
大数据基本公式——二:pandas
df.rename('a_name','b_name')
df.columns=(columns={'acolumn':'b-column'})
一:分组;分组,就是第一层查询条件我想
根据什么分组,它的index就是什么
df.groupby(df.animal)['weight'].mean() df.animal这就是index________________________只要长度相同,就可以放到里面,太重要了,57课有说————
不加[]就是对所有列进行.mean()________ 但是即使这样,还可以在后面加['xx']来取到
这个分组的组,可以是一列的名字,也可以是另一个
df对df中的animal进行分组,找出他们的weight,并求平均值. 如果不加weight就把所有能够计算的列mean了
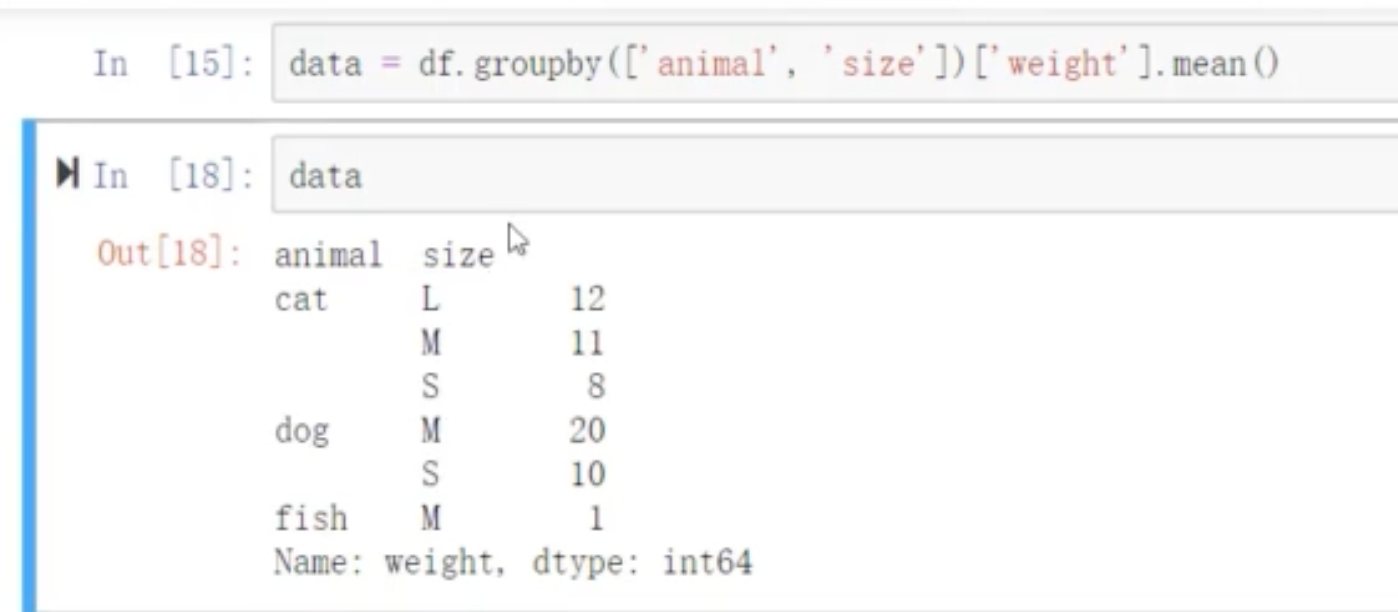
df.groupby(['animal','size'])['weight'].mean() 如果有两个以上,就加到[]————也就有了两个index_所谓multi-index
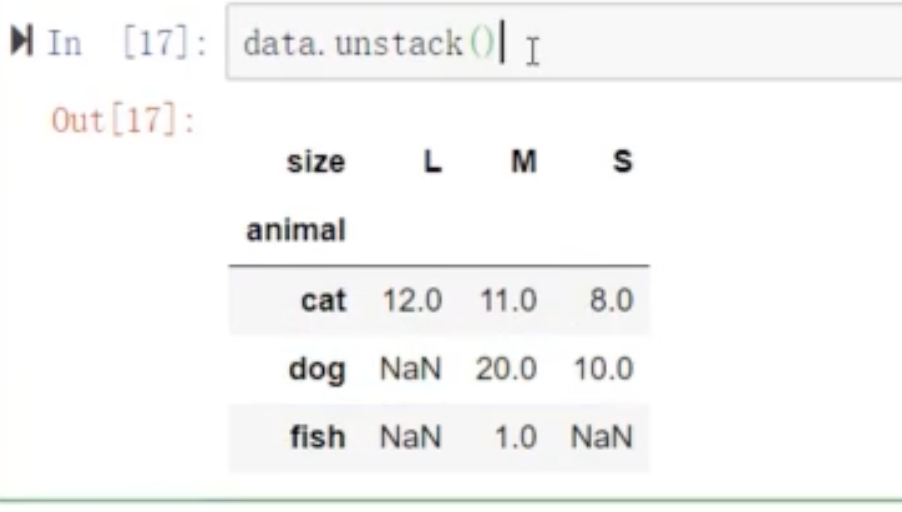
data.unstack() 将index进行一下置换,变成习惯性的index方式的df。针对multii_index也就是多index.内层index变成column___内层index变成column.形成一个小df
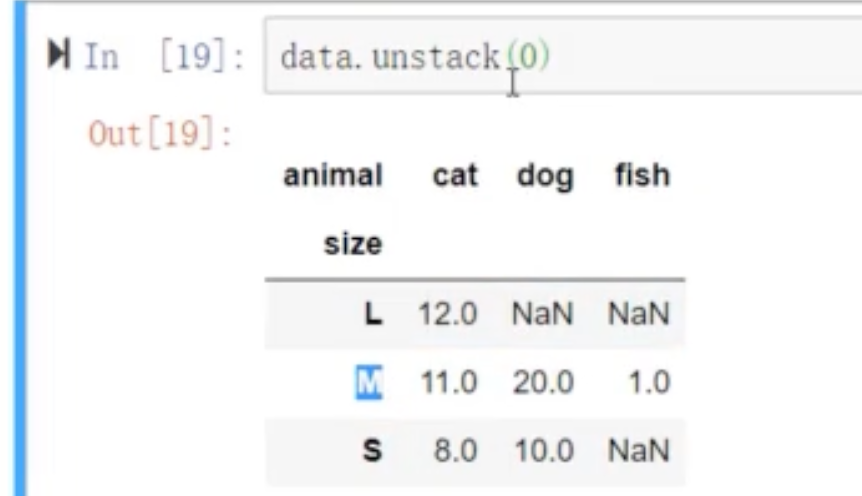
data.unstack(0) 默认将内层index移到上面形成表格,也可变成外层,
data.stack 与之相反
data.reset_index 索引转换为数值
data.set_index('aninal') 将哪一列变为index
data.columns['size','mean'] 重命名columns的复杂方法 data.rename(columns={'size':'mean'}) 做一下映射,,想改哪个就哪个. data.rename(index={'dog':'gou'}

51课重要,重要,重要
data.groupby(['StartDay',''MemberType']).count()
data.groupby(['StartDay',''MemberType']).size()不考虑NaN值
根据什么分组,什么就会成为index.配合着上面的unstack进行调换
下面同上一起参考
二.透视表重新安排列和行
data.pivot_table(index,='mebertype',columns='startday',values='triptime',aggfunc=np.mean). __________行是什么,列是什么,值是什么,方法是什 么
data.groupby(['StartDday','MemberType']).size().unstack().plot.bar(rot=30)
data.groupby(['StartDday','MemberType'])[' TripDurationSec'].mean().unstack().T. _________同透视表:data.pivot_table(index='MemberType',columns='StartDay',values='TripDurationSec',aggfunc=np.mean)
所谓的透视表就是一种data.groupby(['StartDday','MemberType'])[' TripDurationSec'].mean().unstack().T的快捷方式
先告诉人家index和columl及value,以及怎么的aggfunc计算方式
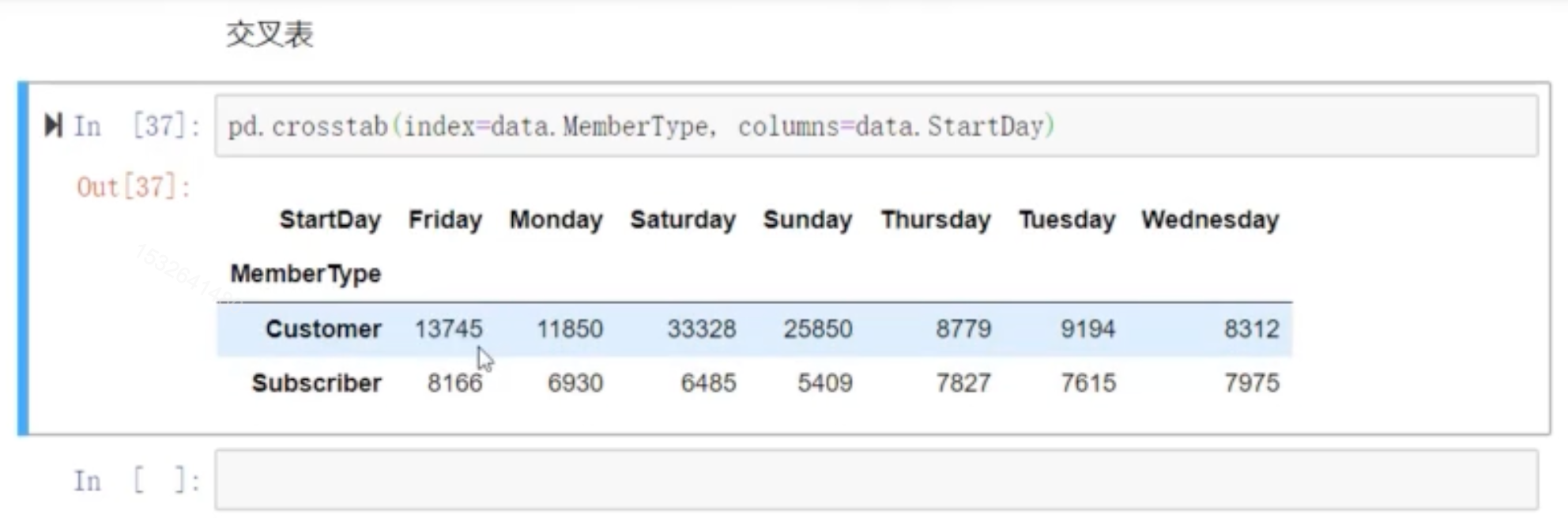
交叉表:
pd.crosstab(index=data.MemberType,columns=data.StartDay)——————最常用的就是计数
快速度算两个项目的出现次数
时间索引(序列)DatetimeIndex
pd.to_datetime(xxx)
index=pd.date_range('2018-2-1','202=18-3-1') 开始-结束
index=pd.date_range('2018-2-1',periods=20) 到20天后
index = pd.date_range('2018.2.1', '2018.2.3', freq='5S') 每融5秒生成一个
index = pd.date_range('2018.2.1', '2018.12.31', freq='BM) 每月最后一个“工作日”
t['2012-1'] 如果是时间序列,直接就把一个月的提出来了
t['2012-1','2013-5'] 如果一个df是/时间序列,直接就把一个月的提出来了
重采样就是把从一个频率重新用另一个频率采样
降采样:
ts.resample('M') 按月重采样
升采样:
设置时间序列:
data = pd.read_csv('./dataset/air1908.csv', index_col='Date', parse_dates=True) parse_dates=True是解析时间的意思
df = df.rename(columns={'村居书记(主任/负责人)': '村居书记_主任_负责人'}) 修改名字
.map() Series有map方法,里面可以对所有元素应用这个函数62课
s.mean() series取均值
s.max() s.min()
'b' in s.index() 判断是否存在
s=pd.series({'a':1,'b':9,'c':4}) 用dict构造series_key就是index
s.isnull() 是不是NaN
df.isnotnull
data.info() 针对列进行统计
data.describe()
np.unique(data) 返回该data的唯一值
df.xxx.value_counts()
df.race.isin(['汉族'])
df.apply()
df.applymap() 对每一个元素应用函数
data.tail()
df.lok[‘one’] 用索引取
df['one':'three'] 用index进行切片时,最后一个值是包函的,和python的数组不一样
df.loc['one':'three',['a','b']] 取前三行,再取里面的前两列。 df.loc['one':'three',['a']] 后面也可以用切片 df.loc['one':'three',['a':'c']]
df.loc[['one':'four'],['a','b']] 同上,如果只取两列,就要放在一个[]中,
df.loc["three","b"] 前面是对行,后面是对列 重点:选范围就不放[] 用:来切,只先哪几行就要用[]括起来。 切片不括,
df.ilok[1:,0]. 按行位置 不抱括最后一位 也是先行后列,前面是表示行. 一句话loc索引,iloc位置 添加行,用loc(append)
df['d']=4. 赋值-添加列
df['d']=4 添加列 df.h=5这样不行,必须中【】
df['d']=np.arrange(4 )
df['d']=pd.Series([2,3,4,5])
del df['e'] 删除列 删除列的话会对原DF直接生效
df.loc['five']=10 添加行
df.drop('one') 删除行 用index当参数 df不变,返回个新的
df.drop(['four','five']) 两行就用list
df.sum() 个数
data.isna()和isnull() 是否为NaN值
data.dropna() series和df中都可以用好像,抛去NaN值__在df中只要有一个缺失值就会删
data.dropna(how='all') 全缺失就会. data.dropna(how='any')删除任意有NaN的值
data.fillna({'aa':,np.nan,'bb':np.nan})
data[np.abs(data>3).any(1)] ___1代表行,axis=1_________太重要了,找出每一行数里有大于3的人
.any()就是这一行只要有一个为True时,就返回,有利于排查大的DF any(1)应该是轴
.all()只有全部为true时才能返回
离散化分析,以分析段为主 哪个级别的粉丝数之类
pd.cut(data,bins=bins,right=false). right这个管包不包括右边,——————categorys这是一种数据类型,专门用来分类57课
pd.cut(data,4)直接输入4就是分成4份
data.isnull().any() 把有null值的人找出来
data.dropna(subset=['location','type']). 抛有空的指定行
data.name.str.replace('beijing','shanghai')
————————drop也可以删除列 df.drop(coumns=['c','f']) ____默认是index
下面我看还是看下面吧,省事,内容也不多
pandas以索引为准 series就是列 Dataframe就是表格 列索引是columns
26课 ————————
s.index
s.value
s=pd.series([1,3,6,2],index=['a','b','c','d'])
'b' in s.index判断B这个INESX是否在index中
s=pd.series({'a':1,'b':9,'c':4})用字典方式构造series
27课
有index,肯定就是定义的index,但是值对不上的话就是NAN
s.isnull()
取反就是~s.isnull()或者isnotnull()_______isnotnull()在series上不能用,只能在dataframe上用
pandas的节片是前后都包括
列索引是columns
用字典创建DataFrame
data=DataFrame({'a':[1,2,3,4],'b':list('abcd'),'c':9,'d':pd.Series([5,6,7,8])})
我理解健就是列,
data.columns列索引 data.index行索引
xuhao=['one','two','three','four']
df=pd.DataFrame(np.random.randn(4,3),index=xuhao,columns=['a','b','c'])
取单列用df['a']或df.b
取多列用df[['a','b']]______用list 又中括号返回多列
取一列返回series取多例返回DF
df.head()
df.tail()
df.values()
28课
loc['one']这样取一行就是一个series,将一行变成了竖着的series 列,将原来column表变成iindex
loc[['one','two']]双中括号取多行就恢复原来的了,取得还是DF
loc['one':'three']切片方式取——————节片不用双【】
loc['one':'three',['a','b']]________分成两部分,前面是行,后面是列
loc['one':'three','a':'c']________分成两部分,前面是行,后面是列,同上,后面也可以切片
总之:切片的时候,不需要将索引放在【】,要精准取就要放到【】
loc前面是行,后面是列
loc[:'three','b':]道理见上
df.iloc[1]按位置
df.iloc[1:]按位置
df.iloc[1:,0]
df.iloc[:2]______不包括这个2——————loc是按index取值 是包括最后一位的而ILOC就和python一样了
总之,一个按索引取值 ,一个按位置取值
29课 增删改查
df['d']=4 添加列 df.h=5这样不行,必须中【】
df['d']=np.arrange(4 )
df['d']=pd.Series([2,3,4,5])
del df['e'] 删除列 删除列的话会对原DF直接生效
df.loc['five']=10 添加行
df.drop('one')删除行 df不变,返回个新的
df.drop(['four','five'])两行就用list
————————drop也可以删除列 df.drop(coumns=['c','f']) ____默认是index
30课
data.sort_index(axis=1,ascending=false)根据索引进行排序_____产生新数据,原数据不变
data.sort_index(axis=1,ascending=false,inplace=true)这就不一样了,立刻生效
data.seort_values(by='c') ascending=false就是降序的意思
data.reindex() columns=['b','c','d','a']_____如果没有的值 ,会让那一列成为NaN值 ————对于series也可以用reindex
同时按照行和列进行对齐
np.mean(data)___如果对DF进行运算的话,默认是在行上进行计算 data.mean data.sun(1)或 data.sun(0)——————对象方法
31课
data.head() data.tail()
data.info() 每一列的情况
data.describe()常见汇总统计结果
data.idxmax(0)每行最大值索引
np.unique(data)返回该data的唯一值
data.iloc[:,-1]取所有的行,取最后一列________后面用.unique() 方法取唯一
data.iloc[:,6].value_counts()
32课
成员关系判断
s.isin(['a','c']) ______一个大表里取出985的同学
data.apply()在data上应用一个函数
data.apply(lamda x:x.max()-x.min(),axis=0) 指定在行上应用,还是在列上应用
data.applymap()对每一个元素运行这个函数 apply这种方法不是向量化的运算,所以速度会慢一些
33课
header=None 有表头就不加,没表头就加
data=pd.read_csv('./xxxx/xxx.txt',sep=''\t)————————分割
data.columns=["age","name","height","wight"]——————给没有column的加columns
data=pd.read_csv('./xxxx/xxx.txt',sep=''\t,sep='\t',header=None,names=["age","name","height","wight"]) 直接添加列名
在read_csv()方法中,index_col比较有用,是指定某一列指定为index
34课,
保存的时候用index=False就不会加一列了
date.to_excel('./xxxx')保存为excel
pd.read_excel('./xxxx',sheetname=1)
pd.to_json('./xxxx')保存为json
data.type____用对象方式选一列
xxx.valut_count()返回一个series,——————然后.index就得到前10种机型
37课横向合并
合并dataframe pd.merge横向合并
data=pd.merge(data1,data2,on='one') 横向合并,增加列 里面的one针对ONE这一列进行合并。——————针对one这一列进行交集合并
案例中的意思是如果有两个表,一个是姓名年纪,一个是姓名身高,这种方式合并。这样相当于多加列。只保留共有的元素
data=pd.merge(data1,data2,how='outer') 并集———— inner是交集(默认) left以左边为准同样right就是右边为准
data=pd.merge(data1,data2,left_on='one1',right_on='one2') 如果两个表的列都不一样,就要指定左边根据哪一列,右边根据哪一列
data=pd.merge(data1,data2,left_index='True',right_index='True',how='outer') 两边都要有true
data1.join(data2)快速合并,这种合并要求较高,用index合并,要求没有重叠的列
用谁来join就以谁为准,data2 如果没有就填充为
38 纵向合并
pd.assign(three=np.arange(6)) 用来单独增加一列
纵向合并 concat([]) 里面是个列表 pd.concat()默认是纵向合并,但参数调整后也可以横向合并
横向好像是用merge--61课有提
ignore_index=True 用了这个,就会用新的index相当于新数据了我想
39课 重复值
data.duplicated()找到重复的布尔值 ___keep='first'
duplicate也可以加subset=['followers','name']之类.可以多加几个条件防止误删——————55课重要
(data.duplicated()).sun() 有几行是重复的呢
data.drop_duplicated() ___data.drop_duplicated('k1')根据K1进行去重
data['k3']=1 给dataframe增加一列
data.drop_duplicated(['k1','k3']) 根据K1和K3去重————重要,根据几行的值决定去重
data.ki.replace('two','three') _____相当于在series上运行了replace方法
data.replace(1,100)把1替换成100,应该是在DF上所有的1
inplace=True一般在修改df的时候会返回一个新DF,但如果加了inplace=True就会让原来的DF立刻生效
40课
sum()运算
isnull() 和notnull()
data.dropna() 抛去所有NaN的值 比较极端
data.dropna(how='all') 所以用这个,只有全为NAN时才删除,这是另一种极端
data.dropna(subset=['location','type']) 这两行任何一个有NaN就抛弃drop掉
如果删除全是NAN的列就用
data.dropna(axis=1,how='all') 列为1,行为0
data.isna()
df['column_name'].isna().any() 如果返回 True,说明该列中有 NaN 值。
填充缺失值
data.fillna(0)
data.fillna({'aa':1,'bb':2}])选择列来填充NAN
data.fillna(data.mean())————————有一些数不能被抛弃的太厉害,所以用一些均值
day41 字符串方法
data.k1.str.replace('beijing','shanghai')
data.k1.str.s('')
strip()去空, split()分割 map方法 再看
42课,
.any()就是这一行只要有一个为True时,就返回,有利于排查大的DF any(1)应该是轴
.all()只有全部为true时才能返回
np.sign()用得少
离散化分析————先定bins,这是划分标准,看看整 个数据的分段情况
data=pd.DataFrame(np.random.randint(1,100,(50,2)))
bins=[0,20,40,60,80,100]
cat=pd.cut(data.iloc[:,0],bins=bins,right=true) right=true就是不包括右边的最大值 right=False就是左开右闭
下面是简写方式
cat=pd.cut(data.iloc[:,0],4)____简单分成4份___由最小的值到最大的值进行等分
cat=pd.qcut(data.iloc[:,0],4)
cat.value_counts()
43课
data.dropna(subset=['location','type']) 这两行任何一个有NaN就抛弃drop掉
data.fillna(0) .sum()的前面应该要用一个0
44课
取列用df['a']或df.b
取列用df['a']或df.b

