
java并发编程的艺术(四)---ConcurrentHashMap原理解析
本文来源于翁舒航的博客,点击即可跳转原文观看!!!(被转载或者拷贝走的内容可能缺失图片、视频等原文的内容)
若网站将链接屏蔽,可直接拷贝原文链接到地址栏跳转观看,原文链接:https://www.cnblogs.com/wengshuhang/p/10240309.html
由来:
我们都知道,hashmap是线程不安全的,所以在多线程情况下无法使用这个数据结构,hashTable是线程安全的,但是它的底层实现只是在hashmap基础上进行了
synchronized的加锁,这种加锁方式效率低下,所以就有了ConcurrentHashMap的出现。
数据结构:
ConcurrentHashMap是由Segment数组(继承了锁ReentrantLock)跟HashEntry数组结构构成的,默认情况下拥有16个Segment数组(可以看成hashmap),每个segment数组里都有一个hashEntry数组,也就是数据+链表/红黑树结构,这点跟hashmap就是一样的了。当要修改hashEntry数组中的元素时候,就需要获取这个segment的锁,从而实现分段锁机制,利用分段锁来提高锁的效率。
笔者阅读到这里时候,发现 JDK1.8源码跟书上所介绍的内容有些不一样了,查阅资料才发现,1.8已经做了一些比较大的改动。
jdk1.8: JDK1.8的实现已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作,整个看起来就像是优化过且线程安全的HashMap,虽然在JDK1.8中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本。
写到这里,我发现有篇博客写的很好,直接转载了
ConcurrentHashmap原理链接:https://www.cnblogs.com/wengshuhang/articles/10243204.html
虽然人家写的好,但是重点的地方我还是自己亲手再写一遍吧,加深印象:
常量设计:
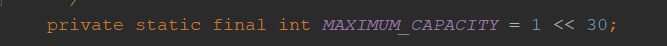 node数组的最高容量2^30,
node数组的最高容量2^30,
 存放node数组的对象。
存放node数组的对象。
其他常量跟hashmap倒是差不多, 初始默认容量都为16,加载因子是0.75, 链表转红黑树的阈值是8 , 树转链表的阈值是 6
 控制标识符,用来控制table的初始化和扩容的操作,不同的值有不同的含义。
控制标识符,用来控制table的初始化和扩容的操作,不同的值有不同的含义。
源码:
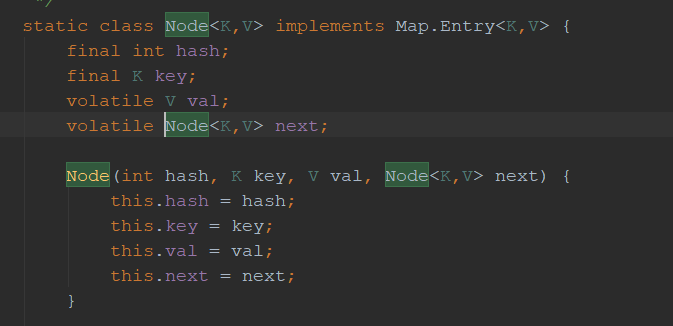
node数组,点进去看node就是个简单的链表,但是只能读取,不允许修改

TreeNode:TreeNode继承与Node,但是数据结构换成了二叉树结构,它是红黑树的数据的存储结构,用于红黑树中存储数据,当链表的节点数大于8时会转换成红黑树的结构,他就是通过TreeNode作为存储结构代替Node来转换成黑红树源代码如下

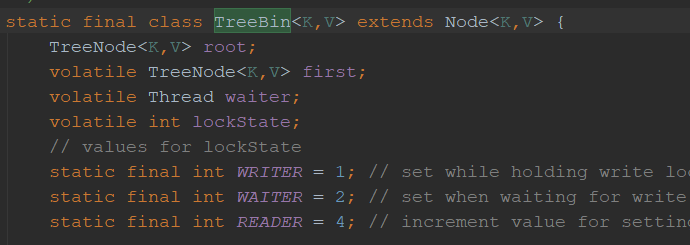
TreeBin从字面含义中可以理解为存储树形结构的容器,而树形结构就是指TreeNode,所以TreeBin就是封装TreeNode的容器,它提供转换黑红树的一些条件和锁的控制,部分源码结构如下
我们接下来看看concurrentHashmap的最常用的put,get操作。首先,concurrentHashmap的初始化操作并不会实例 map中的各个对象,它属于懒加载的类型,就像单例模式,当真正要用到的时候才会去初始化类中的各个对象。
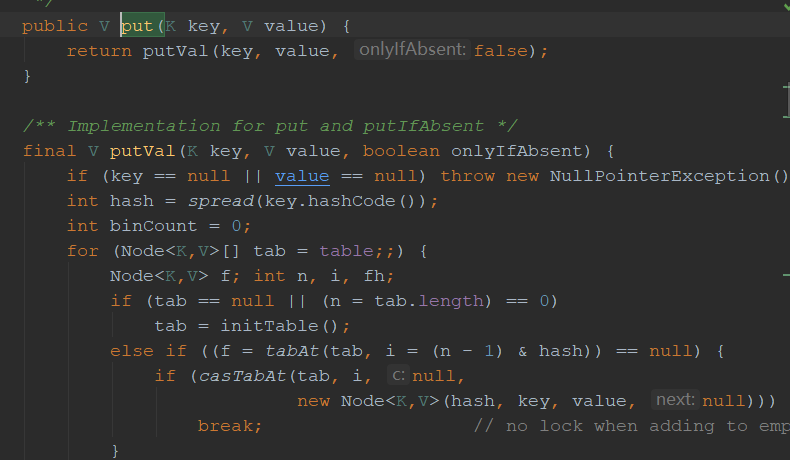

我们能看到 第一个判断,倘若没有 实例tab ,便去初始化table initTable(),,若i位置没有数据则直接无锁插入。initTable中的代码主要就是初始化map类中的table参数跟sizeCtl参数(这两个参数上文有介绍)

其次验证node的hash值(f.hash == noved),若需要扩容则扩容。
若不满足上诉条件则最后进行synchronized加锁操作,对链表或红黑树的头个节点进行加锁,这样就达到了分段式加锁的最初目的,从而抛弃了segment的锁。然后再验证数据结构是链表还是红黑树分开处理。
借原文归纳总结一番

看完感觉最厉害的核心就是当出现同步状态时候,可以调用多个线程一起去并发扩容,通过标志位advance跟CAS插入来保证多个工作线程来一起进行数组的复制扩容,从而节约了计算机的线程资源,不得不佩服jdk的大牛们的思想,在底层就做了这么好的优化。
接下来我们看看链表是怎么转化为红黑树的,当链表长度大于8时,就会转化为红黑树。
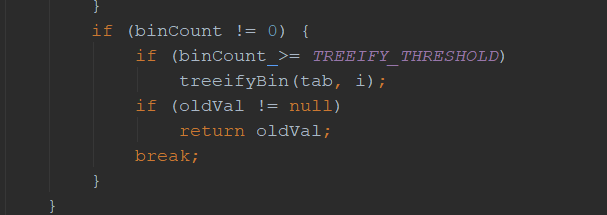
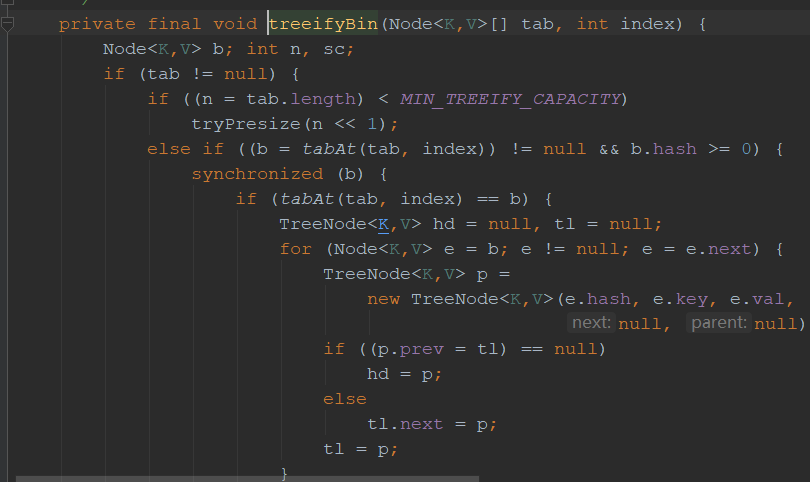
而当数组长度不大于64时候,不进行数据的转换,而是进行了数组的扩容操作,因为当容量变大之后,hash冲突也就自然少了,这个阈值扩容可以减少hash冲突,不必要去转红黑树。
而get的操作比较简单
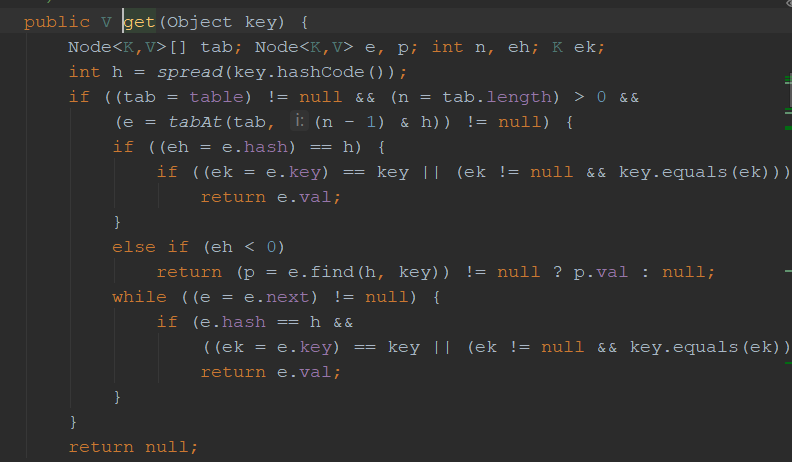

最后不得不说一句,原文作者写的真是太好了,推荐大家看一遍原文,我这边记录的比较不完整。
总结:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号