韩顺平Java(持续更新中)
原创上课笔记,转载请注明出处
第一章 面向对象编程(中级部分) PDF为主
1.1 IDEA
- 删除当前行,ctrl+y
- 复制当前行,ctrl+d
- 补全代码,alt+/
- 添加或者取消注释,ctrl+/
- 导入该行需要的类,alt+enter
- 快速格式化代码,ctrl+ALT+L
- 快速运行程序,alt+r(自己设置)
- 生成构造器等,alt+insert
- 查看一个类的层级关系,ctrl+H,继承有用(光标放在类名上)
- 快速定位某个方法的位置,ctrl+B(ctrl+鼠标点击)
- 自动分配变量,main方法中,.var,例如new Scanner(System.in).var
查看快捷键模板:Live Templates (例如,fori)
1.2 Object类详解(equals、==、hashCode等)
所有类都实现了Object类,都能使用Object类的方法。
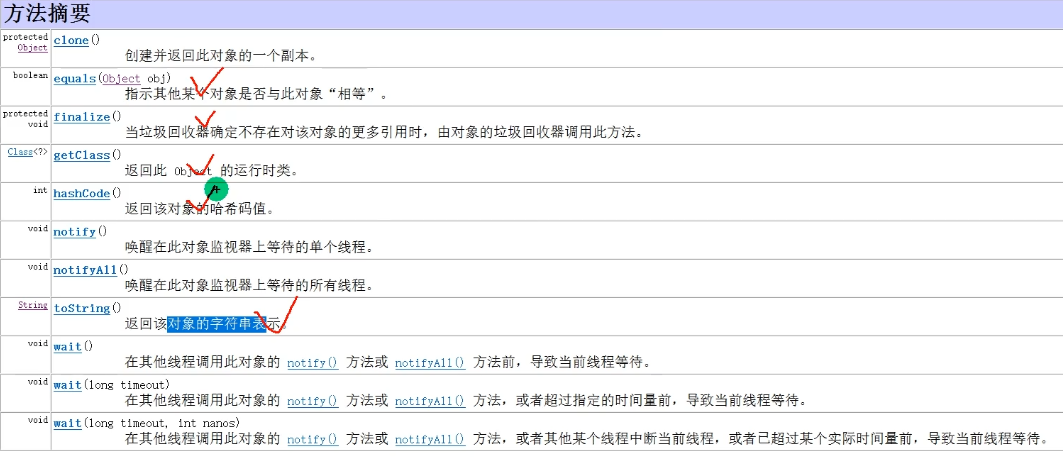
1.2.1 ==运算符

基本类型—>判断值是否相等
引用类型—>判断地址是否相等
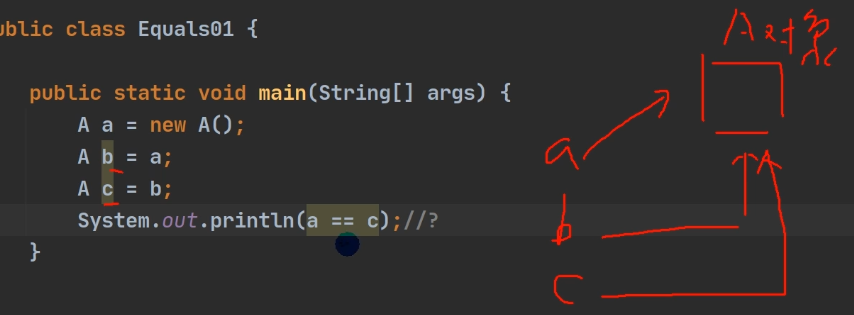
指向同一个地址,结果为true
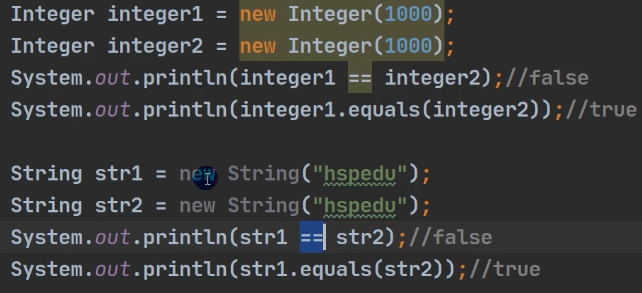
1.2.2 equals()方法
1.2.2.1 基本介绍
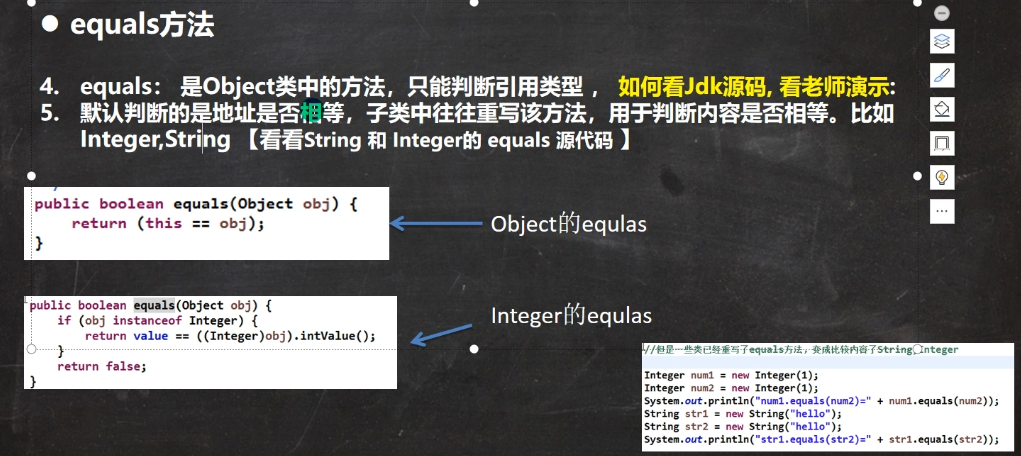
Object的equals()一目了然,==运算符,用来判断地址是否相等
而String等类的equals()被重写了,用来判断内容是否相等(根据需求,判断内容相等的标准也是可能会有所改变的)
如何重写equals方法:
Person person1 = new Person("jack", 10, '男');
Person person2 = new Person("jack", 20, '男');
System.out.println(person1.equals(person2));//假,如果没有重写Person类的equals方法,这里的equals方法调用的Object的(即,判断的是地址)
示例代码:
//重写Object 的 equals方法
public boolean equals(Object obj) {
//判断如果比较的两个对象是同一个对象,则直接返回true
if(this == obj) {
return true;
}
//类型判断
if(obj instanceof Person) {//是Person,我们才比较
//进行 向下转型, 因为我需要得到obj的 各个属性
Person p = (Person)obj;
return this.name.equals(p.name) && this.age == p.age && this.gender == p.gender;
}
//如果不是Person ,则直接返回false
return false;
}
1.2.2.2 课堂练习
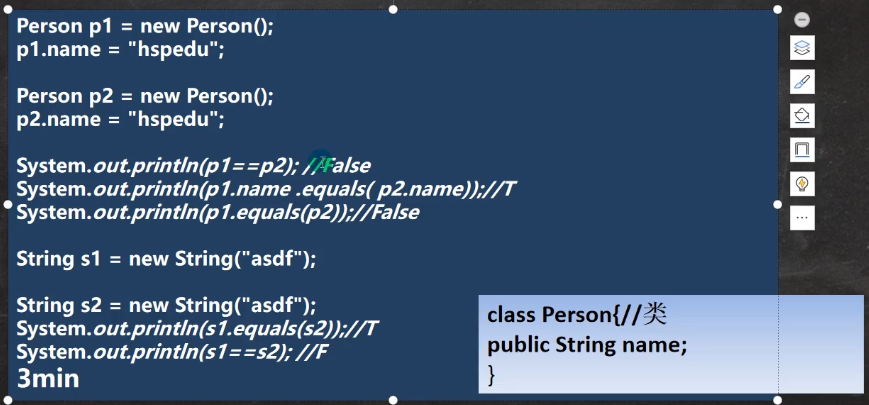
第三个输出:因为Person并没有重写equals,所以这里调用的equals方法是Object的,判断地址是否相同的,而这两个新的对象肯定不相等,所以返回false

这道题需要注意的是,基本数据类型的==运算符是判断内容的
1.2.3 hashCode()方法

1.2.4 toString()方法
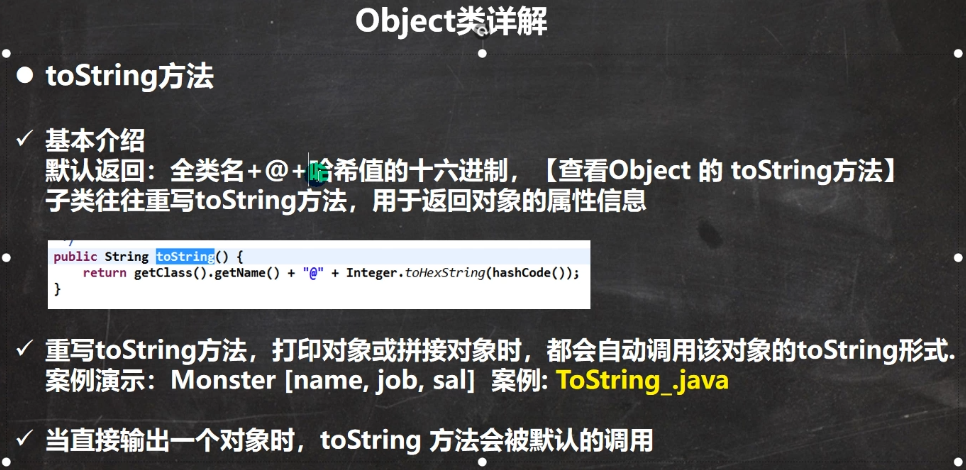
全类名:包名+类名
/**Object的toString() 源码
(1)getClass().getName() 类的全类名(包名+类名 )
(2)Integer.toHexString(hashCode()) 将对象的hashCode值转成16进制字符串
*/
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
1.2.5 finalize()方法

public class Finalize_ {
public static void main(String[] args) {
Car bmw = new Car("宝马");
//这时 car对象就是一个垃圾,垃圾回收器就会回收(销毁)对象, 在销毁对象前,会调用该对象的finalize方法
//,程序员就可以在 finalize中,写自己的业务逻辑代码(比如释放资源:数据库连接,或者打开文件..)
//,如果程序员不重写 finalize,那么就会调用 Object类的 finalize, 即默认处理
//,如果程序员重写了finalize, 就可以实现自己的逻辑
bmw = null;
System.gc();//主动调用垃圾回收器
System.out.println("程序退出了....");
}
}
class Car {
private String name;
//属性, 资源。。
public Car(String name) {
this.name = name;
}
//重写finalize
@Override
protected void finalize() throws Throwable {
System.out.println("我们销毁 汽车" + name );
System.out.println("释放了某些资源...");
}
}
1.3 面向对象的三大特征(封装、继承、多态)
面向对象的三大特征:封装、继承、多态。
1.3.1 封装

好处:隐藏实现的细节、可以对数据进行验证
实现的步骤:

封装与构造器:
/有三个属性的构造器
public Person(String name, int age, double salary) {
// this.name = name;
// this.age = age;
// this.salary = salary;
//我们可以将 set 方法写在构造器中,这样仍然可以验证
setName(name);
setAge(age);
setSalary(salary);
}
1.3.2 继承
提升代码的复用性、便于代码维护和扩展

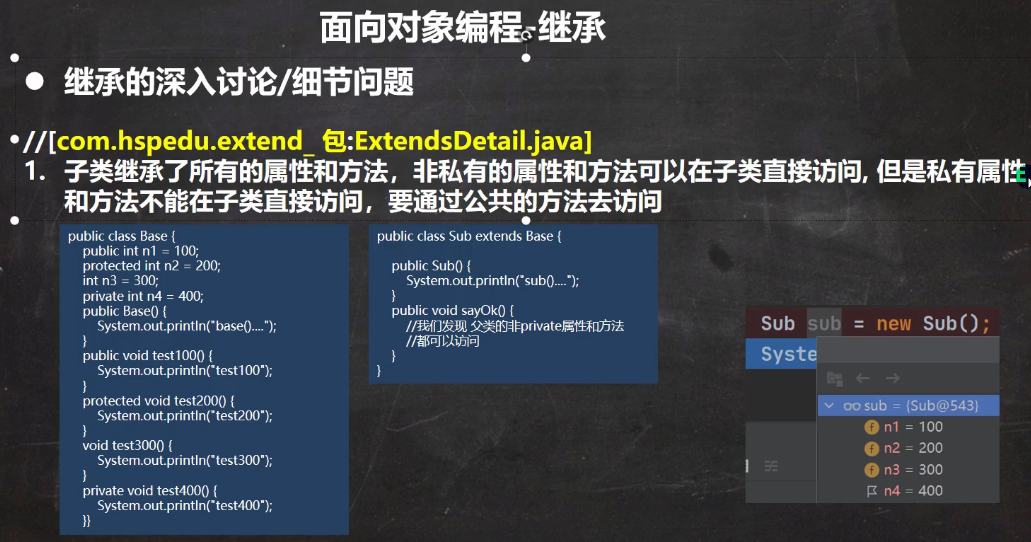

-
注意:子类构造器内部有个默认隐藏的super()方法,调用父类的构造器。(子类构造器中不显示super指明父类构造器的话,就是默认调用父类无参构造器)。
-
当定义了一个有参构造器且没有显式定义无参构造器的话,那么默认的无参构造器就会被有参构造器覆盖。子类此时必须在所有构造器中用super指明调用的哪个父类构造器。

-
super在普通方法也能用,调用父类对应的方法
-
这个细节一定要注意
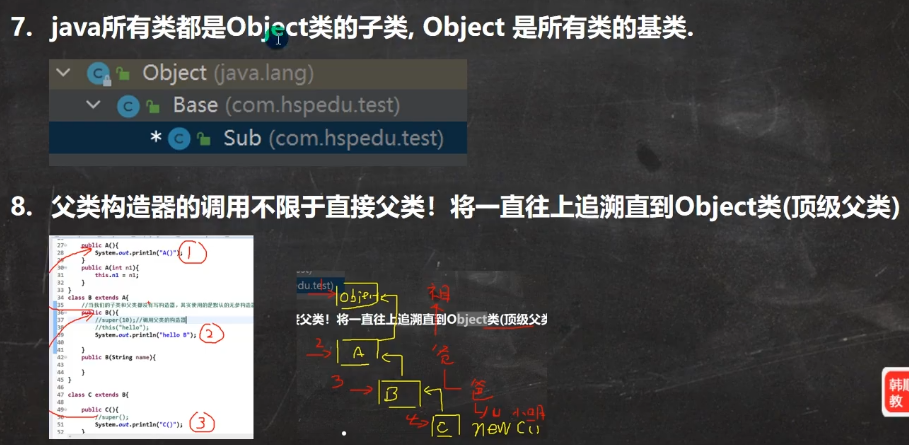
- 从当前类往上一直追溯到Object类,然后从Object类一直调用构造器方法到当前类

继承的本质分析(重要):

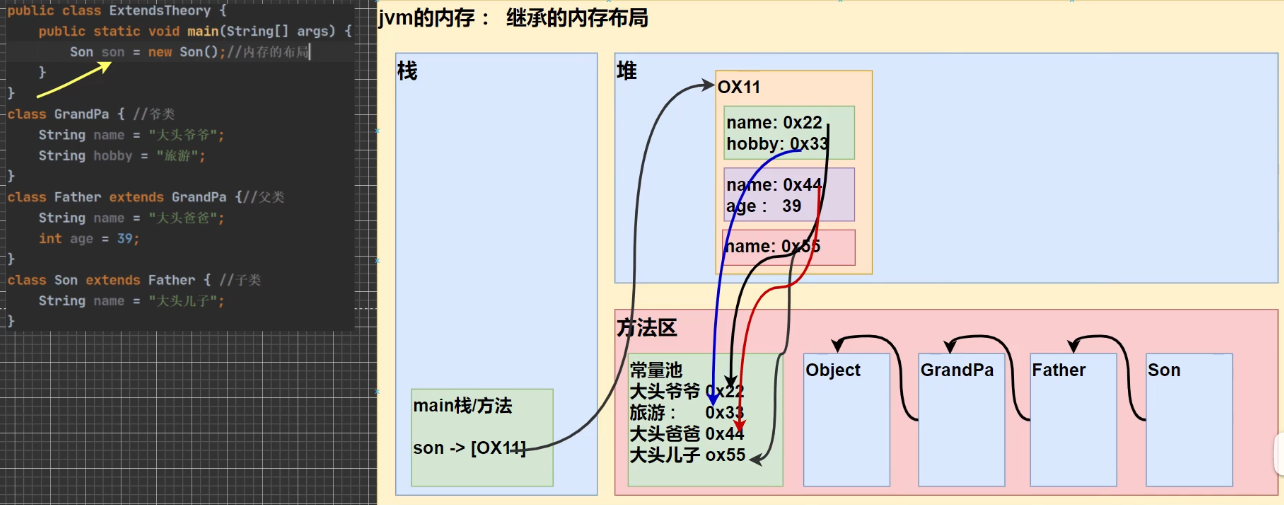
public class ExtendsTheory {
public static void main(String[] args) {
Son son = new Son();//内存的布局
//?-> 这时请大家注意,要按照查找关系来返回信息(就近原则,自己没有就找父亲,父亲没有就找爷爷)
//(1) 首先看子类是否有该属性
//(2) 如果子类有这个属性,并且可以访问,则返回信息
//(3) 如果子类没有这个属性,就看父类有没有这个属性(如果父类有该属性,并且可以访问,就返回信息..)
//(4) 如果父类没有就按照(3)的规则,继续找上级父类,直到Object...
System.out.println(son.name);//返回就是大头儿子
//System.out.println(son.age);//返回的就是39
//System.out.println(son.getAge());//返回的就是39
System.out.println(son.hobby);//返回的就是旅游
}
}
class GrandPa { //爷类
String name = "大头爷爷";
String hobby = "旅游";
}
class Father extends GrandPa {//父类
String name = "大头爸爸";
private int age = 39;
public int getAge() {
return age;
}
}
class Son extends Father { //子类
String name = "大头儿子";
}
注意一点:当打印son.age的时候,此时Son类没有age这个属性,于是去Father中寻找,但是这个age是私有的,此时编译器就会报错,若要访问,就要调用getAge()方法。(如果Father类中也没有age,就去GranPa中寻找)
此外,在现在这个代码情况下,想要访问GrandPa中的age属性(假设爷爷类中有age这个属性),需要在爷爷中创建一个不重名的get方法,并调用。
课堂练习:

这个题需要提醒一下,this会调用B的构造器,this(“abc")会调用B的有参构造器,而且this调用构造器,会有super(),如果再写一个super就冲突(这也是为什么super和this不能共存,指访问构造器)。

注意执行顺序,往上找super
1.3.3 super关键字

super使用细节:
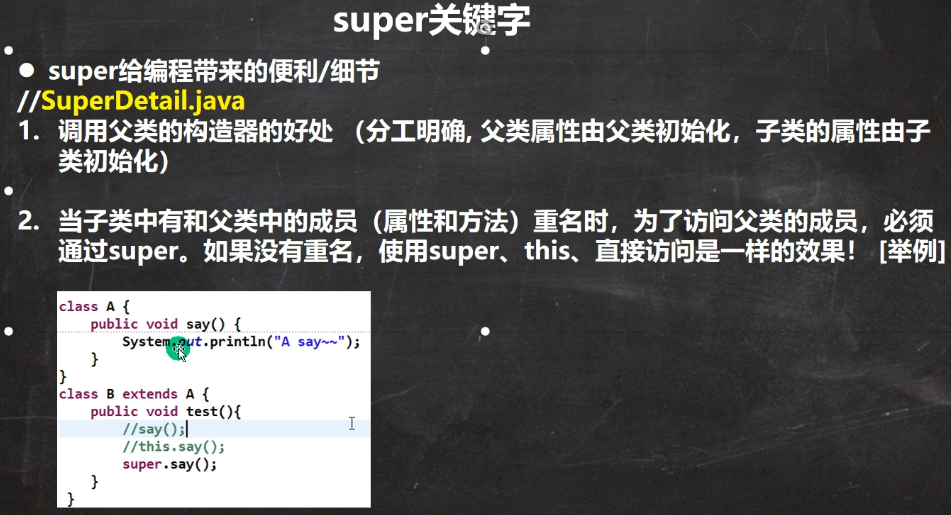
public class B extends A {
public int n1 = 888;
//编写测试方法
public void test() {
//super的访问不限于直接父类,如果爷爷类和本类中有同名的成员,也可以使用super去访问爷爷类的成员;
// 如果多个基类(上级类)中都有同名的成员,使用super访问遵循就近原则。A->B->C
System.out.println("super.n1=" + super.n1);
super.cal();
}
//访问父类的属性 , 但不能访问父类的private属性 [案例]super.属性名
public void hi() {
System.out.println(super.n1 + " " + super.n2 + " " + super.n3 );
}
public void cal() {
System.out.println("B类的cal() 方法...");
}
public void sum() {
System.out.println("B类的sum()");
//希望调用父类-A 的cal方法
//这时,因为子类B没有cal方法,因此我可以使用下面三种方式
//找cal方法时(cal() 和 this.cal()),顺序是:
// (1)先找本类,如果有,则调用
// (2)如果没有,则找父类(如果有,并可以调用,则调用)
// (3)如果父类没有,则继续找父类的父类,整个规则,就是一样的,直到 Object类
// 提示:如果查找方法的过程中,找到了,但是不能访问(比如私有方法), 则报错, cannot access
// 如果查找方法的过程中,没有找到,则提示方法不存在
//cal();
this.cal(); //等价 cal
//找cal方法(super.call()) 的顺序是直接查找父类,其他的规则一样
//super.cal();
//演示访问属性的规则
//n1 和 this.n1 查找的规则是
//(1) 先找本类,如果有,则调用
//(2) 如果没有,则找父类(如果有,并可以调用,则调用)
//(3) 如果父类没有,则继续找父类的父类,整个规则,就是一样的,直到 Object类
// 提示:如果查找属性的过程中,找到了,但是不能访问, 则报错, cannot access
// 如果查找属性的过程中,没有找到,则提示属性不存在
System.out.println(n1);
System.out.println(this.n1);
//找n1 (super.n1) 的顺序是直接查找父类属性,其他的规则一样
System.out.println(super.n1);
}
//访问父类的方法,不能访问父类的private方法 super.方法名(参数列表);
public void ok() {
super.test100();
super.test200();
super.test300();
//super.test400();//不能访问父类private方法
}
//访问父类的构造器(这点前面用过):super(参数列表);只能放在构造器的第一句,只能出现一句!
public B() {
//super();
//super("jack", 10);
super("jack");
}
}

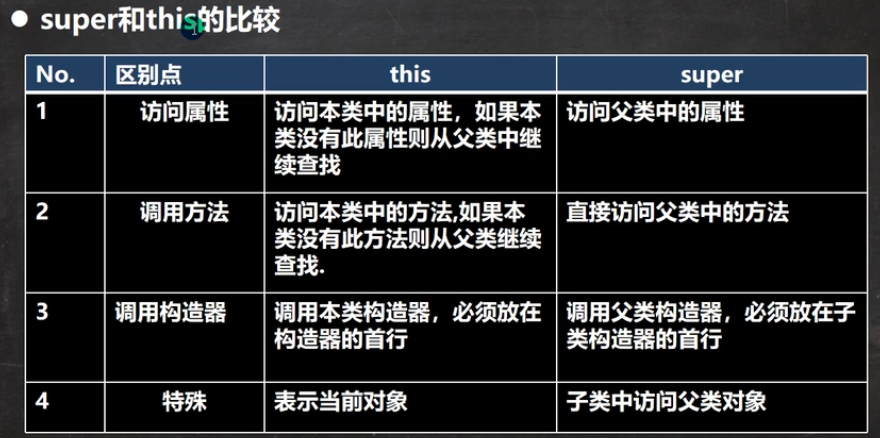
super和this的比较:
1.3.4 重写/覆盖


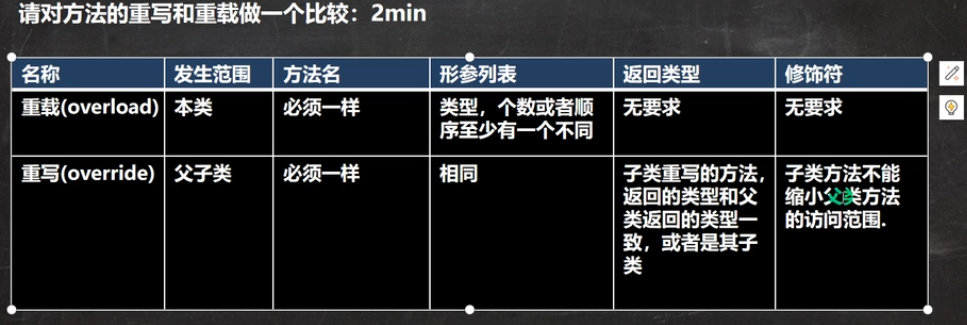
重写(override)与重载(overload)的比较:
1.3.5 多态*
1.3.5.1 引出问题
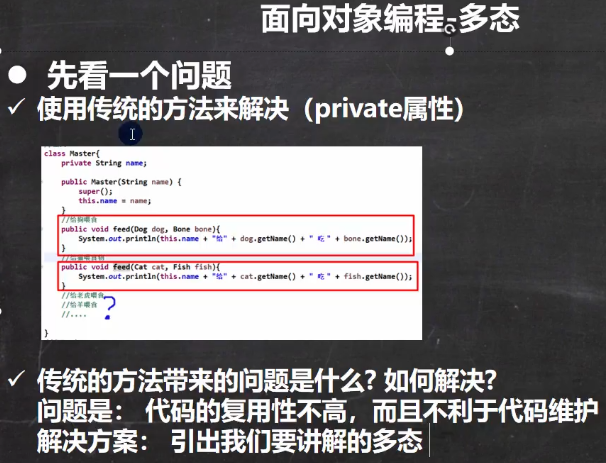
待解决的问题:当对象不同时,需要调用的方法不一样,如果没有多态的话,我们可能就会根据不同对象的种类数重载同一个方法很多次,这样代码的复用性不高,不利于代码维护。
1.3.5.2 基本介绍
多态的具体体现:方法的多态和对象的多态


因为编译类型的对象可以重新指向其他的运行类型,所以运行类型可以改变。运行类型是Java实际执行时的类型,编译类型是编译器识别的。
P308 一段代码的比较,使用了多态前后:animal是dog、cat的父类
//使用多态机制,可以统一的管理主人喂食的问题
//animal 编译类型是Animal,可以指向(接收) Animal子类的对象
//food 编译类型是Food ,可以指向(接收) Food子类的对象
public void feed(Animal animal, Food food) {
System.out.println("主人 " + name + " 给 " + animal.getName() + " 吃 " + food.getName());
}
//主人给小狗 喂食 骨头
// public void feed(Dog dog, Bone bone) {
// System.out.println("主人 " + name + " 给 " + dog.getName() + " 吃 " + bone.getName());
// }
// //主人给 小猫喂 黄花鱼
// public void feed(Cat cat, Fish fish) {
// System.out.println("主人 " + name + " 给 " + cat.getName() + " 吃 " + fish.getName());
// }
//如果动物很多,食物很多
//===> feed 方法很多,不利于管理和维护
//Pig --> Rice
//Tiger ---> meat ...
//...
向上转型:(转型向上还是向下,针对的是等号=右边的类型,相对于它是向上转父类,还是向下转子类)
父类的引用指向了子类的对象
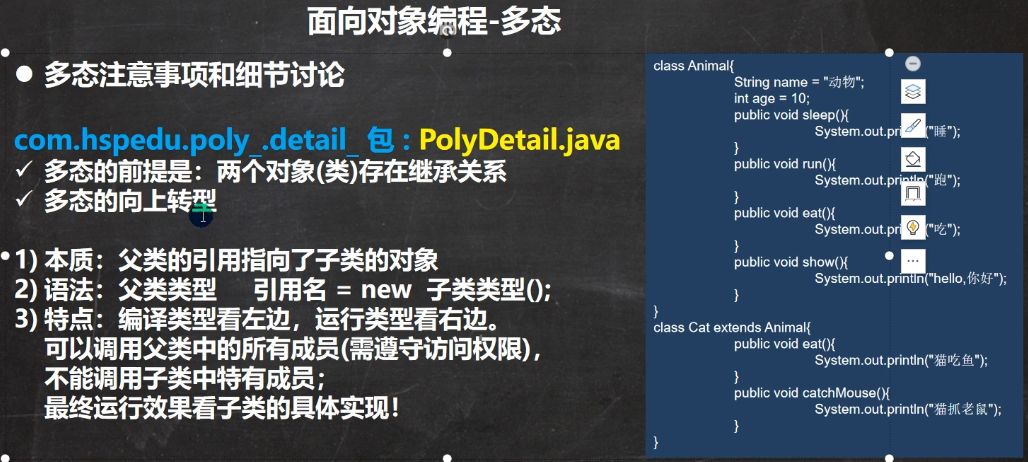
//向上转型: 父类的引用指向了子类的对象
//语法:父类类型引用名 = new 子类类型();
Animal animal = new Cat();
Object obj = new Cat();//可以吗? 可以 Object 也是 Cat的父类
//向上转型调用方法的规则如下:
//(1)可以调用父类中的所有成员(需遵守访问权限)
//(2)但是不能调用子类的特有的成员
//(#)因为在编译阶段,能调用哪些成员,是由编译类型来决定的
//animal.catchMouse();错误
//(4)最终运行效果看子类(运行类型)的具体实现, 即调用方法时,按照从子类(运行类型)开始查找方法
//,然后调用,规则我前面我们讲的方法调用规则一致。
animal.eat();//猫吃鱼..
animal.run();//跑
animal.show();//hello,你好
animal.sleep();//睡
向下转型:

//老师希望,可以调用Cat的 catchMouse方法
//多态的向下转型
//(1)语法:子类类型 引用名 =(子类类型)父类引用;
//问一个问题? cat 的编译类型 Cat,运行类型是 Cat
Cat cat = (Cat) animal;
cat.catchMouse();//猫抓老鼠
//(2)要求父类的引用必须指向的是当前目标类型的对象
Dog dog = (Dog) animal; //可以吗?
System.out.println("ok~~");
1.3.5.3 多态的细节
-
属性重写问题
属性的调用是看编译类型,而方法是看运行类型
属性没有重写之说!属性的值看编译类型
public class PolyDetail02 { public static void main(String[] args) { //属性没有重写之说!属性的值看编译类型 Base base = new Sub();//向上转型 System.out.println(base.count);// ? 看编译类型 10 Sub sub = new Sub(); System.out.println(sub.count);//? 20 } } class Base { //父类 int count = 10;//属性 } class Sub extends Base {//子类 int count = 20;//属性 } -

这里的判断对象类型是编译类型还是运行类型?运行类型
public class PolyDetail03 { public static void main(String[] args) { BB bb = new BB(); System.out.println(bb instanceof BB);// true System.out.println(bb instanceof AA);// true //aa 编译类型 AA, 运行类型是BB //BB是AA子类 AA aa = new BB(); System.out.println(aa instanceof AA);// true System.out.println(aa instanceof BB);// true, 两个true说明是判断的运行类型 Object obj = new Object(); System.out.println(obj instanceof AA);//false String str = "hello"; //System.out.println(str instanceof AA); System.out.println(str instanceof Object);//true } } class AA {} //父类 class BB extends AA {}//子类
1.3.5.4 多态课堂练习
-

-

这一题主要注意:属性看编译类型,方法看运行类型
1.3.5.5 动态绑定机制*

一个经典案例:第一句打印的a.sum()方法里面getI()是子类的还是父类的?
首先,根据方法的动态绑定机制,a的运行类型是B类,所以先去B类中找有没有sum方法,没有去A类中找,找到后发现getI方法,因为a的运行类型是B类,所以又先去B类中找getI方法,由于属性是没有动态绑定机制的,所以getI方法中的i就是B类中的i=20。
public class DynamicBinding {
public static void main(String[] args) {
//a 的编译类型 A, 运行类型 B
A a = new B();//向上转型
System.out.println(a.sum());//?40 -> 30
System.out.println(a.sum1());//?30-> 20
}
}
class A {//父类
public int i = 10;
//动态绑定机制:
public int sum() {//父类sum()
return getI() + 10;//20 + 10
}
public int sum1() {//父类sum1()
return i + 10;//10 + 10
}
public int getI() {//父类getI
return i;
}
}
class B extends A {//子类
public int i = 20;
// public int sum() {
// return i + 20;
// }
public int getI() {//子类getI()
return i;
}
// public int sum1() {
// return i + 10;
// }
}
1.3.5.6 多态数组

public class PloyArray {
public static void main(String[] args) {
//======================================================
//应用实例:现有一个继承结构如下:要求创建1个Person对象、
// 2个Student 对象和2个Teacher对象, 统一放在数组中,并调用每个对象say方法
Person[] persons = new Person[5];
persons[0] = new Person("jack", 20);
persons[1] = new Student("mary", 18, 100);
persons[2] = new Student("smith", 19, 30.1);
persons[3] = new Teacher("scott", 30, 20000);
persons[4] = new Teacher("king", 50, 25000);
//循环遍历多态数组,调用say
for (int i = 0; i < persons.length; i++) {
//老师提示: person[i] 编译类型是 Person ,运行类型是是根据实际情况有JVM来判断
System.out.println(persons[i].say());//动态绑定机制,数组多态
//===================================================
//应用实例:如何调用子类特有的方法
//这里大家聪明. 使用 类型判断 + 向下转型.
if(persons[i] instanceof Student) {//判断person[i] 的运行类型是不是Student
Student student = (Student)persons[i];//向下转型
student.study();
//小伙伴也可以使用一条语句 ((Student)persons[i]).study();
} else if(persons[i] instanceof Teacher) {
Teacher teacher = (Teacher)persons[i];
teacher.teach();
} else if(persons[i] instanceof Person){
//System.out.println("你的类型有误, 请自己检查...");
} else {
System.out.println("你的类型有误, 请自己检查...");
}
}
}
}
1.3.5.7 多态参数

第二章 反射专题
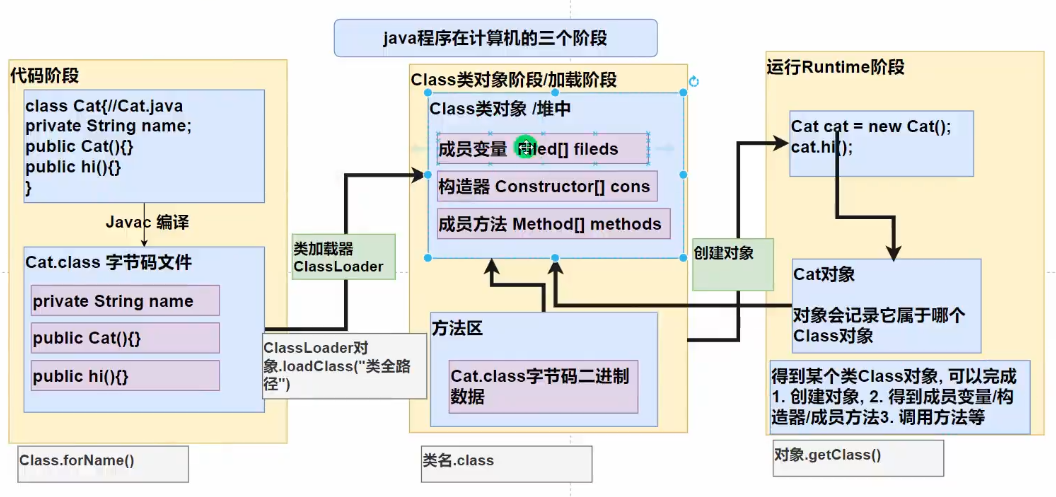
2.1 一个需求引出反射(快速入门)
需求:从一个配置文件中读取指定信息,并用这个信息创建对象且调用方法。
然后在实际操作中会发现,如下图,当获取到类的路径时,并不能通过直接new classfullpath() 来生成对象,因为classfullpath是一个String字符串!
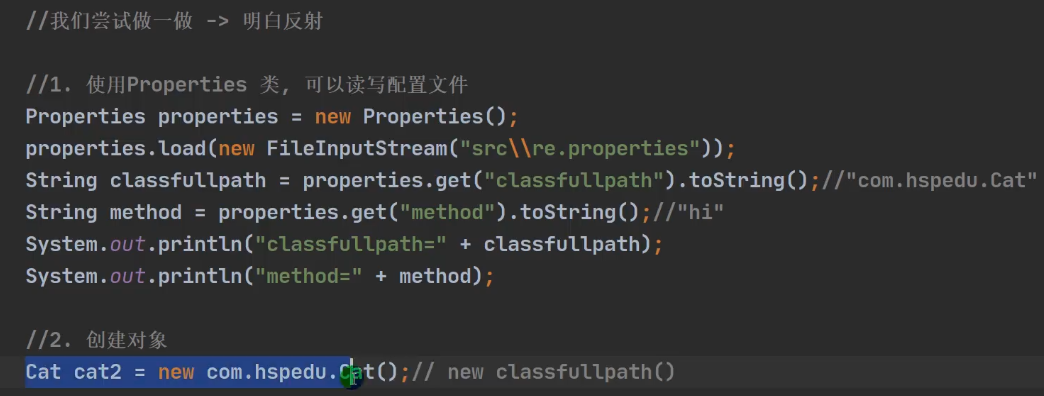
类似于这样的需求在学习框架时很多,即通过外部文件配置,在不修改源码情况下,通过修改外部文件配置来控制程序,也符合设计模式的ocp原则(开闭原则:不修改源码,扩展修改功能) 这一点,在老韩的例子中,只需要把properties配置文件中的methodname更改即可
使用反射解决:通过classfullpath路径名,来获取到对应的类(有点反射的意思了)
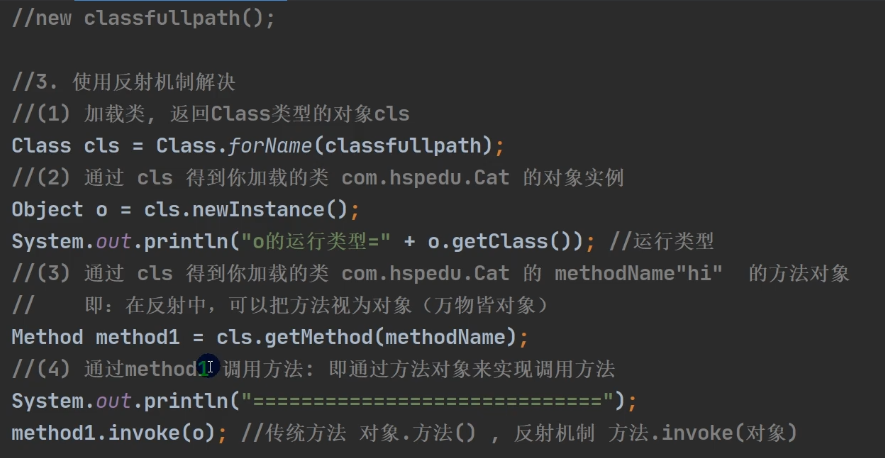
在Java核心技术第11版中,获取对象实例的方法变成:
Object o = cla.getConstructor().newInstance(); // Object o = cla.newInstance();
2.2 反射机制

反射原理图:
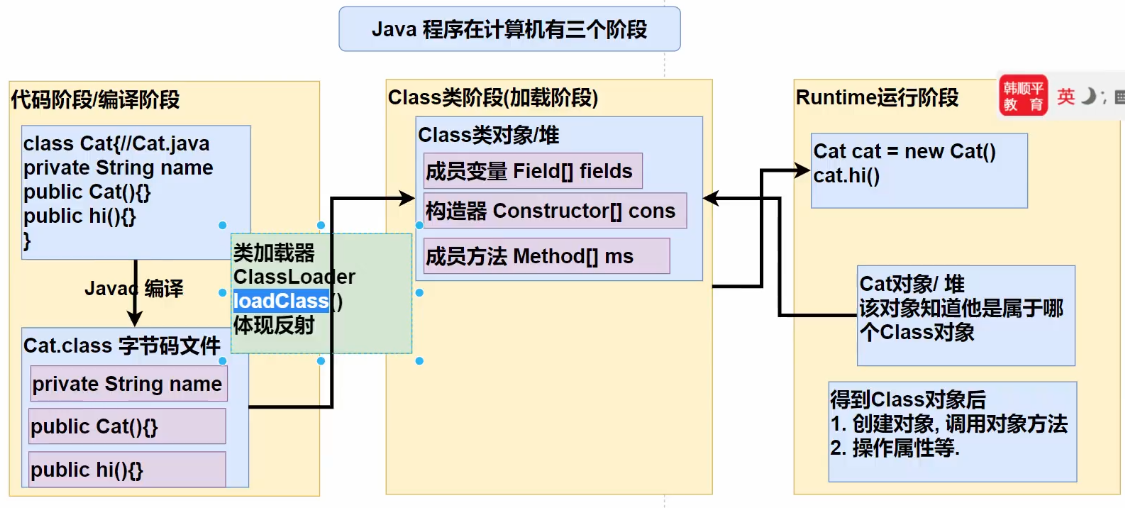
- Java反射机制可以完成:

- 反射相关的主要类:


- 反射的优缺点:
- 优点:可以动态地创建和使用对象(也是框架底层核心),使用灵活,没有反射机制的话,框架技术就失去了底层支撑。
- 缺点:使用反射基本是解释执行,对执行速度会有影响。
// 传统方案
static void test1() {
Cat cat = new Cat();
long start = System.currentTimeMillis();
for (int i = 0; i < 90000000; i++) {
cat.cry();
}
long end = System.currentTimeMillis();
System.out.println("传统方法调用耗时:"+ (end - start));
}
// 反射机制
static void test2() throws NoSuchMethodException, ClassNotFoundException, IllegalAccessException, InvocationTargetException, InstantiationException {
Class cls = Class.forName("Cat");
Object o = cls.getConstructor().newInstance();
Method method = cls.getMethod("cry");
long start = System.currentTimeMillis();
for (int i = 0; i < 90000000; i++) {
method.invoke(o);
}
long end = System.currentTimeMillis();
System.out.println("反射方法调用耗时:" + (end - start));
}
输出:
传统方法调用耗时:6
反射方法调用耗时:501
对反射调用的优化方案——关闭访问检查
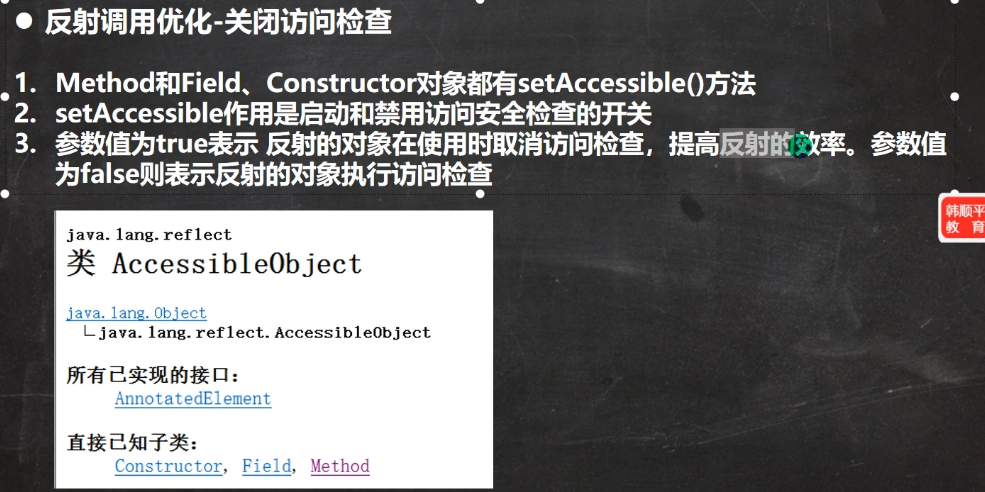
// 反射调用优化
static void test3() throws NoSuchMethodException, ClassNotFoundException, IllegalAccessException, InvocationTargetException, InstantiationException {
Class cls = Class.forName("Cat");
Object o = cls.getConstructor().newInstance();
Method method = cls.getMethod("cry");
method.setAccessible(true); // 在反射调用方法时,取消安全检查,进行速度优化
long start = System.currentTimeMillis();
for (int i = 0; i < 90000000; i++) {
method.invoke(o);
}
long end = System.currentTimeMillis();
System.out.println("反射优化后调用耗时:" + (end - start));
}
结果:
传统方法调用耗时:5
反射方法调用耗时:506
反射优化后调用耗时:292
2.3 Class类特点的梳理

补充:
-
在类加载器中进行创建
-
在Class类堆中,只会有一份Class对象,这里是通过加锁,来保证高并发情况下,只有一份Class对象
-
通过Class对象可以......
2.4 Class常用方法
2.5 获取Class对象六种方式
其实是四种最核心的方法:(前四种最重要)
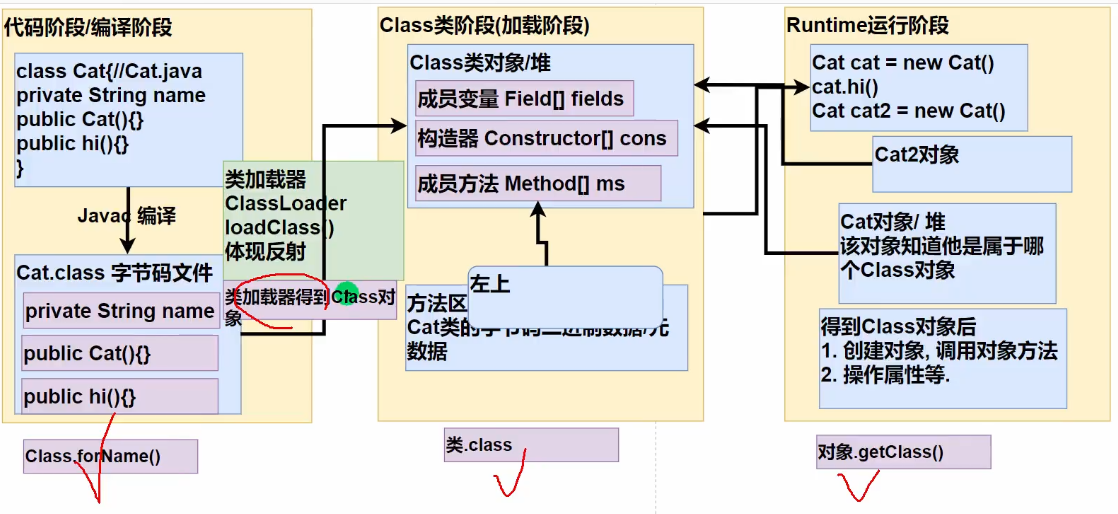
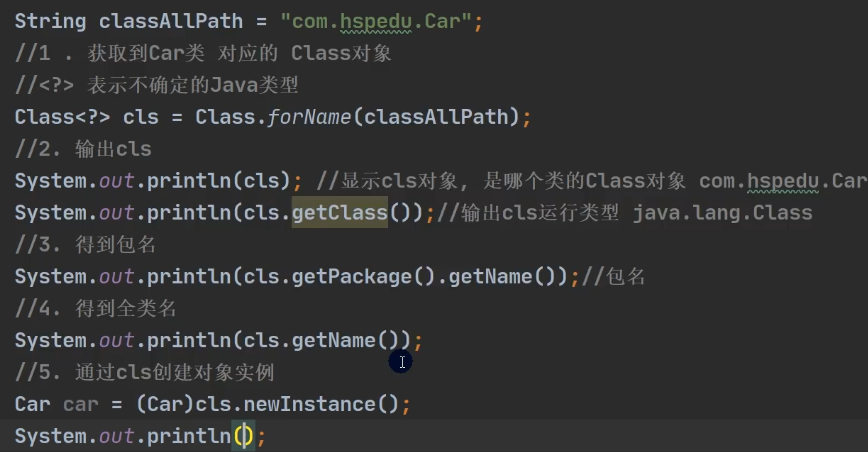
//1. Class.forName
String classAllPath = "com.hspedu.Car"; //通过读取配置文件获取
Class<?> cls1 = Class.forName(classAllPath);
System.out.println(cls1);
//2. 类名.class , 应用场景: 用于参数传递
Class cls2 = Car.class;
System.out.println(cls2);
//3. 对象.getClass(), 应用场景,有对象实例
Car car = new Car();
Class cls3 = car.getClass();
System.out.println(cls3);
//4. 通过类加载器【4种】来获取到类的Class对象
//(1)先得到类加载器 car
ClassLoader classLoader = car.getClass().getClassLoader();
//(2)通过类加载器得到Class对象
Class cls4 = classLoader.loadClass(classAllPath);
System.out.println(cls4);
//cls1 , cls2 , cls3 , cls4 其实是同一个对象
System.out.println(cls1.hashCode());
System.out.println(cls2.hashCode());
System.out.println(cls3.hashCode());
System.out.println(cls4.hashCode());
//5. 基本数据(int, char,boolean,float,double,byte,long,short) 按如下方式得到Class类对象
Class<Integer> integerClass = int.class;
Class<Character> characterClass = char.class;
Class<Boolean> booleanClass = boolean.class;
System.out.println(integerClass);//int
//6. 基本数据类型对应的包装类,可以通过 .TYPE 得到Class类对象(与5的对象是同一个对象)
Class<Integer> type1 = Integer.TYPE;
Class<Character> type2 = Character.TYPE; //其它包装类BOOLEAN, DOUBLE, LONG,BYTE等待
2.6 哪些类型有Class对象

Class<String> cls1 = String.class;//外部类
Class<Serializable> cls2 = Serializable.class;//接口
Class<Integer[]> cls3 = Integer[].class;//数组
Class<float[][]> cls4 = float[][].class;//二维数组
Class<Deprecated> cls5 = Deprecated.class;//注解
//枚举
Class<Thread.State> cls6 = Thread.State.class;
Class<Long> cls7 = long.class;//基本数据类型
Class<Void> cls8 = void.class;//void数据类型
Class<Class> cls9 = Class.class;//
2.7 动态和静态加载

case 1 的语句是静态加载,在程序编译时候就要加载,如果这个类不存在的话,那么就要报错;相反,
case 2 的语句是动态加载,所以只有当执行case 2 这段代码时候,才会进行类的加载,动态加载可以理解为延时加载。
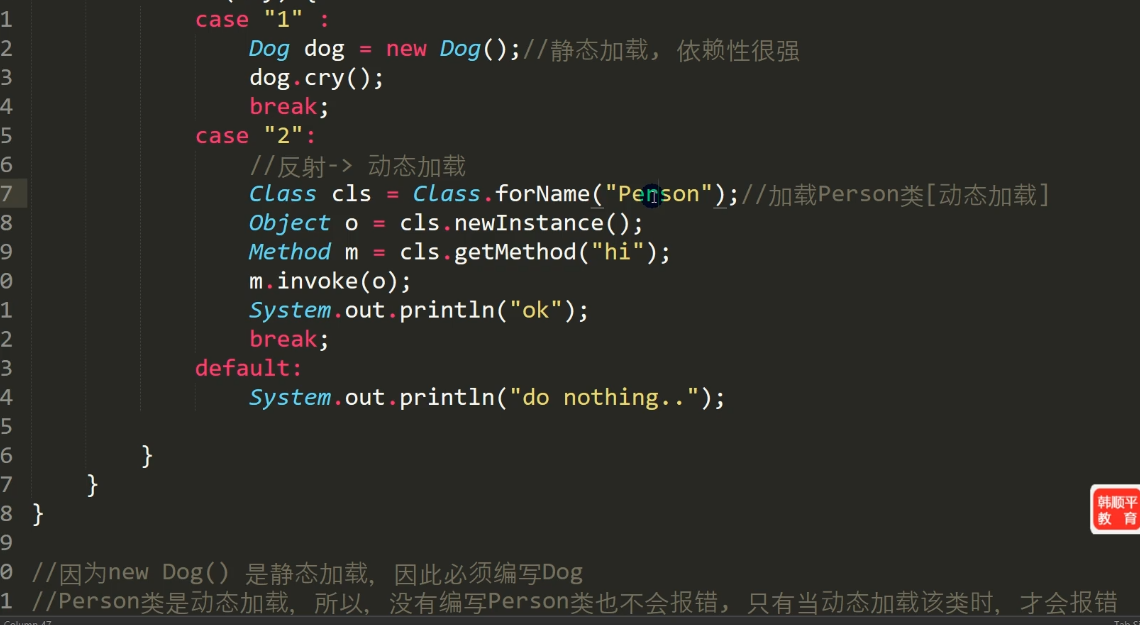
2.8 类加载
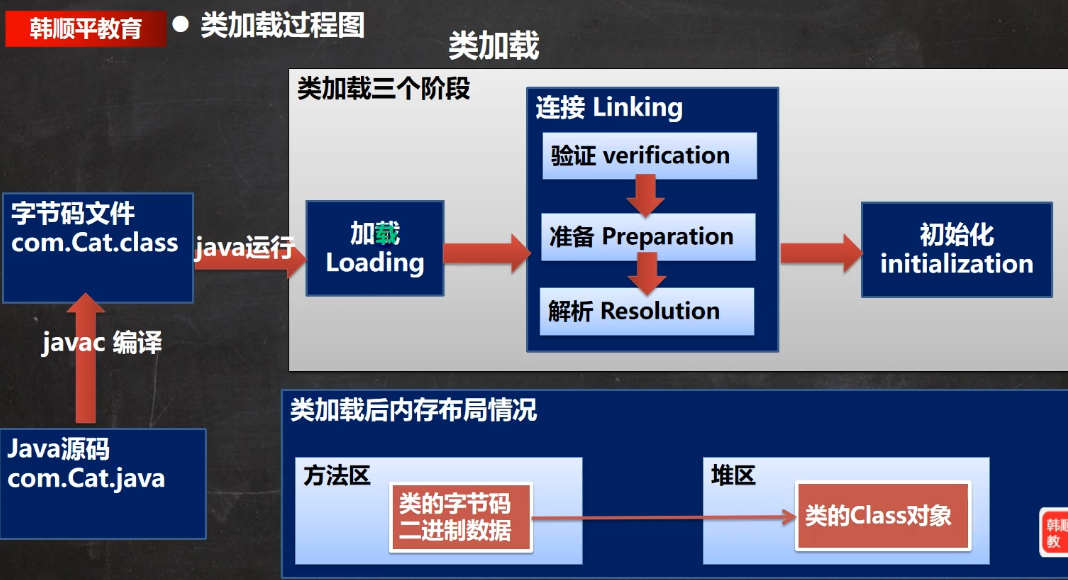
2.8.1 类加载流程图
前两个阶段是JVM控制,只有初始化阶段是可以由程序员控制。
其中下图初始化中,是对静态成员变量的初始化加载,而不是new的阶段,那是属于创建对象了
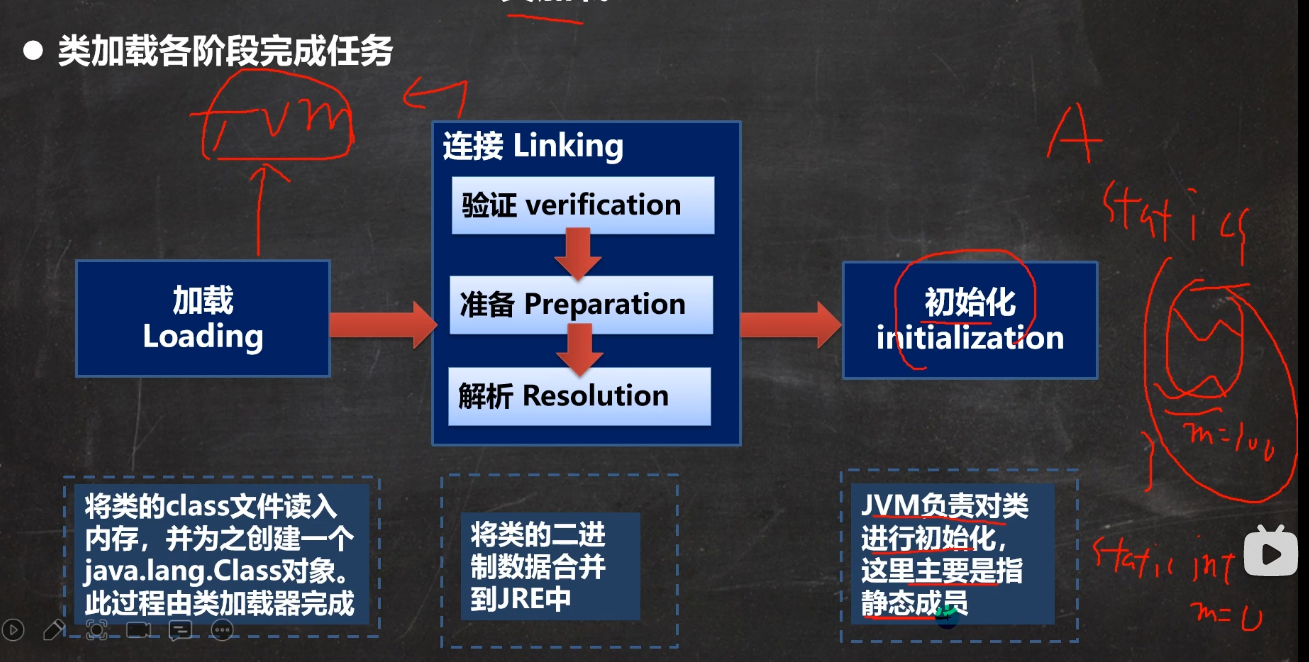
2.8.2 类加载流程——加载阶段
二进制字节流加载到内存中:会将某个类的字节码二进制数据加载到方法区,同时生成相应的Class类对象(上图获取Class对象的三个阶段图中类加载部分)

2.8.3 类加载流程——连接阶段(验证、准备、解析)
验证:

准备:

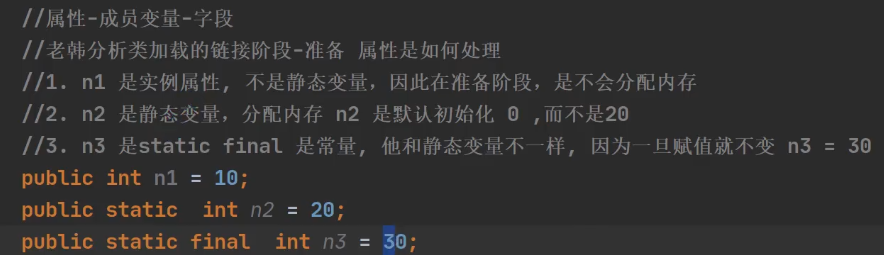
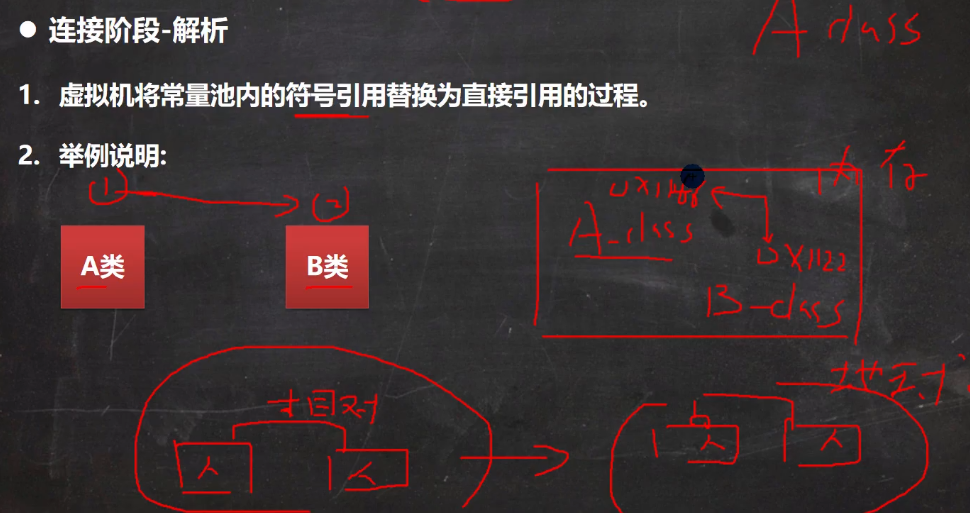
解析:
2.8.4 类加载流程——初始化
程序员可以操作的阶段,与静态变量有关,与对象没关系,这是类加载的过程。(静态变量的加载)

public class ClassLoad03 {
public static void main(String[] args) throws ClassNotFoundException {
//老韩分析(加载顺序)
//1. 加载B类,并生成 B的class对象
//2. 链接 num = 0
//3. 初始化阶段
// 依次自动收集类中的所有静态变量的赋值动作和静态代码块中的语句,并合并
/*
clinit() {
System.out.println("B 静态代码块被执行");
//num = 300;
num = 100;
}
合并: num = 100 // 静态变量按照顺序赋值
*/
//new B();//类加载
//System.out.println(B.num);//100, 如果直接使用类的静态属性,也会导致类的加载
//看看加载类的时候,是有同步机制控制
/*
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
//正因为有这个机制,才能保证某个类在内存中, 只有一份Class对象
synchronized (getClassLoadingLock(name)) {
//....
}
}
*/
new B();
}
}
class B {
static {
System.out.println("B 静态代码块被执行");
num = 300;
}
static int num = 100;
public B() {//构造器
System.out.println("B() 构造器被执行");
}
}
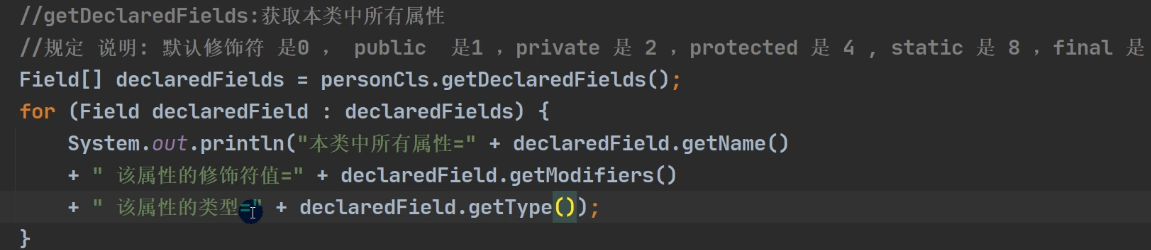
2.9 获取类的结构信息
对于提供的API,一般情况下是返回public修饰的字段和方法,若想获得诸如private、protected修饰的方法或字段,则需要换到类似于getDeclared()*API接口。





2.10 反射暴破
1. 创建实例

/**
* @author 韩顺平
* @version 1.0
* 演示通过反射机制创建实例
*/
public class ReflecCreateInstance {
public static void main(String[] args) throws ClassNotFoundException, IllegalAccessException, InstantiationException, NoSuchMethodException, InvocationTargetException {
//1. 先获取到User类的Class对象
Class<?> userClass = Class.forName("com.hspedu.reflection.User");
//2. 通过public的无参构造器创建实例
Object o = userClass.newInstance();
System.out.println(o);
//3. 通过public的有参构造器创建实例
/*
constructor 对象就是
public User(String name) {//public的有参构造器
this.name = name;
}
*/
//3.1 先得到对应构造器(public的有参构造器,String)
Constructor<?> constructor = userClass.getConstructor(String.class); //注意,这里传入构造器形参类型
//3.2 创建实例,并传入实参
Object hsp = constructor.newInstance("hsp");
System.out.println("hsp=" + hsp);
//4. 通过非public的有参构造器创建实例
//4.1 得到private的构造器对象(private有参构造器,int、String)
Constructor<?> constructor1 = userClass.getDeclaredConstructor(int.class, String.class);
//4.2 创建实例
/*
*暴破【暴力破解】 , 使用反射可以访问private构造器/方法/属性, 反射面前,都是纸老虎
*破坏了类的封装性,相当于留了个后门
*/
constructor1.setAccessible(true);
// 如果没有第35行的爆破,第37行会报错:没有权限...
Object user2 = constructor1.newInstance(100, "张三丰");
System.out.println("user2=" + user2);
}
}
class User { //User类
private int age = 10;
private String name = "韩顺平教育";
public User() {//无参 public
}
public User(String name) {//public的有参构造器
this.name = name;
}
private User(int age, String name) {//private 有参构造器
this.age = age;
this.name = name;
}
public String toString() {
return "User [age=" + age + ", name=" + name + "]";
}
}
这里的反射爆破可以理解为:将原本用来限制访问权限的“门”给爆破掉,从而能够访问私有的字段方法等,其上图第四点,通过setAccessible(true),取消安全性检查,完成爆破。(每一次访问私有,都要爆破)
2. 操作属性

...
//1. 得到Student类对应的 Class对象
Class<?> stuClass = Class.forName("com.hspedu.reflection.Student");
//2. 创建对象
Object o = stuClass.newInstance();//o 的运行类型就是Student
System.out.println(o.getClass());//Student
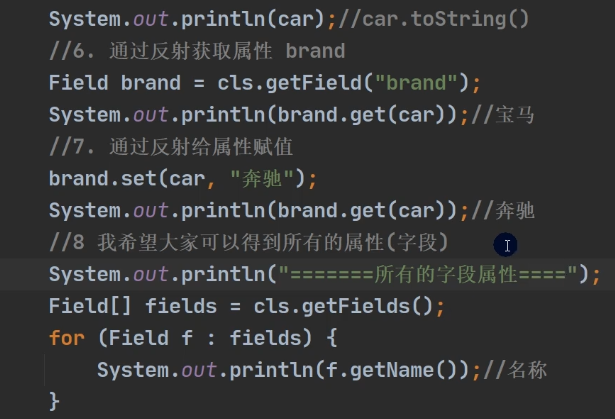
//3. 使用反射得到age 属性对象
Field age = stuClass.getField("age"); // age是public修饰,可用getField方法
age.set(o, 88);//通过反射来操作属性
System.out.println(o);//
System.out.println(age.get(o));//返回age属性的值
//4. 使用反射操作name 属性
Field name = stuClass.getDeclaredField("name");
//对name 进行暴破, 可以操作private 属性
name.setAccessible(true);
//name.set(o, "老韩");
// 因为在类加载的时候,static修饰的字段已经存在初始化好了,可以不用通过实例对象来指定
name.set(null, "老韩~");//修改属性值,因为name是static属性,因此 o 也可以写出null
System.out.println(o);
System.out.println(name.get(o)); //获取属性值
System.out.println(name.get(null));//获取属性值, 要求name是static
}
class Student {//类
public int age;
private static String name;
public Student() {//构造器
}
public String toString() {
return "Student [age=" + age + ", name=" + name + "]";
}
}
3. 操作方法

...
//1. 得到Boss类对应的Class对象
Class<?> bossCls = Class.forName("com.hspedu.reflection.Boss");
//2. 创建对象(无参构造创建即可)
Object o = bossCls.newInstance();
//3. 调用public的hi方法
//Method hi = bossCls.getMethod("hi", String.class);//OK
//3.1 得到hi方法对象(注意形参类型)
Method hi = bossCls.getDeclaredMethod("hi", String.class);//OK,注意是带形参的方法
//3.2 调用
hi.invoke(o, "韩顺平教育~");
//4. 调用private static 方法
//4.1 得到 say 方法对象(注意形参类型)
Method say = bossCls.getDeclaredMethod("say", int.class, String.class, char.class);
//4.2 因为say方法是private, 所以需要暴破,原理和前面讲的构造器和属性一样
say.setAccessible(true);
System.out.println(say.invoke(o, 100, "张三", '男'));
//4.3 因为say方法是static的,还可以这样调用 ,可以传入null
System.out.println(say.invoke(null, 200, "李四", '女'));
//5. 在反射中,如果方法有返回值,统一返回Object , 但是他运行类型和方法定义的返回类型一致
Object reVal = say.invoke(null, 300, "王五", '男');
System.out.println("reVal 的运行类型=" + reVal.getClass());//String
}
class Boss {//类
public int age;
private static String name;
public Boss() {//构造器
}
public Monster m1() {
return new Monster();
}
private static String say(int n, String s, char c) {//静态方法
return n + " " + s + " " + c;
}
public void hi(String s) {//普通public方法
System.out.println("hi " + s);
}
}
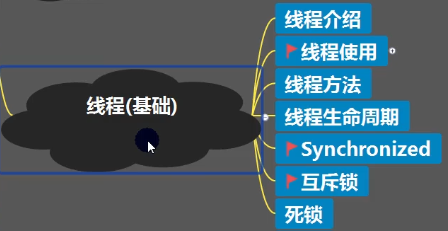
第三章 线程(基础)
3.1 线程的基本操作
1. 继承Thread类

/**
* @author 韩顺平
* @version 1.0
* 演示通过继承Thread 类创建线程
*/
public class Thread01 {
// 主线程main
public static void main(String[] args) throws InterruptedException {
//创建Cat对象,可以当做线程使用
Cat cat = new Cat();
//老韩读源码
/* 执行步骤:
(1)
public synchronized void start() {
start0();
}
(2)
//start0() 是本地方法(底层方法),是JVM调用, 底层是c/c++实现
//真正实现多线程的效果, 是start0(), 而不是 run
private native void start0();
*/
cat.start();//启动线程-> 最终会执行cat的run方法(Thread子线程)
//run方法就是一个普通的方法, 没有真正的启动一个线程,就会把run方法执行完毕,才向下执行,main线程会被阻塞
//cat.run();//相当于main线程切换到Thread子线程
//说明: 当main线程启动一个子线程 Thread-0, 主线程不会阻塞, 会继续执行。.start()开启一个子线程
//这时 主线程和子线程是交替执行..
System.out.println("主线程继续执行" + Thread.currentThread().getName());//名字main
for(int i = 0; i < 60; i++) {
System.out.println("主线程 i=" + i);
//让主线程休眠1秒
Thread.sleep(1000);
}
}
}
//老韩说明
//1. 当一个类继承了 Thread 类, 该类就可以当做线程使用
//2. 我们会重写 run方法,写上自己的业务代码
//3. run Thread 类 实现了 Runnable 接口的run方法
/*
@Override
public void run() {
if (target != null) {
target.run();
}
}
*/
class Cat extends Thread {
int times = 0;
@Override
public void run() {//重写run方法,写上自己的业务逻辑
while (true) {
//该线程每隔1秒。在控制台输出 “喵喵, 我是小猫咪”
System.out.println("喵喵, 我是小猫咪" + (++times) + " 线程名=" + Thread.currentThread().getName());
//让该线程休眠1秒 ctrl+alt+t
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
if(times == 80) {
break;//当times 到80, 退出while, 这时线程也就退出..
}
}
}
}
2. 实现Runnable接口
Java是单继承的,若A已经继承了B,此时就无法再继承Thread开启子线程,因此提供了实现Runnable接口的方式

/**
* @author 韩顺平
* @version 1.0
* 通过实现接口Runnable 来开发线程
*/
public class Thread02 {
public static void main(String[] args) {
Dog dog = new Dog();
//dog.start(); 这里不能调用start
//创建了Thread对象,把 dog对象(实现Runnable),放入Thread
Thread thread = new Thread(dog);
thread.start();
// Tiger tiger = new Tiger();//实现了 Runnable
// ThreadProxy threadProxy = new ThreadProxy(tiger);
// threadProxy.start();
}
}
class Animal {
}
class Tiger extends Animal implements Runnable {
@Override
public void run() {
System.out.println("老虎嗷嗷叫....");
}
}
//线程代理类 , 模拟了一个极简的Thread类
class ThreadProxy implements Runnable {//你可以把Proxy类当做 ThreadProxy
private Runnable target = null;//属性,类型是 Runnable
@Override
public void run() {
if (target != null) {
target.run();//动态绑定(运行类型Tiger)
}
}
public ThreadProxy(Runnable target) {
this.target = target;
}
public void start() {
start0();//这个方法时真正实现多线程方法
}
public void start0() {
run();
}
}
class Dog implements Runnable { //通过实现Runnable接口,开发线程
int count = 0;
@Override
public void run() { //普通方法
while (true) {
System.out.println("小狗汪汪叫..hi" + (++count) + Thread.currentThread().getName());
//休眠1秒
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
if (count == 10) {
break;
}
}
}
}
上面的代码主要涉及到一个很重要的知识点,就是:实现了Runnable接口的类,可以再用Thread构造器构造一个Thread对象来调用start()方法。
使用Runnable接口实现类实例构建Thread对象时,可以不用线程对象.setName()来给线程取名,直接在new对象的时候,传入名字即可:Thread thread = new Thread(Runnable实现类实例,name)
3. 多线程执行

public class Thread03 {
public static void main(String[] args) {
T1 t1 = new T1();
T2 t2 = new T2();
Thread thread1 = new Thread(t1);
Thread thread2 = new Thread(t2);
thread1.start();//启动第1个线程
thread2.start();//启动第2个线程
//...
}
}
class T1 implements Runnable {
int count = 0;
@Override
public void run() {
while (true) {
//每隔1秒输出 “hello,world”,输出10次
System.out.println("hello,world " + (++count));
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
if(count == 60) {
break;
}
}
}
}
class T2 implements Runnable {
int count = 0;
@Override
public void run() {
//每隔1秒输出 “hi”,输出5次
while (true) {
System.out.println("hi " + (++count));
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
if(count == 50) {
break;
}
}
}
}


4. 线程终止


public class ThreadExit_ {
public static void main(String[] args) throws InterruptedException {
T t1 = new T();
t1.start();
//如果希望main线程去控制t1 线程的终止, 必须可以修改 loop
//让t1 退出run方法,从而终止 t1线程 -> 通知方式
//让主线程休眠 10 秒,再通知 t1线程退出
System.out.println("main线程休眠10s...");
Thread.sleep(10 * 1000);
// 通知t1线程退出
t1.setLoop(false);
}
}
class T extends Thread {
private int count = 0;
//设置一个控制变量
private boolean loop = true;
@Override
public void run() {
while (loop) { // loop为false,线程结束
try {
Thread.sleep(50);// 让当前线程休眠50ms
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("T 运行中...." + (++count));
}
}
public void setLoop(boolean loop) {
this.loop = loop;
}
}
3.2. 线程常用方法
1. 中断、礼让、插队


注意事项和细节:
- 指start0方法,JVM底层调用方法,实现多线程
- interrupt,只是中断线程,不是结束线程,用于提前中断休眠的线程
public class ThreadMethod01 {
public static void main(String[] args) throws InterruptedException {
//测试相关的方法
T t = new T();
t.setName("老韩");
t.setPriority(Thread.MIN_PRIORITY);//1
t.start();//启动子线程
//主线程打印5 hi ,然后我就中断 子线程的休眠
for(int i = 0; i < 5; i++) {
Thread.sleep(1000);
System.out.println("hi " + i);
}
System.out.println(t.getName() + " 线程的优先级 =" + t.getPriority());//1
t.interrupt();//当执行到这里,就会提前中断 t线程的休眠.(此时t线程正在休眠中,才能中断休眠)
}
}
class T extends Thread { //自定义的线程类
@Override
public void run() {
while (true) {
for (int i = 0; i < 100; i++) {
//Thread.currentThread().getName() 获取当前线程的名称
System.out.println(Thread.currentThread().getName() + " 吃包子~~~~" + i);
}
try {
System.out.println(Thread.currentThread().getName() + " 休眠中~~~");
Thread.sleep(20000);//20秒
} catch (InterruptedException e) {
//当该线程执行到一个interrupt 方法时,就会catch 一个 异常, 可以加入自己的业务代码
//InterruptedException 是捕获到一个中断异常.
System.out.println(Thread.currentThread().getName() + "被 interrupt了");
}
}
}
}

yield:翻译 —> 让出,礼让的时刻由操作系统底层内核决定,在CPU资源紧张的时候,礼让的成功率要高一些。
join:加入、插队,
public class ThreadMethod02 {
public static void main(String[] args) throws InterruptedException {
T2 t2 = new T2();
t2.start();
for(int i = 1; i <= 20; i++) {
Thread.sleep(1000); // 主线程也休眠1秒
System.out.println("主线程(小弟) 吃了 " + i + " 包子");
if(i == 5) {
System.out.println("主线程(小弟) 让 子线程(老大) 先吃");
//join, 线程插队
//t2.join();// 这里相当于让t2 线程先执行完毕(子线程先吃完)
Thread.yield();//礼让,不一定成功..(主线程礼让)
System.out.println("子线程(老大) 吃完了 主线程(小弟) 接着吃..");
}
}
}
}
class T2 extends Thread {
@Override
public void run() {
for (int i = 1; i <= 20; i++) {
try {
Thread.sleep(1000);//休眠1秒
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("子线程(老大) 吃了 " + i + " 包子");
}
}
}
2. 用户线程和守护线程
守护线程!!!定义重要


public class ThreadMethod03 {
public static void main(String[] args) throws InterruptedException {
MyDaemonThread myDaemonThread = new MyDaemonThread();
//如果我们希望当main线程结束后,子线程自动结束
//,只需将子线程设为守护线程即可
myDaemonThread.setDaemon(true); // 这句话关键,子线程设置为主线程的守护进程,当主线程结束后,子线程自动结束
myDaemonThread.start(); // 开启子线程
for( int i = 1; i <= 10; i++) {//main线程
System.out.println("宝强在辛苦的工作...");
Thread.sleep(1000);
}
}
}
class MyDaemonThread extends Thread {
public void run() {
for (; ; ) {//无限循环
try {
Thread.sleep(1000);//休眠1000毫秒
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("马蓉和宋喆快乐聊天,哈哈哈~~~");
}
}
}
Daemon:守护
3.3 线程的生命周期(操作系统知识)
通常认为线程的生命周期一共有六个状态或七个状态,其中因为在Runnable状态下有细分为就绪态和运行态,所以细分的话有七个状态。( 创建态new、可执行态runnable、阻塞态blocked、等待态waiting、超时等待态timedwaiting)

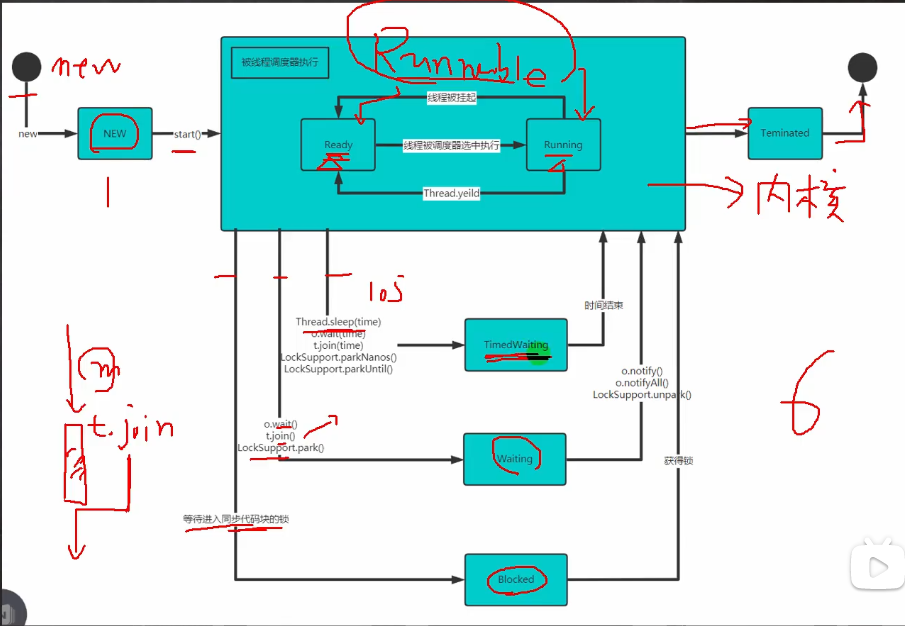
从图中也能明白为什么yield礼让不一定成功呢,因为只是从运行态切换至就绪态,不一定会立马获取到CPU。
public class ThreadState_ {
public static void main(String[] args) throws InterruptedException {
T t = new T();
System.out.println(t.getName() + " 状态 " + t.getState());
t.start();
while (Thread.State.TERMINATED != t.getState()) { // 如果子线程进入结束态,就跳出循环,第一个语句是枚举
System.out.println(t.getName() + " 状态 " + t.getState());
Thread.sleep(500); // 方便打印
}
System.out.println(t.getName() + " 状态 " + t.getState());
}
}
class T extends Thread {
@Override
public void run() {
while (true) {
for (int i = 0; i < 5; i++) {
System.out.println("hi " + i);
try {
Thread.sleep(1000); // 这里会导致子线程进入timedwaiting态
} catch (InterruptedException e) {
e.printStackTrace();
}
}
break;
}
}
}
运行结果:
Thread-0 子线程状态 NEW
Thread-0 子线程状态 RUNNABLE
hi 0
Thread-0 子线程状态 TIMED_WAITING
Thread-0 子线程状态 TIMED_WAITING
hi 1
Thread-0 子线程状态 TIMED_WAITING
Thread-0 子线程状态 TIMED_WAITING
hi 2
Thread-0 子线程状态 TIMED_WAITING
Thread-0 子线程状态 TIMED_WAITING
hi 3
Thread-0 子线程状态 TIMED_WAITING
Thread-0 子线程状态 TIMED_WAITING
hi 4
Thread-0 子线程状态 TIMED_WAITING
Thread-0 子线程状态 TIMED_WAITING
Thread-0 子线程状态 TERMINATED
3.4 线程同步机制


3.5 互斥锁


注意事项:
基本介绍中的第5点:(互斥锁)
在之前售票问题中,为了解决互斥问题,需要让三个线程对象访问同一个对象,代码如下:要求多个线程的锁对象为同一个
失败的反例 1和2 :
1
//使用Thread方式
// new SellTicket01().start(); // 1号
// new SellTicket01().start(); // 2号
class SellTicket01 extends Thread {
private static int ticketNum = 100;//让多个线程共享 ticketNum
public void m1() {
synchronized (this) {// this并不能锁住m1方法(),因为this是指的各自new的一个Thread对象本身(即1号、2号)
System.out.println("hello");
}
}
.......
2 重复创建Object,失败
......
public /*synchronized*/ void sell() { //同步方法, 在同一时刻, 只能有一个线程来执行sell方法
synchronized (new Object()) { // 每个线程拿的都是各自新创建的Object对象,并不能锁到同一个对象
if (ticketNum <= 0) {
System.out.println("售票结束...");
loop = false;
return;
}
......
成功的例子:方法一,使用Object object = new Object(); 方法二,同一个Class对象实例创建的多个不同的子线程对象,争夺同一个this对象(本章作业第二个就是这样)
最稳妥的方法:无论是否是同一个Class对象或不同Class对象,synchronized()里面都用object方法,一般使用synchronized代码块,提高效率。
/**
* 使用多线程,模拟三个窗口同时售票100张
*/
public class SellTicket {
public static void main(String[] args) {
// 方法一:因为三个窗口对象不同,为了实现三个窗口访问同一个售票对象并上锁,需要使用Object指定方法
//测试
// SellTicket01 sellTicket01 = new SellTicket01();
// SellTicket01 sellTicket02 = new SellTicket01();
// SellTicket01 sellTicket03 = new SellTicket01();
//
// //这里我们会出现超卖..
// sellTicket01.start();//启动售票线程
// sellTicket02.start();//启动售票线程
// sellTicket03.start();//启动售票线程
// 方法二:当多个线程执行到这里时,就会去争夺 this对象锁,是同一个this对象
SellTicket03 sellTicket03 = new SellTicket03();
// 子线程执行重写的run()方法
new Thread(sellTicket03).start();//第1个线程-窗口
new Thread(sellTicket03).start();//第2个线程-窗口
new Thread(sellTicket03).start();//第3个线程-窗口
}
}
//实现接口方式, 使用synchronized实现线程同步
class SellTicket03 implements Runnable {
private int ticketNum = 100;//让多个线程共享 ticketNum
private boolean loop = true;//控制run方法变量
Object object = new Object(); // 为了让三个线程(窗口)同时访问一个对象,即对同一售票行为进行上锁
//同步方法(静态的)的锁为当前类本身
//老韩解读
//1. public synchronized static void m1() {} 锁是加在 SellTicket03.class
//2. 如果在静态方法中,实现一个同步代码块.
/*
synchronized (SellTicket03.class) {
System.out.println("m2");
}
*/
public synchronized static void m1() { // 锁是加在 SellTicket03.class
}
public static void m2() { // 注意这里的static方法,syn对象是当前类本身
synchronized (SellTicket03.class) { // 这里不能用this,因为是静态方法,必须用当前类本身
System.out.println("m2");
}
}
//老韩说明
//1. public synchronized void sell() {} 就是一个同步方法,但是是一个非静态方法
//2. 这时锁在 this对象
//3. 也可以在代码块上写 synchronize ,同步代码块, 互斥锁还是在this对象
public /*synchronized*/ void sell() { //同步方法, 在同一时刻, 只能有一个线程来执行sell方法
synchronized (/*this*/ object) { // 注意这里的object
if (ticketNum <= 0) {
System.out.println("售票结束...");
loop = false;
return;
}
//休眠50毫秒, 模拟
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("窗口 " + Thread.currentThread().getName() + " 售出一张票"
+ " 剩余票数=" + (--ticketNum));//1 - 0 - -1 - -2
}
}
@Override
public void run() {
while (loop) { // loop 控制线程运行变量
sell();//sell方法是一共同步方法
}
}
}
3.6 线程死锁

3.7 释放锁


3.8 本章作业

public class ThreadHomeWork01 {
public static void main(String[] args) {
A a = new A();
B b = new B(a); // 传递a进去很关键
b.start();
a.start();
}
}
// 创建A线程类
class A extends Thread {
private boolean loop = true;
@Override
public void run() {
// 输出1-100的数字
while (loop) {
System.out.println((int) (Math.random() * 100 + 1));
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public void setLoop(boolean loop) {
this.loop = loop;
}
}
// 创建B线程类,用于从键盘中读取“Q”命令
class B extends Thread {
private A a;
private Scanner scanner = new Scanner(System.in);
public B() {
}
public B(A a) { // 直接通过构造器传入A类对象
this.a = a;
}
@Override
public void run() {
while (true) { // 循环,方便接收数据
// 接收到用户的输入
System.out.println("请输入你的指令(Q)来表示退出:");
char key = scanner.next().toUpperCase().charAt(0);
if (key == 'Q') {
a.setLoop(false);
System.out.println("B线程退出.");
break;
}
}
}
}

public class ThreadHomeWork02 {
public static void main(String[] args) {
// 同一个实现Runnable接口的实例创建的不同线程对象,争夺同一个this对象
Test t = new Test();
Thread thread1 = new Thread(t);
thread1.setName("t1");
Thread thread2 = new Thread(t);
thread2.setName("t2");
thread1.start();
thread2.start();
}
}
//编程取款的线程
//1.因为这里涉及到多个线程共享资源,所以我们使用实现Runnable方式
//2. 每次取出 1000
class Test implements Runnable {
private int money = 10000;
// Object o = new Object();
@Override
public void run() {
while (true) {
//解读
//1. 这里使用 synchronized 实现了线程同步
//2. 当多个线程执行到这里时,就会去争夺 this对象锁
//3. 哪个线程争夺到(获取)this对象锁,就执行 synchronized 代码块, 执行完后,会释放this对象锁
//4. 争夺不到this对象锁,就blocked ,准备继续争夺
//5. this对象锁是非公平锁.
synchronized (/*o*/ this) {
//判断余额是否够
if (money < 1000) {
System.out.println("余额不足");
break;
}
money -= 1000;
System.out.println(Thread.currentThread().getName() + " 取出了1000 当前余额=" + money);
}
//休眠1s
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
第四章 集合专题
Java集合底层机制很重要!!!!!!!
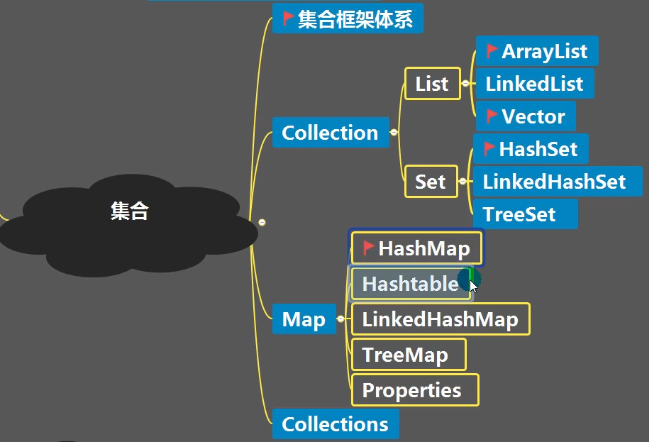
集合主要分两组,分别为单列集合、双列集合(键值对)
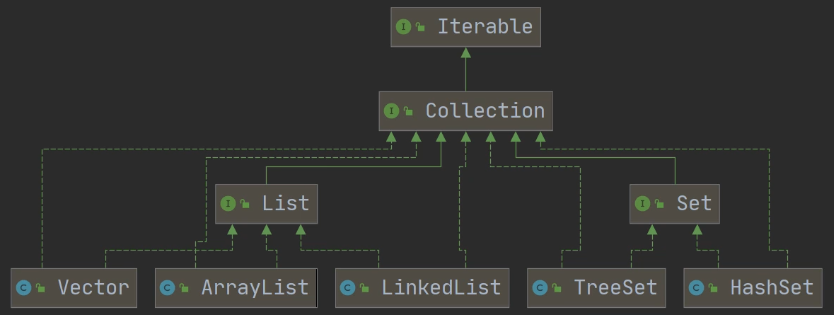
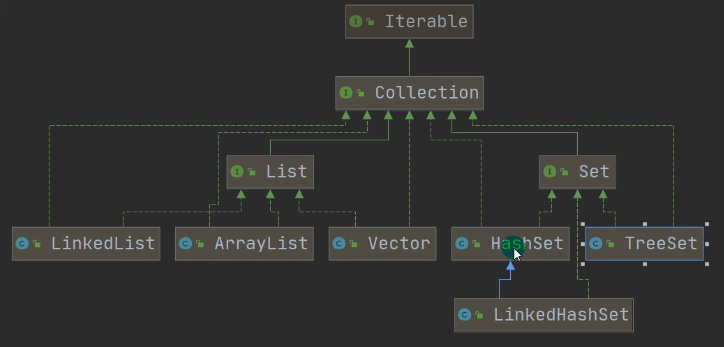
Collection:该接口由两个重要的子接口,List(有序重复)、Set(无序、不允许重复元素),他们的实现子类都是单列集合
Map:实现的子类是双列集合,存放键值对

4.1 Collection接口和常用方法
4.1.1 Collection接口实现类的特点

注意:Collection是接口不能被实例化,只能通过其实现子类来进行实例化

list.add(10); // 其实是list.add(new Integer(10))
List list = new ArrayList();
// add:添加单个元素
list.add("jack");
list.add(10);//list.add(new Integer(10))
list.add(true);
System.out.println("list=" + list);
// remove:删除指定元素
//list.remove(0);//删除第一个元素
list.remove(true);//指定删除某个元素
System.out.println("list=" + list);
// contains:查找元素是否存在
System.out.println(list.contains("jack"));//T
// size:获取元素个数
System.out.println(list.size());//2
// isEmpty:判断是否为空
System.out.println(list.isEmpty());//F
// clear:清空
list.clear();
System.out.println("list=" + list);
// addAll:添加多个元素
ArrayList list2 = new ArrayList();
list2.add("红楼梦");
list2.add("三国演义");
list.addAll(list2);
System.out.println("list=" + list);
// containsAll:查找多个元素是否都存在
System.out.println(list.containsAll(list2));//T
// removeAll:删除多个元素
list.add("聊斋");
list.removeAll(list2);
System.out.println("list=" + list);//[聊斋]
4.1.2 Collection接口遍历元素方式
- 使用Iterator(迭代器)
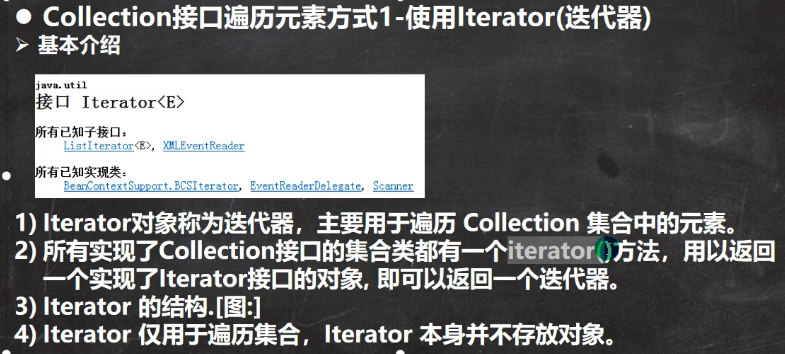
迭代器的执行原理:


Collection col = new ArrayList();
col.add(new Book("三国演义", "罗贯中", 10.1));
col.add(new Book("小李飞刀", "古龙", 5.1));
col.add(new Book("红楼梦", "曹雪芹", 34.6));
//System.out.println("col=" + col);
//现在老师希望能够遍历 col集合
//1. 先得到 col 对应的 迭代器
Iterator iterator = col.iterator();
//2. 使用while循环遍历
// while (iterator.hasNext()) {//判断是否还有数据
// //返回下一个元素,类型是Object
// Object obj = iterator.next(); // 编译类型是Object,但运行时会自动找到对应的类型,运行类型为Book
// System.out.println("obj=" + obj);
// }
//老师教大家一个快捷键,快速生成 while => itit
//显示所有的快捷键的的快捷键 ctrl + j
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println("obj=" + obj);
}
//3. 当退出while循环后 , 这时iterator迭代器,指向最后的元素
// iterator.next();//NoSuchElementException
//4. 如果希望再次遍历,需要重置我们的迭代器
iterator = col.iterator(); // 重置迭代器
System.out.println("===第二次遍历===");
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println("obj=" + obj);
}
4.1.3 课堂练习

List list = new ArrayList();
list.add(new Dog("小黑", 3));
list.add(new Dog("大黄", 100));
list.add(new Dog("大壮", 8));
//先使用for增强
for (Object dog : list) { // 可以使用Dog dog :list,但得确定集合里面全是Dog对象
System.out.println("dog=" + dog);
}
//使用迭代器
System.out.println("===使用迭代器来遍历===");
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
Object dog = iterator.next();
System.out.println("dog=" + dog);
}
4.2 List接口方法
4.2.1 List接口和常用方法

List list = new ArrayList();
list.add("张三丰");
list.add("贾宝玉");
// void add(int index, Object ele):在index位置插入ele元素
//在index = 1的位置插入一个对象
list.add(1, "韩顺平");
System.out.println("list=" + list);
// boolean addAll(int index, Collection eles):从index位置开始将eles中的所有元素添加进来
List list2 = new ArrayList();
list2.add("jack");
list2.add("tom");
list.addAll(1, list2);
System.out.println("list=" + list);
// Object get(int index):获取指定index位置的元素
//说过
// int indexOf(Object obj):返回obj在集合中首次出现的位置
System.out.println(list.indexOf("tom"));//2
// int lastIndexOf(Object obj):返回obj在当前集合中末次出现的位置
list.add("韩顺平");
System.out.println("list=" + list);
System.out.println(list.lastIndexOf("韩顺平"));
// Object remove(int index):移除指定index位置的元素,并返回此元素
list.remove(0);
System.out.println("list=" + list);
// Object set(int index, Object ele):设置指定index位置的元素为ele , 相当于是替换,index必须是已经存在的
list.set(1, "玛丽");
System.out.println("list=" + list);
// List subList(int fromIndex, int toIndex):返回从fromIndex到toIndex位置的子集合
// 注意返回的子集合 fromIndex <= subList < toIndex 包头不包尾
List returnlist = list.subList(0, 2);
System.out.println("returnlist=" + returnlist);
}
4.2.2 课堂练习01
/*
添加10个以上的元素(比如String "hello" ),在2号位插入一个元素"韩顺平教育",
获得第5个元素,删除第6个元素,修改第7个元素,在使用迭代器遍历集合,
要求:使用List的实现类ArrayList完成。
*/
List list = new ArrayList();
for (int i = 0; i < 12; i++) { // 添加元素
list.add("hello" + i);
}
System.out.println("list:" + list);
// 在2号位插入一个元素“韩顺平教育”
list.add(1, "韩顺平教育");
System.out.println("在2号位插入一个元素“韩顺平教育” list:" + list);
// 获得第五个元素
System.out.println("第五个元素:" + list.get(4));
// 删除第六个元素
list.remove(5);
System.out.println("删除第六个元素 list:" + list);
// 修改第七个元素为文豪
list.set(6, "文豪");
System.out.println("修改第七个元素为文豪 list: " + list);
// 使用迭代器遍历集合
Iterator iterator = list.iterator();
System.out.println("迭代器遍历集合 list: ");
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.print(" " + next);
}
4.2.3 List的三种遍历方法

其中方式二,必须重写对象类的toString方法!!
4.2.4 课堂练习02

public class ListExercise02 {
public static void main(String[] args) {
List list = new ArrayList();
list.add(new Book("红楼梦", "曹雪芹", 100));
list.add(new Book("西游记", "吴承恩", 10));
list.add(new Book("水浒传", "施耐庵", 19));
list.add(new Book("三国", "罗贯中", 80));
System.out.println("排序前:");
for (Object o : list) {
System.out.println(o);
}
sort(list);
System.out.println("排序后:");
for (Object o : list) { // 使用这个方法,必须重写toString()
System.out.println(o);
}
}
// //静态方法
// //价格要求是从小到大,冒泡排序
// public static void sort(List list) {
// int listSize = list.size();
// for (int i = 0; i < listSize - 1; i++) {
// for (int j = 0; j < listSize - 1 - i; j++) {
// //取出对象Book
// Book book1 = (Book) list.get(j);
// Book book2 = (Book) list.get(j + 1);
// if (book1.getPrice() > book2.getPrice()) {//交换
// list.set(j, book2);
// list.set(j + 1, book1);
// }
// }
// }
// }
// 冒泡排序,我自己经常写的思路
public static void sort(List list) {
int listSize = list.size();
for (int i = 0; i < listSize - 1; i++) {
for (int j = i; j < listSize; j++) {
Book book1 = (Book)list.get(i);
Book book2 = (Book)list.get(j);
if (book1.getPrice() > book2.getPrice()) {
list.set(i, book2);
list.set(j, book1);
}
}
}
}
}
class Book {
private String name;
private double price;
private String author;
public Book() {}
public Book (String name, String author, double price) {
this.name = name;
this.author = author;
this.price = price;
}
public double getPrice() {
return price;
}
@Override
public String toString() { // 使用list.for 增加型for循环,必须重写toString方法
return "Book{" +
"name='" + name + '\'' +
", price=" + price +
", author='" + author + '\'' +
'}';
}
}
4.3 ArrayList底层结构和源码解析
4.3.1 ArrayList注意事项

2)底层是由数组实现的
3)底层:ArrayList是线程不安全的,源码没有用 synchronized
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}
4.3.2 ArrayList底层结构和源码分析

public class ArrayListSource {
public static void main(String[] args) {
//老韩解读源码
//注意,注意,注意,Idea 默认情况下,Debug 显示的数据是简化后的,如果希望看到完整的数据
//需要做设置.
//使用无参构造器创建ArrayList对象
ArrayList list = new ArrayList(); // 无参构造器进行debug
// ArrayList list = new ArrayList(8); // 指定大小构造器进行debug
//使用for给list集合添加 1-10数据
for (int i = 1; i <= 10; i++) {
list.add(i);
}
//使用for给list集合添加 11-15数据
for (int i = 11; i <= 15; i++) {
list.add(i);
}
list.add(100);
list.add(200);
list.add(null);
}
}
源码解读:(从无参构造器开始debug,分析使用无参构造器,即 ArrayList list = new ArrayList() )
第一步:

创建了一个空的elementData数组={},Object类型,由于Object是所有类的父类,所以能够存放很多不同类型的对象。
从这里也能得出结论:ArrayList的底层其实是数组
ArrayList初始化完成后(创建空数组),代码来到第一个for循环,准备添加数据
第二步:主要是判断是否需要扩容

valueOf 对整数进行装箱处理,将基本数据类型处理为对应的Integer对象

modCount++ 记录集合被修改的次数;此时因为只是创建的空数组,所以size为0,进入另一个add方法
modCount防止多线程操作带来的异常,源码注释的解释:
大概意思就是说:在使用迭代器遍历的时候,用来检查列表中的元素是否发生结构性变化(列表元素数量发生改变)了,保证在多线程环境下,迭代器能够正常遍历,主要在多线程环境下需要使用,防止一个线程正在迭代遍历,另一个线程修改了这个列表的结构。好好认识下这个异常:ConcurrentModificationException。对了,ArrayList是非线程安全的,所以在遍历非线程安全的集合时(ArrayList和LinkedList),最好使用迭代器。

判断,当前elementData的大小够不够,如果不够就调用grow()去扩容。如果当前ArrayList长度s小于已分配的elementData数组大小,那么就直接插入新数据,elementData[s] = e,很明显。

grow() 扩容机制,两种方法。这里的话,执行第二种,即当前size为0,此时初始扩容为10的大小。
第三步:添加数据

扩容成功,可以正常添加数据了,当前ArrayList已有数据+1

内部add方法执行完毕,来到return语句,返回true,数据添加成功,后面大同小异,第一个for循环debug完毕!
第四步:已分配的内存空间用完了,需要扩容
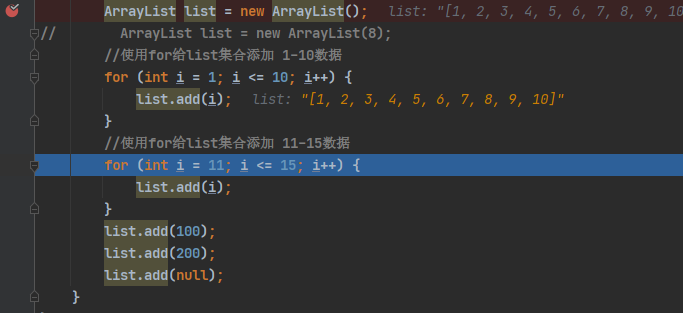
无参构造器第一次初始分配大小为10,第一个for循环已经用完,此时来到第二个for循环,需要进行扩容:
先是装箱,装箱完毕进入add()方法,

此时,modCount为11,第11次修改,即将进入内add方法

判断是否需要扩容,true,进入扩容函数grow()
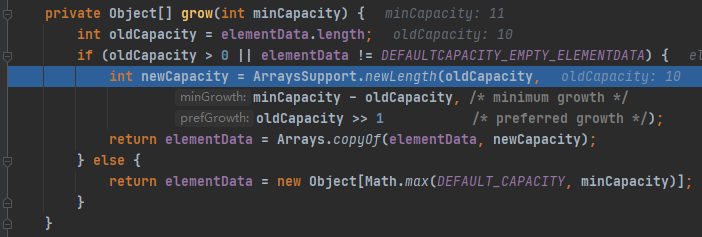
原先分配大小为10,显然得用newLength()方法进行扩容
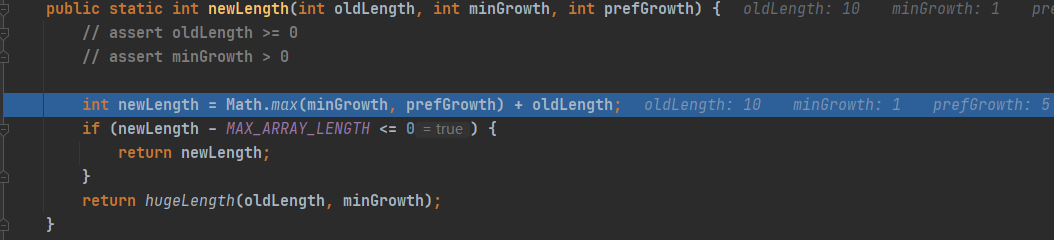
扩容多少的计算方法可以简述为:扩容到oldCapacity的1.5倍。计算方式是:oldCapacity除以2(底层是右移一位实现除法操作),再加上原先的大小,即原先的1.5倍。

调用Arrays.copyOf()方法,该方法作用:将原先数据复制到一个指定新的大小的数组,原先数据顺序和位置不变,多出来的空间全以null。返回给elementData,完成扩容操作。
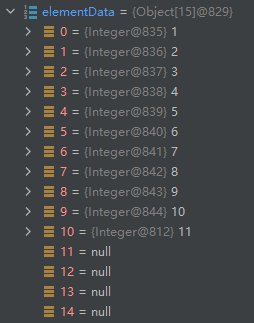
从10扩容到15,1.5倍,没用到的空间,全部是null
另一种:指定大小构造器
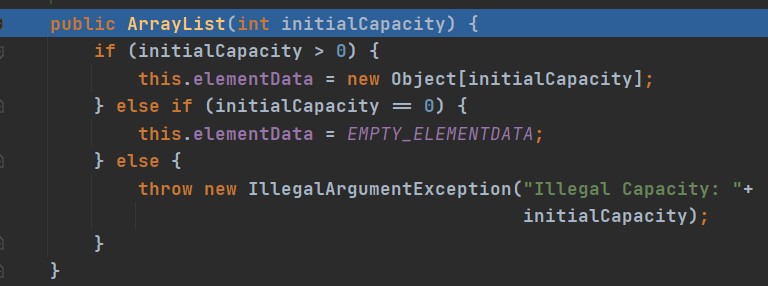
与第一种不同的是:一开始创建了一个指定大小的Object数组。其余后面就跟有大小,进行扩容操作一样。
4.4 Vector底层结构和源码解析

元素可以重复,可以添加null
4.4.1 Vector底层结构和ArrayList的比较
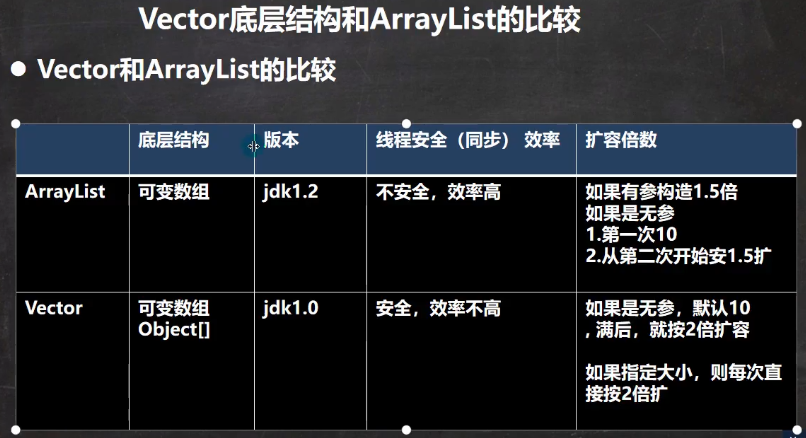
4.4.2 Vector源码分析
自己过一下debug就行:代码里面的源码,跟本地不一样,不同jdk版本,源码实现不一样,但大体思路是一样的。
@SuppressWarnings({"all"})
public class Vector_ {
public static void main(String[] args) {
//无参构造器 Vector vector = new Vector();
//有参数的构造
Vector vector = new Vector(8);
for (int i = 0; i < 10; i++) {
vector.add(i);
}
vector.add(100);
System.out.println("vector=" + vector);
//老韩解读源码
//1. new Vector() 底层
/*
public Vector() {
this(10);
}
补充:如果是 Vector vector = new Vector(8);
走的方法:
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
2. vector.add(i)
2.1 //下面这个方法就添加数据到vector集合
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
2.2 //确定是否需要扩容 条件 : minCapacity - elementData.length>0
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
2.3 //如果 需要的数组大小 不够用,就扩容 , 扩容的算法
//newCapacity = oldCapacity + ((capacityIncrement > 0) ?
// capacityIncrement : oldCapacity);
//就是扩容两倍.
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
*/
}
}
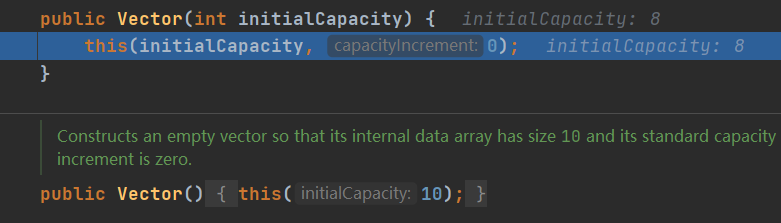
上面有Vector的有参构造和无参构造,无参初试默认容量为10,注意Vector在有参构造时,能够指定扩容大小。
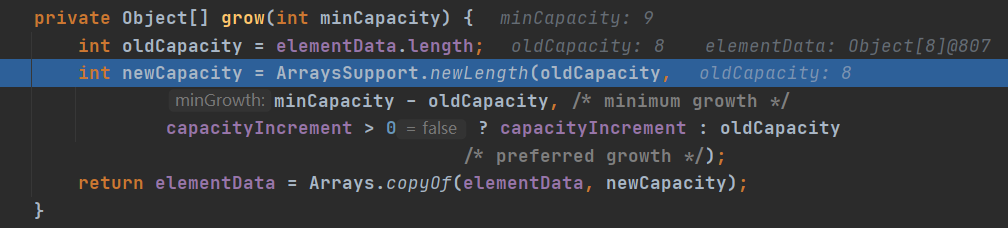
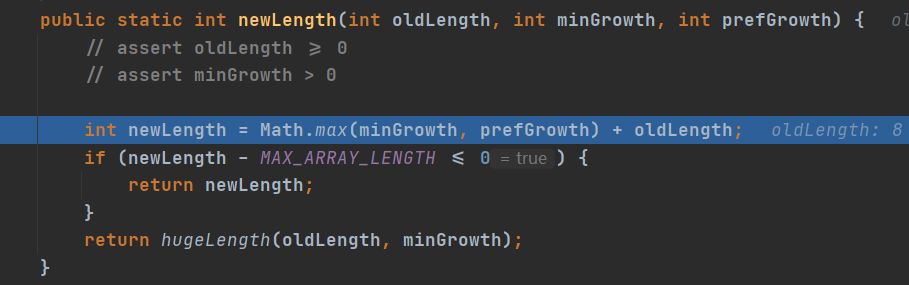
第一张图中的newLength()方法中的三元运算符注意一下,如果我们制定了扩容大小的话,在第二张图里面就能够清晰得看到每次扩容大小等于指定大小加上原先的大小,若没有指定大小,则是加上原来的大小,即两倍。
4.5 LinkedList底层结构和源码解析
4.5.1 底层结构


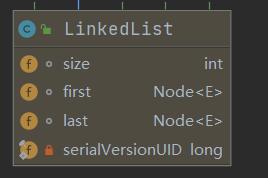
注意点:
- 底层维护了一个双向链表,通过观察LinkedList源码可以发现有Node结点对象:first和last
- LinkedList的增删操作,因为不是通过数组完成的,所以效率较高。改和查则不一定效率高,毕竟数组可以直接查找,链表只能一一遍历。
4.5.2 源码解读
源码解读:LinkedList在底层添加元素,是采用尾插法,有一个linkLast()方法
// Debug程序
@SuppressWarnings({"all"})
public class LinkedListUse {
public static void main(String[] args) {
LinkedList linkedList = new LinkedList();
linkedList.add(1);
linkedList.add(2);
linkedList.add(3);
System.out.println("linkedList=" + linkedList);
//演示一个删除结点的
linkedList.remove(); // 这里默认删除的是第一个结点
//linkedList.remove(2);
System.out.println("linkedList=" + linkedList);
//修改某个结点对象
linkedList.set(1, 999);
System.out.println("linkedList=" + linkedList);
//得到某个结点对象
//get(1) 是得到双向链表的第二个对象
Object o = linkedList.get(1);
System.out.println(o);//999
//因为LinkedList 是 实现了List接口, 遍历方式有三种(迭代器、增强for、普通for)
System.out.println("===LinkeList遍历迭代器====");
Iterator iterator = linkedList.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println("next=" + next);
}
System.out.println("===LinkeList遍历增强for====");
for (Object o1 : linkedList) {
System.out.println("o1=" + o1);
}
System.out.println("===LinkeList遍历普通for====");
for (int i = 0; i < linkedList.size(); i++) {
System.out.println(linkedList.get(i));
}
}
}
//老韩源码阅读.
1. LinkedList linkedList = new LinkedList();
public LinkedList() {}
2. 这时 linkeList 的属性 first = null last = null
3. 执行 添加
public boolean add(E e) {
linkLast(e);
return true;
}
4.将新的结点,加入到双向链表的最后
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
// 老韩读源码 linkedList.remove(); // 这里默认删除的是第一个结点
1. 执行 removeFirst()方法
public E remove() {
return removeFirst(); // 很明确了,默认删除第一个结点
}
2. 执行
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
3. 执行 unlinkFirst, 将 f 指向的双向链表的第一个结点拿掉(源码还是很好理解的)
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
- 底层是双链表
- remove()无参方法,默认是删除第一个元素,即first指向的元素
- LinkedList实现了List接口,所以跟其余List实现子类一样,有三种遍历循环方法
4.5.3 ArrayList和LinkedList比较
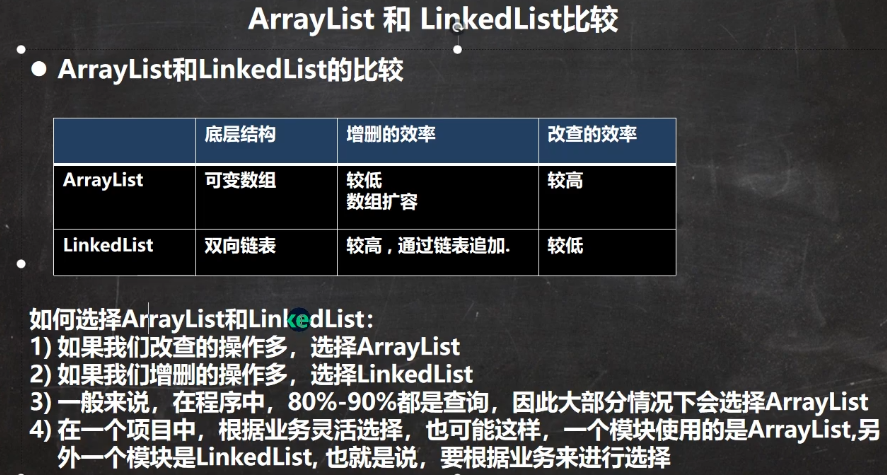
需要注意的是,LinkedList与ArrayList一样,都是线程不安全的,没有实现同步,多线程时要慎用。遍历时,最好使用迭代器进行遍历,有modCount进行修改记录,防止发生异常。
4.6 Set接口方法
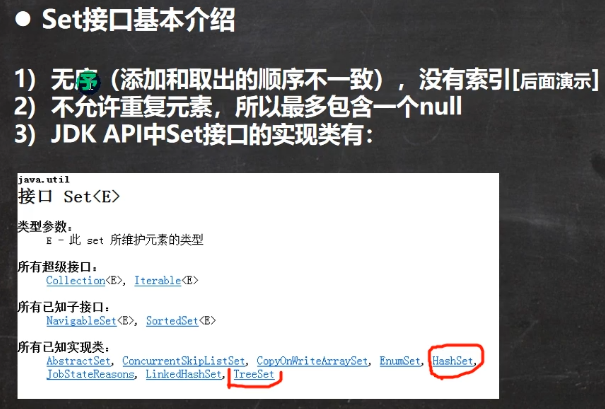

4.6.1 Set接口常用方法
public class SetMethod {
public static void main(String[] args) {
//老韩解读
//1. 以Set 接口的实现类 HashSet 来讲解Set 接口的方法
//2. set 接口的实现类的对象(Set接口对象), 不能存放重复的元素, 可以添加一个null
//3. set 接口对象存放数据是 无序 (即添加的顺序和取出的顺序不一致)
//4. 注意:取出的顺序的顺序虽然不是添加的顺序,但是取出的顺序是固定的.
Set set = new HashSet();
set.add("john");
set.add("lucy");
set.add("john");//重复
set.add("jack");
set.add("hsp");
set.add("mary");
set.add(null);//
set.add(null);//再次添加null
for(int i = 0; i <10;i ++) {
System.out.println("set=" + set); // 结果:set=[null, hsp, mary, john, lucy, jack],取出顺序是固定的
}
//遍历
//方式1: 使用迭代器
System.out.println("=====使用迭代器====");
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println("obj=" + obj);
}
set.remove(null);
//方式2: 增强for(底层是迭代器)
System.out.println("=====增强for====");
for (Object o : set) {
System.out.println("o=" + o);
}
//set 接口对象,不能通过索引来获取(没有get()方法)
}
}
注意点:
- 不能存放重复元素,但能存放一个null
- set存放的数据是无序的,但取出的顺序是固定不变的
- 只能用迭代器和增强for循环进行遍历,不能使用普通for,因为Set底层是HashMap,结构复杂(数组+单链表)
4.6.2 HashSet
4.6.2.1 HashSet全面说明
//说明
//1. 在执行add方法后,会返回一个boolean值
//2. 如果添加成功,返回 true, 否则返回false
//3. 可以通过 remove 指定删除哪个对象
System.out.println(set.add("john"));//T
System.out.println(set.add("lucy"));//T
System.out.println(set.add("john"));//F
System.out.println(set.add("jack"));//T
System.out.println(set.add("Rose"));//T
set.remove("john");
System.out.println("set=" + set);//3个
// 重置一下set
set = new HashSet();
System.out.println("set=" + set);//0
//4 Hashset 不能添加相同的元素/数据?
set.add("lucy");//添加成功
set.add("lucy");//加入不了
set.add(new Dog("tom"));//OK
set.add(new Dog("tom"));//Ok
System.out.println("set=" + set); // set=[Cat{name='tom'}, lucy, Cat{name='tom'}]
//在加深一下. 非常经典的面试题.
//看源码,做分析, 先给小伙伴留一个坑,以后讲完源码,你就了然
//去看他的源码,即 add 到底发生了什么?=> 底层机制.
set.add(new String("hsp"));//ok
set.add(new String("hsp"));//加入不了.
System.out.println("set=" + set); // set=[hsp, Cat{name='tom'}, lucy, Cat{name='tom'}]
4.6.2.2 HashSet底层机制说明
底层是HashMap(数组+单链表+红黑树)

-
HashSet扩容机制
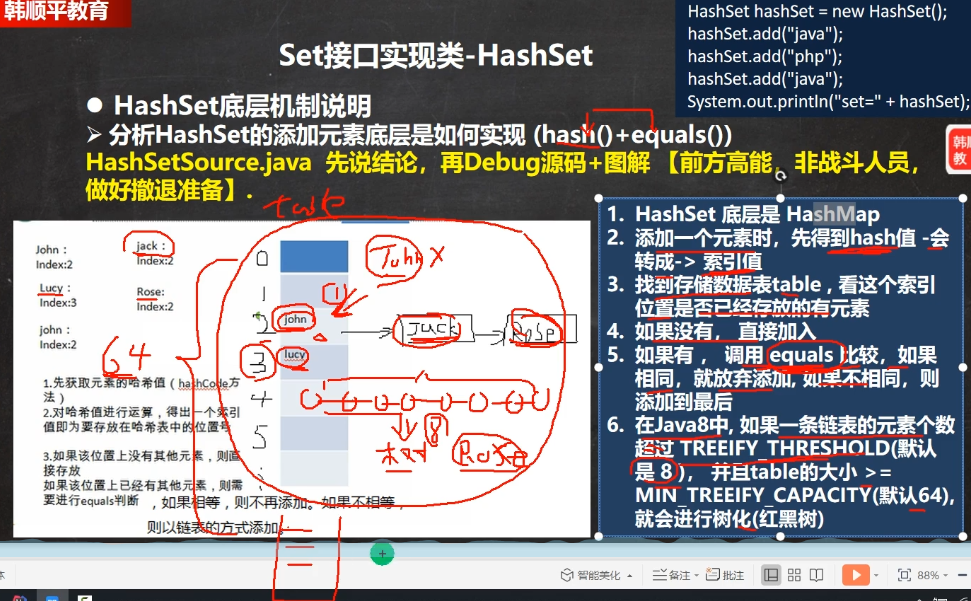
equals方法是可以由程序员进行重写的,也就是是比较对象还是比较内容是可以决定的
一条链表的元素个数到达了8个且整个table表的大小达到了64,就会对这条链表进行树化(红黑树),如果table表大小没有达到64,就会对table表进行按两倍扩容(table数组表)
-
源码解读(复杂且重要)
看代码注释!
// Debug程序
HashSet hashSet = new HashSet();
hashSet.add("java");//到此位置,第1次add分析完毕.
hashSet.add("php");//到此位置,第2次add分析完毕
hashSet.add("java");
System.out.println("set=" + hashSet);
老韩对HashSet 的源码解读
1. 执行 HashSet()
public HashSet() {
map = new HashMap<>(); // 可以看出来HashSet底层是由HashMap来实现的
}
2. 执行 add()
public boolean add(E e) {//e = "java"
return map.put(e, PRESENT)==null;//(static) PRESENT = new Object();
}
3.执行 put() , 该方法会执行 hash(key) 得到key对应的hash值 算法:h = key.hashCode()) ^ (h >>> 16)
public V put(K key, V value) {//key = "java" value = PRESENT 共享
return putVal(hash(key), key, value, false, true);
}
4.执行 putVal
注意:
-
哈希值的计算,并不是完全等价于hashCode

key的哈希值拿去hashCode()得出新的hash值,从而找到在table中的索引位置,即:新hash值的计算,并不是直接返回的key.hashCode(),而是将hashCode()值与自身的高16位进行异或运算。
h >>> 16是用来取出h的高16,(>>>是无符号右移)
原因:
由于和(length-1)运算,length 绝大多数情况小于2的16次方。所以始终是hashcode 的低16位(甚至更低)参与运算。要是高16位也参与运算,会让得到的下标更加散列。
所以这样高16位是用不到的,如何让高16也参与运算呢。所以才有hash(Object key)方法。让他的hashCode()和自己的高16位^运算。所以(h >>> 16)得到他的高16位与hashCode()进行^运算。
-
执行部分:最核心的代码(相当于在讲HashMap)P24
4.执行 putVal /** Params: hash – hash for key (经过hash()方法计算后的新hash值,hashCode与其自身高16位的异或运算) key – the key ("java",数据) value – the value to put (PRESENT 共享,用来占位) */ final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; //定义了辅助变量 //table 就是 HashMap 的一个数组,类型是 Node[] //if 语句表示如果当前table 是null, 或者 大小=0 //就是第一次扩容,到16个空间. if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // resize()方法是扩容方法 //(1)根据key,得到hash 去计算该key应该存放到table表的哪个索引位置 //并把这个位置的对象,赋给 p = tab[...] //(2)判断p 是否为null //(2.1) 如果p 为null, 表示还没有存放元素, 就创建一个Node (key="java",value=PRESENT) //(2.2) 就放在该位置 tab[i] = newNode(hash, key, value, null) if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { // 如果待存放的位置,现在的当前位置已经存放了元素,执行else语句 //一个开发技巧提示: 在需要局部变量(辅助变量)时候,再创建 Node<K,V> e; K k; // //如果当前索引位置对应的链表的第一个元素和准备添加的key的hash值一样 // ==判断地址是否相同(是否为同一对象),equals判断内容是否相同(是否两个对象的属性相同) //并且满足 下面两个条件之一: //(1) 准备加入的key 和 p 指向的Node 结点的 key 是同一个对象 (是否同一对象) //(2) p 指向的Node 结点的 key 的equals() 和准备加入的key比较后相同 (是否内容相同) //就认为是相同的对象,不能加入(比较的是头结点) if (p.hash == hash && // p指向当前索引位置对应的链表的第一个元素 ((k = p.key) == key || (key != null && key.equals(k)))) e = p; //再判断 p 是不是一颗红黑树, //如果是一颗红黑树,就调用 putTreeVal , 来进行添加 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else {//如果table对应索引位置,已经是一个链表, 就使用for循环比较 // 会有下面几种情况 //(1) 依次和该链表的每一个元素比较后,都不相同, 则加入到该链表的最后 //************************************************************ // 注意在把元素添加到链表后,立即判断 该链表是否已经达到8个结点(用binCount判断) // , 就调用 treeifyBin() 对当前这个链表进行树化(转成红黑树) // 注意,在转成红黑树时,要进行判断, 还要要求table大小 小于 64,判断条件: // if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY(64)) // resize();//对table扩容 // 如果上面条件成立,先table扩容.上面的条件是 treeifyBin()里面的判断 // 只有上面条件不成立时,才进行转成红黑树(需要table大小 大于 64,才树化) //************************************************************ //(2) 依次和该链表的每一个元素比较过程中,如果有相同情况,就直接break // 之前比较了头结点,现在比较链表其余部分;下面的循环是一个双指针,向前移动的方式有点特别 for (int binCount = 0; ; ++binCount) {//源码中死循环用for,因为for的指令比while少 //binCount记录当前遍历位置(0~7,从0开始计数) if ((e = p.next) == null) {// 第一种情况,加入到链表最后 p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD(8) - 1) // -1 for 1st,因为从0计数 treeifyBin(tab, hash);//如果插入后,链表长度超过等于8,则要进行树化 break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; // 链表中有一个元素与待插入元素一样,不需要进行尾插,break结束循环 p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; // 把新的值覆盖以前的旧值,map不允许key重复,重复后就替换 afterNodeAccess(e); return oldValue; } } ++modCount; //size 就是我们每加入一个结点Node(k,v,h,next), 就会size++ // threshold = 0.75 × table大小 if (++size > threshold) resize();//达到临界值,扩容 afterNodeInsertion(evict); // 空方法,由HashMap子类实现 return null; }注释:
-
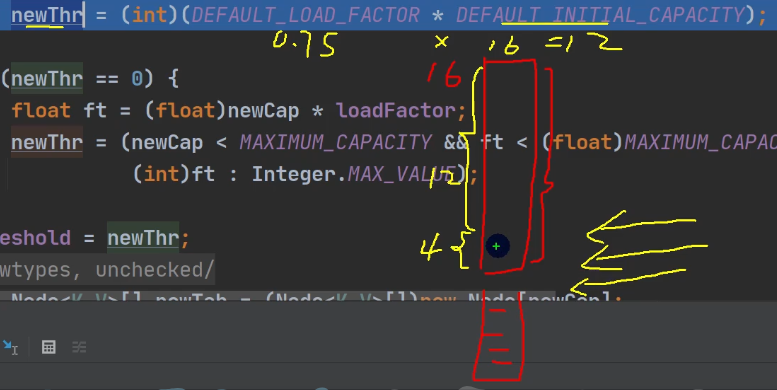
第一次table数组扩容大小为什么是16:在final Node<K,V>[] resize()方法中。table 就是 HashMap 的一个数组,类型是 Node[]

-
DEFAULT_LOAD_FACTOR = 0.75,负载因子,用于计算table数组的临界值newThr(带链表的哈希表),作用是一旦到达临界值后,就扩容,避免大量数据导致阻塞。举个例子:一个班级有50个座位,为了防止将来有很多人来,当座位用到45个座位时,就加新的座位。
-
for (int binCount = 0; ; ++binCount) {
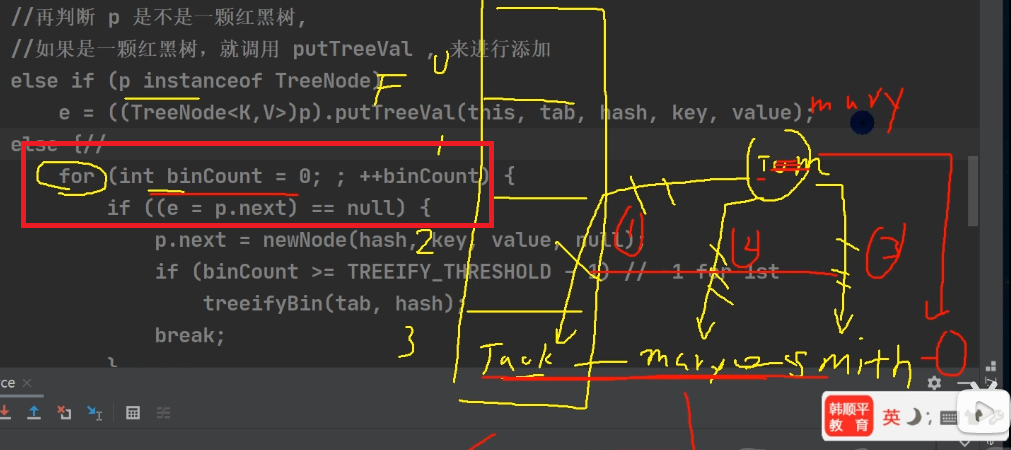
如果table对应索引位置,已经是一个链表, 就使用for循环比较
HashSet底层简要总结:

-
第一次扩容大小为16(默认值16,static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16)
-
超过临界值之后,就每次按两倍扩容:

这里需要额外注意:所谓临界值大小,并不是指在table表中已经有可插入的位置已经达到临界值,而是整个table表中所有插入结点的总个数达到了临界值。关键代码如下:
//size 就是我们每加入一个结点Node(k,v,h,next), 就会size++
// threshold = 0.75 × table大小
if (++size > threshold)
resize();//达到临界值,扩容
重要:也就是说,如果table表当前大小为16,此时表上一条链表上有7个元素(含头结点),另一个链表上此时已经添加了5个元素,再添加一个的话,那么table表就要进行扩容,因为size大小已经到达临界值12了,再添加一个结点,则会触发扩容机制。:
-
树化条件:
在Java8中, 如果一条链表的元素个数到达 TREEIFY_THRESHOLD(默认是 8 ), 并且table的大小 >= MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树), 否则仍然采用数组扩容机制
/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
* between resizing and treeification thresholds.
*/
static final int MIN_TREEIFY_CAPACITY = 64;
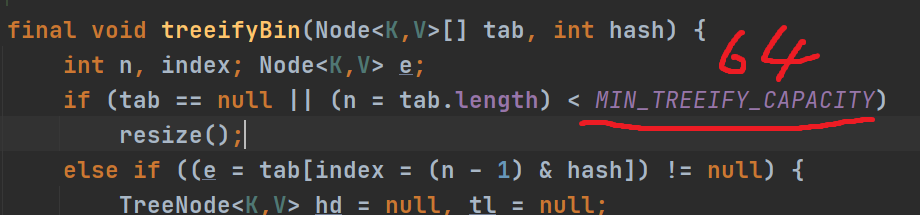
4.6.2.3 HashSet最佳实践
如果是同一个对象,那么它们的HashCode一定相同,反之,HashCode相同,却不一定是同一个对象,这也是为什么在源码中,需要比较内容。
题目:
定义一个Employee类,该类包含:private成员属性name,age 要求:
创建3个Employee 对象放入 HashSet中
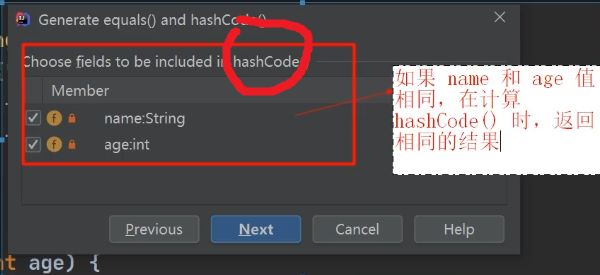
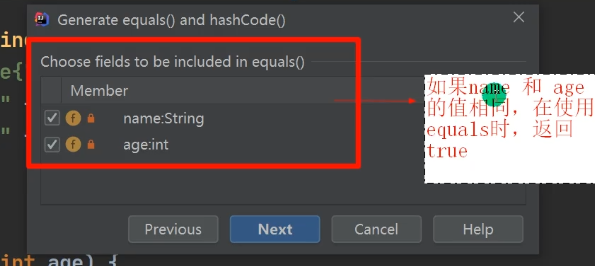
当 name和age的值相同时,认为是相同员工, 不能添加到HashSet集合中(需要重写hashCode和equals方法)
源码:
@SuppressWarnings({"all"})
public class HashSetExercise {
public static void main(String[] args) {
/**
定义一个Employee类,该类包含:private成员属性name,age 要求:
创建3个Employee 对象放入 HashSet中
当 name和age的值相同时,认为是相同员工, 不能添加到HashSet集合中
*/
HashSet hashSet = new HashSet();
hashSet.add(new Employee("milan", 18));//ok
hashSet.add(new Employee("smith", 28));//ok
hashSet.add(new Employee("milan", 18));//需要加入不成功.,不重写的话,就能够成功加入,因为对象不同,哈希值不同
//回答,加入了几个? 3个
System.out.println("hashSet=" + hashSet);
}
}
//创建Employee
class Employee {
private String name;
private int age;
public Employee(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
@Override
public String toString() {
return "Employee{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
public void setAge(int age) {
this.age = age;
}
//如果name 和 age 值相同,则返回相同的hash值
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employee employee = (Employee) o;
return age == employee.age &&
Objects.equals(name, employee.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
为了保证 相同对象 和 不同对象但内容相同 不能新添加至HashSet,结合底层源码putVal方法里面,需要同时满足这两个条件:
哈希值返回一样,equals方法返回一样

4.6.3 LinkedHashSet
4.6.3.1 LinkedHashSet全面说明
HashSet的子类,注意与HashSet的区别,底层最大区别就是使用了数组+双链表结构,能够保证取数据是有顺序的。而HashSet是数组+单链表,且遍历打印输出是无序的,其实是按照哈希值(实际上是哈希table表)遍历排序打印的。
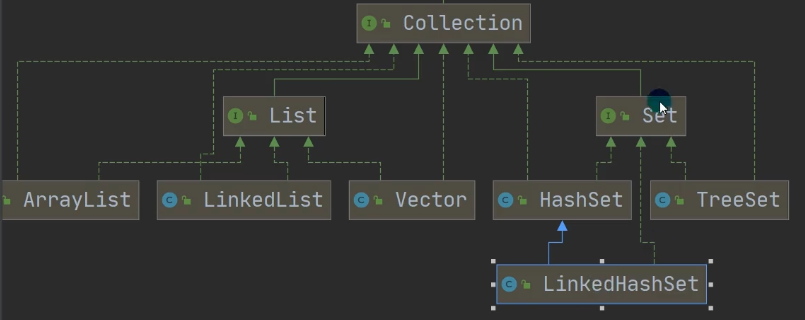

4.6.3.2 LinkedHashSet底层机制说明

Debug代码:
@SuppressWarnings({"all"})
public class LinkedHashSetSource {
public static void main(String[] args) {
//分析一下LinkedHashSet的底层机制
Set set = new LinkedHashSet();
set.add(new String("AA"));
set.add(456);
set.add(456);
set.add(new Customer("刘", 1001));
set.add(123);
set.add("HSP");
System.out.println("set=" + set);
}
}
class Customer {
private String name;
private int no;
public Customer(String name, int no) {
this.name = name;
this.no = no;
}
}
注释:
老韩解读
1. LinkedHashSet 加入顺序和取出元素/数据的顺序一致
2. LinkedHashSet 底层维护的是一个LinkedHashMap(是HashMap的子类)
3. LinkedHashSet 底层结构 (数组table+双向链表)
4. 添加第一次时,直接将 数组table 扩容到 16 ,存放的结点类型是 LinkedHashMap$Entry,而不是Node
5. Table数组是 HashMap$Node[] ,而存放的元素/数据是 LinkedHashMap$Entry类型(其实是数组多态:子类存放至父类类型数组)
//继承关系是在内部类完成.
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
4.6.3.3 LinkedHashSet课堂练习

LinkedHashSet linkedHashSet = new LinkedHashSet();
linkedHashSet.add(new Car("奥拓", 1000));//OK
linkedHashSet.add(new Car("奥迪", 300000));//OK
linkedHashSet.add(new Car("法拉利", 10000000));//OK
linkedHashSet.add(new Car("奥迪", 300000));//ok,因为是不同的car对象
linkedHashSet.add(new Car("保时捷", 70000000));//OK
linkedHashSet.add(new Car("奥迪", 300000));//ok因为是不同的car对象,要只有一个奥迪,重写equals和hash方法
//必须重写equals 方法 和 hashCode
//当 name 和 price 相同时, 就返回相同的 hashCode 值, equals返回t
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Car car = (Car) o;
return Double.compare(car.price, price) == 0 &&
Objects.equals(name, car.name);
}
@Override
public int hashCode() {
return Objects.hash(name, price);
}
跟HashSet最佳实践一样,也是重写两个方法
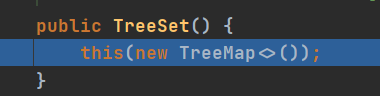
4.6.4 TreeSet
与HashSet最大的不同就是,可以排序(在有参构造器里面重写compare方法),默认构造器是字符串升序排序。
TreeSet的底层其实是TreeMap:键值对中的value使用一个静态对象(Object类)Present进行占位,与前面的HashSet一样
//老韩解读
//1. 当我们使用无参构造器,创建TreeSet时,仍然是无序的
//2. 老师希望添加的元素,按照字符串大小来排序
//3. 使用TreeSet 提供的一个构造器,可以传入一个比较器(匿名内部类)
// 并指定排序规则
//4. 简单看看源码
//老韩解读
/*
1. 构造器把传入的比较器对象,赋给了 TreeSet的底层的 TreeMap的属性this.comparator
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
2. 在 调用 treeSet.add("tom"), 在底层会执行到
if (cpr != null) {//cpr 就是我们的匿名内部类(对象),即:重写的比较规则
do {
parent = t;
//动态绑定到我们的匿名内部类(对象)compare
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else //如果相等,即返回0,这个Key就没有加入
return t.setValue(value);
} while (t != null);
}
*/
// TreeSet treeSet = new TreeSet();
TreeSet treeSet = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//下面 调用String的 compareTo方法进行字符串大小比较
//如果老韩要求加入的元素,按照长度大小排序
//return ((String) o2).compareTo((String) o1);
return ((String) o1).length() - ((String) o2).length();
}
});
//添加数据.
treeSet.add("jack");
treeSet.add("tom");//3
treeSet.add("sp");
treeSet.add("a");
treeSet.add("abc");//3
System.out.println("treeSet=" + treeSet);
加入不了相同值的元素,也不能加入NULL,因为TreeSet的输出是需要排序的,NULL无法进行排序
4.7 Map接口(与Collection并列存在)
在上面可知,Set接口是基于Map实现的,而Map存放的是键值对,key-value,在Set中value是用常量对象present进行替代的,实际上只用到了key

4.7.1 Map接口全面说明

注释:
- Map的输入和输出是无序的,原因跟Set分析一样,是按照key的哈希值(也就是在table表中的排序输出的)。
- 添加元素用put方法
- key不允许重复,当有相同的key时,会进行替换覆盖
//老韩解读Map 接口实现类的特点, 使用实现类HashMap
//1. Map与Collection并列存在。用于保存具有映射关系的数据:Key-Value(双列元素)
//2. Map 中的 key 和 value 可以是任何引用类型的数据,会封装到HashMap$Node 对象中
//3. Map 中的 key 不允许重复,原因和HashSet 一样,前面分析过源码.
//4. Map 中的 value 可以重复
//5. Map 的key 可以为 null, value 也可以为null ,注意 key 为null,
// 只能有一个,value 为null ,可以多个
//6. 常用String类作为Map的 key
//7. key 和 value 之间存在单向一对一关系,即通过指定的 key 总能找到对应的 value
Map map = new HashMap();
map.put("no1", "韩顺平");//k-v
map.put("no2", "张无忌");//k-v
map.put("no1", "张三丰");//当有相同的k , 就等价于替换.
map.put("no3", "张三丰");//k-v
map.put(null, null); //k-v
map.put(null, "abc"); //等价替换
map.put("no4", null); //k-v
map.put("no5", null); //k-v
map.put(1, "赵敏");//k-v
map.put(new Object(), "金毛狮王");//k-v
// 通过get 方法,传入 key ,会返回对应的value
System.out.println(map.get("no2"));//张无忌
System.out.println("map=" + map);
Map接口最重要最复杂最核心的特点!!!!!!!
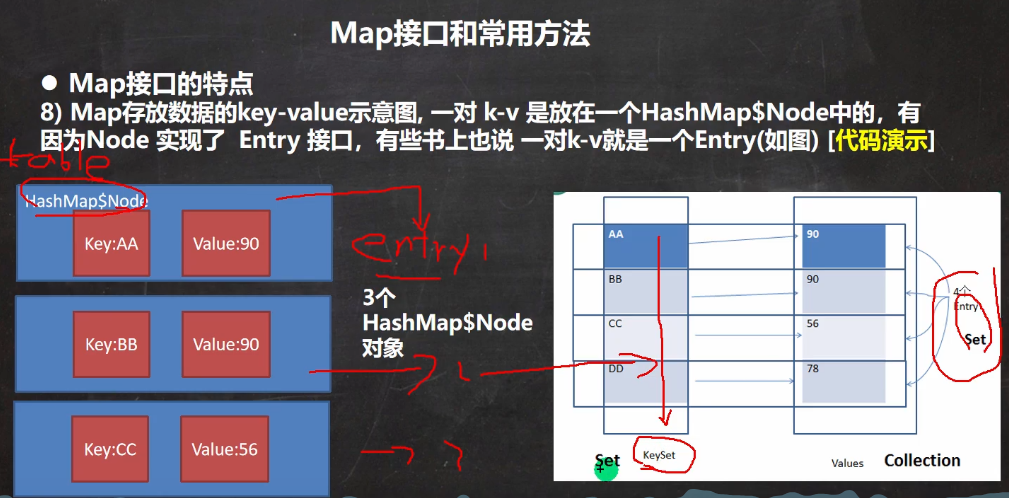
由于Map是按照键对值存放,且table结构复杂,不便于遍历取值。为了方便程序员遍历Map数据,Map将Node数据的引用(不是复制了一份)存放在了Entry中,所有的数据组成了一个EntrySet 集合(Set类型) ,该集合存放的元素的类型 Entry。这样,我们可以通过map.values()和map.keySet()获得key值和value值,更重要的是能够使用Map.entry的两个重要方法:getKey()和getValue()。
Entry是Map定义的一个内部接口,在实现Map的子类中,如HashMap,HMap的Node结点是实现了Entry接口的
Map map = new HashMap();
map.put("no1", "韩顺平");//k-v
map.put("no2", "张无忌");//k-v
map.put(new Car(), new Person());//k-v
//老韩解读
//1. k-v 最后是 HashMap$Node node = newNode(hash, key, value, null)
//2. k-v 为了方便程序员的遍历,还会 创建 EntrySet 集合 ,该集合存放的元素的类型 Entry, 而一个Entry
// 对象存放的是k,v。即:EntrySet<Entry<K,V>>,实际定义:transient Set<Map.Entry<K,V>> entrySet;
//3. entrySet 中, 定义的类型是 Map.Entry ,但是实际上存放的还是 HashMap$Node
// 这是因为 static class Node<K,V> implements Map.Entry<K,V>
// 就是Node类实现了Entry,那么这个类的对象实例就可以赋给接口类Entry
//4. 当把 HashMap$Node 对象 存放到 entrySet 就方便我们的遍历, 因为 Map.Entry 提供了两个重要方法
// K getKey(); V getValue();
Set set = map.entrySet();
System.out.println(set.getClass());// HashMap$EntrySet
for (Object obj : set) {
//System.out.println(obj.getClass()); //HashMap$Node
//为了从 HashMap$Node 取出k-v
//1. 先做一个向下转型
Map.Entry entry = (Map.Entry) obj;
System.out.println(entry.getKey() + "-" + entry.getValue() );
}
4.7.2 Map接口常用方法

4.7.3 Map六大遍历方式

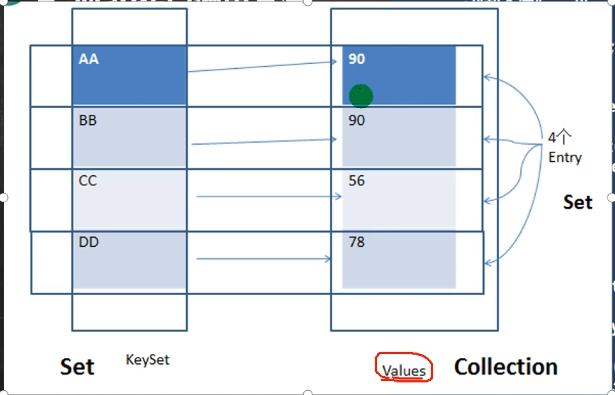
注意什么时候需要将Object对象转换为Map.Entry对象
Map map = new HashMap();
map.put("邓超", "孙俪");
map.put("王宝强", "马蓉");
map.put("宋喆", "马蓉");
map.put("刘令博", null);
map.put(null, "刘亦菲");
map.put("鹿晗", "关晓彤");
//第一组: 先取出 所有的Key , 通过Key 取出对应的Value
Set keyset = map.keySet(); // Entry里面的keySet()
//(1) 增强for
System.out.println("-----第一种方式-------");
for (Object key : keyset) {
System.out.println(key + "-" + map.get(key)); // 通过map.get(key)取得value值
}
//(2) 迭代器
System.out.println("----第二种方式--------");
Iterator iterator = keyset.iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
System.out.println(key + "-" + map.get(key));
}
//第二组: 把所有的values取出
Collection values = map.values();
//这里可以使用所有的Collections使用的遍历方法
//(1) 增强for
System.out.println("---取出所有的value 增强for----");
for (Object value : values) {
System.out.println(value);
}
//(2) 迭代器
System.out.println("---取出所有的value 迭代器----");
Iterator iterator2 = values.iterator();
while (iterator2.hasNext()) {
Object value = iterator2.next();
System.out.println(value);
}
//第三组: 通过EntrySet 来获取 k-v (阿里开发规范,使用entrySet的方式遍历map)
//重要!!!!!
Set entrySet = map.entrySet();// EntrySet<Map.Entry<K,V>>
//(1) 增强for
System.out.println("----使用EntrySet 的 for增强(第3种)----");
for (Object entry : entrySet) {
//将entry 转成 Map.Entry,向下转型
Map.Entry m = (Map.Entry) entry; // 转成Map.Entry很关键
System.out.println(m.getKey() + "-" + m.getValue());
}
//(2) 迭代器
System.out.println("----使用EntrySet 的 迭代器(第4种)----");
Iterator iterator3 = entrySet.iterator(); // 因为entrySet是Set类型
while (iterator3.hasNext()) {
Object entry = iterator3.next();
//System.out.println(next.getClass());//HashMap$Node -实现-> Map.Entry (getKey,getValue)
//向下转型 Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
4.7.4 Map课堂练习(遍历)
/**
* 使用HashMap添加3个员工对象,要求
* 键:员工id
* 值:员工对象
*
* 并遍历显示工资>18000的员工(遍历方式最少两种)
* 员工类:姓名、工资、员工id
*/
// 创建map
Map map = new HashMap();
// 添加对象
map.put(1, new Worker(1, 15000, "张三"));
map.put(2, new Worker(2, 48000, "李四"));
map.put(3, new Worker(5, 38000, "王五"));
// 第一种
System.out.println("=========第一种方式:keyset========");
Set set = map.keySet();
System.out.println("工资大于18000的有:");
for (Object o : set) {
Worker worker = (Worker) map.get(o);
if (worker.getSalary() > 18000) {
System.out.println(worker.getName() + "--" + worker.getSalary());
}
}
// 第二种:迭代器和增强for
System.out.println("=========第二种方式:Entryset========");
Set entry = map.entrySet();
System.out.println("=========迭代器========");
// 迭代器
Iterator iterator = entry.iterator();
System.out.println("工资大于18000的有:");
while (iterator.hasNext()) {
Map.Entry next = (Map.Entry)iterator.next();
Worker worker = (Worker)next.getValue(); // value是Worker对象
if (worker.getSalary() > 18000) {
System.out.println(worker.getName() + "--" + worker.getSalary());
}
}
System.out.println("=========增强for========");
// 增强for循环
System.out.println("工资大于18000的有:");
for (Object o : entry) {
Map.Entry entry1 = (Map.Entry)o;
Worker worker = (Worker) entry1.getValue();
if (worker.getSalary() > 18000) {
System.out.println(worker.getName() + "--" + worker.getSalary());
}
}
4.7.5 HashMap小结

4.7.6 HashMap底层机制及源码剖析
HashSet那节其实已经讲得差不多了
4.7.6.1 底层机制
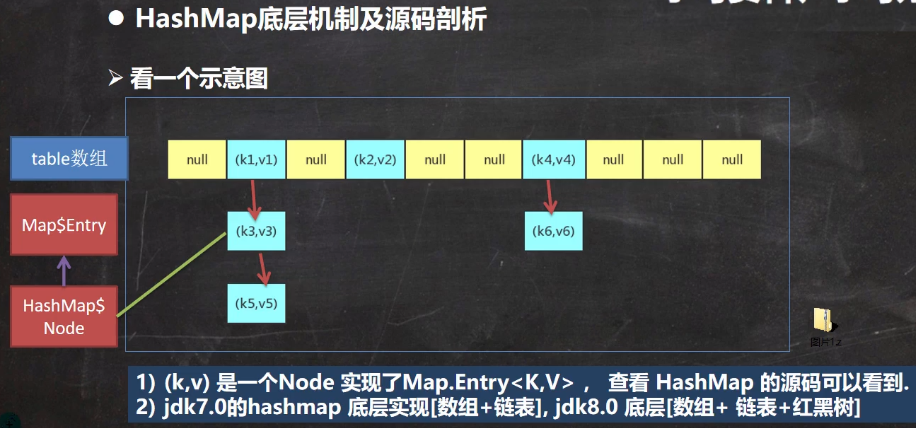
4.7.6.2 源码分析

debug源码:
@SuppressWarnings({"all"})
public class HashMapSource1 {
public static void main(String[] args) {
HashMap map = new HashMap();
map.put("java", 10);//ok
map.put("php", 10);//ok
map.put("java", 20);//替换value
System.out.println("map=" + map);//
/*老韩解读HashMap的源码+图解
1. 执行构造器 new HashMap()
初始化加载因子 loadfactor = 0.75
HashMap$Node[] table = null
2. 执行put 调用 hash方法,计算 key的 新hash值 (h = key.hashCode()) ^ (h >>> 16)
public V put(K key, V value) {//K = "java" value = 10
return putVal(hash(key), key, value, false, true);
}
3. 执行 putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;//辅助变量
//如果底层的table 数组为null, 或者 length =0 , 就扩容到16
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//取出hash值对应的table的索引位置的Node, 如果为null, 就直接把加入的k-v
//, 创建成一个 Node ,加入该位置即可
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;//辅助变量
// 如果table的索引位置的key的hash相同和新的key的hash值相同,
// 并 满足(table现有的结点的key和准备添加的key是同一个对象 || equals返回真)
// 就认为不能加入新的k-v
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)//如果当前的table的已有的Node 是红黑树,就按照红黑树的方式处理
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//如果找到的结点,后面是链表,就循环比较
for (int binCount = 0; ; ++binCount) {//死循环
if ((e = p.next) == null) {//如果整个链表,没有和他相同,就加到该链表的最后
p.next = newNode(hash, key, value, null);
//加入后,判断当前链表的个数,是否已经到8个,到8个,后
//就调用 treeifyBin 方法进行红黑树的转换
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash && //如果在循环比较过程中,发现有相同,就break,就只是替换value
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value; //替换,key对应value
afterNodeAccess(e);
return oldValue;
}
}
++modCount;//每增加一个Node ,就size++
if (++size > threshold[12-24-48])//如size > 临界值,就扩容
resize();
afterNodeInsertion(evict);
return null;
}
5. 关于树化(转成红黑树)
//如果table 为null ,或者大小还没有到 64,暂时不树化,而是进行扩容.
//否则才会真正的树化 -> 剪枝
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
}
*/
}
}
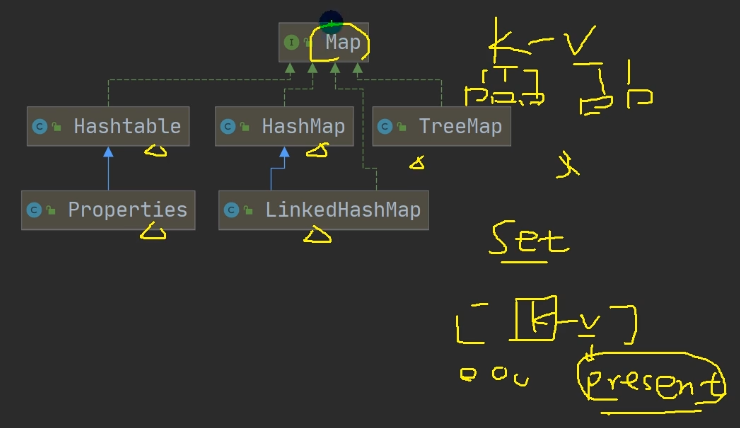
4.7.7 HashTable(与HashMap同级)
HashTable线程安全!HashMap线程不安全!
底层是Entry数组

Debug代码:
Hashtable table = new Hashtable();//ok
table.put("john", 100); //ok
//table.put(null, 100); //异常 NullPointerException
//table.put("john", null);//异常 NullPointerException
table.put("lucy", 100);//ok
table.put("lic", 100);//ok
table.put("lic", 88);//替换
table.put("hello1", 1);
table.put("hello2", 1);
table.put("hello3", 1);
table.put("hello4", 1);
table.put("hello5", 1);
table.put("hello6", 1);
System.out.println(table);
源码底层解读:
简单说明一下Hashtable的底层
1. 底层有数组 Hashtable$Entry[] 初始化大小为 11
2. 临界值 threshold为8: 11 * 0.75 = 8
3. 扩容: 按照自己的扩容机制来进行即可.
4. 执行 方法 addEntry(hash, key, value, index); 添加K-V 封装到Entry
5. 当 if (count >= threshold) 满足时,就进行扩容
5. 按照 int newCapacity = (oldCapacity << 1) + 1; 的大小扩容.(扩容机制)
自己理一下思路:HashTable底层是一个Entry数组,当添加数据时候,进入put方法,首先检查value是否为NULL,NULL会报错,结束;遍历Entry数组,如果当前数据的哈希值与某一数据相同,且equals相同,则进行替换。否则,进入addEntry()方法。



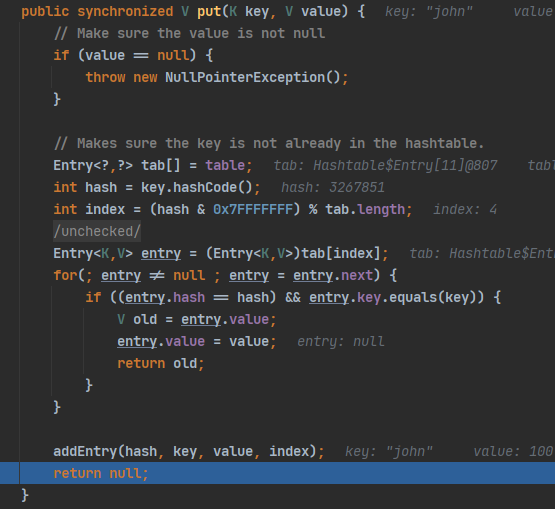
可以看到默认初始数组大小为11,临界值比例值为0.75;
底层数组类型为Entry;
synchronized也解释了HashTable是线程安全的,图3源码展示了不允许value为null,设计的原因。而HashMap在put的时候会调用hash()方法来计算key的hashcode值,可以从hash算法中看出当key==null时返回的值为0;
扩容机制解读:不同于其他集合子类,其具体方法是 原来的两倍再加1
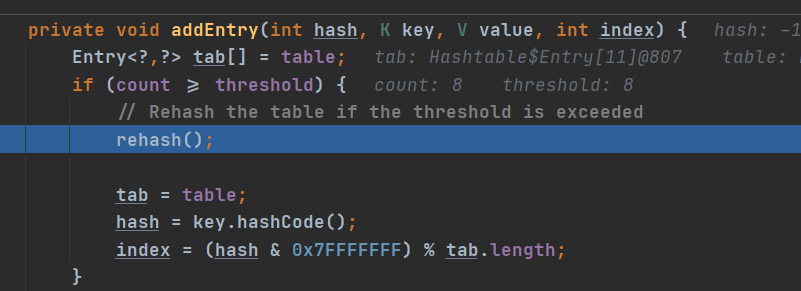
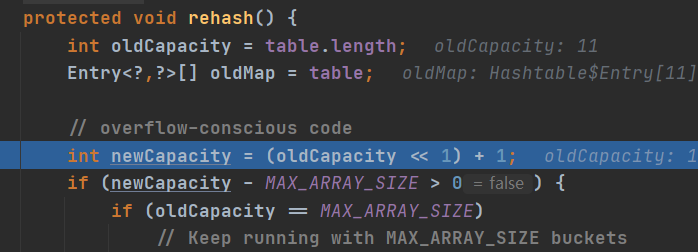
与HashMap的对比:

HashTable的哈希值计算是直接int hash = key.hashCode();
4.7.8 Properties
IO流章节再细讲!
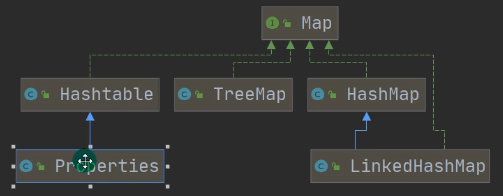

//老韩解读
//1. Properties 继承 Hashtable
//2. 可以通过 k-v 存放数据,当然key 和 value 不能为 null
//增加
Properties properties = new Properties();
//properties.put(null, "abc");//抛出 空指针异常
//properties.put("abc", null); //抛出 空指针异常
properties.put("john", 100);//k-v
properties.put("lucy", 100);
properties.put("lic", 100);
properties.put("lic", 88);//如果有相同的key , value被替换
System.out.println("properties=" + properties);
//通过k 获取对应值
System.out.println(properties.get("lic"));//88
//删除
properties.remove("lic");
System.out.println("properties=" + properties);
//修改
properties.put("john", "约翰");
System.out.println("properties=" + properties);
4.7.9 TreeMap
默认按照ASCII码升序排序(TreeSet底层是TreeMap,也是这样排序)
重写排序规则:有参构造器中重写Compare方法
TreeMap treeMap = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//按照传入的 k(String) 的大小进行排序
//return ((String) o2).compareTo((String) o1);
//按照K(String) 的长度大小排序
return ((String) o2).length() - ((String) o1).length();
}
});
源码解读:
老韩解读源码:
1. 构造器. 把传入的实现了 Comparator接口的匿名内部类(对象),传给给TreeMap的comparator
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
2. 调用put方法
2.1 第一次添加, 把k-v 封装到 Entry对象,放入root(根结点)
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
2.2 以后添加
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do { //遍历所有的key , 给当前key找到适当位置
parent = t;
cmp = cpr.compare(key, t.key);//动态绑定到我们的匿名内部类的compare
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else //如果遍历过程中,发现准备添加Key 和当前已有的Key相等,就不添加
return t.setValue(value);
} while (t != null);
}
需要注意一点的是:无论是在TreeSet,还是在TreeMap,当我们重写了Compare方法为比较字符串长度,如果有两个相同字符串长度的值需要添加,第一个添加成功后,第二个是无法添加进去的,而不是像之前的集合子类是进行替换覆盖的,换言之就是底层不是进行替换的,而是直接返回旧的值。源码中,当cmp返回为0时,此时两个对象的比较是在某种规则下是相同的,此时在do while循环中,是执行else语句返回旧值。
例如:按照比较字符串长度进行排序输出的规则下,第三个键值对就无法添加进去,因为已经有tom了
treeMap.put("jack", "杰克");
treeMap.put("tom", "汤姆");
treeMap.put("hsp", "韩顺平");//加入不了
4.8 开发中如何选择集合实现类(记住)

4.9 Collections工具类

演示:
//创建ArrayList 集合,用于测试.
List list = new ArrayList();
list.add("tom");
list.add("smith");
list.add("king");
list.add("milan");
list.add("tom");
// reverse(List):反转 List 中元素的顺序
Collections.reverse(list);
System.out.println("list=" + list);
// shuffle(List):对 List 集合元素进行随机排序
// for (int i = 0; i < 5; i++) {
// Collections.shuffle(list);
// System.out.println("list=" + list);
// }
// sort(List):根据元素的自然顺序对指定 List 集合元素按升序排序
Collections.sort(list);
System.out.println("自然排序后");
System.out.println("list=" + list);
// sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
//我们希望按照 字符串的长度大小排序
Collections.sort(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//可以加入校验代码.
return ((String) o2).length() - ((String) o1).length();
}
});
System.out.println("字符串长度大小排序=" + list);

//比如
Collections.swap(list, 0, 1);
System.out.println("交换后的情况");
System.out.println("list=" + list);
//Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
System.out.println("自然顺序最大元素=" + Collections.max(list));
//Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素
//比如,我们要返回长度最大的元素
Object maxObject = Collections.max(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String)o1).length() - ((String)o2).length();
}
});
System.out.println("长度最大的元素=" + maxObject);
//Object min(Collection)
//Object min(Collection,Comparator)
//上面的两个方法,参考max即可
//int frequency(Collection,Object):返回指定集合中指定元素的出现次数
System.out.println("tom出现的次数=" + Collections.frequency(list, "tom"));
//void copy(List dest,List src):将src中的内容复制到dest中
ArrayList dest = new ArrayList();
//为了完成一个完整拷贝,我们需要先给dest 赋值,大小和list.size()一样
for(int i = 0; i < list.size(); i++) {
dest.add("");
}
//拷贝
Collections.copy(dest, list);
System.out.println("dest=" + dest);
//boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换 List 对象的所有旧值
//如果list中,有tom 就替换成 汤姆
Collections.replaceAll(list, "tom", "汤姆");
System.out.println("list替换后=" + list);
4.10 本章作业
4.10.1 作业1

public class HomeWork {
public static void main(String[] args) {
List list = new ArrayList();
// 添加新闻对象
list.add(new News("新冠确诊病例超千万,数百万印度教信徒赴恒河\"圣浴\"引民众担忧"));
list.add(new News("男子突然想起2个月前钓的鱼还在网兜里,捞起一看赶紧放生"));
// 要进行倒序遍历,最好使用普通for循环
for (int i = list.size() - 1; i >= 0; i--) {
News news = (News) list.get(i);
if (news.getTitles().length() > 15) {
System.out.println(news.getTitles().substring(0, 15) + "...");
} else {
System.out.println(news.getTitles());
}
}
}
}
class News {
private String titles;
private String news;
public News(String titles) {
this.titles = titles;
}
@Override
public String toString() {
return "News{" +
"titles='" + titles + '\'' + '}';
}
public String getTitles() {
return titles;
}
public void setTitles(String titles) {
this.titles = titles;
}
public String getNews() {
return news;
}
public void setNews(String news) {
this.news = news;
}
}
/**
男子突然想起2个月前钓的鱼还在...
新冠确诊病例超千万,数百万印度...
*/
4.10.2 作业2

public class Homework02 {
public static void main(String[] args) {
ArrayList arrayList = new ArrayList();
Car car = new Car("宝马", 400000);
Car car2 = new Car("宾利",5000000);
//1.add:添加单个元素
arrayList.add(car);
arrayList.add(car2);
System.out.println(arrayList);
//* 2.remove:删除指定元素
arrayList.remove(car);
System.out.println(arrayList);
//* 3.contains:查找元素是否存在
System.out.println(arrayList.contains(car));//F
//* 4.size:获取元素个数
System.out.println(arrayList.size());//1
//* 5.isEmpty:判断是否为空
System.out.println(arrayList.isEmpty());//F
//* 6.clear:清空
//System.out.println(arrayList.clear(););
//* 7.addAll:添加多个元素
System.out.println(arrayList);
arrayList.addAll(arrayList);//2个宾利
System.out.println(arrayList);
//* 8.containsAll:查找多个元素是否都存在
arrayList.containsAll(arrayList);//T
//* 9.removeAll:删除多个元素
//arrayList.removeAll(arrayList); //相当于清空
//* 使用增强for和 迭代器来遍历所有的car , 需要重写 Car 的toString方法
for (Object o : arrayList) {
System.out.println(o);//
}
System.out.println("===迭代器===");
Iterator iterator = arrayList.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println(next);
}
}
}
4.10.3 作业3

public class HomeWork03 {
public static void main(String[] args) {
// * 按要求完成下列任务
// * 1)使用HashMap类实例化一个Map类型的对象m,键(String)和值(int)分别用于存储员工的姓名和工资,
Map m = new HashMap();
// * 存入数据如下: jack—650元;tom—1200元;smith——2900元;
m.put("jack", 650);//int->Integer
m.put("tom", 1200);//int->Integer
m.put("smith", 2900);//int->Integer
System.out.println(m);
// * 2)将jack的工资更改为2600元
m.replace("jack", 2600);
System.out.println(m);
// * 3)为所有员工工资加薪100元;
Set set = m.keySet();
for (Object o : set) {
m.put(o, (Integer)m.get(o) + 100);
}
System.out.println(m);
// * 4)遍历集合中所有的员工
System.out.println("使用entry遍历:");
Set set1 = m.entrySet();
for (Object o : set1) {
Map.Entry entry01 = (Map.Entry) o;
System.out.print(entry01.getKey() + "---" + entry01.getValue() + " ");
}
System.out.println();
// * 5)遍历集合中所有的工资
Collection values = m.values();
for (Object value : values) {
System.out.println(value);
}
}
}
/**
{tom=1200, smith=2900, jack=650}
{tom=1200, smith=2900, jack=2600}
{tom=1300, smith=3000, jack=2700}
使用entry遍历:
tom---1300 smith---3000 jack---2700
1300
3000
2700
*/
4.10.4 作业4
代码分析题
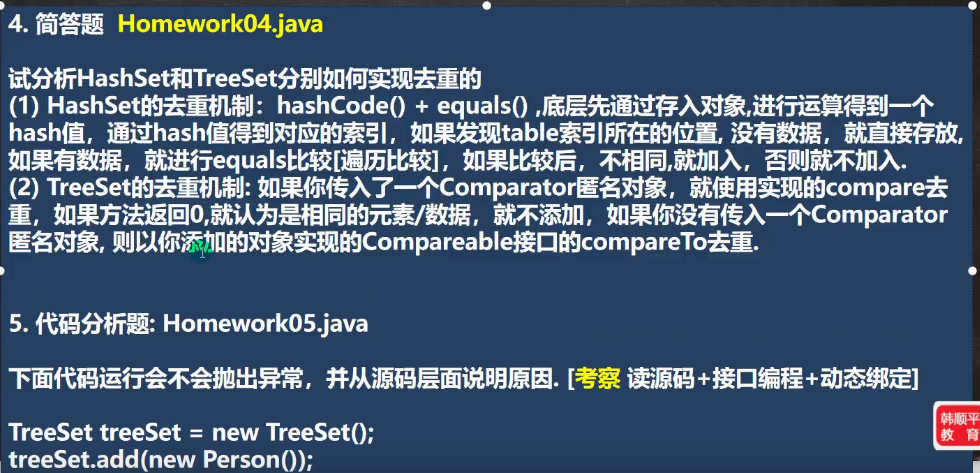
对TreeSet去重机制的解读:
当创建一个新的TreeSet时,实际上是新的TreeMap。而在TreeMap底层,若不传入一个重写的比较器对象的话,那么底层会调用添加对象本身实现的比较器,涉及到这块的源码如下:
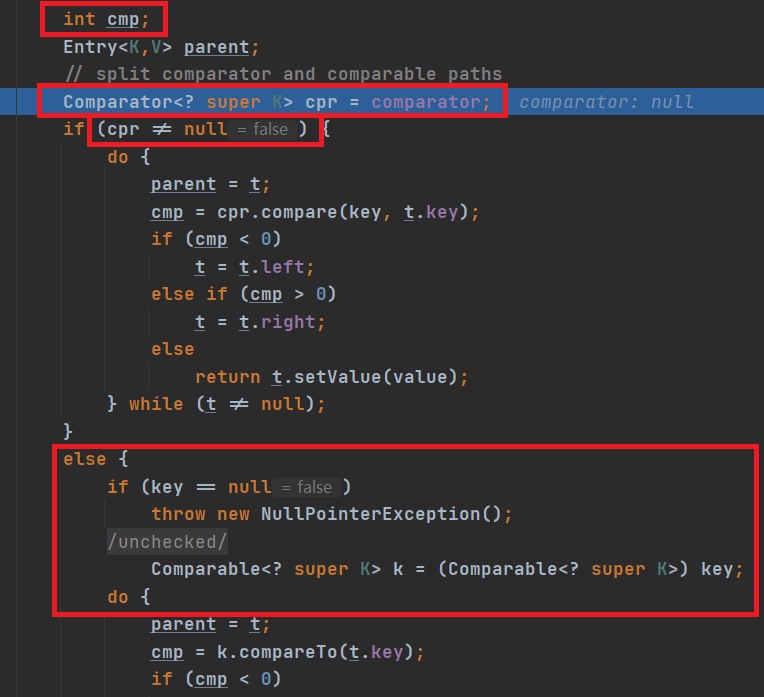
当我们传入了比较器,代码就会运行if那段,调用重写的compare方法进行比较,然后将值返回给cmp,进行下一步处理,如果是0,说明有旧值跟当前插入对象相同,就不进行插入操作。
如果是无参构造器的话!就直接调用插入对象自己的compareTo()方法:如下,当我们插入是String对象时,就调用String对象实现的compareTo()方法
treeSet.add("jack");
treeSet.add("tom");
treeSet.add("sp");
treeSet.add("a");
例子:下面的操作会报错!
@SuppressWarnings({"all"})
public class Homework05 {
public static void main(String[] args) {
TreeSet treeSet = new TreeSet();
//分析源码
//add 方法,因为 TreeSet() 构造器没有传入Comparator接口的匿名内部类
//所以在底层 Comparable<? super K> k = (Comparable<? super K>) key;
//即 把 Perosn转成 Comparable类型
treeSet.add(new Person());//报错!ClassCastException. Person对象没有实现Comparator接口的比较器方法
}
}
class Person{}
@SuppressWarnings({"all"})
public class Homework05 {
public static void main(String[] args) {
TreeSet treeSet = new TreeSet();
treeSet.add(new Person()); // 成功添加
treeSet.add(new Person()); // 添加失败
treeSet.add(new Person()); // 添加失败
System.out.println(treeSet);//因为compareTo()方法均返回0,在TreeMap底层,只能成功添加一个
}
}
class Person implements Comparable{
@Override
public int compareTo(Object o) {
return 0;
}
}
4.10.5 作业5
代码分析题

注解:
remove操作会失败,因为remove会通过p1的哈希值来确定p1在table表中的位置,然而p1已经发生改变,重新定位不到索引为1的老p1。此时打印出来有两个元素:p1(1001CC)和p2。进入到add方法,此时1001CC放在索引为3的位置(并不是P1的位置,因为P1原来的AA被修改为CC,但位置并没有发生改变)。打印元素有:p1、p2、1001CC。再次添加1001AA,定位到索引为1的位置,然而p1发生了改变,重写的equals和hashCode方法都不能将这两个元素判定为相等,所以1001AA挂载在p1的位置。最后打印,有4个元素:p1、1001AA、p2、1001CC。
@SuppressWarnings({"all"})
public class Homework06 {
public static void main(String[] args) {
HashSet set = new HashSet();//ok
Person p1 = new Person(1001,"AA");//ok
Person p2 = new Person(1002,"BB");//ok
set.add(p1);//ok
set.add(p2);//ok
p1.name = "CC";
set.remove(p1);
System.out.println(set);//2
set.add(new Person(1001,"CC"));
System.out.println(set);//3
set.add(new Person(1001,"AA"));
System.out.println(set);//4
}
}
class Person {
public String name;
public int id;
public Person(int id, String name) {
this.name = name;
this.id = id;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return id == person.id &&
Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, id);
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", id=" + id +
'}';
}
}
/**
[Person{name='BB', id=1002}, Person{name='CC', id=1001}]
[Person{name='BB', id=1002}, Person{name='CC', id=1001}, Person{name='CC', id=1001}]
[Person{name='BB', id=1002}, Person{name='CC', id=1001}, Person{name='CC', id=1001}, Person{name='AA', id=1001}]
*/
第五章 面向对象编程(高级部分) 只记重点,其余看PDF
5.1 类变量和类方法(static,/静态变量和静态方法)
5.1.1 类变量/静态变量
static变量是同一个类所有对象共享的,此外,static类变量,在类加载的时候就已经生成了,即类变量是随着类的加载而创建,即使是没有创建对象实例也可以访问。也随着类的消亡而销毁。

访问类变量和类方法的时候,要遵循访问权限限制
5.1.2 类方法/静态方法



- 理解:因为静态变量和静态方法是随着类的加载就加载初始化好了,而普通变量和方法此时并没有进行加载。
课堂作业:



5.2 深入理解main方法


public class Main01 {
//静态的变量/属性
private static String name = "韩顺平教育";
//非静态的变量/属性
private int n1 = 10000;
//静态方法
public static void hi() {
System.out.println("Main01的 hi方法");
}
//非静态方法
public void cry() {
System.out.println("Main01的 cry方法");
}
public static void main(String[] args) {
//可以直接使用 name
//1. 静态方法main 可以访问本类的静态成员
System.out.println("name=" + name);
hi();
//2. 静态方法main 不可以访问本类的非静态成员
//System.out.println("n1=" + n1);//错误
//cry();
//3. 静态方法main 要访问本类的非静态成员,需要先创建对象 , 再调用即可
Main01 main01 = new Main01();
System.out.println(main01.n1);//ok
main01.cry();
}
}
5.3 代码块*
5.3.1 代码块的基本介绍
做初始化的操作


代码块调用的顺序优先于构造器,不管调用哪个构造器创建对象,都会先调用代码块的内容
5.3.2 代码块的注意事项和细节讨论*
类只会加载一次,但可以实例化出多个对象。

public class CodeBlockDetail01 {
public static void main(String[] args) {
//类被加载的情况举例
//1. 创建对象实例时(new)
// AA aa = new AA();
//2. 创建子类对象实例,父类也会被加载, 而且,父类先被加载,子类后被加载
// AA aa2 = new AA();
//3. 使用类的静态成员时(静态属性,静态方法)
// System.out.println(Cat.n1);
//static代码块,是在类加载时,执行的,而且只会执行一次.
// DD dd = new DD();
// DD dd1 = new DD();
// 普通的代码块,在创建对象实例时,会被隐式的调用。
// 被创建一次,就会调用一次。
// 如果只是使用类的静态成员时,普通代码块并不会执行
System.out.println(DD.n1);//8888, 静态模块块一定会执行
}
}
class DD {
public static int n1 = 8888;//静态属性
//静态代码块
static {
System.out.println("DD 的静态代码1被执行...");//
}
//普通代码块, 在new 对象时,被调用,而且是每创建一个对象,就调用一次
//可以这样简单的,理解 普通代码块是构造器的补充
{
System.out.println("DD 的普通代码块...");
}
}
class Animal {
//静态代码块
static {
System.out.println("Animal 的静态代码1被执行...");//
}
}
class Cat extends Animal {
public static int n1 = 999;//静态属性
//静态代码块
static {
System.out.println("Cat 的静态代码1被执行...");//
}
}
class BB {
//静态代码块
static {
System.out.println("BB 的静态代码1被执行...");//1
}
}
class AA extends BB {
//静态代码块
static {
System.out.println("AA 的静态代码1被执行...");//2
}
}

很好记忆,静态跟类加载有关,所以最先执行。
执行顺序:静态属性和代码块 > 普通属性和代码块 >构造器 这里没方法的事情
public class CodeBlockDetail02 {
public static void main(String[] args) {
A a = new A();// (1) A 静态代码块01 (2) getN1被调用...(3)A 普通代码块01 (4)getN2被调用... (5)A() 构造器被调用
}
}
class A {
{ //普通代码块
System.out.println("A 普通代码块01");
}
private int n2 = getN2();//普通属性的初始化
static { //静态代码块
System.out.println("A 静态代码块01");
}
//静态属性的初始化
private static int n1 = getN1();
public static int getN1() {
System.out.println("getN1被调用...");
return 100;
}
public int getN2() { //普通方法/非静态方法
System.out.println("getN2被调用...");
return 200;
}
//无参构造器
public A() {
System.out.println("A() 构造器被调用");
}
}

构造器中隐藏的super和代码块结构一定要记住。
这里就解释了为什么普通代码块执行顺序在构造器前面:其实是进入构造器后先执行super和普通代码块,完了再执行构造器的内容。

注意构造器中隐式调用的super()方法,这导致父类的初始化操作总是比子类同样的初始化操作要先执行。
课堂练习:


5.4 单例设计模式(设计模式内容)

- 饿汉式

示例代码:
- 饿汉式(还没使用类的实例,就提前创建好了一个实例)
public class SingleTon01 {
public static void main(String[] args) {
// GirlFriend xh = new GirlFriend("小红");
// GirlFriend xb = new GirlFriend("小白");
//通过方法可以获取对象
GirlFriend instance = GirlFriend.getInstance();
System.out.println(instance);
GirlFriend instance2 = GirlFriend.getInstance();
System.out.println(instance2);
System.out.println(instance == instance2);//T
}
}
//有一个类, GirlFriend
//只能有一个女朋友
class GirlFriend {
private String name;
//public static int n1 = 100;
//为了能够在静态方法中,返回 gf对象,需要将其修饰为static
//對象,通常是重量級的對象, 餓漢式可能造成創建了對象,但是沒有使用.
private static GirlFriend gf = new GirlFriend("小红红");
//如何保障我们只能创建一个 GirlFriend 对象
//步骤[单例模式-饿汉式](类的实例还没使用,就提前创建成功)
//1. 将构造器私有化(防止在类的外部创建实例)
//2. 在类的内部直接创建对象(该对象是static)
//3. 提供一个公共的static方法,返回 gf对象
private GirlFriend(String name) {
System.out.println("構造器被調用.");
this.name = name;
}
public static GirlFriend getInstance() {
return gf;
}
@Override
public String toString() {
return "GirlFriend{" +
"name='" + name + '\'' +
'}';
}
}
- 懒汉式:使用的时候才创建实例
//希望在程序運行過程中,只能創建一個Cat對象
//使用單例模式
class Cat {
private String name;
private static Cat cat ; //默認是null
//步驟
//1.仍然構造器私有化
//2.定義一個static靜態屬性對象
//3.提供一個public的static方法,可以返回一個Cat對象
//4.懶漢式,只有當用戶使用getInstance時,才返回cat對象, 後面再次調用時,會返回上次創建的cat對象
// 從而保證了單例
private Cat(String name) {
System.out.println("構造器調用...");
this.name = name;
}
public static Cat getInstance() {
if(cat == null) {//如果還沒有創建cat對象
cat = new Cat("小可愛");
}
return cat;
}
}

5.5 final关键字


-
如果我们用final去修饰静态属性的时候,若初始化位置在构造器中,此时当类加载时,构造器还没有被调用,因此这样的初始化是错误的。
注意观察TAX_RATE2和3的加载时机,结合上面提到的注意事项,就能明白为什么final修饰的静态属性不能放在构造器中初始化

-
因为此时整个类已经不能被继承,既然不能被继承,那类中的方法自然不能被重写/覆盖。
-
static final修饰的变量如果是基本数据类型或String,就不会进行类加载,而是直接获取数据值。
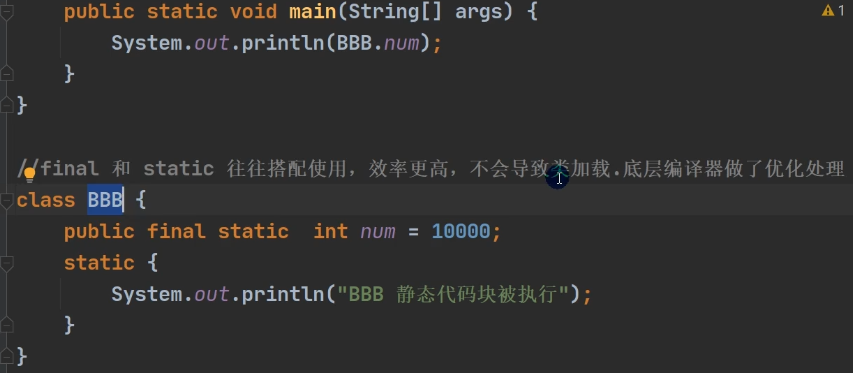
结果:10000
如果去掉final,打印结果将会是:
BBB 静态代码块被执行
10000
课堂作业:
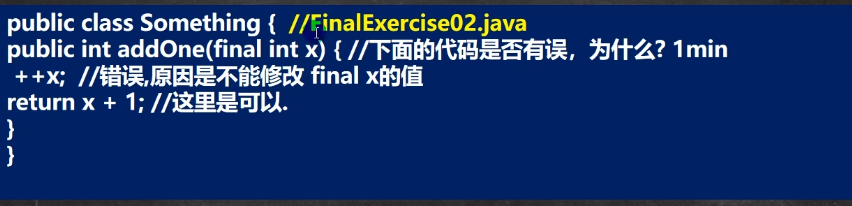
5.6 抽象类
当父类的一些方法不能确定时,可以用abstract关键字来修饰该方法,这个方法就是抽象方法,用abstract来修饰该类就是抽象类。
5.6.1 引出抽象类
//思考:这里eat 这里你实现了,其实没有什么意义
//即: 父类方法不确定性的问题
//===> 考虑将该方法设计为抽象(abstract)方法
//===> 所谓抽象方法就是没有实现的方法
//===> 所谓没有实现就是指,没有方法体
//===> 当一个类中存在抽象方法时,需要将该类声明为abstract类
//===> 一般来说,抽象类会被继承,有其子类来实现抽象方法.
// public void eat() {
// System.out.println("这是一个动物,但是不知道吃什么..");
// }
public abstract void eat() ; // 抽象类不能有方法体
5.6.2 抽象类的介绍

5.6.3 抽象类的细节

- 注意!只要有抽象方法,这个类就要用abstract声明!
- 只能修饰类和方法!!!!!!

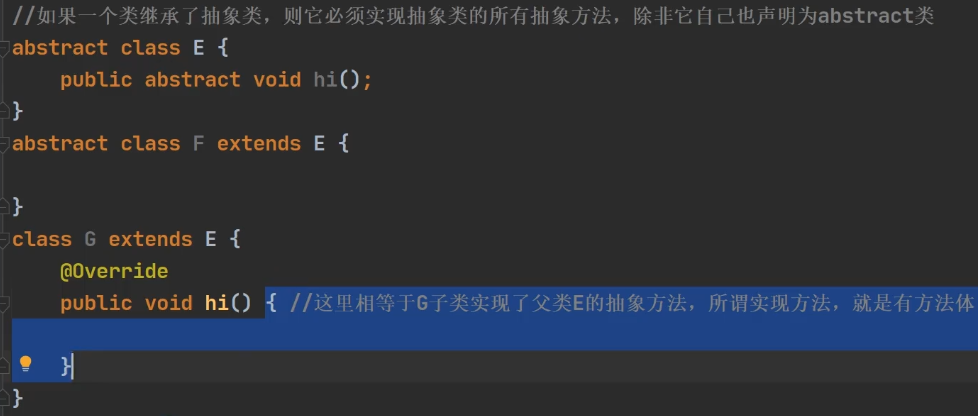

- 这一点很重要!因为如果被private、final、static修饰,那么子类是没有机会去重写这个抽象方法,与子类实现抽象类是相违背的。
5.6.4 抽象类最佳实践—模板设计模式
P401 讲得不错,设计理念

设计精髓:共同代码提取,不同代码抽象
主方法:
public class TestTemplate {
public static void main(String[] args) {
AA aa = new AA();
aa.calculateTime(); //这里还是需要有良好的OOP基础,对多态的动态绑定机制
BB bb = new BB();
bb.calculateTime(); //根据运行类型,calculateTime()方法中job方法会进入到对应的类中——>动态绑定机制
}
}
模板:动态绑定机制和抽象类结合起来了!
abstract public class Template { //抽象类-模板设计模式
public abstract void job();//抽象方法
public void calculateTime() {//实现方法,调用job方法
//得到开始的时间
long start = System.currentTimeMillis();
job(); //动态绑定机制
//得的结束的时间
long end = System.currentTimeMillis();
System.out.println("任务执行时间 " + (end - start));
}
}
A类:
public class AA extends Template {
//计算任务
//1+....+ 800000
@Override
public void job() { //实现Template的抽象方法job
long num = 0;
for (long i = 1; i <= 800000; i++) {
num += i;
}
}
// public void job2() {
// //得到开始的时间
// long start = System.currentTimeMillis();
// long num = 0;
// for (long i = 1; i <= 200000; i++) {
// num += i;
// }
// //得的结束的时间
// long end = System.currentTimeMillis();
// System.out.println("AA 执行时间 " + (end - start));
// }
}
B类:
public class BB extends Template{
public void job() {//这里也去,重写了Template的job方法
long num = 0;
for (long i = 1; i <= 80000; i++) {
num *= i;
}
}
}
5.7 接口*
5.7.1 接口的基本介绍
接口是对抽象类的极致抽象

加一点:在接口中abstract、public关键字都可以省略 。
允许添加的方法有三种:抽象、默认、静态
//写属性
public int n1 = 10;
//写方法
//在接口中,抽象方法,可以省略abstract关键字
public void hi();
//在jdk8后,可以有默认实现方法,需要使用default关键字修饰
default public void ok() {
System.out.println("ok ...");
}
//在jdk8后, 可以有静态方法
public static void cry() {
System.out.println("cry ....");
}
5.7.2 接口的注意事项和细节

- 接口中,方法是默认public和abstract的,所以可以不用显示修饰出来,但记住不能加方法体。

-
Java中类是单继承的,但是接口是可以实现多个。
-
属性是final static类型,int n1 = 10; //等价 public static final int n1 = 10;
5.7.3 课堂练习
对抽象的个人理解:
其实可以把接口理解为抽象且有约束的父类,继承关系中的特殊例子,抽象体现在其父类(接口中)方法全部为抽象方法,约束体现在方法均被public abstract修饰符修饰、属性被public static final修饰。

5.7.4 接口和继承的区别
//继承
//小结: 当子类继承了父类,就自动的拥有父类的功能
// 如果子类需要扩展功能,可以通过实现接口的方式扩展.
// 可以理解 实现接口 是 对java 单继承机制的一种补充.

代码解耦:接口规范性+动态绑定机制
5.7.5 接口的多态特性

-
接口的多态参数:举个例子,很重要,帮助理解接口多态和继承多态
public class InterfacePolyParameter { public static void main(String[] args) { //接口的多态体现 //接口类型的变量 if01 可以指向 实现了IF接口类的对象实例 IF if01 = new Monster(); if01 = new Car(); //继承体现的多态 //父类类型的变量 a 可以指向 继承AAA的子类的对象实例 AAA a = new BBB(); a = new CCC(); } } // 接口多态 interface IF {} class Monster implements IF{} class Car implements IF{} // 继承多态 class AAA {} class BBB extends AAA {} class CCC extends AAA {} -
接口的多态数组:动态绑定机制,接口数组能够根据运行类型自动地调用相关类的方法
public class InterfacePolyArr {
public static void main(String[] args) {
//多态数组 -> 接口类型数组
Usb[] usbs = new Usb[2];
usbs[0] = new Phone_();
usbs[1] = new Camera_();
/*
给Usb数组中,存放 Phone 和 相机对象,Phone类还有一个特有的方法call(),
请遍历Usb数组,如果是Phone对象,除了调用Usb 接口定义的方法外,
还需要调用Phone 特有方法 call
*/
for(int i = 0; i < usbs.length; i++) {
usbs[i].work();//动态绑定..根据当前实现接口的对象调用所属的work方法
//和前面一样,我们仍然需要进行类型的向下转型
if(usbs[i] instanceof Phone_) {//判断他的运行类型是 Phone_
((Phone_) usbs[i]).call();
}
}
}
}
interface Usb{
void work();
}
class Phone_ implements Usb {
public void call() {
System.out.println("手机可以打电话...");
}
@Override
public void work() {
System.out.println("手机工作中...");
}
}
class Camera_ implements Usb {
@Override
public void work() {
System.out.println("相机工作中...");
}
}
- 接口的多态传递现象:其实就是接口继承接口
public class InterfacePolyPass {
public static void main(String[] args) {
//接口类型的变量可以指向,实现了该接口的类的对象实例
IG ig = new Teacher();
//如果IG 继承了 IH 接口,而Teacher 类实现了 IG接口
//那么,实际上就相当于 Teacher 类也实现了 IH接口.
//这就是所谓的 接口多态传递现象.
IH ih = new Teacher();
}
}
interface IH {}
interface IG extends IH {}
class Teacher implements IG {}
5.7.6 课堂练习

x的指向不明确,父类与接口是同优先级的
//System.out.println(x); //错误,原因不明确x
//可以明确的指定x
//访问接口的 x 就使用 A.x
//访问父类的 x 就使用 super.x
System.out.println(A.x + " " + super.x);
5.7.7 类的小结
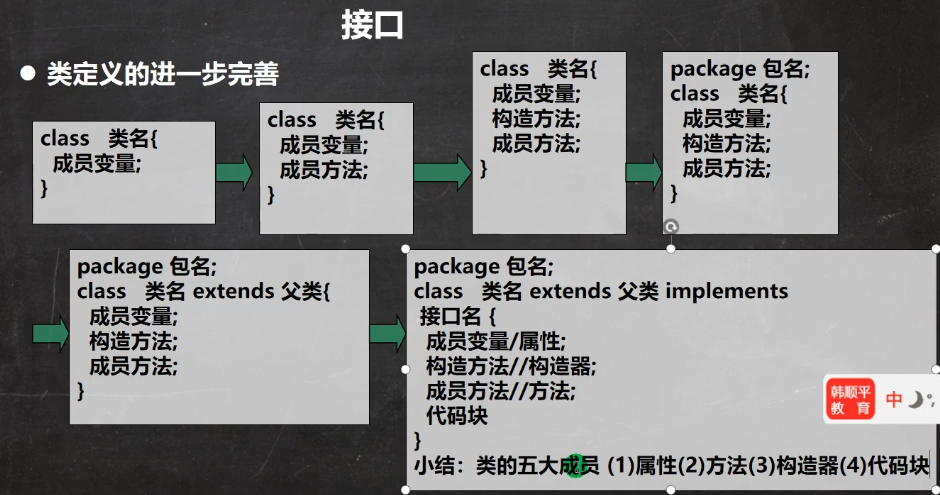
类的五大成员还差内部类。
5.8 内部类

5.8.1 四种内部类

注解:第一点首先根据内部类所在位置进行一个大致判断,是在字段位置(成员位置)上还是局部位置(如方法内)位置上。
匿名内部类很重要!!
5.8.2 局部内部类


示例代码:
public class LocalInnerClass {//
public static void main(String[] args) {
//演示一遍
Outer02 outer02 = new Outer02();
outer02.m1();
System.out.println("outer02的hashcode=" + outer02);
}
}
class Outer02 {//外部类
private int n1 = 100;
private void m2() {
System.out.println("Outer02 m2()");
}//私有方法
public void m1() {//方法
//1.局部内部类是定义在外部类的局部位置,通常在方法
//3.不能添加访问修饰符,但是可以使用final 修饰
//4.作用域 : 仅仅在定义它的方法或代码块中
final class Inner02 {//局部内部类(本质仍然是一个类)
//2.可以直接访问外部类的所有成员,包含私有的
private int n1 = 800;
public void f1() {
//5. 局部内部类可以直接访问外部类的成员,比如下面 外部类n1 和 m2()
//7. 如果外部类和局部内部类的成员重名时,默认遵循就近原则,如果想访问外部类的成员,
// 使用 外部类名.this.成员)去访问
// 老韩解读 Outer02.this 本质就是外部类的对象, 即哪个对象调用了m1, Outer02.this就是哪个对象
System.out.println("n1=" + n1 + " 外部类的n1=" + Outer02.this.n1);
System.out.println("Outer02.this hashcode=" + Outer02.this);
m2();
}
}
//6. 外部类在方法中,可以创建Inner02对象,然后调用方法即可
Inner02 inner02 = new Inner02();
inner02.f1();
}
}
注意事项:
-
因为局部内部类是在局部位置定义的,可以当做一个局部变量,因此不能用一些访问限制符进行修饰。但能用final修饰。
-
内部类和外部类的成员变量重名后,遵循就近原则,(1)访问内部类该成员直接用、(2)访问外部类用 外部类名.this.成员
5.8.3 匿名内部类*

注释:匿名内部类的位置与局部内部类一样,但匿名类没有类名。
/**
* 演示匿名内部类的使用
*/
public class AnonymousInnerClass {
public static void main(String[] args) {
Outer04 outer04 = new Outer04();
outer04.method();
}
}
class Outer04 { //外部类
private int n1 = 10;//属性
public void method() {//方法
//基于接口的匿名内部类
//老韩解读
//1. 需求: 想使用IA接口,并创建对象
//2. 传统方式,是写一个类,实现该接口,并创建对象
//3. 老韩需求是 Tiger/Dog 类只是使用一次,后面再不使用
//4. 可以使用匿名内部类来简化开发
//5. tiger的编译类型 ? IA
//6. tiger的运行类型 ? 就是匿名内部类 Outer04$1
/*
我们看底层 会分配 类名 Outer04$1
class Outer04$1 implements IA {
@Override
public void cry() {
System.out.println("老虎叫唤...");
}
}
*/
//7. jdk底层在创建匿名内部类 Outer04$1,立即马上就创建了 Outer04$1实例,并且把地址
// 返回给 tiger
//8. 匿名内部类使用一次,就不能再使用,但一次实例化后的对象,可以使用多次
IA tiger = new IA() { // 一个匿名类,编译类型:IA,运行类型:外部类$数字
@Override
public void cry() {
System.out.println("老虎叫唤...");
}
};
System.out.println("tiger的运行类型=" + tiger.getClass()); // Outer04$1
tiger.cry();
tiger.cry();
tiger.cry();
// IA tiger = new Tiger(); // 老方法
// tiger.cry();
//演示基于类的匿名内部类
//分析
//1. father编译类型 Father
//2. father运行类型 Outer04$2
//3. 底层会创建匿名内部类
/*
class Outer04$2 extends Father{
@Override
public void test() {
System.out.println("匿名内部类重写了test方法");
}
}
*/
//4. 同时也直接返回了 匿名内部类 Outer04$2的对象
//5. 注意("jack") 参数列表会传递给 构造器
Father father = new Father("jack"){
@Override
public void test() {
System.out.println("匿名内部类重写了test方法");
}
};
System.out.println("father对象的运行类型=" + father.getClass());//Outer04$2
father.test();
//基于抽象类的匿名内部类
//需要实现全部的抽象方法
Animal animal = new Animal(){
@Override
void eat() {
System.out.println("小狗吃骨头...");
}
};
animal.eat();
}
}
interface IA {//接口
public void cry();
}
// 老方法
//class Tiger implements IA {
//
// @Override
// public void cry() {
// System.out.println("老虎叫唤...");
// }
//}
//class Dog implements IA{
// @Override
// public void cry() {
// System.out.println("小狗汪汪...");
// }
//}
class Father {//类
public Father(String name) {//构造器
System.out.println("接收到name=" + name);
}
public void test() {//方法
}
}
abstract class Animal { //抽象类
abstract void eat();
}
注释:
-
匿名类可以分为三种:基于接口的匿名内部类、基于类的匿名内部类(可能会传参数列表进行构造)、基于抽象类的匿名内部类
-
匿名类的底层:JDK会创建一个类 外部类名称$数字,数字按照匿名类顺序从1开始,下面举例:
实现IA接口的匿名类,运行类型为Outer04$1,编译类型为IA
// 我们看底层 会分配 类名 Outer04$1
class Outer04$1 implements IA {
@Override
public void cry() {
System.out.println("老虎叫唤...");
}
}
-
匿名内部类创建一次,就不能再使用,但其一次实例化创建出的对象还存在,可以被使用多次。
// 匿名类只创建一次 IA tiger = new IA() { // 一个匿名类,编译类型:IA,运行类型:外部类$数字 @Override public void cry() { System.out.println("老虎叫唤..."); } }; tiger.cry(); tiger.cry(); tiger.cry(); // 三次tiger.cry()输出都可以 -
基于类的匿名内部类(可能会传参数列表进行构造):创建时,不要忘了方法体
Father father = new Father("jack"){ // 方法体 @Override public void test() { System.out.println("匿名内部类重写了test方法"); } }; Father father = new Father("jack"); // 没有方法体,就是类的实例化
注释:需要明确:匿名内部类既是一个类的定义,同时也是本身也是一个对象,所以才有上图两种方法的调用。


public class AnonymousInnerClassDetail {
public static void main(String[] args) {
Outer05 outer05 = new Outer05();
outer05.f1();
//外部其他类---不能访问----->匿名内部类
System.out.println("main outer05 hashcode=" + outer05);
}
}
class Outer05 {
private int n1 = 99;
public void f1() {
//创建一个基于类的匿名内部类
//不能添加访问修饰符,因为它的地位就是一个局部变量
//作用域 : 仅仅在定义它的方法或代码块中
Person p = new Person(){
private int n1 = 88;
@Override
public void hi() {
//可以直接访问外部类的所有成员,包含私有的
//如果外部类和匿名内部类的成员重名时,匿名内部类访问的话,
//默认遵循就近原则,如果想访问外部类的成员,则可以使用 (外部类名.this.成员)去访问
System.out.println("匿名内部类重写了 hi方法 n1=" + n1 +
" 外部内的n1=" + Outer05.this.n1 );
//Outer05.this 就是调用 f1的 对象
System.out.println("Outer05.this hashcode=" + Outer05.this);
}
};
p.hi();//动态绑定, 运行类型是 Outer05$1
//也可以直接调用, 匿名内部类本身也是返回对象
// class 匿名内部类 extends Person {}
// new Person(){
// @Override
// public void hi() {
// System.out.println("匿名内部类重写了 hi方法,哈哈...");
// }
// @Override
// public void ok(String str) {
// super.ok(str);
// }
// }.ok("jack");
}
}
class Person {//类
public void hi() {
System.out.println("Person hi()");
}
public void ok(String str) {
System.out.println("Person ok() " + str);
}
}
//抽象类/接口...
最佳实践:

public class InnerClassExercise01 {
public static void main(String[] args) {
//当做实参直接传递,简洁高效
f1(new IL() { //因为匿名类可以当做一个对象
@Override
public void show() {
System.out.println("这是一副名画~~...");
}
});
//传统方法
f1(new Picture());
}
//静态方法,形参是接口类型
public static void f1(IL il) {
il.show();
}
}
//接口
interface IL {
void show();
}
//类->实现IL => 编程领域 (硬编码)
class Picture implements IL {
@Override
public void show() {
System.out.println("这是一副名画XX...");
}
}
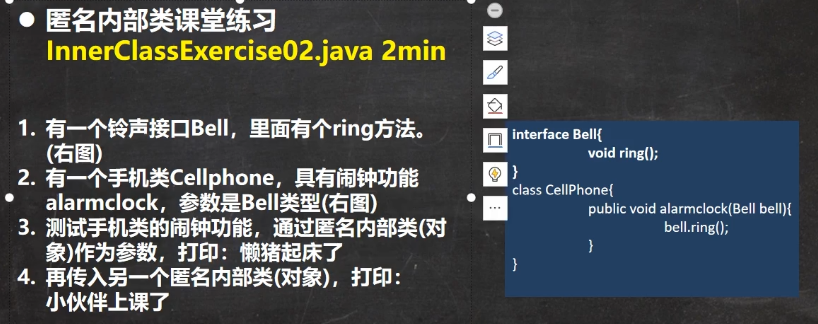
public class InnerClassExercise02 {
public static void main(String[] args) {
new CellPhone().alarmClock(new Bell() {//class com.hspedu.innerclass.InnerClassExercise02$1
@Override
public void ring() {
System.out.println("懒猪起床了!!!");
}
});
CellPhone cellPhone = new CellPhone();
cellPhone.alarmClock(new Bell() {//class com.hspedu.innerclass.InnerClassExercise02$2
@Override
public void ring() {
System.out.println("小伙伴上课了!!!");
}
});
}
}
interface Bell {
void ring();
}
class CellPhone {
public void alarmClock (Bell bell) {//形参是Bell接口类型
System.out.println(bell.getClass());
bell.ring();//动态绑定
}
}
5.8.4 成员内部类


public class MemberInnerClass01 {
public static void main(String[] args) {
Outer08 outer08 = new Outer08();
outer08.t1();
//外部其他类,使用成员内部类的两种方式
//老韩解读
// 第一种方式
// outer08.new Inner08(); 相当于把 new Inner08()当做是outer08成员
// 这就是一个语法,不要特别的纠结.
Outer08.Inner08 inner08 = outer08.new Inner08();
inner08.say();
// 第二方式 在外部类中,编写一个方法,可以返回 Inner08对象
Outer08.Inner08 inner08Instance = outer08.getInner08Instance();
inner08Instance.say();
}
}
class Outer08 { //外部类
private int n1 = 10;
public String name = "张三";
private void hi() {
System.out.println("hi()方法...");
}
//1.注意: 成员内部类,是定义在外部内的成员位置上
//2.可以添加任意访问修饰符(public、protected 、默认、private),因为它的地位就是一个成员
public class Inner08 {//成员内部类
private double sal = 99.8;
private int n1 = 66;
public void say() {
//可以直接访问外部类的所有成员,包含私有的
//如果成员内部类的成员和外部类的成员重名,会遵守就近原则.
//,可以通过 外部类名.this.属性 来访问外部类的成员
System.out.println("n1 = " + n1 + " name = " + name + " 外部类的n1=" + Outer08.this.n1);
hi();
}
}
//方法,返回一个Inner08实例
public Inner08 getInner08Instance(){
return new Inner08();
}
//写方法
public void t1() {
//外部类想要使用成员内部类
//首先创建成员内部类的对象,然后使用相关的方法
Inner08 inner08 = new Inner08();
inner08.say();
System.out.println(inner08.sal);
}
}
注释:
-
成员内部类,理解位置,其实就是与属性字段、方法平级。它的地位就是一个普通成员,所以可以使用访问修饰符进行修饰。
-
外部其他类使用内部成员类的两种方式,其中新建一个成员内部类语法很怪,Outer08.Inner08 inner08 = outer08.new Inner08();
-
重名还是遵循就近原则,可以通过 外部类名.this.属性 来访问外部类的成员。
5.8.5 静态内部类

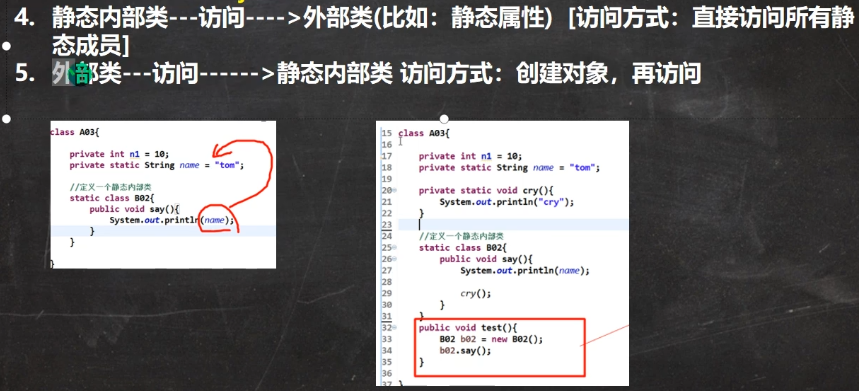


注释:其实就是成员内部类用static修饰了。
因此,静态内部类只能访问外部类所有静态方法和属性。
因为静态内部类只能访问静态属性和方法,因此当静态内部类发生重名的时候想要访问外部类的属性时,直接使用 外部类名.成员 即可。
public class StaticInnerClass01 {
public static void main(String[] args) {
Outer10 outer10 = new Outer10();
outer10.m1();
//外部其他类 使用静态内部类
//方式1
//因为静态内部类,是可以通过类名直接访问(前提是满足访问权限)
Outer10.Inner10 inner10 = new Outer10.Inner10();
inner10.say();
//方式2
//编写一个方法,可以返回静态内部类的对象实例.
Outer10.Inner10 inner101 = outer10.getInner10();
System.out.println("============");
inner101.say();
Outer10.Inner10 inner10_ = Outer10.getInner10_();
System.out.println("************");
inner10_.say();
}
}
class Outer10 { //外部类
private int n1 = 10;
private static String name = "张三";
private static void cry() {}
//Inner10就是静态内部类
//1. 放在外部类的成员位置
//2. 使用static 修饰
//3. 可以直接访问外部类的所有静态成员,包含私有的,但不能直接访问非静态成员
//4. 可以添加任意访问修饰符(public、protected 、默认、private),因为它的地位就是一个成员
//5. 作用域 :同其他的成员,为整个类体
static class Inner10 {
private static String name = "韩顺平教育";
public void say() {
//如果外部类和静态内部类的成员重名时,静态内部类访问的时,
//默认遵循就近原则,如果想访问外部类的成员,则可以使用 (外部类名.成员)
System.out.println(name + " 外部类name= " + Outer10.name);
cry();
}
}
public void m1() { //外部类---访问------>静态内部类 访问方式:创建对象,再访问
Inner10 inner10 = new Inner10();
inner10.say();
}
public Inner10 getInner10() {
return new Inner10();
}
public static Inner10 getInner10_() {
return new Inner10();
}
}

第六章 异常(Exception)

捕获异常,避免程序因异常而中断,保证程序继续执行下去!
6.1 异常体系图
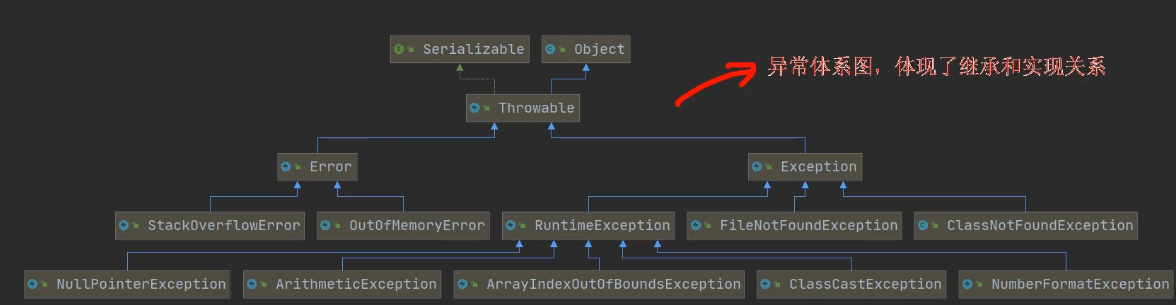
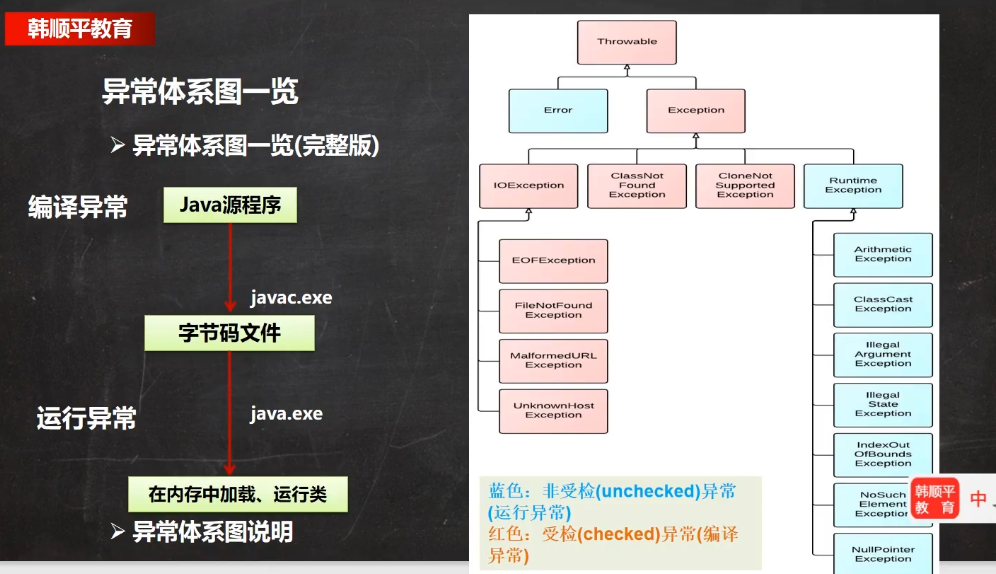
在Exception里面,如果不是在RuntimeException下面,那么就是编译时异常。

6.2 五大运行时异常
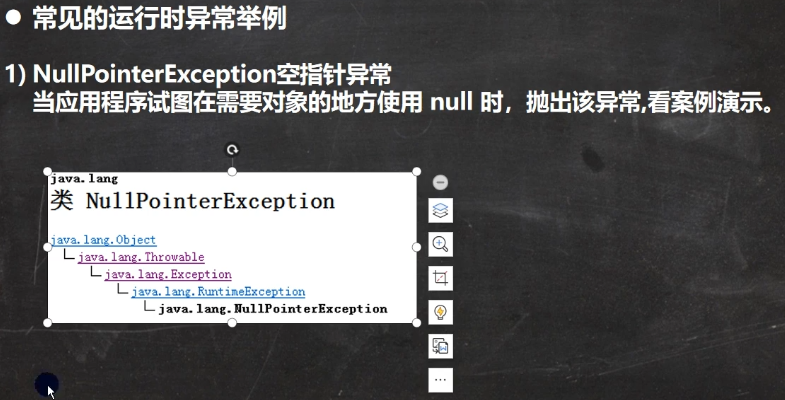




6.3 编译异常

6.4 异常处理

- try-catch:

- throws:
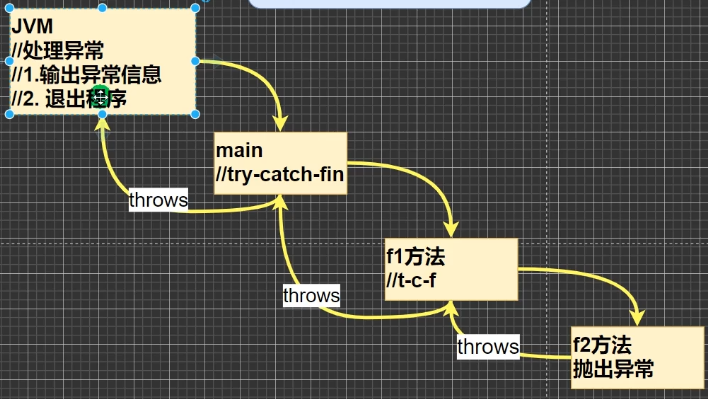
throws处理机制,其实是二选一,当前方法可以选择用try-catch-finally进行处理,也可以throws抛出异常,当最后抛出至JVM底层时,JVM打印异常信息然后就退出程序了
6.4.1 try-catch

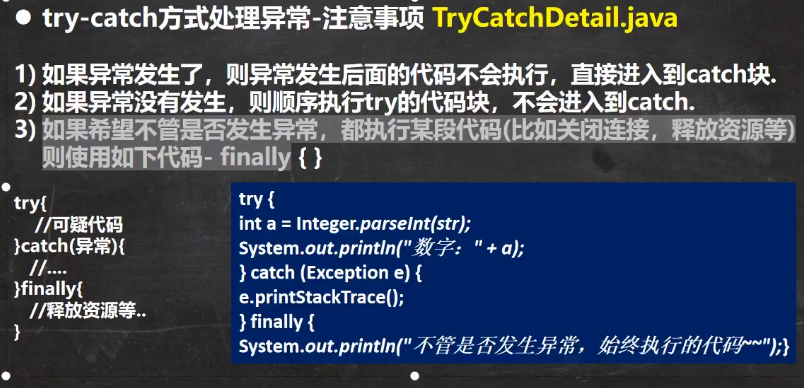
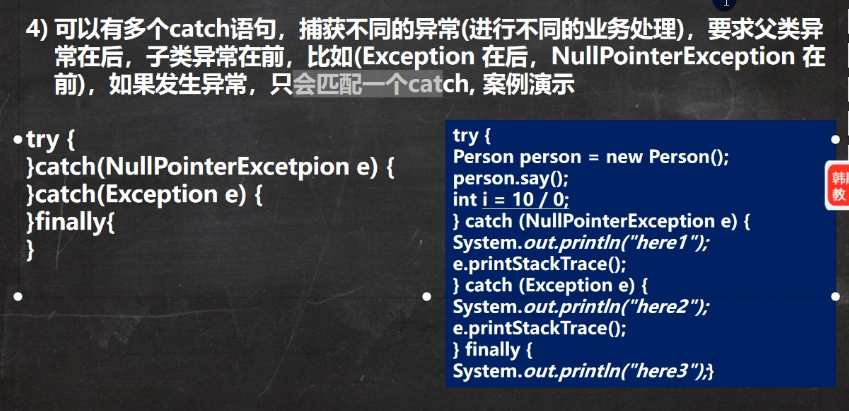

课堂练习:

这道题要好好看!!!因为finally必须执行,所以return3不会返回,返回return4。

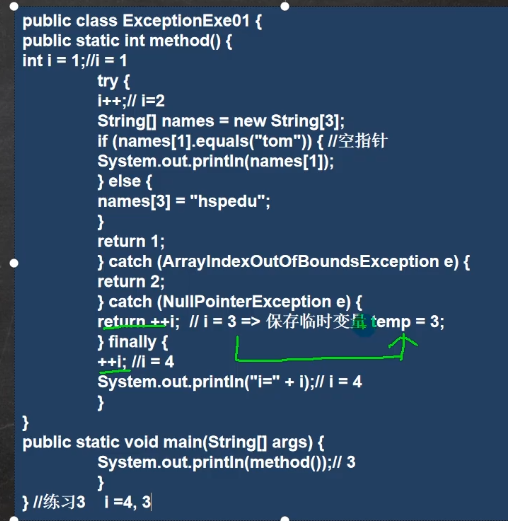
这个题很秒!

最佳实践:
//如果用户输入的不是一个整数,就提示他反复输入,直到输入一个整数为止
//思路
//1. 创建Scanner对象
//2. 使用无限循环,去接收一个输入
//3. 然后将该输入的值,转成一个int
//4. 如果在转换时,抛出异常,说明输入的内容不是一个可以转成int的内容
//5. 如果没有抛出异常,则break 该循环
public class TryCatchExercise04 {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int num = 0;
String inputStr = "";
while (true) {
System.out.println("请输入一个整数:"); //
inputStr = scanner.next();
try {
num = Integer.parseInt(inputStr); //这里是可能抛出异常
break;
} catch (NumberFormatException e) {// 出现异常后
System.out.println("你输入的不是一个整数:");
}
}
System.out.println("你输入的值是=" + num);
}
}
6.4.2 throws

- 对第二点的理解,可以参考下面代码中 throws 抛出:
public class Throws01 {
public static void main(String[] args) {
}
// 也可以只用一个Exception
public void f2() throws FileNotFoundException,NullPointerException,ArithmeticException {
//创建了一个文件流对象
//老韩解读:
//1. 这里的异常是一个FileNotFoundException 编译异常
//2. 使用前面讲过的 try-catch-finally
//3. 使用throws ,抛出异常, 让调用f2方法的调用者(方法)处理
//4. throws 后面的异常类型可以是方法中产生的异常类型,也可以是它的父类
//5. throws 关键字后也可以是 异常列表, 即可以抛出多个异常
FileInputStream fis = new FileInputStream("d://aa.txt");
}
}

//1.对于编译异常,程序中必须处理,比如 try-catch 或者 throws
//2.对于运行时异常,程序中如果没有处理,默认就是throws的方式处理
class Father { //父类
public void method() throws RuntimeException {
}
}
class Son extends Father {//子类
//3. 子类重写父类的方法时,对抛出异常的规定:子类重写的方法,
// 所抛出的异常类型要么和父类抛出的异常一致,要么为父类抛出的异常类型的子类型
//4. 在throws 过程中,如果有方法 try-catch , 就相当于处理异常,就可以不必throws
@Override
public void method() throws ArithmeticException {
}
}
运行异常有默认处理机制(throws),编译异常必须立马解决!
// 编译处理,必须立马解决
public static void f1() throws FileNotFoundException {// 编译异常,必须处理
//这里大家思考问题 调用f3() 报错
//老韩解读
//1. 因为f3() 方法抛出的是一个编译异常
//2. 即这时,就要f1() 必须处理这个编译异常
//3. 在f1() 中,要么 try-catch-finally ,或者继续throws 这个编译异常
f3(); // 抛出异常
}
public static void f3() throws FileNotFoundException {
FileInputStream fis = new FileInputStream("d://aa.txt");
}
// 运行异常,有默认处理机制,可以不用显示throws处理
public static void f4() {
//老韩解读:
//1. 在f4()中调用方法f5() 是OK
//2. 原因是f5() 抛出的是运行异常
//3. 而java中,并不要求程序员显示处理,因为有默认处理机制
f5();
}
public static void f5() throws ArithmeticException {
}
6.5 自定义异常

public class CustomException {
public static void main(String[] args) /*throws AgeException*/ {
int age = 180;
//要求范围在 18 – 120 之间,否则抛出一个自定义异常
if(!(age >= 18 && age <= 120)) {
//这里我们可以通过构造器,设置信息
throw new AgeException("年龄需要在 18~120之间");
}
System.out.println("你的年龄范围正确.");
}
}
//自定义一个异常
//老韩解读
//1. 一般情况下,我们自定义异常是继承 RuntimeException
//2. 即把自定义异常做成 运行时异常,好处时,我们可以使用默认的处理机制
//3. 即比较方便
class AgeException extends RuntimeException {
public AgeException(String message) {//构造器
super(message);
}
}
6.6 throw和throws对比


输出了“进入方法A”,然后手动throw一个异常,此时发生已经发生异常,进入finally输出,主方法捕捉到异常,执行catch语句,打印e.getMessage(),其内容就是throw的内容:”制造异常"。然后就是B方法的执行..................
6.7 课后作业
-
/* 编写应用程序EcmDef.java,接收命令行的两个参数(整数),计算两数相除。 计算两个数相除,要求使用方法 cal(int n1, int n2) 对数据格式不正确(NumberFormatException)、缺少命令行参数(ArrayIndexOutOfBoundsException)、除0 进行异常处理(ArithmeticException)。 */ public class Homework01 { public static void main(String[] args) { try { //先验证输入的参数的个数是否正确 两个参数 if(args.length != 2) { throw new ArrayIndexOutOfBoundsException("参数个数不对"); } //先把接收到的参数,转成整数 int n1 = Integer.parseInt(args[0]); int n2 = Integer.parseInt(args[1]); double res = cal(n1, n2);//该方法可能抛出ArithmeticException System.out.println("计算结果是=" + res); } catch (ArrayIndexOutOfBoundsException e) { System.out.println(e.getMessage()); } catch (NumberFormatException e) { System.out.println("参数格式不正确,需要输出整数"); } catch (ArithmeticException e) { System.out.println("出现了除0的异常"); } } //编写cal方法,就是两个数的商 public static double cal(int n1, int n2) { return n1 / n2; } } -

-

func捕获到异常后,就不执行try代码块中的其余剩下部分了,转而执行catch。因为成功捕获异常,输出D的语句会照常执行。

第七章 常用类
小红旗的笔记有,其余类看PDF
7.1 包装类
八种基本数据类型!

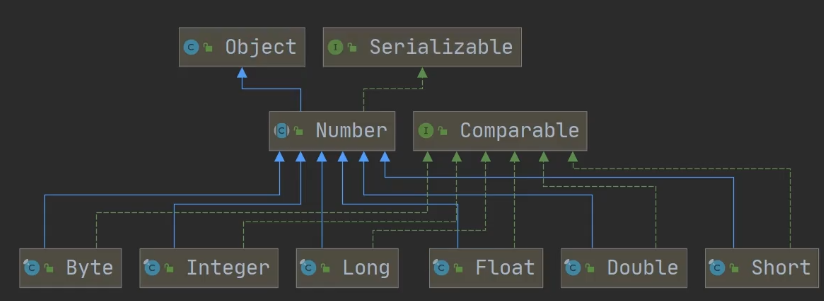
7.1.1 装箱与拆箱

public class Integer01 {
public static void main(String[] args) {
//演示int <--> Integer 的装箱和拆箱
//jdk5前是手动装箱和拆箱
//手动装箱 int->Integer
int n1 = 100;
Integer integer = new Integer(n1);//第一种方式
Integer integer1 = Integer.valueOf(n1);//第二种方式
//手动拆箱
//Integer -> int
int i = integer.intValue();
//jdk5后,就可以自动装箱和自动拆箱
int n2 = 200;
//自动装箱 int->Integer
Integer integer2 = n2; //这里是Integer包装器类等于int类型,自动装箱,底层使用的是 Integer.valueOf(n2),
//自动拆箱 Integer->int
int n3 = integer2; //底层仍然使用的是 intValue()方法
}
}
7.1.2 课堂练习

三元运算符那里当做一个整体,会向Double精度靠,输出1.0。而下面的因为是if-else语句独立分开的,所以输出1,而不是1.0。
7.1.3 包装器方法
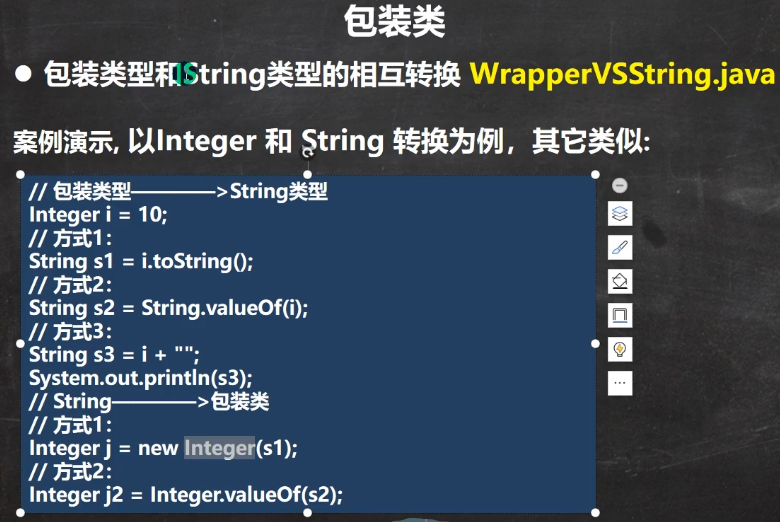
//包装类(Integer)->String
Integer i = 100;//自动装箱
//方式1
String str1 = i + "";
//方式2
String str2 = i.toString();
//方式3
String str3 = String.valueOf(i);
//String -> 包装类(Integer)
String str4 = "12345";
Integer i2 = Integer.parseInt(str4);//使用到自动装箱
Integer i3 = new Integer(str4);//构造器

7.1.4 Integer创建机制
在范围里面(-128~127)是直接返回一个已存在的缓存对象,否则是返回新建的Integer对象。

128那里,均为新建的Integer对象。
7.1.5 Integer面试题

注释:
==判断两个对象是否相等,但在比较基本数据类型时,是比较值是否相等;因此,1和2是new的对象,自然不可能是同一个对象,而6和7是值的比较。
7.2 String类*
7.2.1 基本介绍
不适合大量修改的情况下,适合有多个引用的情况下,如配置文件。

注:实现序列化之后,可以持久化到本地或者进行网络传输,数据序列化就是变成二进制。

注:String底层还是数组,且是一个final类型的数组value,一旦赋值之后,其String的域——value数组指向的地址是不可以改变的(数组是引用类型)。字符串指向的首字符所在的地址。(JDK8是char类型,JDK11是byte类型,但一定是final类型数组)
7.2.2 创建String的两种方式并剖析

注解:
- 方式一:这种方式是直接赋值,首先查看常量池中是否已经存在这样一个常量,有就直接引用,没有就创建一个新的final类型常量。
- 方式二:s2指向堆中的value数组,而value数组指向常量池中的数据,value数组的指向是无法改变的。但s2可以改变指向。
7.2.3 课堂测试

String的equals方法:比较内容(是否为同一对象,是否字符串挨个字符相同)
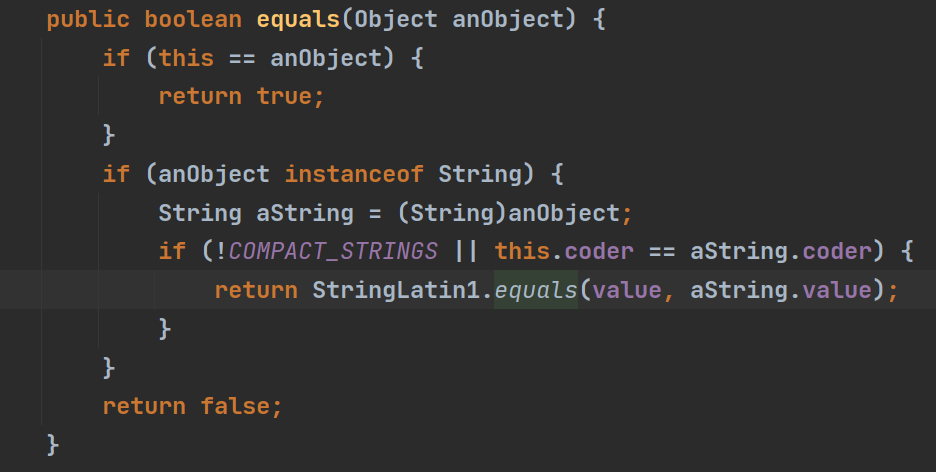

注:最后一个为F,记住intern始终指向常量池中的对象就行。
-

-
这个题要搞清楚!!P468
7.2.4 String特性

在常量池中已创建的常量对象是无法改变的,s1只是重新指向了常量池中另一个对象。


补充一下:c并不是直接指向的常量池中的"helloabc",而是堆中的一个对象。(可以自己跑一下,jdk版本不一样源码不一样)
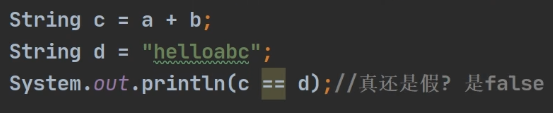

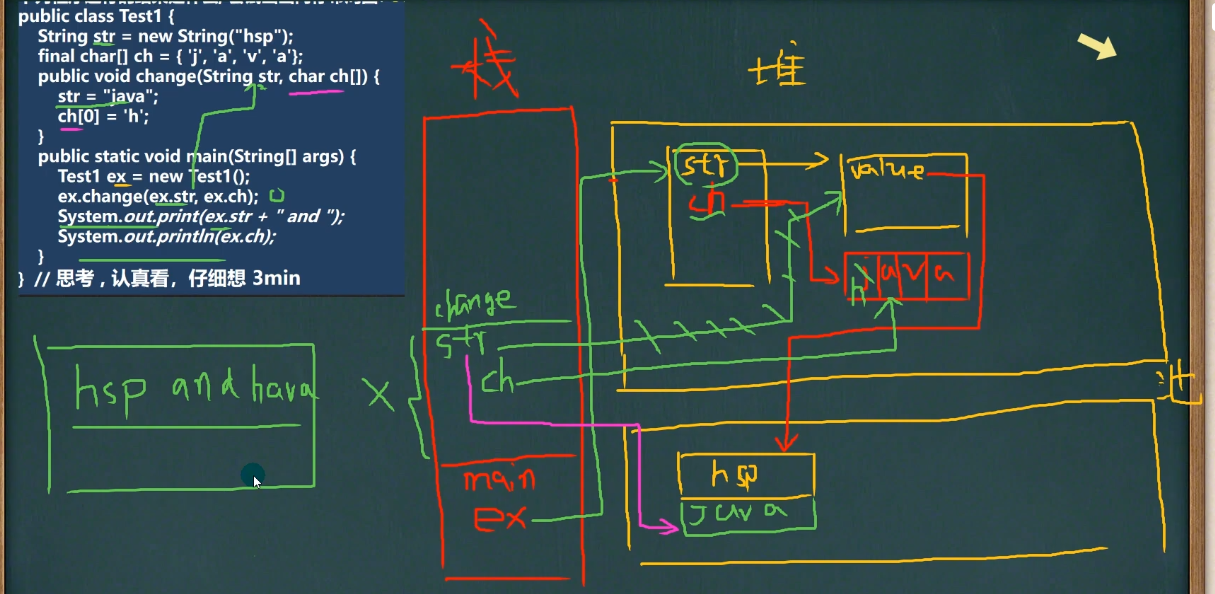
这道题很综合,面试题!
分析完毕后,也能发现在局部方法中,方法栈有临时变量性,数组的指向是地址,对其进行修改能够影响值的真实变化。
7.3 StringBuffer类(线程安全)
7.3.1 基本介绍和结构剖析
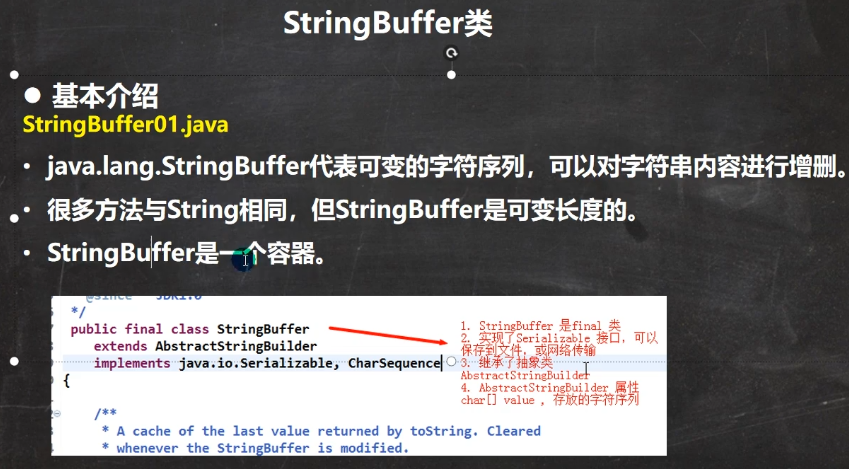
String是final类型。
//老韩解读
//1. StringBuffer 的直接父类 是 AbstractStringBuilder
//2. StringBuffer 实现了 Serializable, 即StringBuffer的对象可以串行化
//3. 在父类中 AbstractStringBuilder 有属性 char[] value,不是final(底层还是数组)
// 该 value 数组存放 字符串内容,引出存放在堆中的,而不是像String一样存放在常量池
//4. StringBuffer 是一个 final类,不能被继承
//5. 因为StringBuffer 字符内容是存在 char[] value, 所有在变化(增加/删除)
// 不用每次都更换地址(即不是每次创建新对象), 所以效率高于 String
StringBuffer stringBuffer = new StringBuffer("hello");

2)这里说的不用每次更新地址,主要是指String中,str对象指向堆空间中的value的地址不能改变,value则是存放的指向常量池中某个常量的地址,但是如果改变值,那么value指向常量池中的地址就会进行重新指向(因为String是存放final类型的常量值,没有就新建一个常量值存放在常量池中)。而StringBuffer有一个类似于自动维护缓冲区大小的机制,是一个存放字符串变量的容器(底层是char数组),因此不用每次改变值的时候都需要重新指向。
7.3.2 StringBuffer构造器和与String转换
- 构造器
//构造器的使用
//老韩解读
//1. 创建一个 大小为 16的 char[] ,用于存放字符内容
StringBuffer stringBuffer = new StringBuffer();
//2 通过构造器指定 char[] 大小
StringBuffer stringBuffer1 = new StringBuffer(100);
//3. 通过给一个String 创建 StringBuffer, char[] 大小就是 str.length() + 16
StringBuffer hello = new StringBuffer("hello");
-
与String的转换
StringBuffer与String的相互转换:
//看 String——>StringBuffer String str = "hello tom"; //方式1 使用构造器 //注意: 返回的才是StringBuffer对象,对str 本身没有影响 StringBuffer stringBuffer = new StringBuffer(str); //方式2 使用的是append方法 StringBuffer stringBuffer1 = new StringBuffer(); stringBuffer1 = stringBuffer1.append(str); //看看 StringBuffer ->String StringBuffer stringBuffer3 = new StringBuffer("韩顺平教育"); //方式1 使用StringBuffer提供的 toString方法 String s = stringBuffer3.toString(); //方式2: 使用构造器来搞定 String s1 = new String(stringBuffer3);
7.3.3 StringBuffer常用方法

StringBuffer s = new StringBuffer("hello");
//增,append方法是在尾部增加
s.append(',');// "hello,"
s.append("张三丰");//"hello,张三丰"
s.append("赵敏").append(100).append(true).append(10.5);//"hello,张三丰赵敏100true10.5"
System.out.println(s);//"hello,张三丰赵敏100true10.5"
//删
/*
* 删除索引为>=start && <end 处的字符
* 解读: 删除 11~14的字符 [11, 14)
*/
s.delete(11, 14);
System.out.println(s);//"hello,张三丰赵敏true10.5"
//改
//老韩解读,使用 周芷若 替换 索引9-11的字符 [9,11)
s.replace(9, 11, "周芷若");
System.out.println(s);//"hello,张三丰周芷若true10.5"
//查找指定的子串在字符串第一次出现的索引,如果找不到返回-1
int indexOf = s.indexOf("张三丰");
System.out.println(indexOf);//6
//插
//老韩解读,在索引为9的位置插入 "赵敏",原来索引为9的内容自动后移
s.insert(9, "赵敏");
System.out.println(s);//"hello,张三丰赵敏周芷若true10.5"
//长度
System.out.println(s.length());//22
System.out.println(s);
7.3.4 课堂练习
-

注释:
- str此时是null对象,追进源码发现,在append方法底层实现中,对null的处理是处理出一个存放 ‘ n ’、‘ u ’、‘ l ’、‘ l ’ 的数组:
- 而在new StringBuffer()构造器方法中,传入null,因为null.length()非法,会报空指针异常
-

String price = "8123564.59"; StringBuffer sb = new StringBuffer(price); //先完成一个最简单的实现123,564.59 //找到小数点的索引,然后在该位置的前3位,插入,即可 // int i = sb.lastIndexOf("."); // sb = sb.insert(i - 3, ","); //上面的两步需要做一个循环处理,才是正确的 for (int i = sb.lastIndexOf(".") - 3; i > 0; i -= 3) { sb = sb.insert(i, ","); } System.out.println(sb);//8,123,564.59
7.4 StringBuilder类


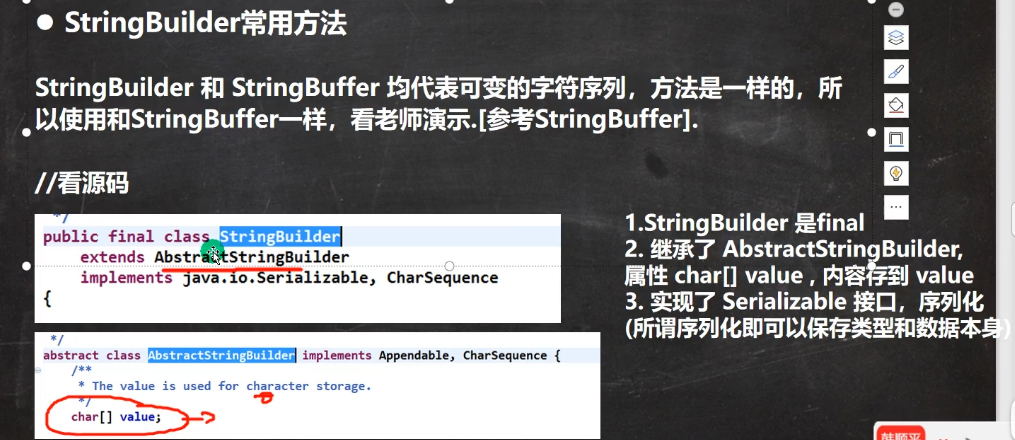
//老韩解读
//1. StringBuilder 继承 AbstractStringBuilder 类
//2. 实现了 Serializable ,说明StringBuilder对象是可以串行化(对象可以网络传输,可以保存到文件)
//3. StringBuilder 是final类, 不能被继承
//4. StringBuilder 对象字符序列仍然是存放在其父类 AbstractStringBuilder的 char[] value;
// 因此,字符序列是堆中
//5. StringBuilder 的方法,没有做互斥的处理,即没有synchronized 关键字,因此在单线程的情况下使用
// StringBuilder
StringBuilder stringBuilder = new StringBuilder();
7.5 String、StringBuffer和StringBuilder的比较

2):String复用率高:因为String是final字符串,字符串常量存放在常量池中,不必再新建一个字符串常量,而是直接指向这个已经创建好了的字符串,这既是优点,又具有其缺点,那就是每当改变成为新字符串的时候,就要在常量池新创建字符串常量,会增大开销。
效率对比:StringBuilder > StringBuffer > String
long startTime = 0L;
long endTime = 0L;
// *************************************************************
StringBuffer buffer = new StringBuffer("");
startTime = System.currentTimeMillis();
for (int i = 0; i < 80000; i++) {//StringBuffer 拼接 20000次
buffer.append(String.valueOf(i));
}
endTime = System.currentTimeMillis();
System.out.println("StringBuffer的执行时间:" + (endTime - startTime));
// *************************************************************
StringBuilder builder = new StringBuilder("");
startTime = System.currentTimeMillis();
for (int i = 0; i < 80000; i++) {//StringBuilder 拼接 20000次
builder.append(String.valueOf(i));
}
endTime = System.currentTimeMillis();
System.out.println("StringBuilder的执行时间:" + (endTime - startTime));
// *************************************************************
String text = "";
startTime = System.currentTimeMillis();
for (int i = 0; i < 80000; i++) {//String 拼接 20000
text = text + i;
}
endTime = System.currentTimeMillis();
System.out.println("String的执行时间:" + (endTime - startTime));
}
/**
StringBuffer的执行时间:16
StringBuilder的执行时间:22
String的执行时间:3432
*/
总结:

大量修改操作情况下,不用String做开发。
第八章 泛型
8.1 引出泛型
public class Generic01 {
public static void main(String[] args) {
//使用传统的方法来解决
ArrayList arrayList = new ArrayList();
arrayList.add(new Dog("旺财", 10));
arrayList.add(new Dog("发财", 1));
arrayList.add(new Dog("小黄", 5));
//假如我们的程序员,不小心,添加了一只猫
arrayList.add(new Cat("招财猫", 8));//没有对数据类型进行约束,能正常进行添加,但是for循环遍历会出错
//遍历
for (Object o : arrayList) {
//向下转型Object ->Dog,此时误添加进去的Cat对象会导致发生错误
Dog dog = (Dog) o;
System.out.println(dog.getName() + "-" + dog.getAge());
}
}
}
/*
请编写程序,在ArrayList 中,添加3个Dog对象
Dog对象含有name 和 age, 并输出name 和 age (要求使用getXxx())
*/

引入泛型来解决数据类型没有被约束的问题:
//使用传统的方法来解决===> 使用泛型
//老韩解读
//1. 当我们 ArrayList<Dog> 表示存放到 ArrayList 集合中的元素是Dog类型 (细节后面说...)
//2. 如果编译器发现添加的类型,不满足要求,就会报错
//3. 在遍历的时候,可以直接取出 Dog 类型而不是 Object
//4. public class ArrayList<E> {} E称为泛型,那么 Dog->E
ArrayList<Dog> arrayList = new ArrayList<Dog>();
arrayList.add(new Dog("旺财", 10));
arrayList.add(new Dog("发财", 1));
arrayList.add(new Dog("小黄", 5));
//假如我们的程序员,不小心,添加了一只猫
//arrayList.add(new Cat("招财猫", 8));//引入泛型后,这里添加非Dog类型的Cat数据,会报错!!!!
System.out.println("===使用泛型====");
for (Dog dog : arrayList) {
System.out.println(dog.getName() + "-" + dog.getAge());
}

8.2 泛型说明
泛型就是一种表示数据类型的数据类型,也就是数据类型的参数化。

4):E就相当于占位符,等待编译器传入数据类型,编译期间就确定了E的数据类型。
public class Generic03 {
public static void main(String[] args) {
//注意,特别强调: E具体的数据类型在定义Person对象的时候指定,即在编译期间,就确定E是什么类型
Person<String> person = new Person<String>("韩顺平教育");
person.show(); //String
/*
你可以这样理解,上面的Person类
class Person {
String s ;//E表示 s的数据类型, 该数据类型在定义Person对象的时候指定,即在编译期间,就确定E是什么类型
public Person(String s) {//E也可以是参数类型
this.s = s;
}
public String f() {//返回类型使用E
return s;
}
}
*/
Person<Integer> person2 = new Person<Integer>(100);
person2.show();//Integer
/*
class Person {
Integer s ;//E表示 s的数据类型, 该数据类型在定义Person对象的时候指定,即在编译期间,就确定E是什么类型
public Person(Integer s) {//E也可以是参数类型
this.s = s;
}
public Integer f() {//返回类型使用E
return s;
}
}
*/
}
}
// 泛型的作用是:可以在类声明时通过一个标识表示类中某个属性的类型,
// 或者是某个方法的返回值的类型,或者是参数类型
class Person<E> {
E s ;//E表示 s的数据类型, 该数据类型在定义Person对象的时候指定,即在编译期间,就确定E是什么类型
public Person(E s) {//E也可以是参数类型
this.s = s;
}
public E f() {//返回类型使用E
return s;
}
public void show() {
System.out.println(s.getClass());//显示s的运行类型
}
}
8.3 泛型的语法和应用实例


package com.hspedu.generic;
import java.util.*;
/**
* @author Wenhao Zou
* @title: Generic01
* @projectName JavaHan
* @description: TODO
* @date 2021/9/1 17:18
*/
public class Generic01 {
public static void main(String[] args) {
// 1. 使用泛型方式给HashSet,放入三个学生对象
HashSet<Student> students = new HashSet<>();
students.add(new Student("jack", 18));
students.add(new Student("tom", 28));
students.add(new Student("mary", 19));
//遍历
for (Student student : students) {
System.out.println(student);
}
// 2. 使用泛型方式给HashMap 放入3个学生对象
//K -> String V->Student
HashMap<String, Student> hm = new HashMap<String, Student>();
/*
public class HashMap<K,V> {}
*/
hm.put("milan", new Student("milan", 38));
hm.put("smith", new Student("smith", 48));
hm.put("hsp", new Student("hsp", 28));
//迭代器遍历
Set<Map.Entry<String, Student>> entries = hm.entrySet();
Iterator<Map.Entry<String, Student>> iterator = entries.iterator();
while (iterator.hasNext()) {
Map.Entry<String, Student> next = iterator.next();
System.out.println(next);
}
}
}
/**
* 创建 3个学生对象
* 放入到HashSet中学生对象, 使用.
* 放入到 HashMap中,要求 Key 是 String name, Value 就是 学生对象
* 使用两种方式遍历
*/
class Student {}
8.4 泛型使用细节

基本数据类型不能作为泛型参数,要使用的话,得用其包装器类型。
public class GenericDetail {
public static void main(String[] args) {
//1.给泛型指向数据类型是,要求是引用类型,不能是基本数据类型
List<Integer> list = new ArrayList<Integer>(); //OK
//List<int> list2 = new ArrayList<int>();//错误
//2. 说明
//因为 E 指定了 A 类型, 构造器传入了 new A()
//在给泛型指定具体类型后,可以传入该类型或者其子类类型
Pig<A> aPig = new Pig<A>(new A());
aPig.f();
Pig<A> aPig2 = new Pig<A>(new B());
aPig2.f();
//3. 泛型的使用形式
ArrayList<Integer> list1 = new ArrayList<Integer>();
List<Integer> list2 = new ArrayList<Integer>();
//在实际开发中,我们往往简写
//编译器会进行类型推断, 老师推荐使用下面写法
ArrayList<Integer> list3 = new ArrayList<>();
List<Integer> list4 = new ArrayList<>();
ArrayList<Pig> pigs = new ArrayList<>();
//4. 如果是这样写 泛型默认是 Object
ArrayList arrayList = new ArrayList();//等价 ArrayList<Object> arrayList = new ArrayList<Object>();
/*
public boolean add(Object e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
*/
Tiger tiger = new Tiger();//泛型默认为Object
/*
class Tiger {//类
Object e;
public Tiger() {}
public Tiger(Object e) {
this.e = e;
}
}
*/
}
}
class Tiger<E> {//类
E e;
public Tiger() {} //默认无参构造器被有参构造器覆盖,要想使用,必须显式声明
public Tiger(E e) {
this.e = e;
}
}
class A {}
class B extends A {}
class Pig<E> {//
E e;
public Pig(E e) {
this.e = e;
}
public void f() {
System.out.println(e.getClass()); //运行类型
}
}
8.5 泛型课堂练习

public class GenericExercise {
public static void main(String[] args) {
ArrayList<Employee> employees = new ArrayList<>();
employees.add(new Employee("Tom", 20000, new Mydate(2001, 11, 11)));
employees.add(new Employee("Jack", 12000, new Mydate(2001, 10, 12)));
employees.add(new Employee("Hsp", 50000, new Mydate(1980, 5, 1)));
System.out.println("employees: " + employees);
System.out.println("对员工进行排序:=================");
employees.sort(new Comparator<Employee>() {
@Override
public int compare(Employee o1, Employee o2) {
if (!(o1 instanceof Employee && o2 instanceof Employee)) {
System.out.println("类型不正确!");
return 0;
} else {
return o1.getBirthday().compareTo(o2.getBirthday());
}
}
});
System.out.println("employees: " + employees);
}
}
class Mydate {
private int year;
private int month;
private int day;
public Mydate(int year, int month, int day) {
this.year = year;
this.month = month;
this.day = day;
}
public int getYear() {
return year;
}
public void setYear(int year) {
this.year = year;
}
public int getMonth() {
return month;
}
public void setMonth(int month) {
this.month = month;
}
public int getDay() {
return day;
}
public void setDay(int day) {
this.day = day;
}
@Override
public String toString() {
return "Mydate{" +
"year=" + year +
", month=" + month +
", day=" + day +
'}';
}
public int compareTo (Mydate o) {
int yearMinus = this.year - o.getYear();
if (yearMinus != 0) {
return yearMinus;
}
//如果年相同,就比较month
int monthMinus = this.month - o.getMonth();
if (monthMinus != 0) {
return monthMinus;
}
//如果年月相同,比较日
return this.day - o.getDay();
}
}
class Employee {
private String name;
private int sal;
private Mydate birthday;
public Employee(String name, int sal, Mydate birthday) {
this.name = name;
this.sal = sal;
this.birthday = birthday;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getSal() {
return sal;
}
public void setSal(int sal) {
this.sal = sal;
}
public Mydate getBirthday() {
return birthday;
}
public void setBirthday(Mydate birthday) {
this.birthday = birthday;
}
@Override
public String toString() {
return "\nEmployee{" +
"name='" + name + '\'' +
", sal=" + sal +
", birthday=" + birthday +
'}';
}
}
8.6 自定义泛型
8.6.1 基本介绍

注释:具体案例见下文代码部分
2)因为在类定义中,数组的类型是用泛型符号占位使用的,而编译器此时不知道数组的具体数据类型,从而无法知晓应该分配多大的内存空间,因此无法进行初始化(也就是new一个数组)。只能定义一个泛型数组的引用类型。
3)与2)差不多,因为无法指定数据类型,JVM并不能对其进行内存空间的分配以及初始化,因此静态方法中不能使用泛型。、
//老韩解读
//1. Tiger 后面有泛型,所以我们把 Tiger 就称为自定义泛型类
//2, T, R, M 泛型的标识符, 一般是单个大写字母
//3. < >内泛型标识符可以有多个.
//4. 普通成员可以使用泛型 (属性、方法)
//5. 使用泛型的数组,不能初始化
//6. 静态方法中不能使用类的泛型
class Tiger<T, R, M> {
String name;
R r; //属性使用到泛型,具体R M T 是什么类型的数据,是在定义Tiger时指定的
M m;
T t;
//因为数组在new 不能确定T的类型,因此不知道要使用多大的内存,所以就无法在内存开空间
//T[] ts = new T[8] //错误
T[] ts;//只能定义一个引用
public Tiger(String name, R r, M m, T t) {//构造器使用泛型
this.name = name;
this.r = r;
this.m = m;
this.t = t;
}
//因为静态是和类相关的,在类加载时,对象还没有创建
//所以,如果静态方法和静态属性使用了泛型,JVM就无法完成初始化
// static R r2;
// public static void m1(M m) {
//
// }
//方法使用泛型
public R getR() {
return r;
}
public void setR(R r) {//方法使用到泛型
this.r = r;
}
public M getM() {//返回类型可以使用泛型.
return m;
}
......
}
8.6.2 案例演示
//T=Double, R=String, M=Integer
Tiger<Double,String,Integer> g = new Tiger<>("john");
g.setT(10.9); //OK
//g.setT("yy"); //错误,类型不对
System.out.println(g);
Tiger g2 = new Tiger("john~~");//OK T=Object R=Object M=Object
g2.setT("yy"); //OK ,因为 T=Object "yy"=String 是Object子类
System.out.println("g2=" + g2);
public class CustomGeneric_ {
public static void main(String[] args) {
//T=Double, R=String, M=Integer
Tiger<Double,String,Integer> g = new Tiger<>("john");
g.setT(10.9); //OK
//g.setT("yy"); //错误,类型不对
System.out.println(g);
Tiger g2 = new Tiger("john~~");//OK T=Object R=Object M=Object
g2.setT("yy"); //OK ,因为 T=Object "yy"=String 是Object子类
System.out.println("g2=" + g2);
}
}
//老韩解读
//1. Tiger 后面有泛型,所以我们把 Tiger 就称为自定义泛型类
//2, T, R, M 泛型的标识符, 一般是单个大写字母
//3. < >内泛型标识符可以有多个.
//4. 普通成员可以使用泛型 (属性、方法)
//5. 使用泛型的数组,不能初始化
//6. 静态方法中不能使用类的泛型
class Tiger<T, R, M> {
String name;
R r; //属性使用到泛型,具体R M T 是什么类型的数据,是在定义Tiger时指定的
M m;
T t;
//因为数组在new 不能确定T的类型,因此不知道要使用多大的内存,所以就无法在内存开空间
//T[] ts = new T[8] //错误
T[] ts;//只能定义一个引用
public Tiger(String name) {
this.name = name;
}
public Tiger(R r, M m, T t) {//构造器使用泛型
this.r = r;
this.m = m;
this.t = t;
}
public Tiger(String name, R r, M m, T t) {//构造器使用泛型
this.name = name;
this.r = r;
this.m = m;
this.t = t;
}
//因为静态是和类相关的,在类加载时,对象还没有创建
//所以,如果静态方法和静态属性使用了泛型,JVM就无法完成初始化
// static R r2;
// public static void m1(M m) {
//
// }
//方法使用泛型
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public R getR() {
return r;
}
public void setR(R r) {//方法使用到泛型
this.r = r;
}
public M getM() {//返回类型可以使用泛型.
return m;
}
public void setM(M m) {
this.m = m;
}
public T getT() {
return t;
}
public void setT(T t) {
this.t = t;
}
@Override
public String toString() {
return "Tiger{" +
"name='" + name + '\'' +
", r=" + r +
", m=" + m +
", t=" + t +
", ts=" + Arrays.toString(ts) +
'}';
}
}
8.6.3 自定义泛型接口

/**
* 泛型接口使用的说明
* 1. 接口中,静态成员也不能使用泛型
* 2. 泛型接口的类型, 在继承接口或者实现接口时确定
* 3. 没有指定类型,默认为Object
*/
//在继承接口 指定泛型接口的类型
interface IA extends IUsb<String, Double> {
}
//当我们去实现IA接口时,因为IA在继承IUsu 接口时,指定了U 为String R为Double
//,在实现IUsu接口的方法时,使用String替换U, 是Double替换R
class AA implements IA {
@Override
public Double get(String s) {
return null;
}
@Override
public void hi(Double aDouble) {
}
@Override
public void run(Double r1, Double r2, String u1, String u2) {
}
}
//实现接口时,直接指定泛型接口的类型
//给U 指定Integer 给 R 指定了 Float
//所以,当我们实现IUsb方法时,会使用Integer替换U, 使用Float替换R
class BB implements IUsb<Integer, Float> {
@Override
public Float get(Integer integer) {
return null;
}
@Override
public void hi(Float aFloat) {
}
@Override
public void run(Float r1, Float r2, Integer u1, Integer u2) {
}
}
//没有指定类型,默认为Object
//建议直接写成 IUsb<Object,Object>
class CC implements IUsb { //等价 class CC implements IUsb<Object,Object> {
@Override
public Object get(Object o) {
return null;
}
@Override
public void hi(Object o) {
}
@Override
public void run(Object r1, Object r2, Object u1, Object u2) {
}
}
interface IUsb<U, R> {
int n = 10;
//U name; 不能这样使用,因为接口中所有属性默认为public static final
//普通方法中,可以使用接口泛型
R get(U u);
void hi(R r);
void run(R r1, R r2, U u1, U u2);
//在jdk8 中,可以在接口中,使用默认方法, 也是可以使用泛型
default R method(U u) {
return null;
}
}
注意:接口中属性不能用泛型定义,记住接口中属性默认为public static final。普通方法中的参数列表里可以使用。
8.6.4 自定义泛型方法
注意与方法使用了泛型进行对比,方法使用了泛型一般是在参数列表位置上使用了泛型占位符。而自定义泛型方法是在修饰符后面有自定义泛型符号。

public class CustomMethodGeneric {
public static void main(String[] args) {
Car car = new Car();
car.fly("宝马", 100);//当调用方法时,传入参数,编译器,就会确定类型
System.out.println("=======");
car.fly(300, 100.1);//当调用方法时,传入参数,编译器,就会确定类型
//测试
//T->String, R-> ArrayList
Fish<String, ArrayList> fish = new Fish<>();
fish.hello(new ArrayList(), 11.3f);
}
}
//泛型方法,可以定义在普通类中, 也可以定义在泛型类中
class Car {//普通类
public void run() {//普通方法
}
//说明 泛型方法
//1. <T,R> 就是泛型
//2. 是提供给 fly使用的
public <T, R> void fly(T t, R r) {//泛型方法
System.out.println(t.getClass());//String,根据传入的不同数据类型,会进行变化
System.out.println(r.getClass());//Integer
}
}
class Fish<T, R> {//泛型类
public void run() {//普通方法
}
public<U,M> void eat(U u, M m) {//泛型方法
}
//说明
//1. 下面hi方法不是泛型方法
//2. 是hi方法使用了类声明的 泛型
public void hi(T t) {
}
//泛型方法,可以使用类声明的泛型,也可以使用自己声明泛型
public<K> void hello(R r, K k) {
System.out.println(r.getClass());//ArrayList
System.out.println(k.getClass());//Float
}
}
课堂练习:

注解:
- 注意题中的U是没有定义的,既不是类名后的泛型符号,也不是泛型方法。
- apple.fly(10);// 10 会被自动装箱 Integer 10, 输出Integer
- apple.fly(new Dog());//Dog
- getClass()会打印包名+类名,而getSimpleName()只会打印类名。
8.6.5 泛型继承和通配符(受限泛型)

注解:
-
泛型不具备继承性!
-
泛型上下限的理解:(好好理解,很重要)
1)<? extends A> 此时泛型只能支持A类或其子类,而父类不能使用,规定了向上支持的上限。
2)同理,<? super A> 此时泛型支持A类及其父类,A类的子类不能使用,也就是向下使用最低到A类,规定了下限。
public class GenericExtends {
public static void main(String[] args) {
Object o = new String("xx");
//泛型没有继承性
//List<Object> list = new ArrayList<String>();
//举例说明下面三个方法的使用
List<Object> list1 = new ArrayList<>();
List<String> list2 = new ArrayList<>();
List<AA> list3 = new ArrayList<>();
List<BB> list4 = new ArrayList<>();
List<CC> list5 = new ArrayList<>();
//如果是 List<?> c ,可以接受任意的泛型类型
printCollection1(list1);
printCollection1(list2);
printCollection1(list3);
printCollection1(list4);
printCollection1(list5);
//List<? extends AA> c: 表示 上限,可以接受 AA或者AA子类
// printCollection2(list1);//×
// printCollection2(list2);//×
printCollection2(list3);//√
printCollection2(list4);//√
printCollection2(list5);//√
//List<? super AA> c: 支持AA类以及AA类的父类,不限于直接父类
printCollection3(list1);//√
//printCollection3(list2);//×
printCollection3(list3);//√
//printCollection3(list4);//×
//printCollection3(list5);//×
}
// ? extends AA 表示 上限,可以接受 AA或者AA子类
public static void printCollection2(List<? extends AA> c) {
for (Object object : c) {
System.out.println(object);
}
}
//说明: List<?> 表示 任意的泛型类型都可以接受
public static void printCollection1(List<?> c) {
for (Object object : c) { // 通配符,取出时,就是Object
System.out.println(object);
}
}
// ? super 子类类名AA:支持AA类以及AA类的父类,不限于直接父类,
//规定了泛型的下限
public static void printCollection3(List<? super AA> c) {
for (Object object : c) {
System.out.println(object);
}
}
}
class AA {
}
class BB extends AA {
}
class CC extends BB {
}
8.7 JUnit(单元测试框架)

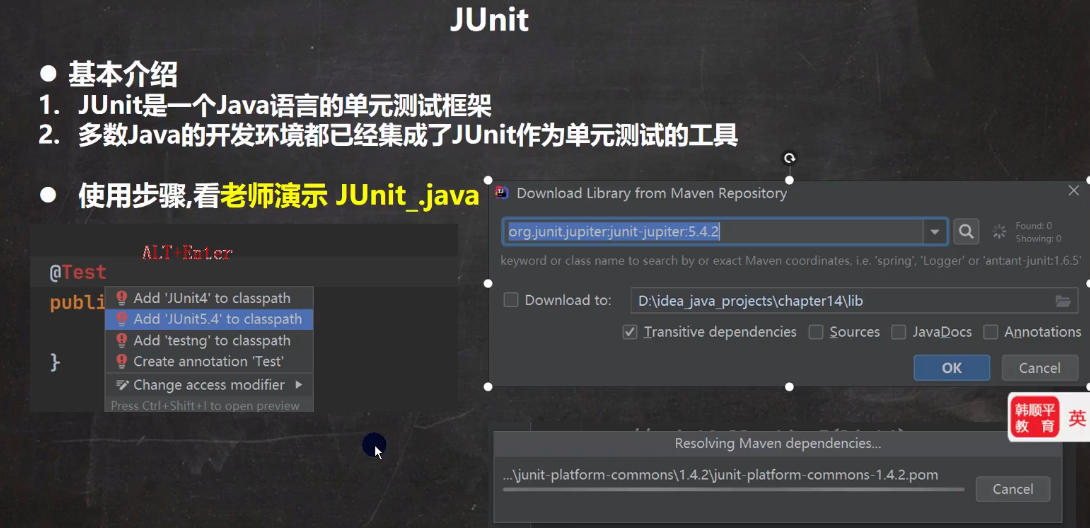
8.8 本章作业

主要代码展示,DAO:
/**
* 定义个泛型类 DAO<T>,在其中定义一个Map 成员变量,Map 的键为 String 类型,值为 T 类型。
* * 分别创建以下方法:
* * (1) public void save(String id,T entity): 保存 T 类型的对象到 Map 成员变量中
* * (2) public T get(String id):从 map 中获取 id 对应的对象
* * (3) public void update(String id,T entity):替换 map 中key为id的内容,改为 entity 对象
* * (4) public List<T> list():返回 map 中存放的所有 T 对象
* * (5) public void delete(String id):删除指定 id 对象
*/
public class DAO<T> {//泛型类
private Map<String, T> map = new HashMap<>();
public T get(String id) {
return map.get(id);
}
public void update(String id,T entity) {
map.put(id, entity);
}
//返回 map 中存放的所有 T 对象
//遍历map [k-v],将map的 所有value(T entity),封装到ArrayList返回即可
public List<T> list() {
//创建 Arraylist
List<T> list = new ArrayList<>();
//遍历map
Set<String> keySet = map.keySet();
for (String key : keySet) {
//map.get(key) 返回就是 User对象->ArrayList
list.add(map.get(key));//也可以直接使用本类的 get(String id)
}
return list;
}
public void delete(String id) {
map.remove(id);
}
public void save(String id,T entity) {//把entity保存到map
map.put(id, entity);
}
}
第九章 IO流专题
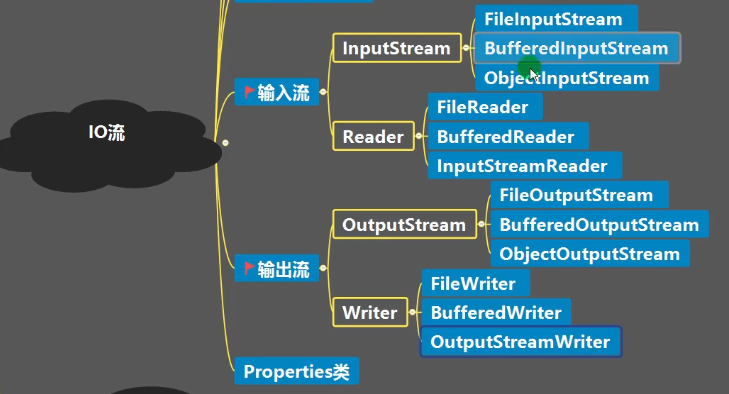

9.1 文件
9.1.1 文件的基本介绍
文件就是保存数据的地方。

9.1.2 常用的文件操作
- 创建文件
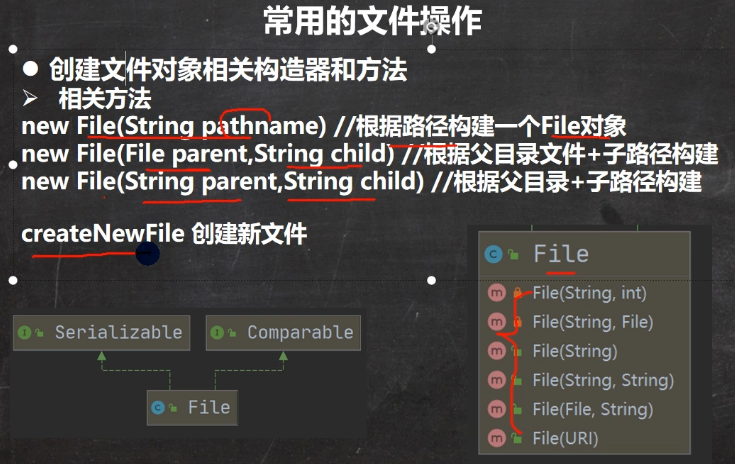
主要需要注意,一定要调用creatNewFile方法在磁盘中创建文件。
//方式1 new File(String pathname)
@Test
public void create01() {
String filePath = "e:\\news1.txt";
File file = new File(filePath);
try {
file.createNewFile();
System.out.println("文件创建成功");
} catch (IOException e) {
e.printStackTrace();
}
}
//方式2 new File(File parent,String child) //根据父目录文件+子路径构建
//e:\\news2.txt
@Test
public void create02() {
File parentFile = new File("e:\\");
String fileName = "news2.txt";
//这里的file对象,在java程序中,只是一个对象
//只有执行了createNewFile 方法,才会真正的,在磁盘创建该文件
File file = new File(parentFile, fileName);
try {
file.createNewFile();
System.out.println("创建成功~");
} catch (IOException e) {
e.printStackTrace();
}
}
//方式3 new File(String parent,String child) //根据父目录+子路径构建
@Test
public void create03() {
//String parentPath = "e:\\";
String parentPath = "e:\\"; // 这里是String,不是File,注意
String fileName = "news4.txt";
File file = new File(parentPath, fileName);
try {
file.createNewFile();
System.out.println("创建成功~");
} catch (IOException e) {
e.printStackTrace();
}
}
- 获取文件信息
//先创建文件对象
File file = new File("e:\\news1.txt");
//调用相应的方法,得到对应信息
System.out.println("文件名字=" + file.getName());
//getName、getAbsolutePath、getParent、length、exists、isFile、isDirectory
System.out.println("文件绝对路径=" + file.getAbsolutePath());
System.out.println("文件父级目录=" + file.getParent());
System.out.println("文件大小(字节)=" + file.length());
System.out.println("文件是否存在=" + file.exists());//T
System.out.println("是不是一个文件=" + file.isFile());//T
System.out.println("是不是一个目录=" + file.isDirectory());//F
/** 结果
文件名字=news1.txt
文件绝对路径=e:\news1.txt
文件父级目录=e:\
文件大小(字节)=0
文件是否存在=false
是不是一个文件=false
是不是一个目录=false
*/
-
目录的操作和文件删除
//判断 d:\\news1.txt 是否存在,如果存在就删除 @Test public void m1() { String filePath = "e:\\news1.txt"; File file = new File(filePath); if (file.exists()) { if (file.delete()) { System.out.println(filePath + "删除成功"); } else { System.out.println(filePath + "删除失败"); } } else { System.out.println("该文件不存在..."); } } //判断 D:\\demo02 是否存在,存在就删除,否则提示不存在 //这里我们需要体会到,在java编程中,目录也被当做文件 @Test public void m2() { String filePath = "D:\\demo02"; File file = new File(filePath); if (file.exists()) { if (file.delete()) { System.out.println(filePath + "删除成功"); } else { System.out.println(filePath + "删除失败"); } } else { System.out.println("该目录不存在..."); } } //判断 D:\\demo\\a\\b\\c 目录是否存在,如果存在就提示已经存在,否则就创建 @Test public void m3() { String directoryPath = "D:\\demo\\a\\b\\c"; File file = new File(directoryPath); if (file.exists()) { System.out.println(directoryPath + "存在.."); } else { if (file.mkdirs()) { //创建一级目录使用mkdir() ,创建多级目录使用mkdirs() System.out.println(directoryPath + "创建成功.."); } else { System.out.println(directoryPath + "创建失败..."); } } }删除:file.delete()
存在:file.exists()
创建一级目录:file.mkdir()
创建多级目录:file.mkdirs()
9.2 IO流原理和分类
9.2.1 IO流原理


9.2.2 IO流分类

1)IO流按照操作数据的单位不同可以分为字节流和字符流。字节流适用于二进制文件,比如0101的字节流。而字符流(按字符,一个字符有多少个字节,取决于编码方式)适用于文本文件的读写(如汉字,一个汉字由三个字节组成,如果用字节流处理汉字,会出现乱码)。
2)这四个抽象基类都不能单独实例化(顶级基类),必须使用其实现子类进行实例化。
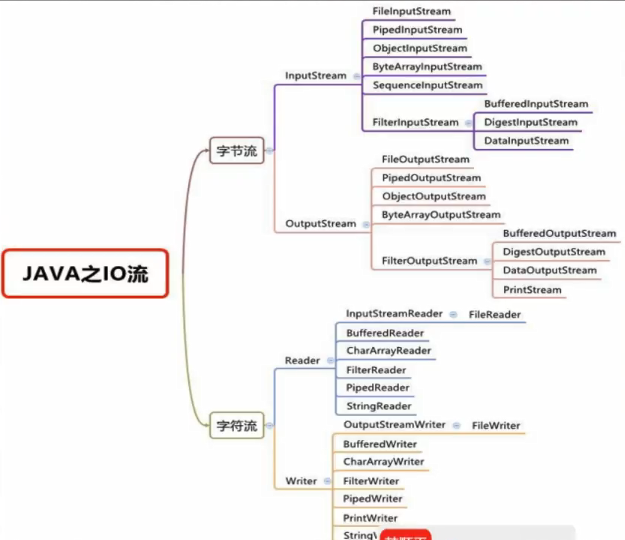
9.3 字节流
9.3.1 InputStream 字节输入流

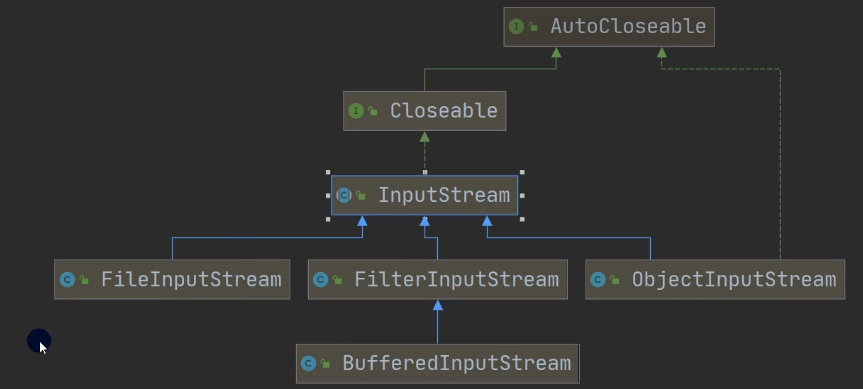
9.3.1.1 FileInputStream
字节输入流(文件 ——> 程序)

下面代码演示了用FileInputStream进行字节的读取:进行几点说明
- 方法01是单个字节的读取,效率比较低,如果对汉字进行读写的化,会有乱码的情况,因为一个汉字是由多个字节组成,而此时是按照单个字节读取并打印的,会出现乱码。
- 方法02是提高效率的方式,按照一个指定大小的byte数组进行读取,效率高。
/**
* 演示读取文件...
* 单个字节的读取,效率比较低
* -> 使用 read(byte[] b) 效率高
*/
@Test
public void readFile01() {
String filePath = "e:\\hello.txt";
int readData = 0;
FileInputStream fileInputStream = null;
try {
//创建 FileInputStream 对象,用于读取 文件
fileInputStream = new FileInputStream(filePath);
//从该输入流读取一个字节的数据。 如果没有输入可用,此方法将阻止。
//如果返回-1 , 表示读取完毕
while ((readData = fileInputStream.read()) != -1) {
System.out.print((char)readData);//转成char显示
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//关闭文件流,释放资源.
try {
fileInputStream.close();//这个动作一定要执行,释放资源
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 使用 read(byte[] b) 读取文件,提高效率
* 需要明确,如果用字节流读取中文汉字,会出现乱码,
* 因为汉字一个字符不止一个字节组成
*/
@Test
public void readFile02() {
String filePath = "e:\\hello.txt";
//字节数组
byte[] buf = new byte[8]; //一次读取8个字节.每8个字节读取一次
int readLen = 0;
FileInputStream fileInputStream = null;
try {
//创建 FileInputStream 对象,用于读取 文件
fileInputStream = new FileInputStream(filePath);
//从该输入流读取最多b.length字节的数据到字节数组。 此方法将阻塞,直到某些输入可用。
//如果返回-1 , 表示读取完毕
//如果读取正常, 返回实际读取的字节数
while ((readLen = fileInputStream.read(buf)) != -1) {
System.out.print(new String(buf, 0, readLen));//显示,以实际读取字节数进行显示
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//关闭文件流,释放资源.
try {
fileInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
9.3.1.2 BufferedInputStream(包装流)

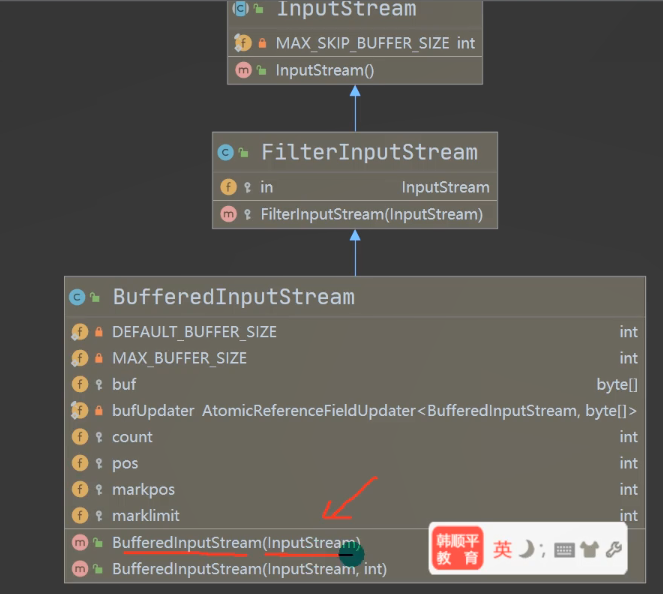
BufferedInputStream接收InputStream抽象类实现的子类就行。
9.3.2 OutputStream 字节输出流
9.3.2.1 FileOutputStream
字节输出流(文件 <—— 程序)

/**
* 演示使用FileOutputStream 将数据写到文件中,
* 如果该文件不存在,则创建该文件
*/
@Test
public void writeFile() {
//创建 FileOutputStream对象
String filePath = "e:\\a.txt";
FileOutputStream fileOutputStream = null;
try {
//得到 FileOutputStream对象 对象
//老师说明
//1. new FileOutputStream(filePath) 创建方式,当写入内容是,会覆盖原来的内容
//2. new FileOutputStream(filePath, true) 创建方式,当写入内容是,是追加到文件后面
fileOutputStream = new FileOutputStream(filePath, true);
//写入一个字节
fileOutputStream.write('H');
//写入字符串
String str = "hsp,world!";
fileOutputStream.write(str.getBytes());//str.getBytes() 可以把 字符串-> 字节数组
/*
write(byte[] b, int off, int len) 将 len字节从位于偏移量 off的指定字节数组写入此文件输出流
*/
fileOutputStream.write(str.getBytes(), 0, 3);
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
fileOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
9.3.2.2 BufferedOutputStream(包装流/处理流)


9.3.3 应用实例
9.3.3.1 文件拷贝
要求:编程完成图片/音乐的拷贝(涉及到文件字节输入流和输出流)

public class FileCopy {
public static void main(String[] args) {
//完成 文件拷贝,将 e:\\Koala.jpg 拷贝 c:\\
//思路分析
//1. 创建文件的输入流 , 将文件读入到程序
//2. 创建文件的输出流, 将读取到的文件数据,写入到指定的文件.
String srcFilePath = "e:\\Koala.jpg";
String destFilePath = "e:\\Koala3.jpg";
FileInputStream fileInputStream = null;
FileOutputStream fileOutputStream = null;
try {
fileInputStream = new FileInputStream(srcFilePath);
fileOutputStream = new FileOutputStream(destFilePath);
//定义一个字节数组,提高读取效果
byte[] buf = new byte[1024];
int readLen = 0;
while ((readLen = fileInputStream.read(buf)) != -1) {//返回-1时,说明读取完毕
//读取到后,就写入到文件 通过 fileOutputStream
//即,是一边读,一边写
fileOutputStream.write(buf, 0, readLen);//一定要使用这个方法(因为无法保证最后一次buf能读满1024个字节)
}
System.out.println("拷贝ok~");
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
//关闭输入流和输出流,释放资源
if (fileInputStream != null) {
fileInputStream.close();
}
if (fileOutputStream != null) {
fileOutputStream.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
9.3.3.2 文件拷贝(包装流实现)
// 使用字节流,可以实现拷贝二进制文件,当然也可以拷贝文本文件
public class BufferedCopy {
public static void main(String[] args) {
// 使用图片读取会发生错误,得用字节流
String sourceFile = "d:\\LalaLand.jpg";
String destFile = "e:\\LalaLand.jpg";
BufferedInputStream bufferedReader = null;// 改成字节流之后,图片能够进行读取了
BufferedOutputStream bufferedWriter = null;
int line;
//byte[] buff = new byte[1024];//数组读取法,效率高
try {
bufferedReader = new BufferedInputStream(new FileInputStream(sourceFile));
bufferedWriter = new BufferedOutputStream(new FileOutputStream(destFile));
while ((line = bufferedReader.read() )!= -1) {//bufferedReader.read(buff);
bufferedWriter.write((char)line);//bufferedWriter.write(buff, 0, line);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
bufferedReader.close();
bufferedWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
9.4 字符流
9.4.1 Reader 字符输入流
9.4.1.1 FileReader
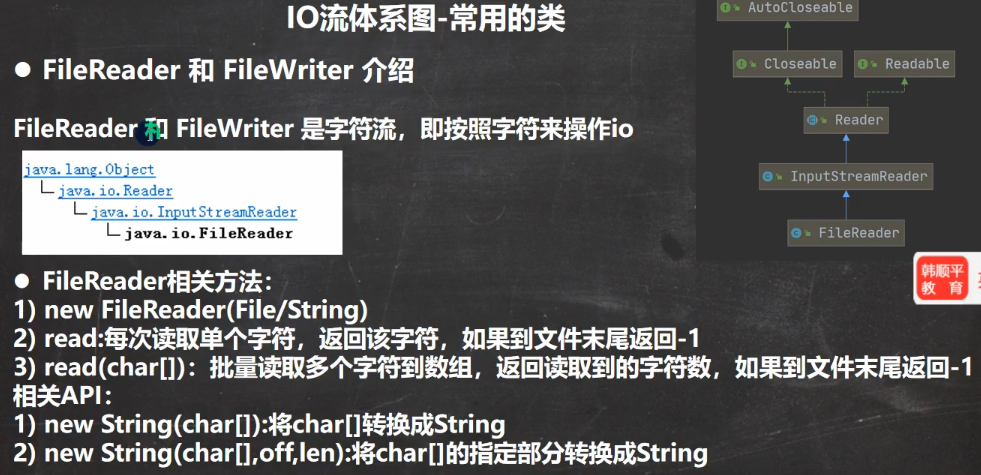
使用FileReader从story.txt中读取内容
/**
* 单个字符读取文件
*/
@Test
public void readFile01() {
String filePath = "e:\\story.txt";
FileReader fileReader = null;
int data = 0;
//1. 创建FileReader对象
try {
fileReader = new FileReader(filePath);
//循环读取 使用read, 单个字符读取
while ((data = fileReader.read()) != -1) {
System.out.print((char) data); //ASCII码
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (fileReader != null) {
fileReader.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 字符数组读取文件
*/
@Test
public void readFile02() {
System.out.println("~~~readFile02 ~~~");
String filePath = "e:\\story.txt";
FileReader fileReader = null;
int readLen = 0;
char[] buf = new char[8];
//1. 创建FileReader对象
try {
fileReader = new FileReader(filePath);
//循环读取 使用read(buf), 返回的是实际读取到的字符数
//如果返回-1, 说明到文件结束
while ((readLen = fileReader.read(buf)) != -1) {
System.out.print(new String(buf, 0, readLen)); //注意操作,一定得这样写
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (fileReader != null) {
fileReader.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
9.4.1.2 BufferedReader 包装流(处理流)
继承于Reader
包装流只进行包装,真正进行数据读取的还是节点流。当我们去关闭包装流的时候,底层实际上是去关闭节点流。
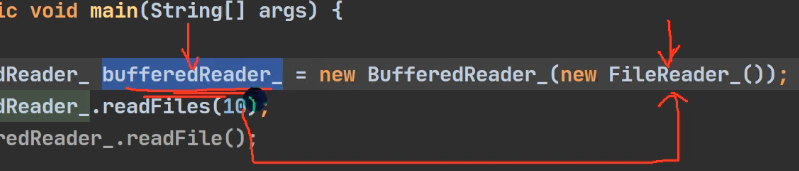
应用案例:

String filePath = "e:\\a.java";
//创建bufferedReader
BufferedReader bufferedReader = new BufferedReader(new FileReader(filePath));
//读取
String line; //按行读取, 效率高
//说明
//1. bufferedReader.readLine() 是按行读取文件
//2. 当返回null 时,表示文件读取完毕
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);
}
//关闭流, 这里注意,只需要关闭 BufferedReader ,因为底层会自动的去关闭 节点流
//FileReader。
/*
public void close() throws IOException {
synchronized (lock) {
if (in == null)
return;
try {
in.close();//in 就是我们传入的 new FileReader(filePath), 关闭了.
} finally {
in = null;
cb = null;
}
}
}
*/
bufferedReader.close();//关闭流,节省开销
注意:BufferedReader流读取时候,文件读取完毕,是返回null表示结束,而不是-1。
9.4.2 Writer 字符输出流
9.4.2.1 FileWriter
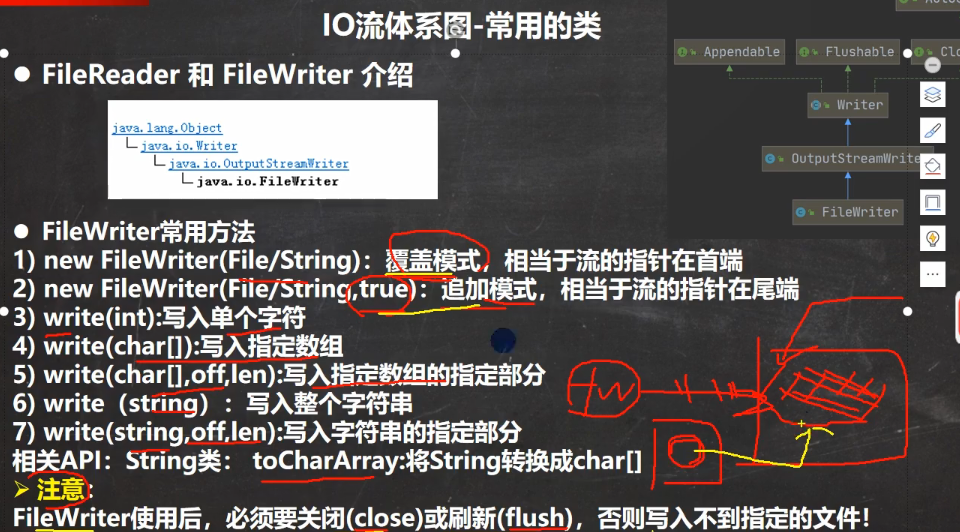
最后一句:因为此时文件还在内存中,需要手动刷新或关闭才能写到磁盘上,关闭操作是会引起强制刷新的,所以也可以。
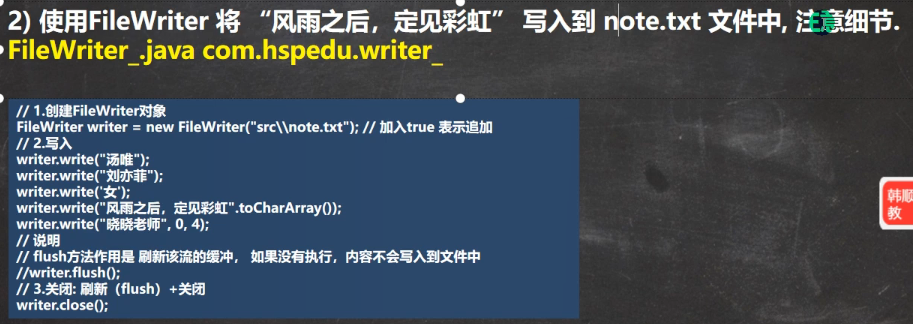
细节:1.写入完之后一定要关闭或者刷新。2.是覆盖写入还是追加写入。
public class FileWriter_ {
public static void main(String[] args) {
String filePath = "e:\\note.txt";
//创建FileWriter对象
FileWriter fileWriter = null;
char[] chars = {'a', 'b', 'c'};
try {
fileWriter = new FileWriter(filePath);//默认是覆盖写入
// 3) write(int):写入单个字符
fileWriter.write('H');
// 4) write(char[]):写入指定数组
fileWriter.write(chars);
// 5) write(char[],off,len):写入指定数组的指定部分
fileWriter.write("韩顺平教育".toCharArray(), 0, 3);
// 6) write(string):写入整个字符串
fileWriter.write(" 你好北京~");
fileWriter.write("风雨之后,定见彩虹");
// 7) write(string,off,len):写入字符串的指定部分
fileWriter.write("上海天津", 0, 2);
//在数据量大的情况下,可以使用循环操作.
} catch (IOException e) {
e.printStackTrace();
} finally {
//对应FileWriter , 一定要关闭流,或者flush才能真正的把数据写入到文件
//老韩看源码就知道原因.
/*
看看代码
private void writeBytes() throws IOException {
this.bb.flip();
int var1 = this.bb.limit();
int var2 = this.bb.position();
assert var2 <= var1;
int var3 = var2 <= var1 ? var1 - var2 : 0;
if (var3 > 0) {
if (this.ch != null) {
assert this.ch.write(this.bb) == var3 : var3;
} else {
this.out.write(this.bb.array(), this.bb.arrayOffset() + var2, var3);
}
}
this.bb.clear();
}
*/
try {
//fileWriter.flush();
//关闭文件流,等价 flush() + 关闭
fileWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println("程序结束...");
}
}
9.4.2.2 BufferedWriter
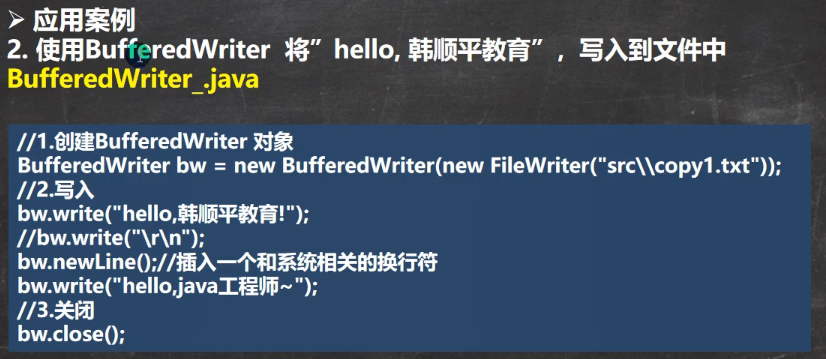
String filePath = "e:\\ok.txt";
//创建BufferedWriter
//说明:
//1. new FileWriter(filePath, true) 表示以追加的方式写入
//2. new FileWriter(filePath) , 表示以覆盖的方式写入
BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter(filePath));
bufferedWriter.write("hello, 韩顺平教育!");
bufferedWriter.newLine();//插入一个和系统相关的换行
bufferedWriter.write("hello2, 韩顺平教育!");
bufferedWriter.newLine();
bufferedWriter.write("hello3, 韩顺平教育!");
bufferedWriter.newLine();
//说明:关闭外层流即可 , 传入的 new FileWriter(filePath) ,会在底层关闭
bufferedWriter.close();
9.4.3 应用实例
9.4.3.1 文本文件拷贝(BufferedReader和Writer实现)
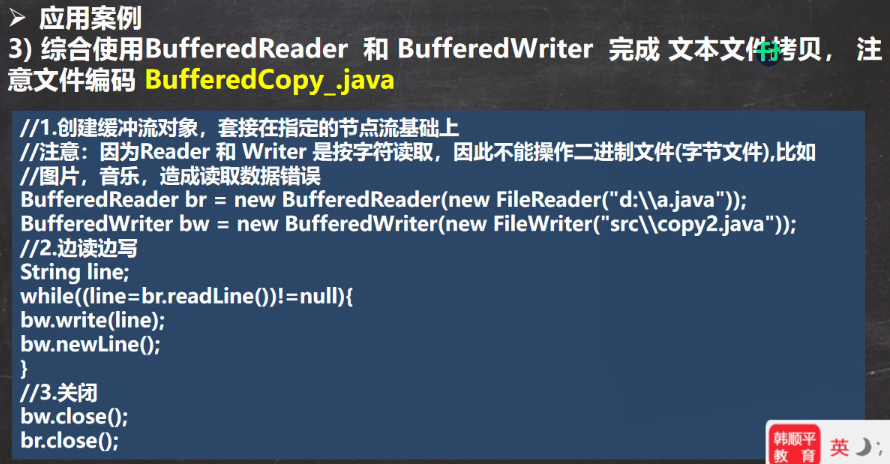
BufferedReader及Writer是字符流,不能用来读取二进制文件(如图片、音乐)
//老韩说明
//1. BufferedReader 和 BufferedWriter 是安装字符操作
//2. 不要去操作 二进制文件[声音,视频,doc, pdf ], 可能造成文件损坏
//BufferedInputStream
//BufferedOutputStream
String srcFilePath = "e:\\a.java";
String destFilePath = "e:\\a2.java";
// String srcFilePath = "e:\\0245_韩顺平零基础学Java_引出this.avi";
// String destFilePath = "e:\\a2韩顺平.avi";//要读二进制文件,得用BufferedInputStream及OutputStream
BufferedReader br = null;
BufferedWriter bw = null;
String line;
try {
br = new BufferedReader(new FileReader(srcFilePath));
bw = new BufferedWriter(new FileWriter(destFilePath));
//说明: readLine 读取一行内容,但是没有换行
while ((line = br.readLine()) != null) {
//每读取一行,就写入
bw.write(line);
//插入一个换行
bw.newLine();
}
System.out.println("拷贝完毕...");
} catch (IOException e) {
e.printStackTrace();
} finally {
//关闭流
try {
if(br != null) {
br.close();//关闭的是FileReader
}
if(bw != null) {
bw.close();//关闭的是FileWriter
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
9.5 节点流和包装流
9.5.1 基本介绍与解析

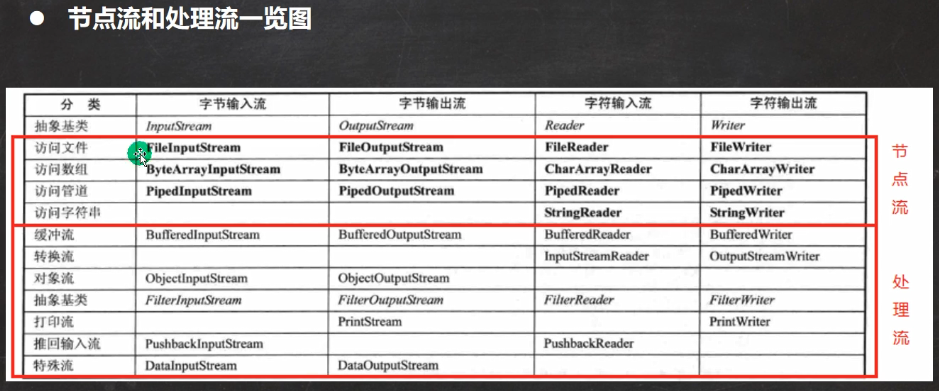
注释:
-
节点流(低级流/底层流)是比较低级的数据流,直接与特定数据源进行数据读写,并没有提供强大的包装功能,灵活性不高,效率不是很高。
-
对包装流的深入理解:

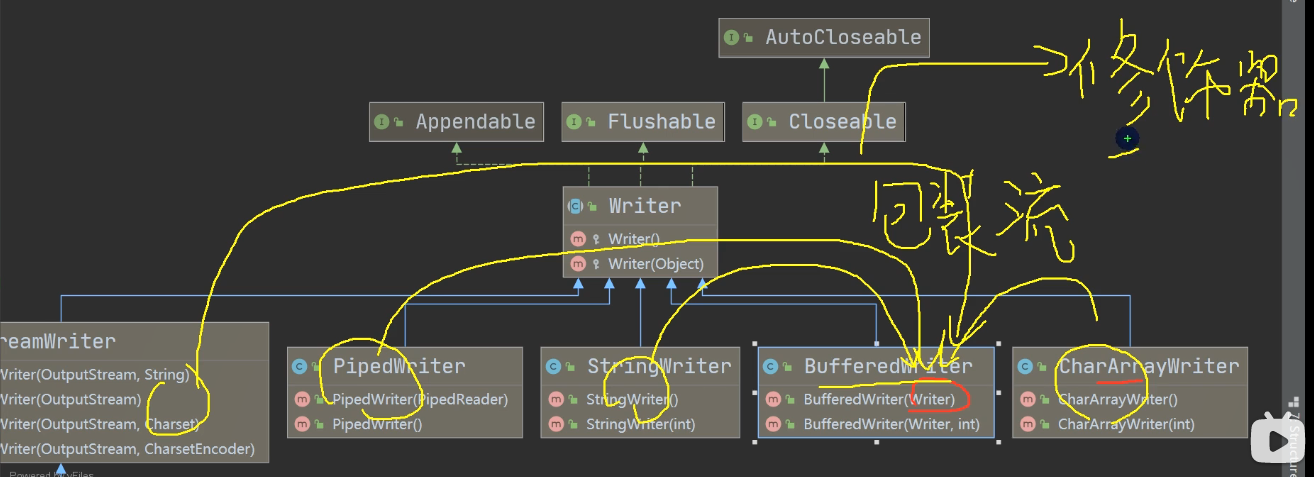
包装流是在节点流(底层流)之上的,但不同于节点流局限于同一个数据源,我们可以看到包装流中(以Buffered为例),无论是writer还是reader都有一个父类的引用属性Reader或者Writer,这样就会导致在包装流中可以实例化任何一个基础于Writer或者Reader的子类(多态),如上图的访问管道流、访问字符串流、访问数组等等节点流。相当于用一种包装流就可以操作所有的节点流,提高了操作的灵活性和性能。这样的设计模式也叫做修饰器模式。
9.5.2 区别与联系

注释:
- 可以在包装器类定义一些便捷的方法来处理数据,这是在节点流当中不具备的,包装器类扩展了节点流类的功能。
9.6 对象处理流(序列化)

9.6.1 序列化和反序列化
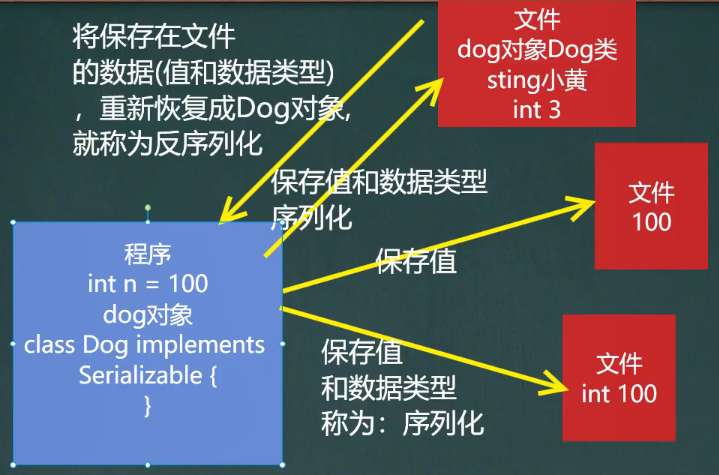
序列化:将程序中的数据能够按照值和其类型一一保存到文件中。
反序列化:从文件中读取数据,能够恢复数据的值和类型。
9.6.2 对象处理流的基本介绍
遵循修饰者模式,要使用对象处理流,将其对应实现Input/OutputStream的子类传进去即可。
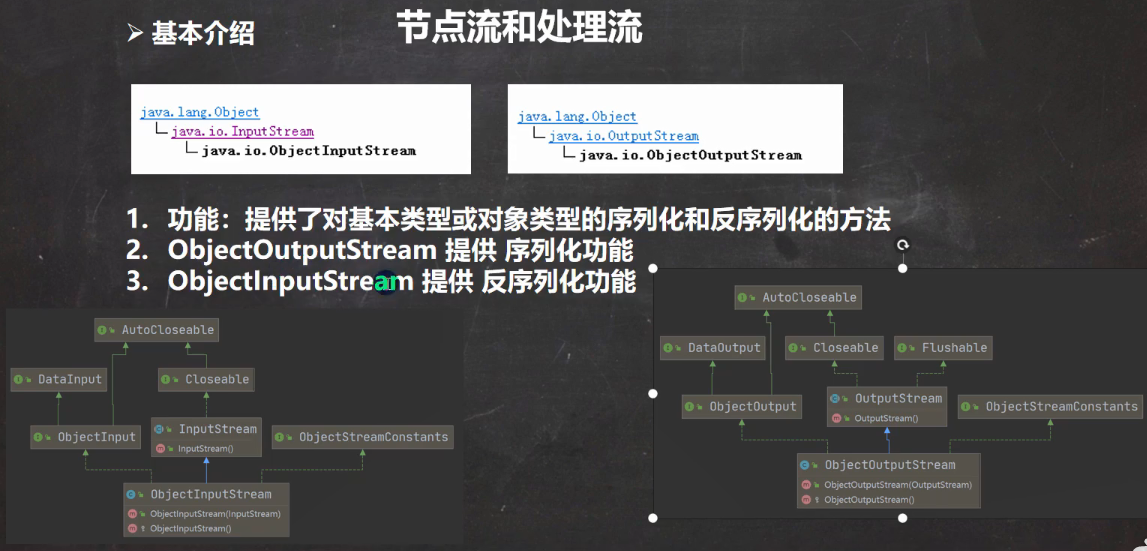
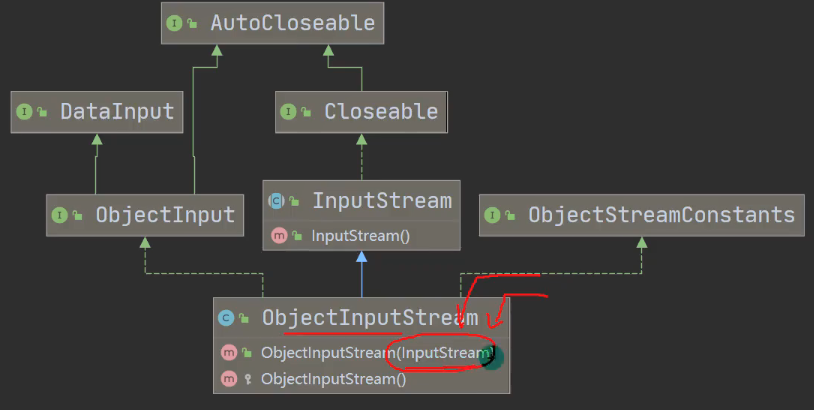
举例:ObjectInputStream因为是从文件向程序进行输入的,所以是将数据的值和类型进行恢复,所以是反序列化。
9.6.3 ObjectOutputStream(序列化操作)

字节输出流,从程序输出到文件,因此是序列化操作。
.writeXX()相关方法
//序列化
public static void main(String[] args) throws Exception {
//序列化后,保存的文件格式,不是存文本,而是按照他的格式来保存
String filePath = "e:\\data.dat";
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(filePath));
//序列化数据到 e:\data.dat
oos.writeInt(100);// int -> Integer 自动装箱 (Integer的父类Number是实现了 Serializable 接口的)
oos.writeBoolean(true);// boolean -> Boolean (实现了 Serializable)
oos.writeChar('a');// char -> Character (实现了 Serializable)
oos.writeDouble(9.5);// double -> Double (实现了 Serializable)
oos.writeUTF("韩顺平教育");//String (实现了 Serializable)
//保存一个dog对象
oos.writeObject(new Dog("旺财", 10, "日本", "白色"));//Dog须实现序列化(实现Serializable接口),不然要报错
oos.close();//关闭流
System.out.println("数据保存完毕(序列化形式)");
}
9.6.4 ObjectInputStream(反序列化操作)
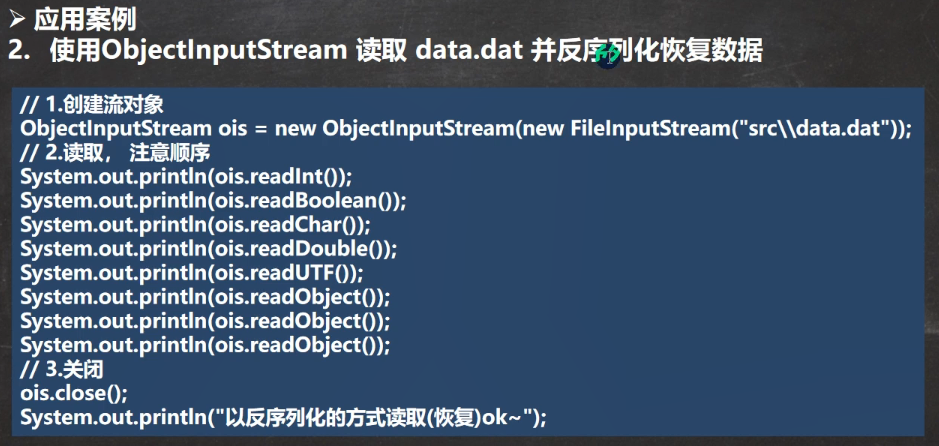
恢复上一节序列化的操作:
- 读取(反序列化)的顺序需要和保存数据(序列化)的顺序一致。
- .readXX()方法进行反序列化。
public static void main(String[] args) throws IOException, ClassNotFoundException {
//指定反序列化的文件
String filePath = "e:\\data.dat";
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(filePath));
//读取
//老师解读
//1. 读取(反序列化)的顺序需要和你保存数据(序列化)的顺序一致
//2. 否则会出现异常
System.out.println(ois.readInt());
System.out.println(ois.readBoolean());
System.out.println(ois.readChar());
System.out.println(ois.readDouble());
System.out.println(ois.readUTF());
//dog 的编译类型是 Object , dog 的运行类型是 Dog
Object dog = ois.readObject();
System.out.println("运行类型=" + dog.getClass());//dog
System.out.println("dog信息=" + dog);//底层 Object -> Dog
//这里是特别重要的细节:
//1. 如果我们希望调用Dog的方法, 需要向下转型
//2. 需要我们将Dog类的定义,放在到可以引用的位置
Dog dog2 = (Dog)dog;
System.out.println(dog2.getName()); //旺财..
//关闭流, 关闭外层流即可,底层会关闭 FileInputStream 流
ois.close();
}
9.6.5 对象处理流使用细节

注解:
1)反序列化顺序要和序列化顺序一致。
3)private static final long serialVersionUID = 1L; //serialVersionUID 序列化的版本号,可以提高兼容性,当添加新属性后,不会被认为是新类,而是原先类的升级版
4)transient 表示该属性不进行序列化保存数据;
5)如果成员属性有没有进行序列化的,会报错,如下面代码演示中的Master类必须进行序列化。
6)序列化支持继承,只要父类实现了序列化,子类也默认实现了(此时无需显示注明实现Serializable接口)。如下举例:
Dog类实现序列化接口,演示:
//如果需要序列化某个类的对象,实现 Serializable
public class Dog implements Serializable {
private String name;
private int age;
//序列化对象时,默认将里面所有属性都进行序列化,但除了static或transient修饰的成员
private static String nation;
private transient String color;
//序列化对象时,要求里面属性的类型也需要实现序列化接口
private Master master = new Master();//Master没有序列化,所以会报错
//serialVersionUID 序列化的版本号,可以提高兼容性,当添加新属性后,不会被认为是新类,而是原先类的升级版
private static final long serialVersionUID = 1L;
public Dog(String name, int age, String nation, String color) {
this.name = name;
this.age = age;
this.color = color;
this.nation = nation;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
", age=" + age +
", color='" + color + '\'' +
'}' + nation + " " +master;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
9.7 标准输入输出流

public static void main(String[] args) {
//System 类 的 public final static InputStream in = null;
// System.in 编译类型 InputStream
// System.in 运行类型 BufferedInputStream
// 表示的是标准输入(键盘)
System.out.println(System.in.getClass());
//老韩解读
//1. System.out ——> public final static PrintStream out = null;
//2. 编译类型 PrintStream
//3. 运行类型 PrintStream
//4. 表示标准输出(显示器)
System.out.println(System.out.getClass());
System.out.println("hello, 韩顺平教育~");//向显示器标准输出流
Scanner scanner = new Scanner(System.in);//从键盘标准输入流
System.out.println("输入内容");
String next = scanner.next();
System.out.println("next=" + next);
}
9.8 转换流
9.8.1 基本介绍
引出问题:一个中文乱码问题。(引出指定读取文件编码方式的重要性)
转换流的核心:可以将字节流转换为字符流,并且字节流可以指定编码方式(GBK、UTF-8等等)
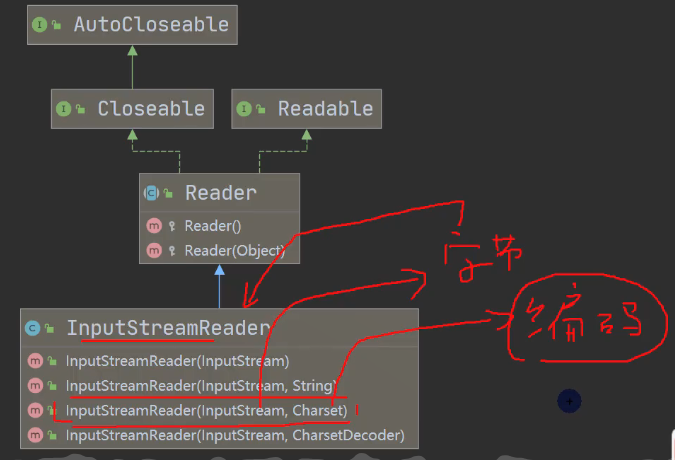
InputStreamReader构造器可以指定处理的编码,同理,OutputstreamWriter也有。

9.8.2 InputStreamReader 转换流
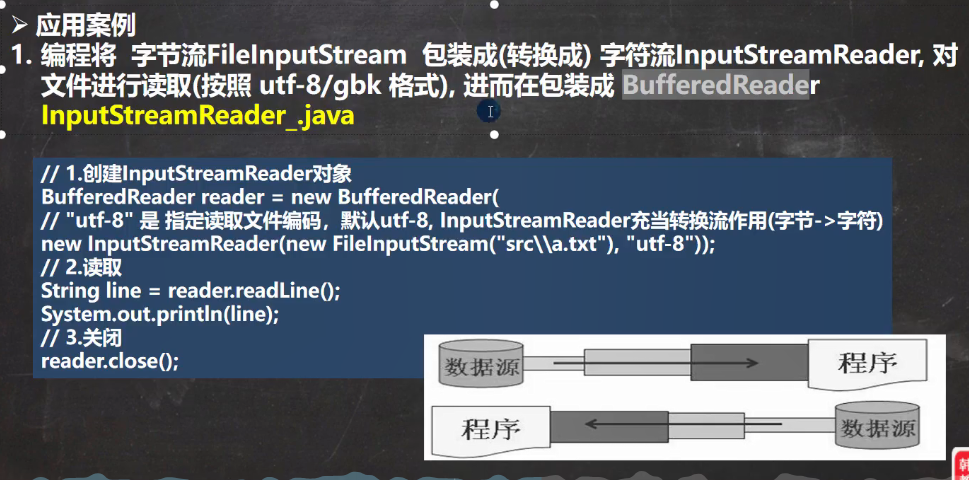
/**
* 演示使用 InputStreamReader 转换流解决中文乱码问题
* 将字节流 FileInputStream 转成字符流 InputStreamReader, 指定编码 gbk/utf-8
*/
public class InputStreamReader_ {
public static void main(String[] args) throws IOException {
String filePath = "e:\\a.txt";
//解读
//1. 把 FileInputStream 转成 InputStreamReader
//2. 指定编码 gbk
//InputStreamReader isr = new InputStreamReader(new FileInputStream(filePath), "gbk");
//3. 把 InputStreamReader 传入 BufferedReader
//BufferedReader br = new BufferedReader(isr);
//将2 和 3 合在一起
BufferedReader br = new BufferedReader(new InputStreamReader(
new FileInputStream(filePath), "gbk"));
//4. 读取
String s = br.readLine();
System.out.println("读取内容=" + s);
//5. 关闭外层流
br.close();
}
}
9.8.3 OutputStreamWriter 转换流
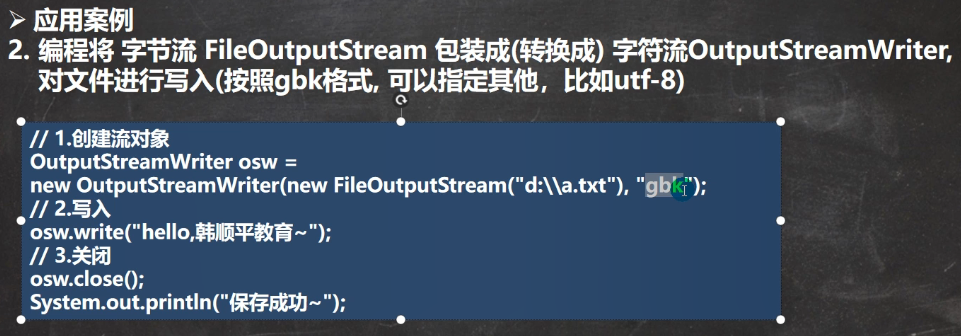
/**
* 演示 OutputStreamWriter 使用
* 把FileOutputStream 字节流,转成字符流 OutputStreamWriter
* 指定处理的编码 gbk/utf-8/utf8
*/
public class OutputStreamWriter_ {
public static void main(String[] args) throws IOException {
String filePath = "e:\\hsp.txt";
String charSet = "utf-8";
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(filePath), charSet);
osw.write("hi, 韩顺平教育");
osw.close();
System.out.println("按照 " + charSet + " 保存文件成功~");
}
}
9.9 打印流
打印流只有输出流,没有输入流
-
PrintStream 字节流
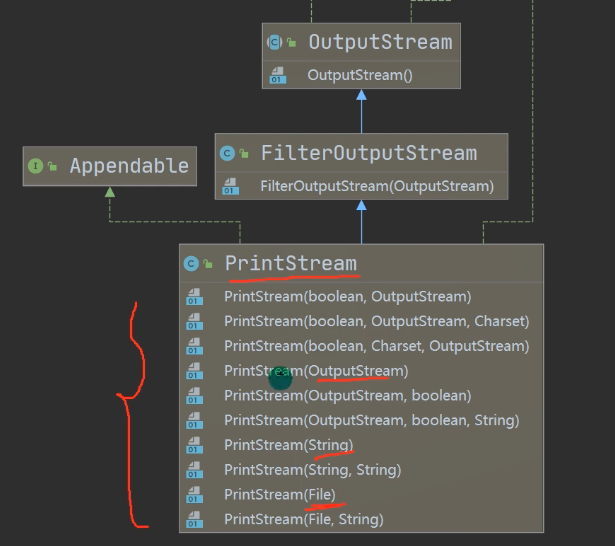
可以直接打印到文件里面,注意File
/** * 演示PrintStream (字节打印流/输出流) */ public class PrintStream_ { public static void main(String[] args) throws IOException { PrintStream out = System.out; //在默认情况下,PrintStream 输出数据的位置是 标准输出,即显示器 /* //print底层代码其实就是调用write public void print(String s) { if (s == null) { s = "null"; } write(s); } */ out.print("john, hello"); //因为print底层使用的是write , 所以我们可以直接调用write进行打印/输出 out.write("韩顺平,你好".getBytes()); out.close(); //我们可以去修改打印流输出的位置/设备 //1. 输出修改成到 "e:\\f1.txt" //2. "hello, 韩顺平教育~" 就会输出到 e:\f1.txt //3. public static void setOut(PrintStream out) { // checkIO(); // setOut0(out); // native 方法,修改了out // } System.setOut(new PrintStream("e:\\f1.txt"));//修改输出位置 System.out.println("hello, 韩顺平教育~");//输出到 e:\f1.txt } } -
PrintWriter 字符流
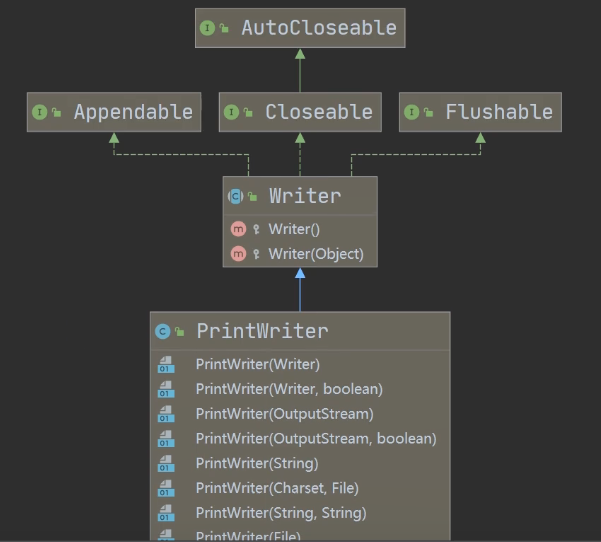
/**
* 演示 PrintWriter 使用方式
*/
public class PrintWriter_ {
public static void main(String[] args) throws IOException {
//PrintWriter printWriter = new PrintWriter(System.out);//打印到显示器
PrintWriter printWriter = new PrintWriter(new FileWriter("e:\\f2.txt"));//更改打印/输出的位置
printWriter.print("hi, 北京你好~~~~");
printWriter.close();//flush + 关闭流, 才会将数据写入到文件..
}
}
9.10 Properties类
9.10.1 引出Properties

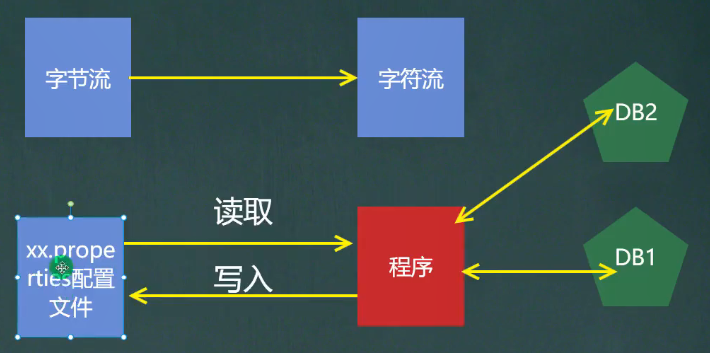
有时候需要对程序进行修改,但直接修改程序极为不灵活,所以才会引出properties配置文件的需求。
传统方法:获取数据麻烦,尤其是获取指定数据更为麻烦,需要进行一系列判断和处理。
public class Properties01 {
public static void main(String[] args) throws IOException {
//读取mysql.properties 文件,并得到ip, user 和 pwd
BufferedReader br = new BufferedReader(new FileReader("src\\mysql.properties"));
String line = "";
while ((line = br.readLine()) != null) { //循环读取
String[] split = line.split("=");
//如果我们要求指定的ip值
if("ip".equals(split[0])) {
System.out.println(split[0] + "值是: " + split[1]);
}
}
br.close();
}
}
9.10.2 Properties基本介绍

注意:Properties类的底层是HashTable,配置文件的存放其实就是键值对。

set方法,如果对象中没有相应的键值对,那么就会添加到Properties对象中
9.10.3 应用案例

-
public class Properties02 { public static void main(String[] args) throws IOException { //使用Properties 类来读取mysql.properties 文件 //1. 创建Properties 对象 Properties properties = new Properties(); //2. 加载指定配置文件 properties.load(new FileReader("src\\mysql.properties")); //3. 把k-v显示控制台 properties.list(System.out); //4. 根据key 获取对应的值 String user = properties.getProperty("user"); String pwd = properties.getProperty("pwd"); System.out.println("用户名=" + user); System.out.println("密码是=" + pwd); } } -
public class Properties03 { public static void main(String[] args) throws IOException { //使用Properties 类来创建 配置文件, 修改配置文件内容 Properties properties = new Properties(); //创建 /* Properties 父类是 Hashtable , 底层就是Hashtable 核心方法 public synchronized V put(K key, V value) { // Make sure the value is not null if (value == null) { throw new NullPointerException(); } // Makes sure the key is not already in the hashtable. Entry<?,?> tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; @SuppressWarnings("unchecked") Entry<K,V> entry = (Entry<K,V>)tab[index]; for(; entry != null ; entry = entry.next) { if ((entry.hash == hash) && entry.key.equals(key)) { V old = entry.value; entry.value = value;//如果key 存在,就替换 return old; } } addEntry(hash, key, value, index);//如果是新k, 就addEntry return null; } */ // 拥有了三个键值对,现在的键值对在内存中 //1.如果该文件没有key 就是创建 //2.如果该文件有key ,就是修改 properties.setProperty("charset", "utf8");//底层就是HashTable properties.setProperty("user", "汤姆");//注意保存时,是中文的 unicode码值 properties.setProperty("pwd", "888888"); //将k-v 存储文件中即可,这里的null代表comments(注释),一般用null即可 properties.store(new FileOutputStream("src\\mysql2.properties"), null);//从内存中写到文件中 System.out.println("保存配置文件成功~"); } }
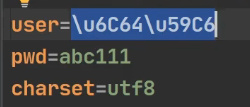
程序执行完毕,查看配置文件时,发现中文变成了unicode码,可以去查询,发现就是汤姆。
9.11 本章作业

public class Homework01 {
public static void main(String[] args) throws IOException {
/**
*(1) 在判断e盘下是否有文件夹mytemp ,如果没有就创建mytemp
*(2) 在e:\\mytemp 目录下, 创建文件 hello.txt
*(3) 如果hello.txt 已经存在,提示该文件已经存在,就不要再重复创建了
*(4) 并且在hello.txt 文件中,写入 hello,world~
*/
String directoryPath = "e:\\mytemp";
File file = new File(directoryPath);
if(!file.exists()) {
//创建
if(file.mkdirs()) {
System.out.println("创建 " + directoryPath + " 创建成功" );
}else {
System.out.println("创建 " + directoryPath + " 创建失败");
}
}
String filePath = directoryPath + "\\hello.txt";// e:\mytemp\hello.txt
file = new File(filePath);
if(!file.exists()) {
//创建文件
if(file.createNewFile()) {
System.out.println(filePath + " 创建成功~");
//如果文件存在,我们就使用BufferedWriter 字符输入流写入内容
BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter(file));
bufferedWriter.write("hello, world~~ 韩顺平教育");
bufferedWriter.close();
} else {
System.out.println(filePath + " 创建失败~");
}
} else {
//如果文件已经存在,给出提示信息
System.out.println(filePath + " 已经存在,不在重复创建...");
}
}
}

public class Homework02 {
public static void main(String[] args) {
/**
* 要求: 使用BufferedReader读取一个文本文件,为每行加上行号,
* 再连同内容一并输出到屏幕上。
*/
String filePath = "e:\\a.txt";
BufferedReader br = null;
String line = "";
int lineNum = 0;
try {
br = new BufferedReader(new FileReader(filePath));
while ((line = br.readLine()) != null) {//循环读取
System.out.println(++lineNum + line);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if(br != null) {
br.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
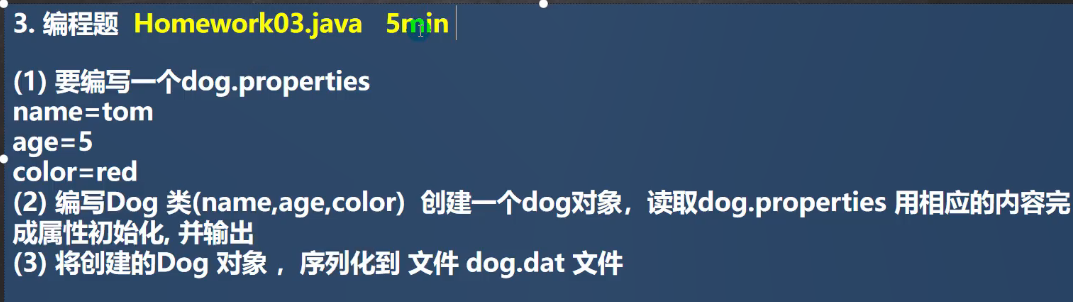
public class Homework03 {
public static void main(String[] args) throws IOException {
/**
* (1) 要编写一个dog.properties name=tom age=5 color=red
* (2) 编写Dog 类(name,age,color) 创建一个dog对象,读取dog.properties 用相应的内容完成属性初始化, 并输出
* (3) 将创建的Dog 对象 ,序列化到 文件 e:\\dog.dat 文件
*/
String filePath = "src\\dog.properties";
Properties properties = new Properties();
properties.load(new FileReader(filePath));
String name = properties.get("name") + ""; //Object -> String
int age = Integer.parseInt(properties.get("age") + "");// Object -> int
String color = properties.get("color") + "";//Object -> String
Dog dog = new Dog(name, age, color);
System.out.println("===dog对象信息====");
System.out.println(dog);
//将创建的Dog 对象 ,序列化到 文件 dog.dat 文件
String serFilePath = "e:\\dog.dat";
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(serFilePath));
oos.writeObject(dog);
//关闭流
oos.close();
System.out.println("dog对象,序列化完成...");
}
//在编写一个方法,反序列化dog
@Test
public void m1() throws IOException, ClassNotFoundException {
String serFilePath = "e:\\dog.dat";
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(serFilePath));
Dog dog = (Dog)ois.readObject();
System.out.println("===反序列化后 dog====");
System.out.println(dog);
ois.close();
}
}
class Dog implements Serializable{
private String name;
private int age;
private String color;
public Dog(String name, int age, String color) {
this.name = name;
this.age = age;
this.color = color;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
", age=" + age +
", color='" + color + '\'' +
'}';
}
}
第十章 网络编程
计算机网络基本知识已经省略
10.1 InetAddress

//1. 获取本机的InetAddress 对象
InetAddress localHost = InetAddress.getLocalHost();
System.out.println(localHost);//DESKTOP-S4MP84S/192.168.12.1
//2. 根据指定主机名 获取 InetAddress对象
InetAddress host1 = InetAddress.getByName("DESKTOP-S4MP84S");
System.out.println("host1=" + host1);//DESKTOP-S4MP84S/192.168.12.1
//3. 根据域名返回 InetAddress对象, 比如 www.baidu.com 对应
InetAddress host2 = InetAddress.getByName("www.baidu.com");
System.out.println("host2=" + host2);//www.baidu.com / 110.242.68.4
//4. 通过 InetAddress 对象,获取对应的地址
String hostAddress = host2.getHostAddress();//IP 110.242.68.4
System.out.println("host2 对应的ip = " + hostAddress);//110.242.68.4
//5. 通过 InetAddress 对象,获取对应的主机名/或者的域名
String hostName = host2.getHostName();
System.out.println("host2对应的主机名/域名=" + hostName); // www.baidu.com
10.2 Socket

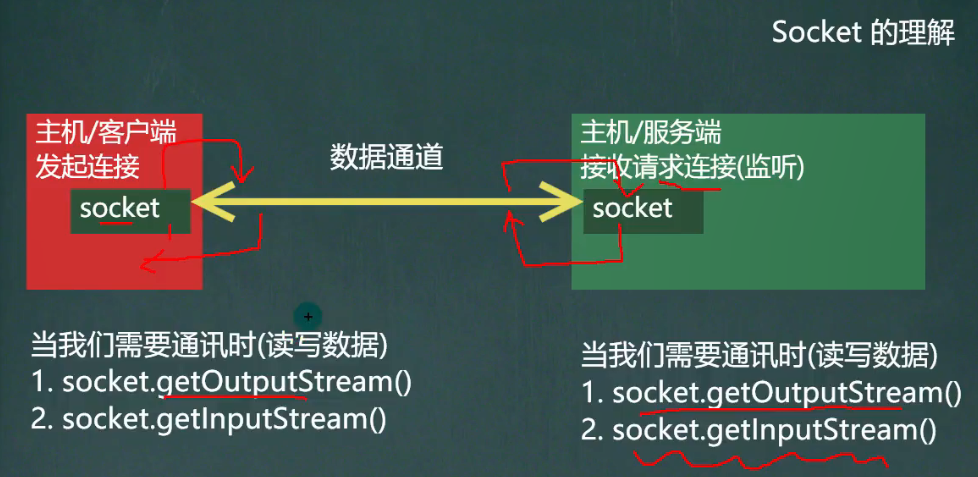
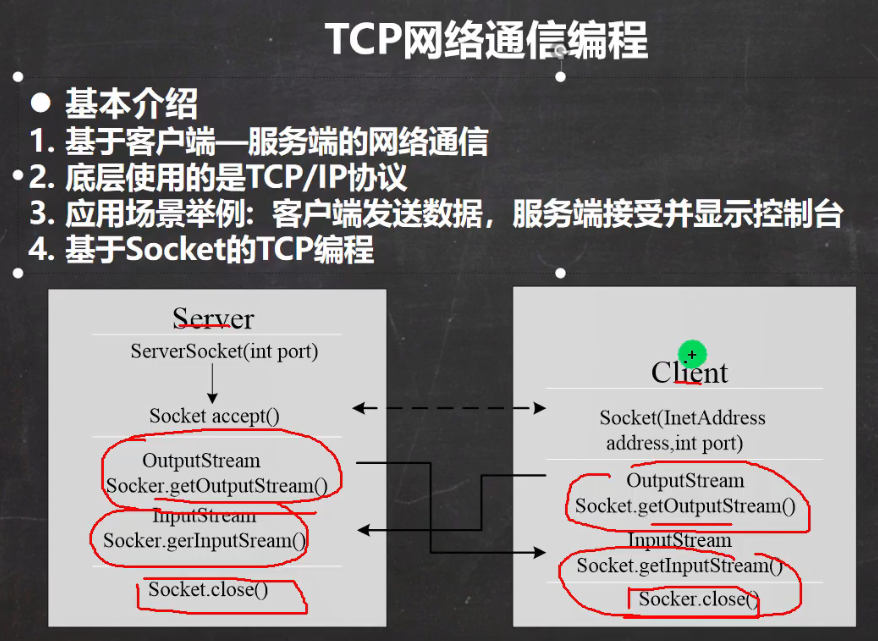
注意:通信结束后,必须手动close,不然可能会导致连接数过多,影响其他连接。
10.3 TCP字节流编程
10.3.1 应用案例1*


服务器端代码:
// 服务器端代码
public class SocketTcpServe01 {
public static void main(String[] args) throws IOException {
//思路
//1. 在本机 的9999端口监听, 等待连接
// 细节: 要求在本机没有其它服务在监听9999
// 细节:这个 ServerSocket 可以通过 accept() 返回多个Socket[多个客户端连接服务器的并发]
ServerSocket serverSocket = new ServerSocket(9999);
System.out.println("服务端,在9999端口监听,等待连接..");
//2. 当没有客户端连接9999端口时,程序会阻塞, 等待连接
// 如果有客户端连接,则会返回Socket对象,程序继续,阻塞结束
Socket socket = serverSocket.accept();//阻塞,accept()方法返回与端口9999建立连接的服务器端socket对象
System.out.println("服务端 socket =" + socket.getClass());
//3. 通过socket.getInputStream() 读取客户端写入到数据通道的数据, 显示
InputStream inputStream = socket.getInputStream();//从通信通道中读取数据
//4. IO读取
byte[] buf = new byte[1024];
int readLen = 0;
while ((readLen = inputStream.read(buf)) != -1) {
System.out.println(new String(buf, 0, readLen));//根据读取到的实际长度,显示内容.
}
//5.关闭流和socket
inputStream.close();//关闭流
socket.close();//关闭当前与端口9999建立连接的通信通道
serverSocket.close();//关闭端口9999
}
}
客户端代码:
// 客户端,发送 "hello, server" 给服务端
public class SocketTcpClient01 {
public static void main(String[] args) throws IOException {
//思路
//1. 连接服务端 (ip , 端口)
//解读: 连接本机的 9999端口, 如果连接成功,返回Socket对象
Socket socket = new Socket(InetAddress.getLocalHost(), 9999);
System.out.println("客户端 socket返回=" + socket.getClass());
//2. 连接上后,生成Socket, 通过socket.getOutputStream()
// 得到 和 socket对象关联的输出流对象
OutputStream outputStream = socket.getOutputStream();//获得建立通信通道的输出流
//3. 通过输出流,写入数据到 数据通道
outputStream.write("hello, server".getBytes());//向建立的通信通道中写入数据
//4. 关闭流对象和socket, 必须关闭
outputStream.close();
socket.close();
System.out.println("客户端退出.....");
}
}
10.3.2 应用案例2*

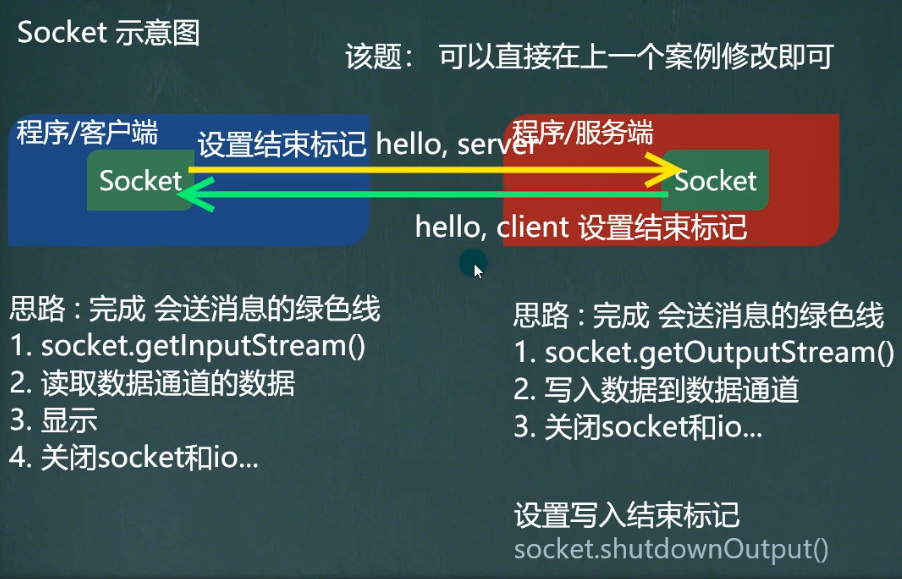
小结:本题可以在上一个案例的基础上进行修改,本案例的最主要的关键点是设置通道写入结束标记,如果不设置的话,会导致通道在等待输出流向其写入数据。
服务器端:
public class SocketTCP02Server {
public static void main(String[] args) throws IOException {
//思路
//1. 在本机 的9999端口监听, 等待连接
// 细节: 要求在本机没有其它服务在监听9999
// 细节:这个 ServerSocket 可以通过 accept() 返回多个Socket[多个客户端连接服务器的并发]
ServerSocket serverSocket = new ServerSocket(9999);
System.out.println("服务端,在9999端口监听,等待连接..");
//2. 当没有客户端连接9999端口时,程序会 阻塞, 等待连接
// 如果有客户端连接,则会返回Socket对象,程序继续
Socket socket = serverSocket.accept();
System.out.println("服务端 socket =" + socket.getClass());
//
//3. 通过socket.getInputStream() 读取客户端写入到数据通道的数据, 显示
InputStream inputStream = socket.getInputStream();
//4. IO读取
byte[] buf = new byte[1024];
int readLen = 0;
while ((readLen = inputStream.read(buf)) != -1) {
System.out.println(new String(buf, 0, readLen));//根据读取到的实际长度,显示内容.
}
//======================新增=============================
//5. 获取socket相关联的输出流
OutputStream outputStream = socket.getOutputStream();
outputStream.write("hello, client".getBytes());
// 设置结束标记
socket.shutdownOutput();//结束输入到通信通道
//======================新增=============================
//6.关闭流和socket
outputStream.close();
inputStream.close();
socket.close();
serverSocket.close();//关闭
}
}
客户端:
public class SocketTCP02Client {
public static void main(String[] args) throws IOException {
//思路
//1. 连接服务端 (ip , 端口)
//解读: 连接本机的 9999端口, 如果连接成功,返回Socket对象
Socket socket = new Socket(InetAddress.getLocalHost(), 9999);
System.out.println("客户端 socket返回=" + socket.getClass());
//2. 连接上后,生成Socket, 通过socket.getOutputStream()
// 得到 和 socket对象关联的输出流对象
OutputStream outputStream = socket.getOutputStream();
//3. 通过输出流,写入数据到 数据通道
outputStream.write("hello, server".getBytes());
//======================新增=============================
// 设置结束标记
socket.shutdownOutput();//输出已结束
//4. 获取和socket关联的输入流. 读取数据(字节),并显示
InputStream inputStream = socket.getInputStream();
byte[] buf = new byte[1024];
int readLen = 0;
while ((readLen = inputStream.read(buf)) != -1) {
System.out.println(new String(buf, 0, readLen));
}
//======================新增=============================
//5. 关闭流对象和socket, 必须关闭
inputStream.close();
outputStream.close();
socket.close();
System.out.println("客户端退出.....");
}
}
10.4 TCP字符流编程


在字符流编程中,此时的结束标志换成了newLine()换行符。
服务器端:
public class SocketTcpServe03 {
public static void main(String[] args) throws IOException {
//思路
//1. 在本机 的9999端口监听, 等待连接
// 细节: 要求在本机没有其它服务在监听9999
// 细节:这个 ServerSocket 可以通过 accept() 返回多个Socket[多个客户端连接服务器的并发]
ServerSocket serverSocket = new ServerSocket(9999);
System.out.println("服务端,在9999端口监听,等待连接..");
//2. 当没有客户端连接9999端口时,程序会阻塞, 等待连接
// 如果有客户端连接,则会返回Socket对象,程序继续,阻塞结束
Socket socket = serverSocket.accept();//阻塞,accept()方法返回与端口9999建立连接的服务器端socket对象
System.out.println("服务端 socket =" + socket.getClass());
// 从客户端读取数据显示在服务器端
//3. 通过socket.getInputStream() 读取客户端写入到数据通道的数据, 显示
InputStream inputStream = socket.getInputStream();//从通信通道中读取数据
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
//4. IO读取
System.out.println("客户端数据:" + bufferedReader.readLine());
// 向客户端传数据
BufferedWriter bufferedWriter = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()));
bufferedWriter.write("这里是服务器端传字符流!");
bufferedWriter.newLine();
bufferedWriter.flush();
//5.关闭流和socket
bufferedWriter.close();
bufferedReader.close();
inputStream.close();//关闭流
socket.close();//关闭当前与端口9999建立连接的通信通道
serverSocket.close();//关闭端口9999
}
}
客户端:
public class SocketTCP03Client {
public static void main(String[] args) throws IOException {
//思路
//1. 连接服务端 (ip , 端口)
//解读: 连接本机的 9999端口, 如果连接成功,返回Socket对象
Socket socket = new Socket(InetAddress.getLocalHost(), 9999);
System.out.println("客户端 socket返回=" + socket.getClass());
//2. 连接上后,生成Socket, 通过socket.getOutputStream()
// 得到 和 socket对象关联的输出流对象
OutputStream outputStream = socket.getOutputStream();
//3. 通过输出流,写入数据到 数据通道, 使用字符流
BufferedWriter bufferedWriter = new BufferedWriter(new OutputStreamWriter(outputStream));
bufferedWriter.write("hello, server 字符流");
bufferedWriter.newLine();//插入一个换行符,表示写入的内容结束, 注意,要求对方使用readLine()!!!!
bufferedWriter.flush();// 如果使用的字符流,需要手动刷新,否则数据不会写入数据通道
//4. 获取和socket关联的输入流. 读取数据(字符),并显示
InputStream inputStream = socket.getInputStream();
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
String s = bufferedReader.readLine();
System.out.println(s);
//5. 关闭流对象和socket, 必须关闭
bufferedReader.close();//关闭外层流
bufferedWriter.close();
socket.close();
System.out.println("客户端退出.....");
}
}
10.5 网络上传文件

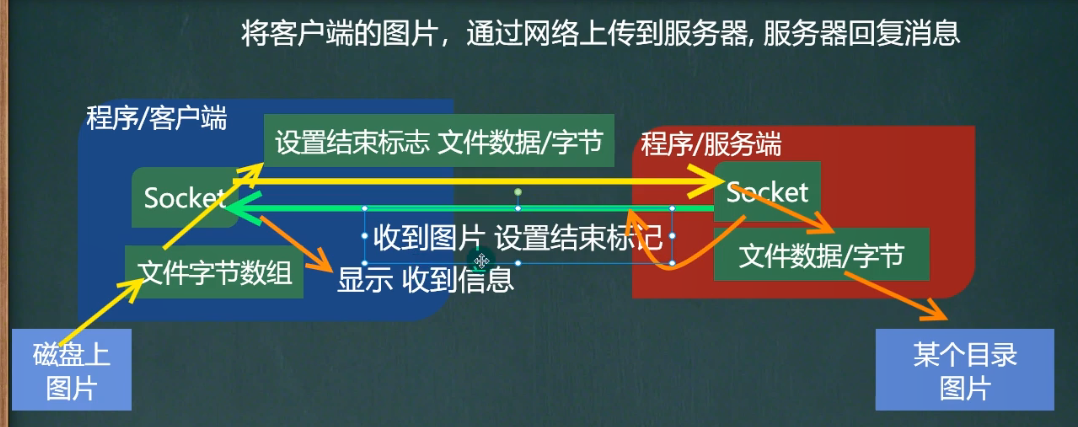
一般来说,当我们写数据完成后的设置结束标记,有两种:
- socket.shutdownOutput();
- 两边设置readLine()方法
服务器代码:
public class TCPFileUploadServer {
public static void main(String[] args) throws Exception {
// 1. 监听本机9999端口
ServerSocket serverSocket = new ServerSocket(9999);
System.out.println("服务器正在监听9999号端口..........");
Socket accept = serverSocket.accept();//阻塞,等待客户端
System.out.println("与客户端连接建立成功!");
// 2. 设置输入流,读取客户端传来的文件数据
BufferedInputStream bufferedInputStream = new BufferedInputStream(accept.getInputStream());
byte[] bytes = StreamUtil.streamToByteArray(bufferedInputStream);//将读取的流转换为byte数组
// 3. 将得到的文件byte数组,写入到指定位置
String destFile = "src\\Lalaland.jpg";
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(new FileOutputStream(destFile));
bufferedOutputStream.write(bytes);//在指定位置写入数据
System.out.println("服务器端:文件写入完毕!");
// 4. 向客户端发出 文件接收成功 的消息
// 通过socket 获取到输出流(字符)
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(accept.getOutputStream()));
writer.write("服务器端已经收到图片了!");
writer.flush();//把内容刷新到数据通道
accept.shutdownOutput();//设置写入结束标记
// 关闭资源
writer.close();
bufferedOutputStream.close();
bufferedInputStream.close();
accept.close();
serverSocket.close();
}
}
客户端代码:
public class TCPFileUploadClient {
public static void main(String[] args) throws Exception {
// 1. 建立与服务器端的连接
Socket socket = new Socket(InetAddress.getLocalHost(), 9999);
System.out.println("与服务器建立成功!");
// 2. 将文件转为byte数组
String filePath = "d:\\LalaLand.jpg";
BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream(filePath));// 获取文件输入流
byte[] bytes = StreamUtil.streamToByteArray(bufferedInputStream);//转为byte数组
// 3. 向socket建立的通道获得输出流,传送文件byte数组
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(socket.getOutputStream());//获得输出流
bufferedOutputStream.write(bytes);//写数据
System.out.println("客户端:文件传送完毕!");
socket.shutdownOutput();//设置写出数据的结束符
// 4. 接收服务器端发来 文件接收成功 的消息
BufferedInputStream bufferedInputStream1 = new BufferedInputStream(socket.getInputStream());// 设置输入流
String s = StreamUtil.streamToString(bufferedInputStream1);
System.out.println(s);
// 关闭资源
bufferedOutputStream.close();//关闭输出流
bufferedInputStream.close();
bufferedInputStream1.close();
socket.close();
}
}
10.6 netstat
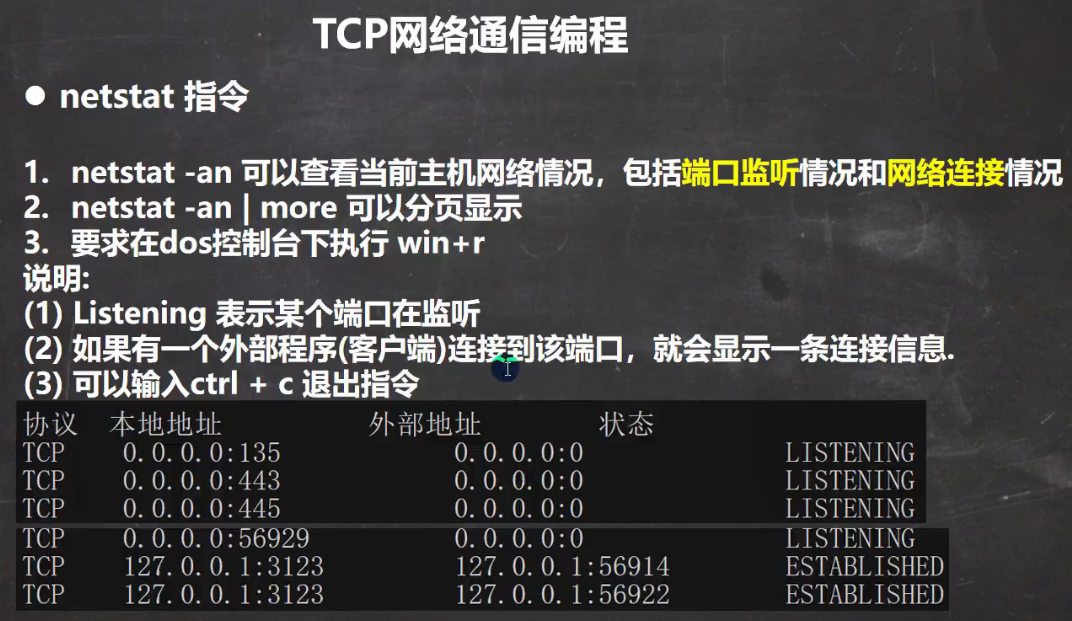
管理员权限下,netstat -anb 可以查看是哪个程序在使用。
10.7 TCP连接的秘密
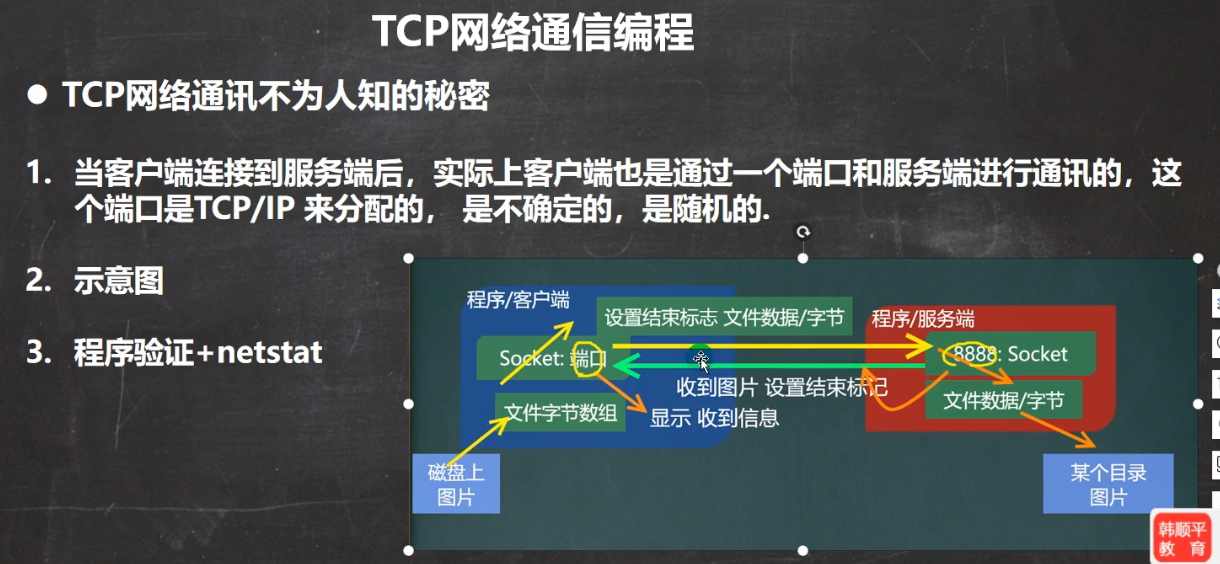
建立连接时,客户端的端口是随机分配的,而服务器端始终是固定。
10.8 UDP编程
10.8.1 UDP原理

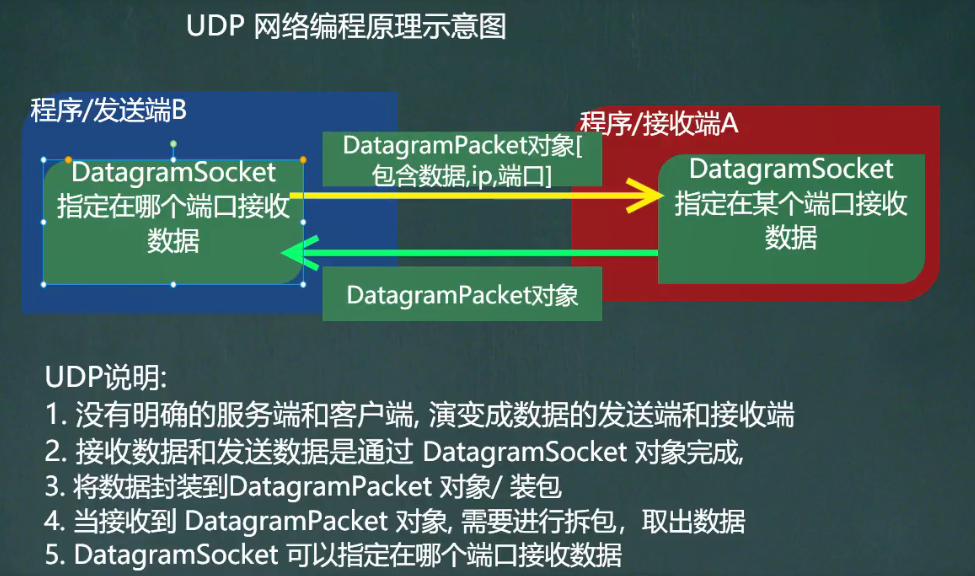
UDP原理的注意事项:
-
UDP建立连接的两端,没有明确的客户端和服务器端,因为接收端也有可能变成发送端,发送端也有可能变成接收端。
-
数据的接发送对象不再是Socket和ServerSocket,而是DatagramSocket。
-
数据需要进行装包和拆包。

上图DatagramPacket构造方法中,可以观察到:
可以指定主机地址和端口号,进行数据打包。
10.8.2 应用案例


服务端A:
public class UDPReceiverA {
public static void main(String[] args) throws IOException {
//1. 创建一个 DatagramSocket 对象,准备在9999接收数据
DatagramSocket socket = new DatagramSocket(9999);
//2. 构建一个 DatagramPacket 对象,准备接收数据
// 在前面讲解UDP 协议时,老师说过一个数据包最大 64k
byte[] buf = new byte[1024];
DatagramPacket packet = new DatagramPacket(buf, buf.length);//接收数据也要进行封装打包
//3. 调用 接收方法, 将通过网络传输的 DatagramPacket 对象
// 填充到 packet对象
//老师提示: 当有数据包发送到 本机的9999端口时,就会接收到数据
// 如果没有数据包发送到 本机的9999端口, 就会阻塞等待.
System.out.println("接收端A 等待接收数据..");
socket.receive(packet);//阻塞等待数据
//4. 可以把packet 进行拆包,取出数据,并显示.
int length = packet.getLength();//实际接收到的数据字节长度
byte[] data = packet.getData();//接收到数据,拆包
String s = new String(data, 0, length);//toString,然后打印
System.out.println(s);
//==============回复信息给B端================
//将需要发送的数据,封装到 DatagramPacket对象
data = "好的, 明天见".getBytes();
//说明: 封装的 DatagramPacket对象 data 内容字节数组 , data.length , 主机(IP) , 端口
packet =
new DatagramPacket(data, data.length, InetAddress.getLocalHost(), 9998);//向9998发送数据
socket.send(packet);//发送
//5. 关闭资源
socket.close();
System.out.println("A端退出...");
}
}
服务端B:
public class UDPSenderB {
public static void main(String[] args) throws IOException {
//1.创建 DatagramSocket 对象,准备在9998端口 接收数据
//注意在UDP连接中,如果在同一台主机上,各个服务端占据属于自己的端口,进行接收发送数据的请求
DatagramSocket socket = new DatagramSocket(9998);
//2. 将需要发送的数据,封装到 DatagramPacket对象
byte[] data = "hello 明天吃火锅~".getBytes(); //
//说明: 封装的 DatagramPacket对象 data 内容字节数组 , data.length , 主机(IP) , 端口
DatagramPacket packet =
new DatagramPacket(data, data.length, InetAddress.getByName("192.168.12.1"), 9999);
socket.send(packet);
//3.====接收从A端回复的信息=================
//(1) 构建一个 DatagramPacket 对象,准备接收数据
byte[] buf = new byte[1024];
packet = new DatagramPacket(buf, buf.length);//packet已经重新引用了
//(2) 调用 接收方法, 将通过网络传输的 DatagramPacket 对象
// 填充到 packet对象
//老师提示: 当有数据包发送到 本机的9998端口时,就会接收到数据
// 如果没有数据包发送到 本机的9998端口, 就会阻塞等待.
socket.receive(packet);//等待数据发到自己这里9998端口
//(3) 可以把packet 进行拆包,取出数据,并显示.
int length = packet.getLength();//实际接收到的数据字节长度
data = packet.getData();//接收到数据
String s = new String(data, 0, length);
System.out.println(s);
//关闭资源
socket.close();
System.out.println("B端退出");
}
}
10.9 本章作业
10.9.1 TCP、UDP

客户端:
public class HW01Client {
public static void main(String[] args) throws IOException {
// 1. 客户端向本机端口9999发送数据,需要先建立连接
Socket socket = new Socket(InetAddress.getLocalHost(), 9999);
System.out.println("客户端与服务器连接建立成功!");
// 2. 获取用户输入
System.out.println("请输入发往服务器的内容:");
Scanner scanner = new Scanner(System.in);
String question = scanner.next();
// 3. 使用包装流进行输出流的封装,对服务器发出消息
BufferedWriter bufferedWriter = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()));
bufferedWriter.write(question);
bufferedWriter.newLine();//结束标志
bufferedWriter.flush();//刷新,确认写入
//4. 接收服务器发来的回复
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
System.out.println(bufferedReader.readLine());
// 5. 关闭资源
bufferedReader.close();
bufferedWriter.close();
socket.close();
}
}
服务器端:
public class HW01Server {
public static void main(String[] args) throws IOException {
// 1. 服务器端在9999端口监听
ServerSocket serverSocket = new ServerSocket(9999);
System.out.println("等待连接........");
Socket sockets = serverSocket.accept();//等待客户端程序
System.out.println("连接建立成功!");
// 2. 服务器端获取客户端发来的内容
// 按照字符流进行传送数据,因此需要使用转换流InputStreamReader将socket的字节流进行转换,最终使用包装流进行操作
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(sockets.getInputStream()));
// 3. 根据客户端发来的内容进行相应处理
// 获取写入流对象
BufferedWriter bufferedWriter = new BufferedWriter(new OutputStreamWriter(sockets.getOutputStream()));
// 进行判断处理
String s = bufferedReader.readLine();
if (s.equals("name")) {
bufferedWriter.write("我是nova");
} else if (s.equals("hobby")) {
bufferedWriter.write("编写Java程序");
} else {
bufferedWriter.write("非法输入");
}
System.out.println("向客户端发送回复完毕!");
bufferedWriter.newLine();//设置结束标志
bufferedWriter.flush();//刷新,确认写入
// 4. 关闭资源
bufferedWriter.close();
bufferedReader.close();
sockets.close();
serverSocket.close();
}
}
-

发送服务端:
public class Homework02SenderB {
public static void main(String[] args) throws IOException {
//1.创建 DatagramSocket 对象,准备在9998端口 接收数据
DatagramSocket socket = new DatagramSocket(9998);
//2. 将需要发送的数据,封装到 DatagramPacket对象
Scanner scanner = new Scanner(System.in);
System.out.println("请输入你的问题: ");
String question = scanner.next();
byte[] data = question.getBytes();
DatagramPacket packet =
new DatagramPacket(data, data.length, InetAddress.getLocalHost(), 8888);
socket.send(packet);
byte[] buf = new byte[1024];
packet = new DatagramPacket(buf, buf.length);
socket.receive(packet);
int length = packet.getLength();//实际接收到的数据字节长度
data = packet.getData();//接收到数据
String s = new String(data, 0, length);
System.out.println(s);
//关闭资源
socket.close();
System.out.println("B端退出");
}
}
接收服务端:
public class Homework02ReceiverA {
public static void main(String[] args) throws IOException {
DatagramSocket socket = new DatagramSocket(8888);
byte[] buf = new byte[1024];
DatagramPacket packet = new DatagramPacket(buf, buf.length);
System.out.println("接收端 等待接收问题 ");
socket.receive(packet);
int length = packet.getLength();//实际接收到的数据字节长度
byte[] data = packet.getData();//接收到数据
String s = new String(data, 0, length);
String answer = "";
if("四大名著是哪些".equals(s)) {
answer = "四大名著 <<红楼梦>> <<三国演示>> <<西游记>> <<水浒传>>";
} else {
answer = "what?";
}
//===回复信息给B端
data = answer.getBytes();
packet =
new DatagramPacket(data, data.length, InetAddress.getLocalHost(), 9998);
socket.send(packet);//发送
socket.close();
System.out.println("A端退出...");
}
}
10.9.2 文件下载
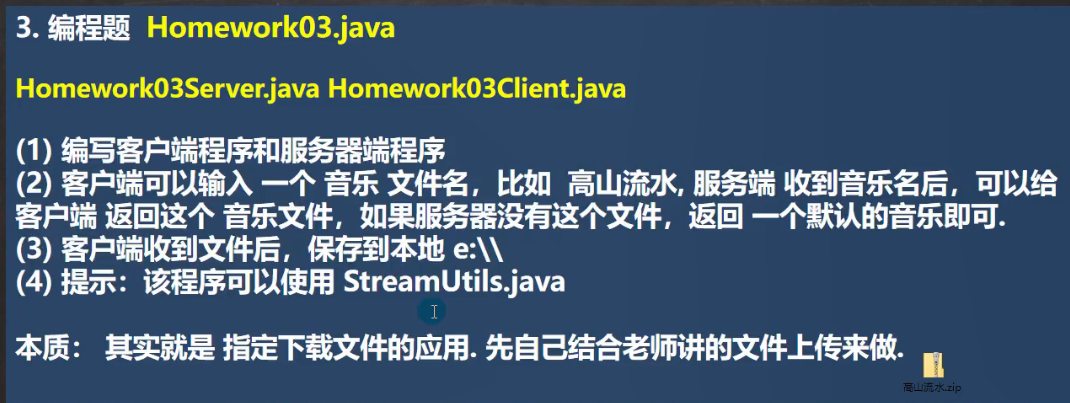
服务器端程序:
public class Homework03Server {
public static void main(String[] args) throws Exception {
//1 监听 9999端口
ServerSocket serverSocket = new ServerSocket(9999);
//2.等待客户端连接
System.out.println("服务端,在9999端口监听,等待下载文件");
Socket socket = serverSocket.accept();//阻塞等待客户端连接
//3.读取 客户端发送要下载的文件名
// 这里老师使用了while读取文件名,时考虑将来客户端发送的数据较大的情况
InputStream inputStream = socket.getInputStream();
byte[] b = new byte[1024];
int len = 0;
String downLoadFileName = "";
while ((len = inputStream.read(b)) != -1) {
downLoadFileName += new String(b, 0 , len);
}
System.out.println("客户端希望下载文件名=" + downLoadFileName);
//老师在服务器上有两个文件, 无名.mp3 高山流水.mp3
//如果客户下载的是 高山流水 我们就返回该文件,否则一律返回 无名.mp3
String resFileName = "";
if("高山流水".equals(downLoadFileName)) {
resFileName = "src\\高山流水.mp3";
} else {
resFileName = "src\\无名.mp3";
}
//4. 创建一个输入流,读取文件
BufferedInputStream bis =
new BufferedInputStream(new FileInputStream(resFileName));
//5. 使用工具类StreamUtils ,读取文件到一个字节数组
byte[] bytes = StreamUtils.streamToByteArray(bis);
//6. 得到Socket关联的输出流
BufferedOutputStream bos =
new BufferedOutputStream(socket.getOutputStream());
//7. 写入到数据通道,返回给客户端
bos.write(bytes);
socket.shutdownOutput();//很关键.
//8 关闭相关的资源
bis.close();
inputStream.close();
socket.close();
serverSocket.close();
System.out.println("服务端退出...");
}
}
客户端程序:
public class Homework03Client {
public static void main(String[] args) throws Exception {
//1. 接收用户输入,指定下载文件名
Scanner scanner = new Scanner(System.in);
System.out.println("请输入下载文件名");
String downloadFileName = scanner.next();
//2. 客户端连接服务端,准备发送
Socket socket = new Socket(InetAddress.getLocalHost(), 9999);
//3. 获取和Socket关联的输出流
OutputStream outputStream = socket.getOutputStream();
outputStream.write(downloadFileName.getBytes());
//设置写入结束的标志
socket.shutdownOutput();
//4. 读取服务端返回的文件(字节数据)
BufferedInputStream bis = new BufferedInputStream(socket.getInputStream());
byte[] bytes = StreamUtils.streamToByteArray(bis);
//5. 得到一个输出流,准备将 bytes 写入到磁盘文件
//比如你下载的是 高山流水 => 下载的就是 高山流水.mp3
// 你下载的是 韩顺平 => 下载的就是 无名.mp3 文件名 韩顺平.mp3
String filePath = "e:\\" + downloadFileName + ".mp3";
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(filePath));
bos.write(bytes);
//6. 关闭相关的资源
bos.close();
bis.close();
outputStream.close();
socket.close();
System.out.println("客户端下载完毕,正确退出..");
}
}
10.10 项目-多用户通信系统
看老韩PDF
