Coherent Semantic Attention for Image Inpainting
文章的基本信息
文章来源: ICCV 2019
下载链接:Code Download
现状: 现存基于学习的图像修复算法生成的内容带有模糊的纹理和扭曲的结构,这是因为局部像素的不连续性导致的。从语义级别的角度来看,局部像素不连续性主要是因为这些方法忽略了语义相关性和缺失区域的特征连续性。
提出的方法: 根据人类修复图片的行为,提出一种带有coherent semantic attention (CSA) layer的基于深度生成模型的方法。
提出方法的作用: 不仅能够保持上下文结构,而且还能通过对缺失区域特征之间的语义相关性进行建模,可以更有效地预测缺失部分。
网络架构: 由两部分组成,粗修复网络和精细修复网络,两个网络都是基于U-Net结构,其中CSA层被嵌入在细修复网络中的编码阶段。
损失函数: 提出一致损失函数consistency loss和块判别器patch discriminator,这两个来进一步稳定训练过程和提升细节。
数据集: CelebA 、Places2 、Paris StreetView
Introduction
图像修复 是合成合理假设的缺失或损坏部分的任务,可用于许多应用程序中,例如删除不需要的物体,完成遮挡的区域,恢复损坏或损坏的部分。
图像修复面临主要的挑战 是 维持全局语义结构并为缺失的区域生成逼真的纹理细节。
传统修复工作总结 :主要是通过纹理合成来实现。Patch-Match algorithm等。存在的缺陷是没有有效地利用上下文信息contextual information来生成缺失部分的内容,从而导致结果包含噪声模式。
最近的修复工作总结 :利用上下文信息contextual information来实现修复,这些方法可以分为两种类型。
- 第一种类型是利用
spatial attention利用周围图像特征来恢复缺失图像区域。这些方法可以确保所生成内容与上下文信息的语义一致性。但是只是在缺失区域为矩形,并且结果显示像素不连续且具有语义鸿沟。 - 第二种类型是对原始图像中的有效像素进行像素丢失情况的预测,这些方法可以正确处理不规则缺失部分,但生成的内容仍然遇到语义错误和边界伪影的问题。
- 上述方法存在的问题是忽略生成内容的语义相关性和特征连续性,这对于图像级别的局部像素连续性至关重要。
人修复图片的过程: 分为构思和修复两个过程。构思阶段,人先观察图像的整体结构,构思缺失部分的内容,这样可以保持图像的全局一致性。在修复阶段,人总是接着之前的线来添加新的线段和颜色。这实际上是确保局部一致性。
CSA(coherent semantic attention layer): 填充缺失区域对应的特征图。具体步骤:最初,用已知区域中最相似的特征Patch初始化未知区域中的每个未知特征Patch。 此后,通过考虑与相邻Patch的空间一致性来迭代优化它们。 因此,第一步可以保证全局语义的一致性,而优化步骤可以保持局部特征的一致性。
网络结构: 将网络结构分为两个步骤,第一步骤为粗修复网络,粗略的生成缺失的部分。第二步为精细修复网络,在编码器encoder阶段嵌入了CSA层,来实现更好的修复。为了让网络训练的过程更容易稳定,提出了一致损失函数,不仅可以测量VGG特征层与CSA层之间的距离,而且还可以测量VGG特征层与CSA解码器中相应层之间的距离。于此同时,还增加了一个块判别器patch discriminator来提升细节信息,训练更快,更稳定。除了一致损失consistency loss,重构损失reconstruction loss,相对平均LS对抗损失relativistic average LS adversarial loss也被合并加入进来。
本文贡献:
- 提出
coherent semantic attention layer来构造缺失区域深层特征之间的相关性。无论缺失的区域是否规则。 - 提出一致损失函数
consistency loss来指导CSA层来学习ground truth的VGG特征。同时块判别器patch discriminator被引入,来实现更好预测结果。 - 实现了高质量的结果,即使修复任务是两个阶段(粗、细修复网络),但是我们的网络在训练的过程是端到端的过程。
Related Works
Image inpainting
- 图像修复分为两类:
- 第一类
Non-learning inpainting approaches,利用低级特征,基于传播相邻信息的方法或者基于patch的方法。 - 第二类
Learning inpainting approaches,学习图像的语义来完成修复任务,并且通常训练卷积神经网络来推断缺失的内容。Context encoders第一个使用卷积神经网络来实现图像修复。(发展流程参考原文)
- 第一类
- 以上论文存在的问题:这些方法未明确考虑有效特征之间的相关性,因此导致完整图像的颜色不一致。
Attention based image inpainting
近来,基于上下文contextual和缺失区域hole regions之间的关系的空间注意力spatial attention通常用于图像修复任务。
| 论文名 | 方法 | 具体操作 |
|---|---|---|
| Contextual Attention [40] | contextual attention layer | searches for a collection of background patches with the highest similarity to the coarse prediction |
| Yan et al. [35] | introduce a shift-net powered by a shift operation and a guidance loss | The shift operation speculates the relationship between the contextual regions in the encoder layer and the associated hole region in the decoder layer. |
| Song et al. [30] | introduce a patch-swap layer | patch-swap layer replaces each patch inside the missing regions of a feature map with the most similar patch on the contextual regions, and the feature map is extracted by VGG network |
| [40]存在的缺陷 | Although [40] has the spatial propagation layer to encourage spatial coherency by the fusion of attention scores, it fails to model the correlations between patches inside the hole regions, which is also the drawbacks of the other two methods. |
Approach
The overall structure
模型包括两个部分:粗修复网络和精细修复网络。这样的结构能够稳定训练和增大感受野receptive fields。整个网络结构图如下:
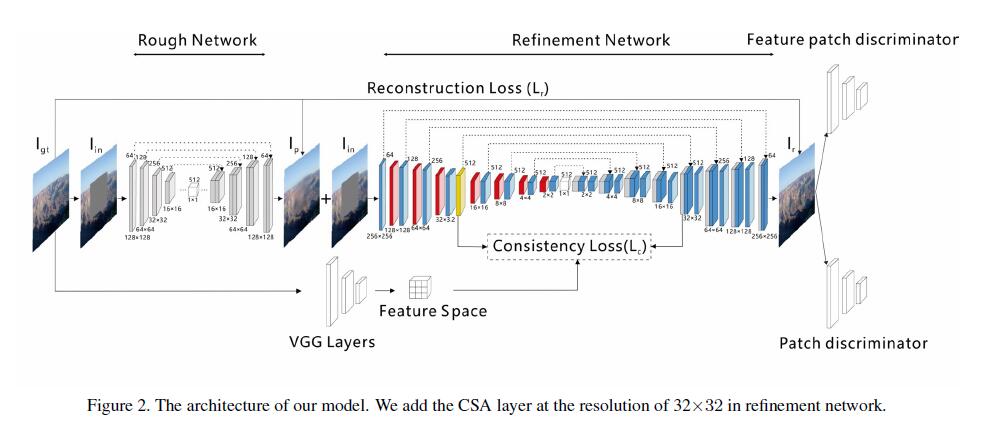
网络参数的定义:
- \(I_{gt}\)表示
ground truth images。\(I_{in}\)表示the input to the rough network。\(I_{p}\)表示粗修复网络输出结构。\(I_{r}\)精细网络的输出结构。
网络的工作流程:
- 首先在粗修复阶段,输入\(I_{in}\)到粗修复网络得到预测结构\(I_{p}\)。
- 然后带有
CSA层的细修复网络将\(I_{p}\)、\(I_{in}\)做为输入对输入到网络,得到最后的结果\(I_r\)。 - 最后patch和feature判别器共同工作得到高分辨率的\(I_r\)。
Rough inpainting
- 粗修复网络的输入\(I_{in}\)是一
个3×256×256的中间缺失或者不规则缺失的图片,输出结果为\(I_{p}\),粗修复网络和这篇文章Image-to-image translation with conditional adversarial networks. CVPR, 2017.的网络结构一样,composed of 4×4 convolutions with skip connections to concatenate the features from each layer of encoder and the corresponding layer of decoder. - 粗修复网络采用
L1 reconstruction loss。
Refinement inpainting
refinement network
- 我们以\(I_{in}\)为条件的\(I_{p}\)做为细修复网络的输入,得到预测的结果\(I_r\)。这种类型的输入会堆叠已知区域的信息,以促使网络更快地捕获有效特征,这对于重建孔区域的内容至关重要。
- 细修复网络包括
encoder和decoder,同时skip connection也被采用,类似于粗修复网络。 - 在
encoder,每一层由3×3的卷积和4×4的空洞卷积dilated convolution构成。3×3卷积保持相同的空间大小,同时通道数量加倍。这种大小的层可以提高获取深度语义信息的能力。4×4扩展的空洞卷积将空间大小减小一半,并保持相同的通道数。 空洞卷积可以扩大感受野,从而可以防止过多的信息丢失。CSA层被嵌入到encoder的第四层。 decoder和encoder对称的,只是没有CSA层,并且所有的卷积是4×4的反卷积deconvolutions。
Coherent Semantic Attention
- \(M\)和\(M^-\)分别表示缺失区域和非缺失区域。
- 作者认为只考虑\(M\)和\(M^-\)的特征层图的关系是不够的,这是因为生成的
patch之间的关系被忽略了,这将会导致最终结果缺乏像素的延展性和连续性。 - 由此,作者提出了
CSA层,在考虑\(M\)和\(M^-\)之间关系的同时,也考虑\(M\)中生成的patch之间的关系。
以缺失区域为中心的矩形为例,解释CSA层的原理:
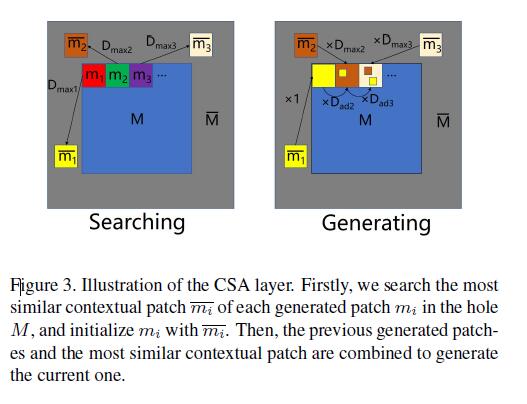
-
CSA层包括两部分,搜索和生成(Searching and Generating)。 -
在搜索阶段,对于每个1×1的生成
patch\(m_i\),其中\(m_i\)属于\(M\),\(i\)属于[1,n],CSA层在\(M^-\)寻找语境最近最匹配的\(m_{i}^-\)来初始化\(m_i\)。 -
在生成阶段,设置\(m_{i}^-\)为恢复\(m_i\)的主要部分,之前生成的
patch(\(m_1\)-\(m_{i-1}\))为次要部分。 -
这两部分的权重由
cross-correlation metric公式得到: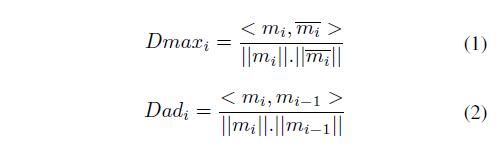 其中\(D_{max_i}\)表示\(m_i\)和最相似的\(m_{i}^-\)之间的相似程度。\(D_{ad_i}\)表示\(m_{i}^-\)两个相邻生成
其中\(D_{max_i}\)表示\(m_i\)和最相似的\(m_{i}^-\)之间的相似程度。\(D_{ad_i}\)表示\(m_{i}^-\)两个相邻生成patch之间的相似程度。 -
将\(D_{max_i}\)和\(D_{ad_i}\)分别归一化(两个加权来为1)分别做为主要部分和次要部分(所有先前生成的
patch)的权重。
CSA的具体工作过程:
Searching: 我首先从\(M^-\)种提取出Patch,然后reshape他们为卷积核大小,然后与\(M\)进行卷积。然后得到一个向量,表示\(M\)中的每一个patch与\(M^-\)中所有patch的cross-correlation。以这为基础,每个生成patch\(m_i\),用最相似的\(m_{i}^-\)初始化\(m_i\)并且分配最大的cross-correlation值\(D_{max_i}\)给它。
Generating: \(M\)左上方的patch被用作生成过程的初始Patch(在图3用\(m_1\)表示)。因为\(m_1\)没有前驱,所以\(D_{ad_1}\)记为0,并且直接用\(m_{1}^-\)代替
\(m_1\),即\(m_1\)=\(m_{1}^-\)。同时,下一个patch\(m_2\)有前驱 \(m_1\),\(m_1\)做为\(m_2\)的附件参考。因此将\(m_1\)做为卷积核,去测量\(m_1\)与\(m_2\)之间的cross-correlation metric的\(D_{ad_2}\),然后归一化\(D_{max_2}\)和\(D_{ad_2}\),分别做为\(m_1\)和\(m_{2}^-\)的权重,得到新生成的\(m_2\),即\(m_2\)=\({D_{ad_2}/(D_{ad_2}+D_{max_2})×m_1+D_{max_2}/(D_{ad_2}+D_{max_2})×m_{2}^-}\)。总结上面的过程,从\(m_1\)到\(m_n\),生成的过程可以总结为: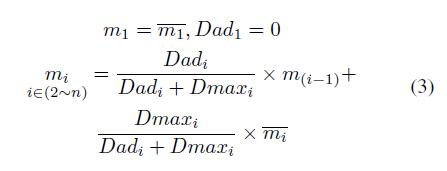
总结: 生成的过程是一个迭代的过程,每一个\(m_i\)包括\(m_{1到i}\)的信息,当我计算根据\(m_i\)和\(m_{i-1}\)计算\(D_{ad_i}\),相应的\(m_i\)和\(m_{1到i-1}\)也被考虑在其中。并且由于\(D_{ad_i}\)值的范围是0到1,因此当前生成的Patch和先前生成的patch之间的相关性随着距离的增加而减小。
Attention map \(A_i\):
CSA层算法:

Consistency loss
- 一些方法[27][23]使用
perceptual loss,来提高网络的恢复能力。 perceptual loss不能直接优化指定的卷积层,这可能会误导CSA层的训练过程。perceptual loss不能确保CSA层之后的特征图与解码器中相应层之间的一致性。- 我们重新设计了
perceptual loss并且提出Consistency loss来结果这个问题。 - 我们使用
ImageNet-pretrained VGG-16来提取原图的高维特征空间。对于\(M\)任意中任意位置,我们将特征空间分别设置为解码器中CSA层和CSA对应层的目标,以计算L2距离。为了匹配特征图的形状,我们采用VGG-16的4-3层作为perceptual loss。perceptual loss定义为: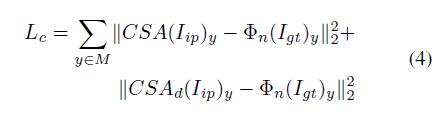 \(φ_n\)
\(φ_n\)VGG-16被选择层的activation map,\(CSA(.)\)表示为CSA层之后的特征,\(CSA_d(.)\)是解码器中的相应特征。 Guidance loss和我们的perceptual loss类似。
Feature Patch Discriminator
-
之前的图像修复网络总是使用一个
local discriminator来提高结果。但是local discriminator是不适合缺失部分为任意形状的情况,借鉴Gated Conv [39], Markovian Gans [21] and SRFeat [25],我们提出了feature patch discriminator检测特征图来区分修复后的图像和原始图像。 -
feature patch discriminator,结合了conventional feature discriminator和patch discriminator,不仅在训练过程中快速且稳定,而且使优化网络合成了更有意义的高频细节。如图: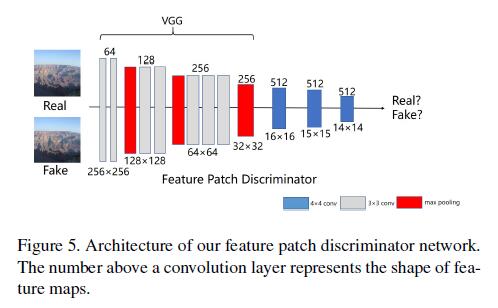 作者使用
作者使用VGG-16在pool3层之后提取特征图,然后将该特征图作为几个下采样层的输入,以捕获Markovain patches的特征统计信息。最终,因为此特征图中每个点的接受域仍可以覆盖整个输入图像,所有作者直在此特征图上计算adversarial loss。 -
除了
feature patch discriminator外,我们使用的70×70的patch discriminator通过类似[25]的方法来检测像素值来区分\(l_r\)和\(l_{gt}\)图像。同时,作者使用Relativistic Average LS adversarial loss做为判别器。这种损失可以帮助细修复网络从对抗训练中生成的数据和实际的数据的梯度中受益,这有利于训练的稳定性。精细网络的GAN损失项\(D_R\)和鉴别器的损失项\(D_F\)定义为: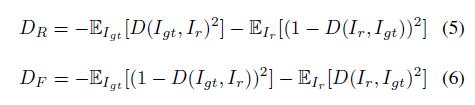 其中\(D\)代表鉴别器,\(E{I_{{gt}/I_f}[.]}\)是指
其中\(D\)代表鉴别器,\(E{I_{{gt}/I_f}[.]}\)是指mini patch所有实/假数据取平均值的操作。
Objective
- 和
[35]一样,我们使用\(L_1\)距离做为我们reconstruction loss,以保证\(I_p\)和\(I_r\)应该近似于真实图像的约束: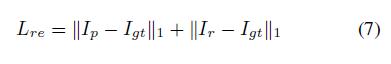
- 考虑
consistency, adversarial, and reconstruct losses,我们的细修复网络和粗修复网络的总体目标定义为: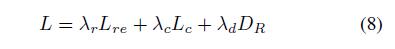 其中,\(λ\)表示权重参数。
其中,\(λ\)表示权重参数。
Experiments
- 测试数据集为:
Places2,CelebA和Paris StreetView。 - 作者使用数据集本身的数据集划分,同时也使用数据增强等操作。
- 模型参数:
- 输入网络的图片大小为:
256×256(training and testing) - 优化器:
Adam algorithm - 学习率:\(2 × 10^{−4}\)和\(β_1=0.5\)
- 总目标函数权重参数:\(λ_1\)=1,\(λ_2\)=0.01,\(λ_3\)=0.002
BatchSize设置为1.- 模型训练花费的时间:
CelebA 9days,Paris StreetView 5 days,Place2 2day。
- 输入网络的图片大小为:
- 与其它论文相比:
CA: Contextual Attention, proposed by Yu et al.SH: Shift-net, proposed by Yan et al.PC: Partial Conv, proposed by Liu et al.GC: Gated Conv, proposed by Yu et al.
- 为了公平的进行评估,我对居中矩形和任意形状的缺失情况,都进行了评估。我们从
PC中得到任意形状缺失的情况的mask,并且跟去mask的大小对其进行分类。- 对于居中矩形缺失的情况,作者在
CelebA和Places2的验证集,将本文提出的方法和CA和SH进行对比。 - 对于任意形状的缺失情况,作者在
Paris StreetView和CelebA验证集,将本文所提出的方法和PC和GC进行了对比。
- 对于居中矩形缺失的情况,作者在
定性比较(Qualitative Comparison)
- 在居中矩形缺失的情况和任意形状的情况,每种方法的表示都做得讲解,并且讲解了效果好与不好的原因,最后的总结是以上这四种方法都没有考虑缺失区域之间深层特征之间的相关性。
- 另外就是
Attention map的问题:第一行是左右相邻像素的注意力图,第二和第三行是上下相邻像素的注意力图。可以注意到两个相邻像素的注意力图基本相同,并且相关区域不限于最相关的上下文区域,注意力图中的弱相关区域是所生成的patch的关注区域,与之相距甚远。 强相关区域是相邻生成的patch和最相关的上下文补丁所关注的领域。

定量比较(Quantitative comparisons)
- 我们从
Celeba验证数据集中随机选择500张图像,并为每个图像生成不规则和居中的缺失部分以进行比较。 - 衡量标准:
L1L2PSNRSSIM 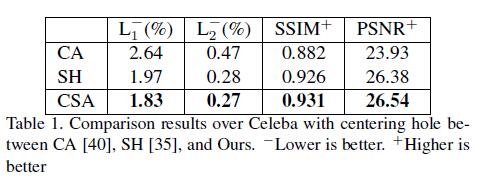
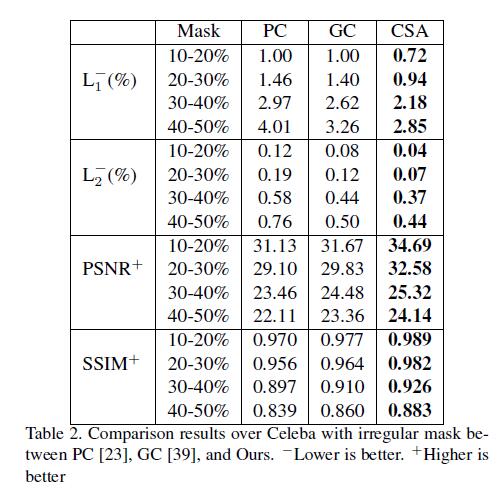 实验结果表明我们的结果在两种情况都优于其他方法。
实验结果表明我们的结果在两种情况都优于其他方法。
Ablation Study(消融研究[对照实验])
Effect of CSA layer
为了评估CSA 层的影响,我们将CSA层替换成3×3的卷积和contextual attention layer分别进行比较,结果如图8(b),使用常规的卷积,缺失部分没办法恢复成较好的结果,尽管contextual attention layer,与传统的卷积相比,它可以改善性能,修复结果仍然缺乏精细的纹理细节,并且像素与背景不一致,如图8(c)。以其他方法相比,我们的性能更好,如图8(d)。这说明CSA层构造了全局语义结构和局部一致性的事实。
Effect of CSA layer at different positions
CSA层的位置太深或太浅都可能导致信息细节丢失或增加计算时间开销。图(9)显示了CSA层在细修复网络第二,第三,第四层下采样的位置,当CSA层第二层,大小为64×64的时候,模型表现出更好的结果,如图9(b)。当CSA层第四层,大小为16×16的时候,模型表现出非常有效率,如图9(c)。当CSA层第三层,大小为32×32的时候,模型表现出最高有效率,如图9(d)。
Effect of consistency loss
如图10所示,可以看出在没有consistency loss情况下,缺失区域中心呈现扭曲结构,这可能是由于训练的不稳定性和对图像语义的误解引起的,如图10(b)。一致性损失consistency loss有助于解决这些问题,如图10(c).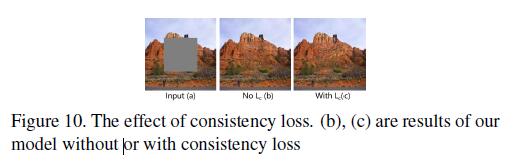
Effect of feature patch discriminator
如图11(b)所示,当我们仅使用patch discriminator时,结果性能会失真。 然后我们添加了传统的特征鉴别器[25],但是生成的内容仍然显得模糊(参见图11(c)。 最后,通过执行feature patch discriminator,可以获得精细的细节和合理的结构(见图11(d)。 而且,feature patch discriminator比传统的[25]更快地处理每个图像0.2秒。
Conclusion
本文提出了一种基于精细深度生成模型的方法,该方法设计了一种新颖的Coherent Semantic Attention layer,以学习图像修复任务中缺失区域的特征之间的关系。 引入一致性损失 consistency loss是为了增强CSA层学习能力,以增强地面真值特征分布和训练稳定性。 此外,feature patch discriminator已加入我们的模型中,以实现更好的预测。 实验已经验证了我们提出的方法的有效性。 将来,我们计划将该方法扩展到其他任务,例如样式转换和单图像超分辨率。

