卷积 Convolution 原理及可视化
文章抄自 知乎-王贵波
本文主要介绍了卷积 Convolution 的背景、基本原理、特点、与全连接的区别与联系、不同的卷积模式,进行了卷积可视化以及代码实现了一个简单的 2 维卷积操作,并针对卷积操作进行了计算优化。
目录
- 卷积背景及原理
- 卷积的特点(与全连接的区别与联系)
- 卷积的三种模式
- 卷积操作
Numpy简单实现 - 卷积优化实现
卷积背景及原理
卷积操作历史上来发展于信号处理领域,在信号处理中原始信号通常会被混入噪音,假设传感器在每个时刻 \(t\) 会输出一个信号 \(f(t)\),这个信号通常混入了一些噪声,我们可以通过过个测量点进行加权平均来抵消掉噪声,并且离当前时间点 \(t\) 越近的测量点权重应该越高,我们可以用下面的公式表示
上式中\(g\)是一个权重函数,参数是时间点\(t'\)距离当前时间 的\(t\)距离,输出 \(t'\) 时间点测量的权重;\(f\) 是信号测量函数。在这个例子中,\(t'\)的采样是离散的,因此采用了加和的形式,同时 \(g\)还应该是一个概率密度函数,因为在这个例子中表示了一种权重。下图就是这个例子的可视化,灰色是 \(f(t)\),红色的部分就是经过翻转的 \(g\),绿色部分是生成的 \(h\) 。
这个例子实际上就是卷积操作的一种特例,进一步扩展成连续函数,并且对\(g\) 函数没有限制,我们就得到了卷积操作的定义。根据维基百科定义,卷积运算(Convolution)g是一种通过两个函数 \(f\) 和\(g\) 生成第三个函数 \(f\) 的一种数学算子,公式表示如下。通常将函数 称为输入(
input),函数 称为卷积核(
kernel),函数 称为特征图谱(
feature map)
我们考虑离散多维卷积的情况,这个也是深度学习领域最常见的情况,即输入是一个多维数组,卷积核也是一个多维的数组,时间上是离散的,因此无限的积分变成有限的数组有限元素的加和:
上式表明的操作在直观上理解是先对卷积核翻转,然后与输入点乘、求和得到输出。在机器学习领域尤其是深度学习中,卷积的实现通常省去了卷积核翻转这一步,因为深度学习中的卷积核参数是不断学习更新,因此有没有翻转并没有性质上的影响。严格定义上说,深度学习中的卷积实际上是另一种操作:互相关 Cross-Correlation。公式表示如下
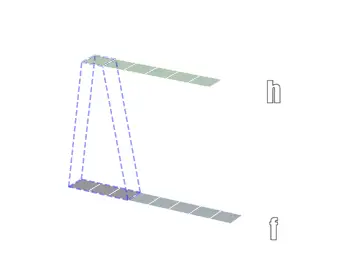
下文中我们忽略卷积核是否被翻转,将严格意义上的互相关和卷积都称作卷积。二维卷积的可视化如下图
卷积的特点(与全连接的区别与联系)
卷积神经网络(Convotional Neural Network, CNN)是深度学习领域中重要的一个领域,可以说 CNN 近年在计算机视觉领域取得的成功直接推动了深度学习的复兴。 CNN 是一种基于卷积操作的神经网络,可以粗略地理解为 CNN 就是将全连接网络中的矩阵相乘换成卷积操作(说粗略是因为通常 CNN 中还带有 pooling 等 CNN 专有的操作)。那么卷积操作有什么区别于全连接的特点呢?
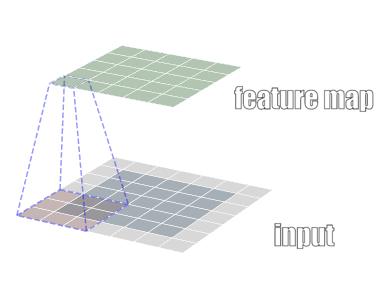
我们以一个例子来看卷积的具体
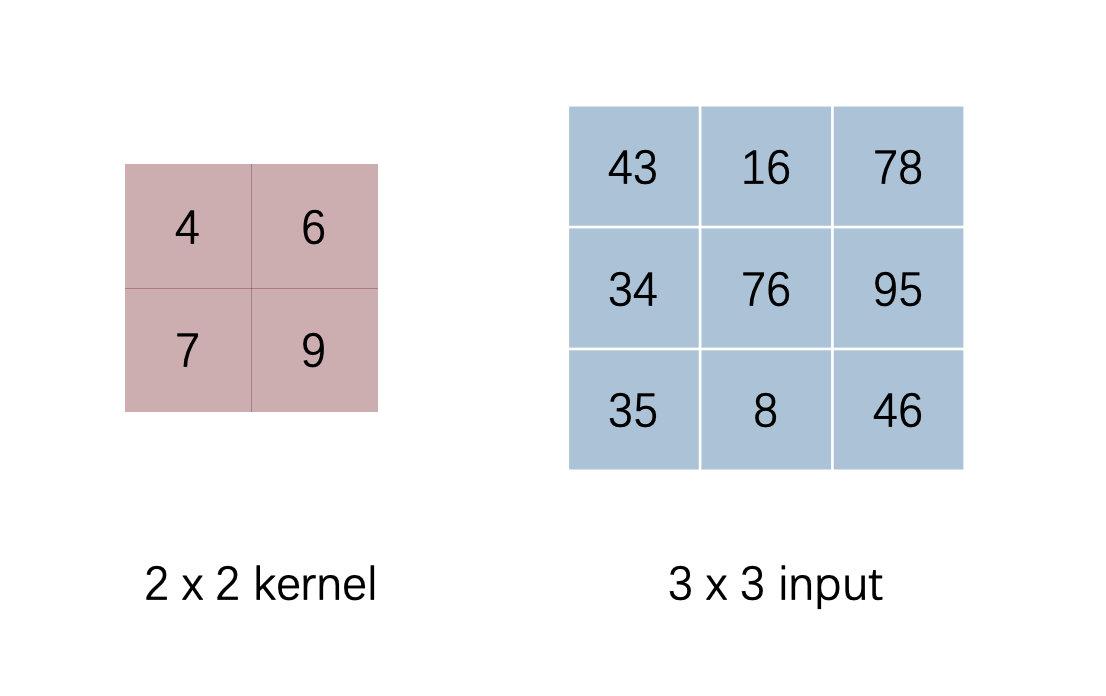
不考虑 padding,以 stride 为 1,那么我们进行卷积计算得到的结果为
我们对 input 和 kernel 分别进行下图的转换,input 展平为一位向量,kernel 在合适的地方填零
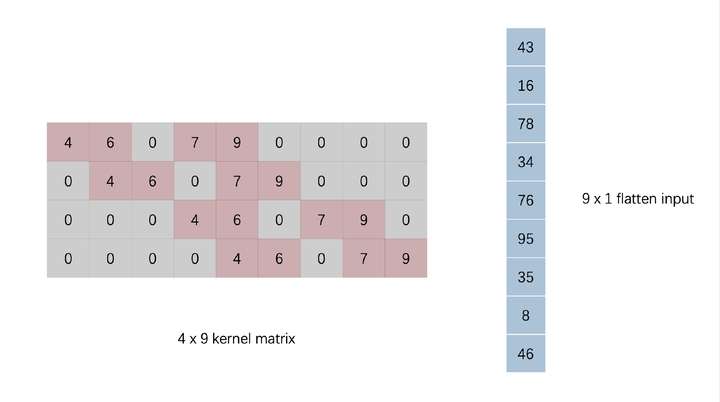
经过这样处理实际上左边的 kernel matrix 乘上右边的 flatten input 向量后得到结果与上面的结果是等效的,即向量的卷积操作可以表示为上图的一个核矩阵乘一个向量得到。有没有觉得很眼熟?这种一个参数矩阵乘一个输入向量得到一个输出向量的形式与全连接是完全一致的。
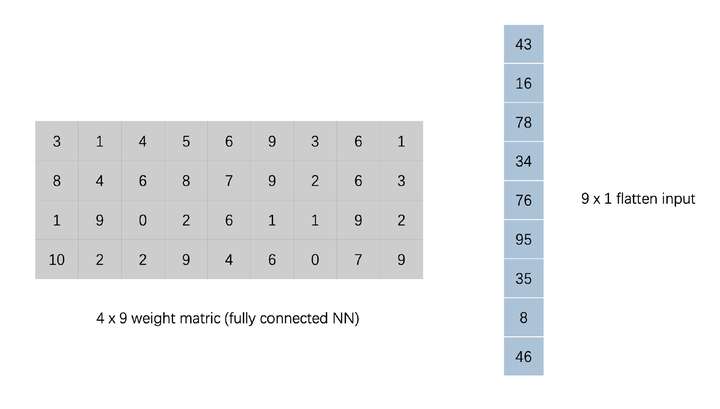
因此卷积和全连接实质上都是一组线性转换,但是卷积相比全连接而言,其参数矩阵更加稀疏,kernel matrix 中很多为零(sparse connectivity),同时非零部分的参数实际上是共享的(parameter sharing)。这两个特点让卷积可以大大减少参数的数量,同时同一套参数(卷积核)在多个地方复用更有利于捕捉局部的特征。相比之下全连接的参数更多,每个参数只负责唯一的连接,计算量、内存需求增大的同时也更加难以训练。
更本质来说,卷积相比全连接实际上是对参数矩阵做了一种先验的限制(矩阵是稀疏的、同时参数复用),这种先验是建立在在高维空间中相邻的数据点存在一定的关系的基础上,比如图像中一个局部之间可能构成一个形状或者一个组件,因此卷积这种操作特别适合应用于图像数据。虽然加入这种先验会让模型损失一定的拟合能力,但是从最终效果上看带来的收益是远远大于拟合能力的损失的。
卷积的三种模式
深度学习框架中通常会实现三种不同的卷积模式,分别是 SAME、VALID、FULL。这三种模式的核心区别在于卷积核进行卷积操作的移动区域不同,进而导致输出的尺寸不同。我们以一个例子来看这三种模式的区别,输入图片的尺寸是 ,卷积核尺寸是
,stride 取 1。
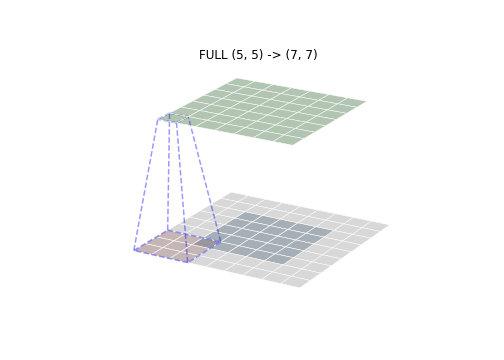
- FULL 模式
FULL 模式下卷积核从与输入有一个点的相交的地方就开始卷积。如下图所示,蓝框的位置就是卷积核第一个卷积的地方,灰色部分是为了卷积能够正常进行的 padding(一般填 0)。因此 FULL 模式下卷积核移动区域最大,卷积后输出的尺寸也最大。
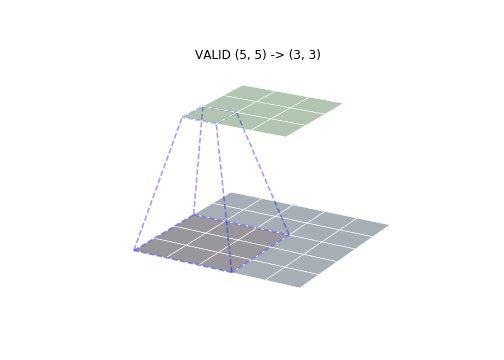
- VALID 模式
VALID 模式与 FULL 模式相反,在整个卷积核与输入重叠的地方才开始卷积操作,因此不需要 padding,输出的尺寸也最小
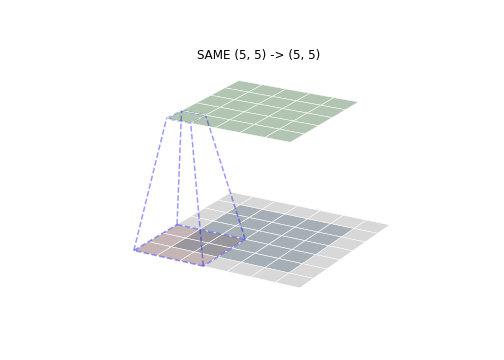
- SAME 模式
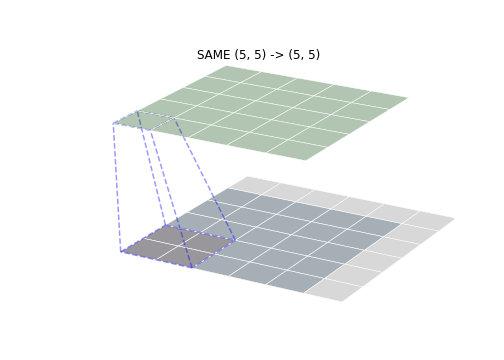
SAME 模式是最常用的一种模式,SAME 的意思是卷积后输出的尺寸与输入尺寸保持一致(假定 stride 为 1)。通过将卷积核的中心与输入的第一个点进行对齐确定卷积核起始位置,然后补齐对应 padding 即可。如下图所示,可以看到卷积输出的尺寸与出入保持一致。
SAME 模式下当卷积核边长为偶数时,可以通过在其中一边增加多一行(列)padding,即不对称的 padding 实现输出尺寸与输入尺寸保持一致,如下图所示(卷积核尺寸为 )
以上三种模式区别在于卷积核进行卷积操作的移动区域不同,其实是确定了所需的 padding。各种模式 padding 计算如下
def get_padding(inputs, ks, mode="SAME"):
"""
Return padding list in different modes.
params: inputs (input array)
params: ks (kernel size) [p, q]
return: padding list [n,m,j,k]
"""
pad = None
if mode == "FULL":
pad = [ks[0] - 1, ks[1] - 1, ks[0] - 1, ks[1] - 1]
elif mode == "VALID":
pad = [0, 0, 0, 0]
elif mode == "SAME":
pad = [(ks[0] - 1) // 2, (ks[1] - 1) // 2,
(ks[0] - 1) // 2, (ks[1] - 1) // 2]
if ks[0] % 2 == 0:
pad[2] += 1
if ks[1] % 2 == 0:
pad[3] += 1
else:
print("Invalid mode")
return pad
确定了输入尺寸、卷积核尺寸、padding 以及 stride,输出的尺寸就被确定下来,可以由以下公式计算。其中 分别是输出、输入尺寸,
是卷积核尺寸,
分别是两侧的 padding。
卷积操作 Numpy 简单实现
解卷积操作的原理后,其实实现起来非常简单,我们可以用代码来实现 2 维卷积操作,代码如下
def conv(inputs, kernel, stride, mode="SAME"):
ks = kernel.shape[:2]
# get_padding
pad = get_padding(inputs, ks, mode="SAME")
padded_inputs = np.pad(inputs, pad_width=((pad[0], pad[2]), (pad[1], pad[3]), (0, 0)), mode="constant")
height, width, channels = inputs.shape
out_width = int((width + pad[0] + pad[2] - ks[0]) / stride + 1)
out_height = int((height + pad[1] + pad[3] - ks[1]) / stride + 1)
outputs = np.empty(shape=(out_height, out_width))
for r, y in enumerate(range(0, padded_inputs.shape[0]-ks[1]+1, stride)):
for c, x in enumerate(range(0, padded_inputs.shape[1]-ks[0]+1, stride)):
outputs[r][c] = np.sum(padded_inputs[y:y+ks[1], x:x+ks[0], :] * kernel)
return outputs
使用一幅图像测试一下
inputs = from_image("./Lenna_test_image.png")
to_image(inputs, save_path="./plots/conv/lenna_origin.png")
# Embossing Filter
kernel_one_channel = np.array([[0.1, 0.1, 0.1], [0.1, -0.8, 0.1], [0.1, 0.1, 0.1]])
kernel = np.stack([kernel_one_channel] * 3, axis=2)
stride = 1
output = conv(inputs, kernel, stride)
to_image(output, grey=True, save_path="./plots/conv/lenna_conv.png")
输入图像和经过卷积的效果如下。


卷积操作 Numpy 简单实现
上面我们是严格按照卷积的流程实现的(点乘 -> 求和 -> 移动卷积核),在上面讨论卷积与全连接的区别时我们讲到只要对卷积核和输入做一定的变化,卷积可以等价转化为矩阵和向量相乘,这样可以提升卷积计算的效率。这里有两种转换方法,一种是对卷积核扩展填充,对输入展平,另一种则是对卷积核展平,对输入扩展填充。这两种方法最后的结果是一直的,我们选择第二种方案进行实现。下图是经过展平的卷积向量与经过扩展的输入矩阵。
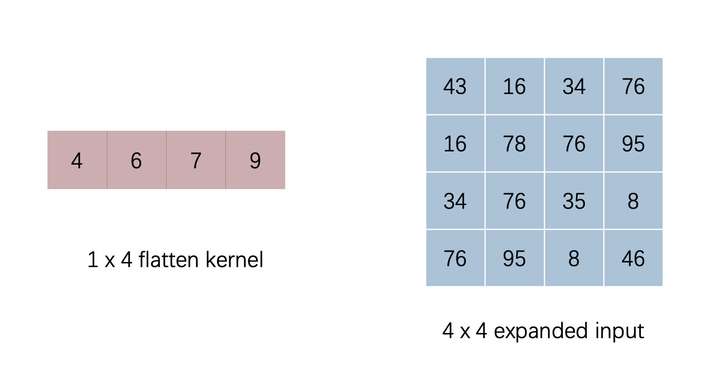
ptyhon 代码实现如下
def conv_matmul(inputs, kernel, stride, mode="SAME"):
ks = kernel.shape[:2]
pad = get_padding(inputs, ks, mode=mode)
padded_inputs = np.pad(inputs, pad_width=((pad[0], pad[2]), (pad[1], pad[3]), (0, 0)), mode="constant")
height, width, channels = inputs.shape
out_width = int((width + pad[0] + pad[2] - ks[0]) / stride + 1)
out_height = int((height + pad[1] + pad[3] - ks[1]) / stride + 1)
rearrange = []
for y in range(0, padded_inputs.shape[0]-ks[1]+1, stride):
for x in range(0, padded_inputs.shape[1]-ks[0]+1, stride):
patch = padded_inputs[y:y+ks[1], x:x+ks[0], :]
rearrange.append(patch.ravel())
rearrange = np.asarray(rearrange).T
kernel = kernel.reshape(1, -1)
return np.matmul(kernel, rearrange).reshape(out_height, out_width)
先验证效果
inputs = from_image("./Lenna_test_image.png")
to_image(inputs, save_path="./plots/conv/lenna_origin.png")
# Embossing Filter
kernel_one_channel = np.array([[0.1, 0.1, 0.1], [0.1, -0.8, 0.1], [0.1, 0.1, 0.1]])
kernel = np.stack([kernel_one_channel] * 3, axis=2)
stride = 1
output = conv_matmul(inputs, kernel, stride)
to_image(output, grey=True, save_path="./plots/conv/lenna_conv.png")

对比下原始实现与优化后的运行时间
n = 5
start = time.time()
for _ in range(n):
output = conv(inputs, kernel, stride=1)
cost1 = float((time.time() - start) / n)
print("raw time cost: %.4fs" % cost1)
start = time.time()
for _ in range(n):
output = conv_matmul(inputs, kernel, stride=1)
cost2 = float((time.time() - start) / n)
print("optimized time cost: %.4fs" % cost2)
reduce = 100 * (cost1 - cost2) / cost1
print("reduce %.2f%% time cost" % reduce)
raw time cost: 0.7281s
optimized time cost: 0.1511s
reduce 79.25% time cost
第一种实现方式在测试图像上平均耗时 0.7281s,优化后的实现方式平均耗时 0.1511s,通过优化的矩阵运算大约能带来 80% 的运算速度提升。
最后本文相关的代码见 这里

