今日内容回顾7.13
迭代取值与索引取值的差异
索引取值
-
优点:可以随意并反复的获取任意数据值。
-
缺点:针对无序的容器类型无法使用索引取值。
示例:
l1 = [11, 22, 33, 44, 55] print(l1[0]) print(l1[1]) print(l1[0])
迭代取值
-
优点:提供了一种不依赖索引取值的通用方式。
-
缺点:取值一旦开始只能依次往下取值不能重复取之前的值。
示例:
l1 = [11, 22, 33, 44, 55] res = l1.__iter__() print(res.__next__()) print(res.__next__()) print(res.__next__())
模块的简介
什么是模块
模块可以看成是一些功能的结合体
使用模块就相当于拥有了结合体内的所有功能
模块的分类
-
内置模块
解释器自带的模块,通过import加上模块名先将其导入后通过模块名加点的方式直接调用其内部代码。
列如:
import time # 导入模块关键字、模块名 time.time # 调用模块内的代码 -
第三方模块
别人写的模块,存在于网络之上,使用前需要提前下载好。
-
在自定义模块
自己编写代码存储在py文件中,文件名就是后续导入的模块名
模块名不能跟解释器中的内置模块名起冲突。
-
模块的表现形式
- py文件(又被称之为模块文件)
- 含有多个py文件的文件夹(按照模块功能的不同划分不同的文件夹储存)
- 已被编译为共享库或DLL的c或C++扩展(了解)
- 使用C编写并链接到python解释器的内置模块(了解)
导入模块的俩种句式
导入模块句式1
import + 模块名
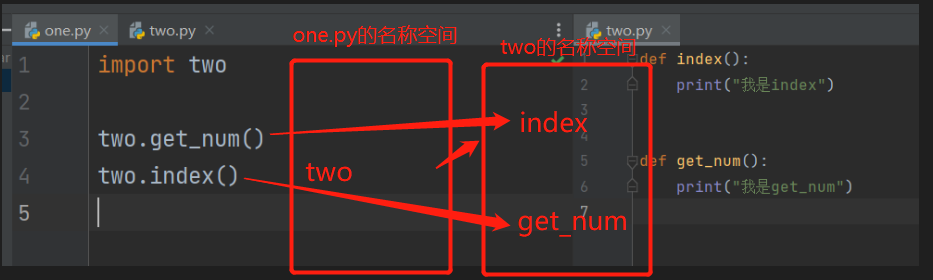
首先执行文件为one.py,需要导入的是two.py
- 在执行文件内运行代码,先产生执行文件one.py的名称空间,将里面的名字存入one.py的名称空间内
- import two导入two.py文件,
- 产生被导入文件的名称空间后,并运行文件内的代码将产生的名字储存在该名称空间内
- 使用two.index()就是向two.py名称空间索要名字index调用。
导入模块的句式2
from (模块名) import (模块名称空间内的名字)
指明道姓的导入,可以简单的理解为我只需要从模块名称空间内拿到我指定的名字其他的不需要。
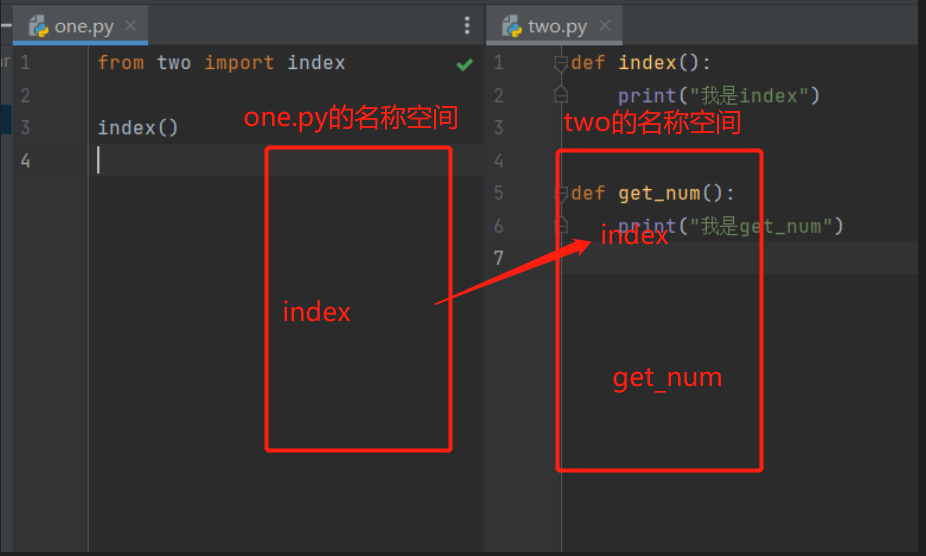
-
首先执行one.py文件,产生一个名称空间,
-
然后执行被导入two.py文件,产生一个名称空间,并运行代码将名字存入名称空间
-
在执行文件中获取到指定的名字 指向被导入文件的名称空间
俩种方式的差异
-
第一种 import one
-
优点
通过one点的方式可以使用到模块内所有的名字,而且不会和执行文件起冲突
-
缺点:
one什么都可以点,有时候并不想让所有的名字都能被使用。
-
-
第二种 from one import index,get_num
-
优点
指明道姓的使用指定的名字,并且不需要用模块名加点的方式调用
-
缺点
名字及其容易产生冲突(绑定关系被修改)
-
模块的其他知识
-
起别名
多个模块文件名相同,比如多人写的模块需要结合到一起使用
但模块名字又是相同的这个时候可以考虑到使用起别名这个方法。
from one import index as one_index from two import index as two_index print(one_index) print(two_index) -
导入多个指定名字
import time, sys, os # 上述导入方式建议多个模块功能相似才能适应 不相似尽量分开导入 import time import os import sys from md import money, read1, read2 # 上述导入方式是推荐使用的 因为多个名字出自于一个模块文件 -
全部导入
需求:需要使用模块名称空间中很多名字 并且只能使用from...import句式 from md import * # *表示所有 针对*号的导入还可以控制名字的数量 在模块文件中可以使用__all__ = [字符串的名字]控制*能够获取的名字
循环导入问题
-
什么是循环导入
可以理解为俩个文件彼此相互导入彼此, 这样导入容易出现报错现象,使用彼此的名字可能是在没有准备好的情况就使用了。 如何解决循环导入保存现象,彼此在使用彼此名字之前 先准备好。 循环导入将来尽量避免出现!!! 如果真的避免不了 就想办法让所有的名字在使用之前提前准备好。
判断文件类型
学习完模块之后 以后我们的程序运行起来可能涉及到的文件就不止一个
所有的py文件中都自带一个__name__内置名
当py文件是执行文件的时候 __name__的结果是__main__
当py文件是被导入文件的时候 __name__的结果是模块名(文件名)
__name__主要用于开发模块的作者测试自己的代码使用
if __name__ == '__main__':
当文件是执行文件的时候才会执行if的子代码
上述判断一般只出现整个程序的启动文件中
ps:在pycharm中可以直接编写main按tab键自动补全
模块的查找顺序
1.导入一个文件 然后在导入过程中删除该文件 发现还可以使用
"""
1.先去内存中查找
2.再去内置中查找
3.再去sys.path中查找(程序系统环境变量) 下面详细的讲解
"""
import md
import time
time.sleep(15)
print(md.money)
2.创建一个跟内置模块名相同的文件名
# import time
# print(time.time())
from time import name
print(name)
ps:创建模块文件的时候尽量不要与内置模块名冲突
3.导入模块的时候一定要知道谁是执行文件
所有的路径都是参照执行文件来的
import sys
sys.path.append(r'D:\pythonProject\day22\xxx')
import mdd
print(mdd.name)
"""
1.通用的方式
sys.path.append(目标文件所在的路径)
2.利用from...import句式
起始位置一定是执行文件所在的路径
from xxx import mdd
"""

 浙公网安备 33010602011771号
浙公网安备 33010602011771号