加上适当的遮罩代替典型的填充。 这样可以确保图像边界处的已修复内容不会受到图像之外的无效值的影响,这些值可以解释为另一个孔。
-
loss function
- 定义:
input image with hole\(I_{in}\),initial binary mask\(M\) (0 for holes),the network prediction\(I_{out}\), andthe ground truth image\(I_{gt}\) - 包括5个损失函数,分别为:
perpixel losses\(L_{hole}\) 和perceptual loss\(L_{perceptual}\) 和style-loss( \(L_{styleout}\) 和\(L_{stylecomp}\) )和total variation (TV)\(L_{tv}\) perpixel losses: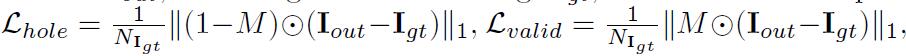

perceptual loss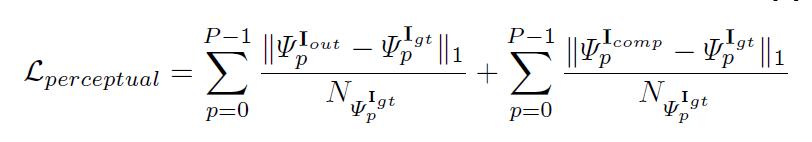
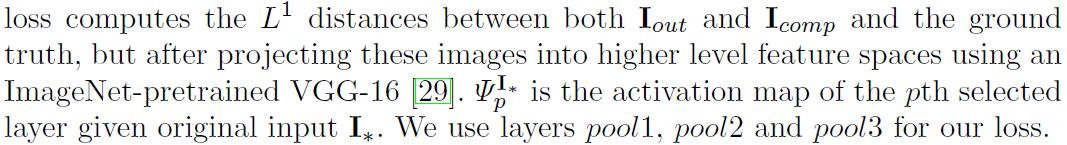
style-loss首先在应用L1之前在每个特征图上执行自相关((Gram矩阵)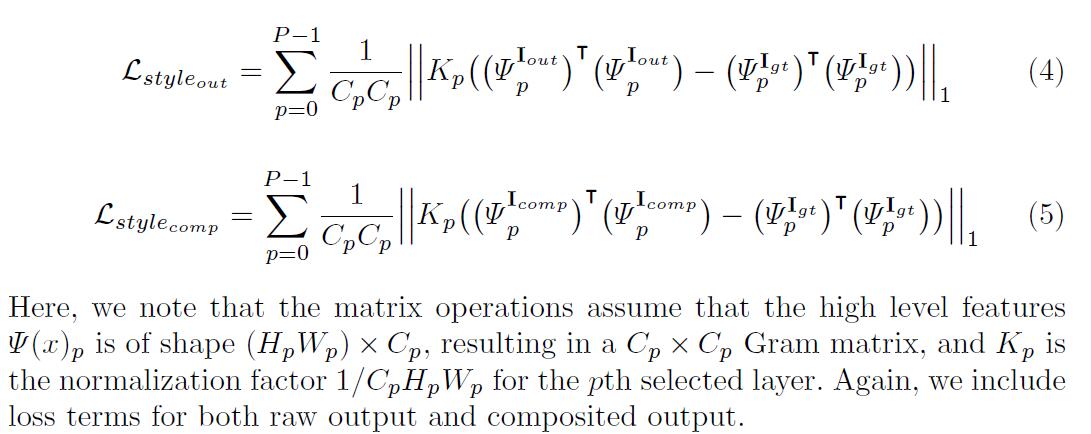
total variation (TV)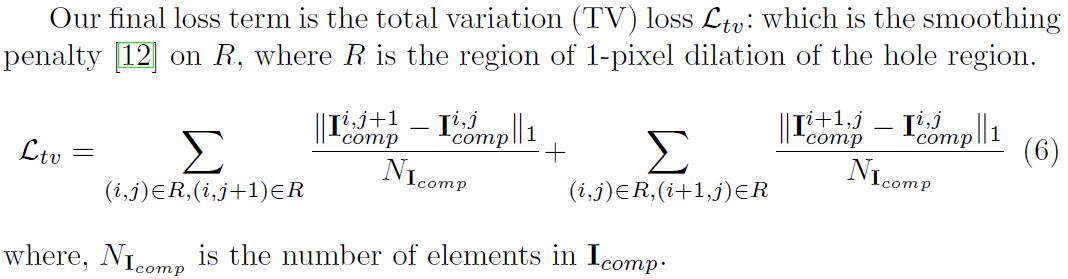
- total loss \(L_{total}\)
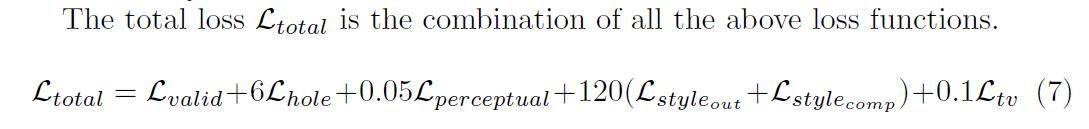
- 定义:
-
Ablation Study of Different Loss Terms(不同损失函数的消融实验)

Experiments
Irregular Mask Dataset
- 所有用于训练和测试的掩膜和图像尺寸为
512×512。 - 我们为训练产生了
55116个Mask,并为测试产生了24866个Mask。 - 在测试的时候对
24866个Mask进行了数据增强。 - 同时,我们更加
Mask的大小,进行分类。
Training Process
Training Data
- 使用3个独立的图像数据集进行训练和测试,
ImageNet数据集,Places2数据集和CelebA-HQ。
Training Procedure
Adam for optimizationBatchSize:6
Initial Training and Fine-Tuning
- 图像缺失,会对批量归一产生影响,因为平均值和方差都将针对缺失像素进行计算,所以在掩蔽位置忽略它们是有意义的。但是,每个应用程序都会逐渐填充空洞,并且通常完全由解码器阶段完成。为了在存在孔的情况下使用批量归一化,我们首先使用0.0002的学习率为初始训练启用批量归一化。然后,我们使用0.00005的学习率进行微调,并冻结网络编码器部分的批量归一化参数。我们在解码器中保持启用批量归一化。这不仅避免了不正确的均值和方差问题,而且还帮助我们实现更快的收敛。
Comparisons
-
与下面四种方法进行了对比:
方法名称 特征 PM PatchMatch, the state-of-the-art non-learning based approach GL Method proposed by Iizuka et al. GntIpt Method proposed by Yu et al. Conv Same network structure as our method but using typical convolutional layers. Loss weights were re-determined via hyperparameter search. PConv ours
Qualitative Comparisons


Quantitative comparisons.
- 评估图像修复结果没有较好的评估方法。
- 评估标准为:
L1 error,PSNR,SSIM,inception score (IS-core)。 - 其中
L1 error,PSNR,SSIM在数据集Places2评估,Inception score (IS-core)在数据集ImageNet评估。
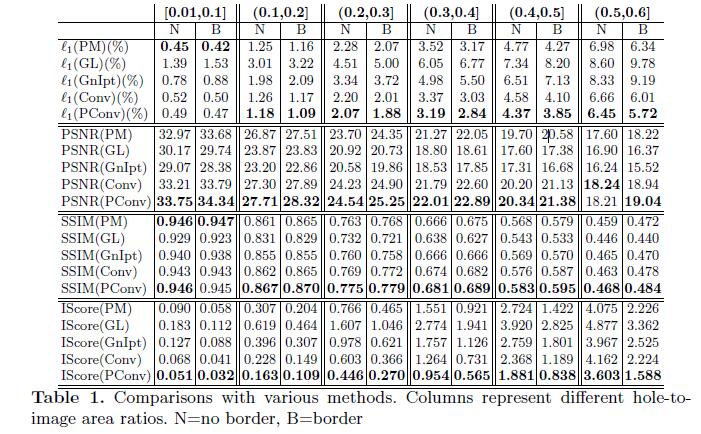
扩展
- 部分卷积应用到图像超分辨率

