用户HTTP请求过程简单剖析
用户终端(如电脑浏览器)发起某个url请求,如http://www.baidu.com/1.jpg。
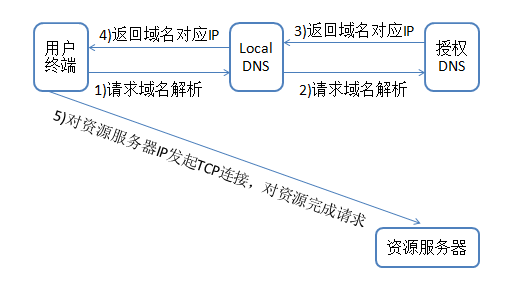
1、电脑首先会对www.baidu.com进行解析请求,获得域名对应的服务器IP。
2、电脑对服务器IP发起建立TCP连接,完成TCP连接之后,GET /1.jpg的资源,而www.baidu.com就会放置在请求头部中的host字段,用于服务器后台识别判断是什么域名下的资源(因为服务器可能同时承载很多其他域名)。过程可参考类似的抓包:
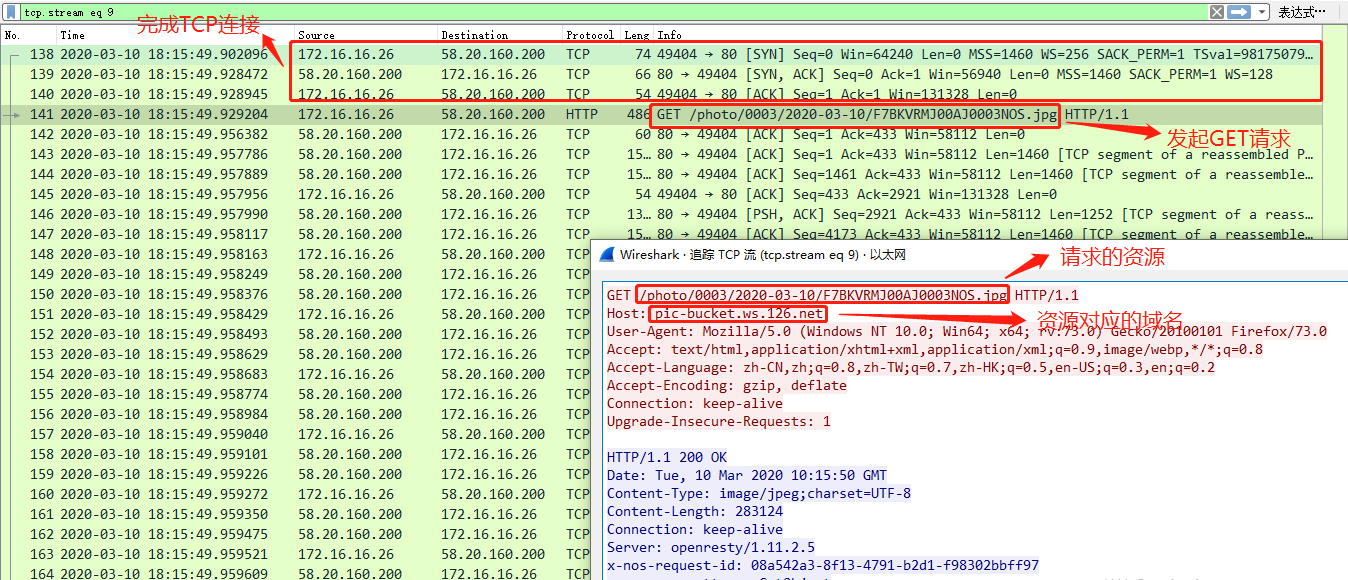
所以域名起到的只是寻址的作用,并不是后台资源的一部分。
如果是已知资源服务器IP(如1.1.1.1),需要在linux模拟浏览器访问:
curl -v "http://www.baidu.com/1.jpg" --resolve "www.baidu.com:80:1.1.1.1"
而非
curl -v "http://www.baidu.com/1.jpg" -x 1.1.1.1:80
因为-x的话,访问的效果会变成:GET http://www.baidu.com/1.jpg
