
java IO流学习
本文来源于翁舒航的博客,点击即可跳转原文观看!!!(被转载或者拷贝走的内容可能缺失图片、视频等原文的内容)
若网站将链接屏蔽,可直接拷贝原文链接到地址栏跳转观看,原文链接:https://www.cnblogs.com/wengshuhang/p/10133020.html
之前的工作很少使用io,就算用了一两次也只是用完就完了。没有系统地去整理io的整体与结构,现在回来补坑。
首先,io分为最常见的字节流跟字符流,
区别:
字节流单位是1byte,字符流则是2btye,区别就这些,字符流主要是用在文本上的,比如汉字,需要两位才能表示一个汉字,其中还包括着汉字的编码。
io流分类:
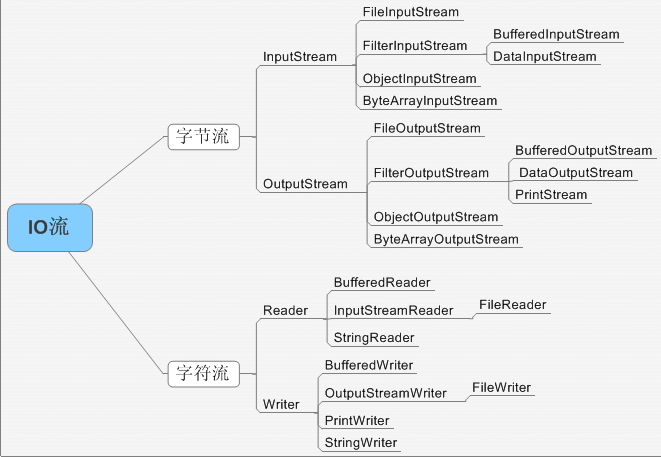
按照流是否直接与特定的地方(如磁盘、内存、设备等)相连,分为节点流和处理流两类。
节点流:可以从或向一个特定的地方(节点)读写数据。如FileReader
处理流:是对一个已存在的流的连接和封装,通过所封装的流的功能调用实现数据读写。
如BufferedReader。处理流的构造方法总是要带一个其他的流对象做参数。一个流对象经过
其他流的多次包装,称为流的链接。
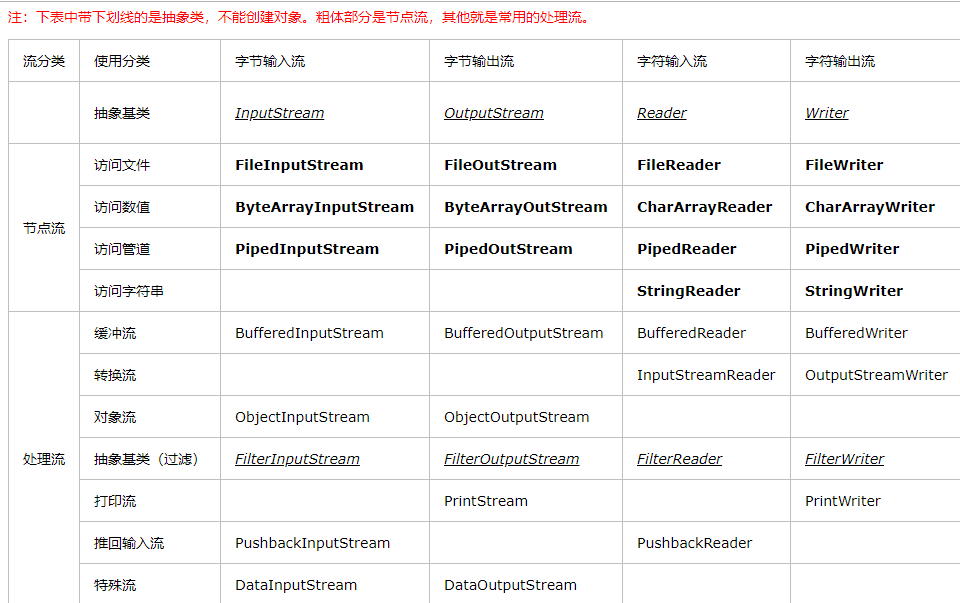
我们一般比较常用的就file跟buffer类,当字符流与字节流之间需要转换时,可以使用InputStreamReader跟OutputStreamReader。
类结构与源码:
用idea可以看到
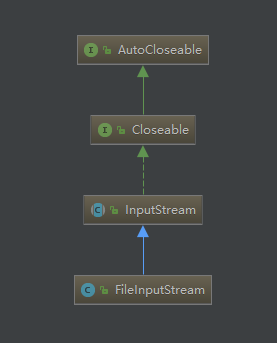
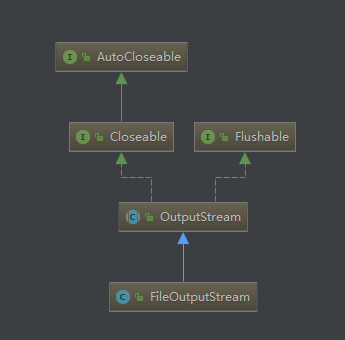
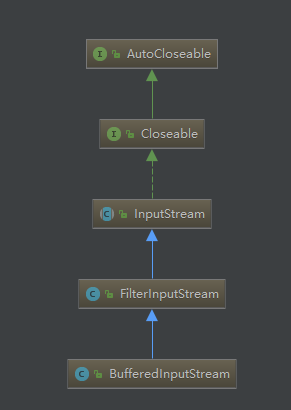
字符流都是继承InputStream跟OutputStream的,
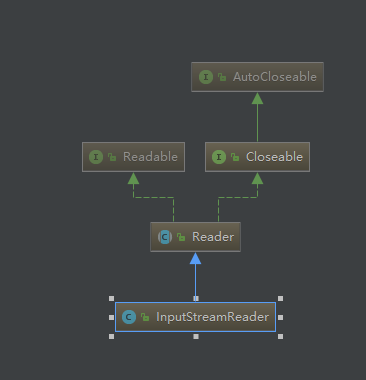
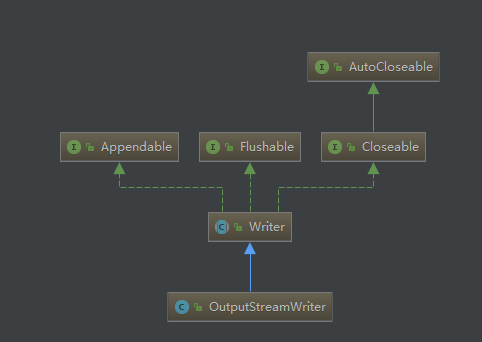
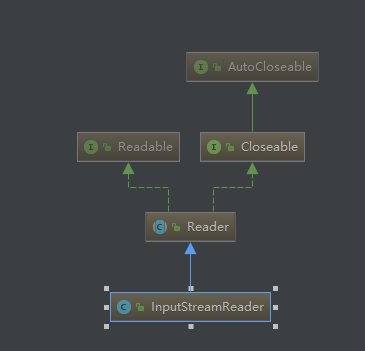
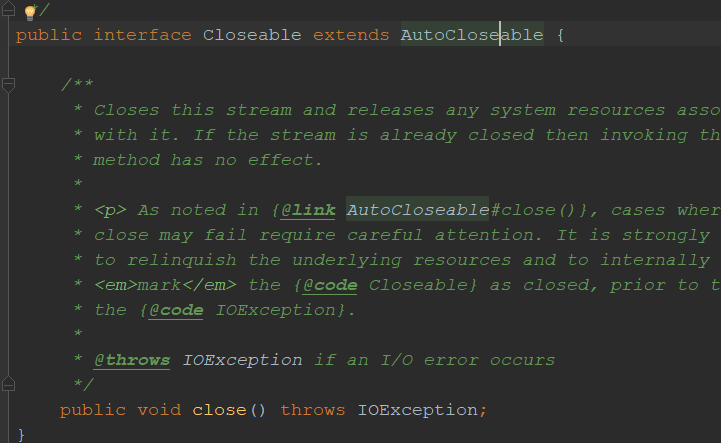
而字符流跟转换流是继承reader跟wirter的,他们的顶层都是实现Closeable跟AutoCloseable接口的。
而点开看这两个接口就只有一个方法。close()关闭流
jdk1.7之后closeable方法继承了AutoCloseable,在try(定义流){}中定义流就不用再去手动写代码close了
那我们接下来看看最主要的io流read()方法跟write()方法的实现吧
字符流中方法跟字节流中大同小异,只是一个参数是byte[],一个参数是char[]而已。我们看看字节流的就好了:
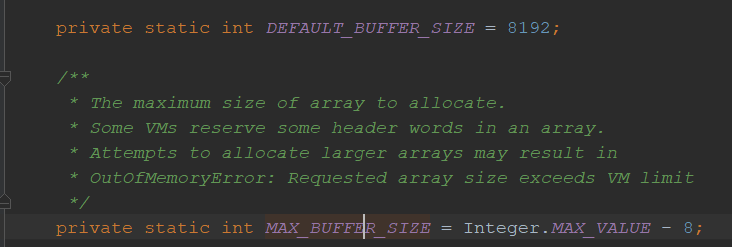
能看到默认的字节长度为8192,最大值是max_value - 8
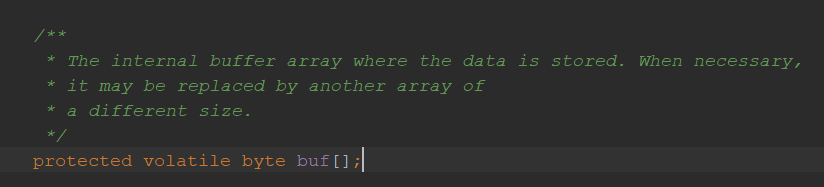
存放字节的数组。
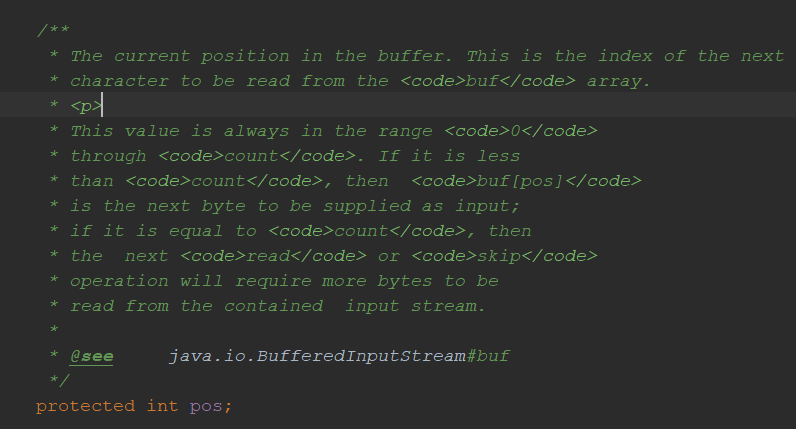
记载下一个目标的索引

两个构造方法,第一个只是调用了第二个 8192的byte[]数组
这里说明一下,IO流是典型的装饰模式,我们可以随意转换流的类型,从而扩展流的功能,主要功能是这个构造方法,调动父类的构造方法,将原来流存储,当实现功能时候,也是用原来流来实现。

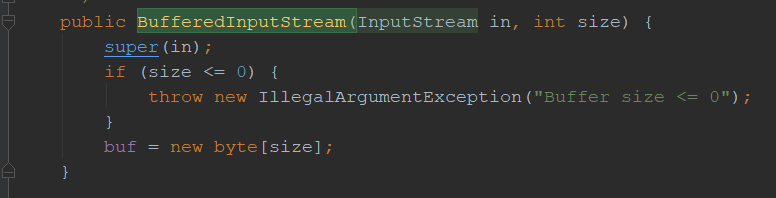
只是初始化了buf数组。
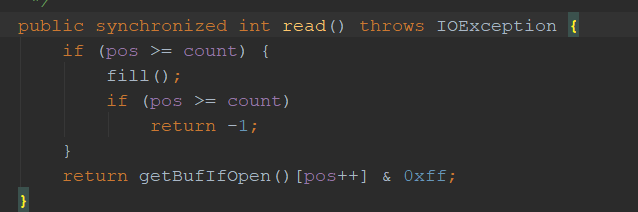
read方法,调用了fill()方法然后再校验一次当前值时候大于最大值,fill()方法可能是清空的操作,当byte[]数组用完了,就读下一组,当没有下一组则返回-1结束了。
/**
* Fills the buffer with more data, taking into account
* shuffling and other tricks for dealing with marks.
* Assumes that it is being called by a synchronized method.
* This method also assumes that all data has already been read in,
* hence pos > count.
*/
private void fill() throws IOException {
byte[] buffer = getBufIfOpen();
if (markpos < 0)
pos = 0; /* no mark: throw away the buffer */
else if (pos >= buffer.length) /* no room left in buffer */
if (markpos > 0) { /* can throw away early part of the buffer */
int sz = pos - markpos;
System.arraycopy(buffer, markpos, buffer, 0, sz);
pos = sz;
markpos = 0;
} else if (buffer.length >= marklimit) {
markpos = -1; /* buffer got too big, invalidate mark */
pos = 0; /* drop buffer contents */
} else if (buffer.length >= MAX_BUFFER_SIZE) {
throw new OutOfMemoryError("Required array size too large");
} else { /* grow buffer */
int nsz = (pos <= MAX_BUFFER_SIZE - pos) ?
pos * 2 : MAX_BUFFER_SIZE;
if (nsz > marklimit)
nsz = marklimit;
byte nbuf[] = new byte[nsz];
System.arraycopy(buffer, 0, nbuf, 0, pos);
if (!bufUpdater.compareAndSet(this, buffer, nbuf)) {
// Can't replace buf if there was an async close.
// Note: This would need to be changed if fill()
// is ever made accessible to multiple threads.
// But for now, the only way CAS can fail is via close.
// assert buf == null;
throw new IOException("Stream closed");
}
buffer = nbuf;
}
count = pos;
int n = getInIfOpen().read(buffer, pos, buffer.length - pos);
if (n > 0)
count = n + pos;
}
留着以后再看吧。
再看看wrtie(x,x,x)方法

前边只是检验异常,后边调用了write(int)方法
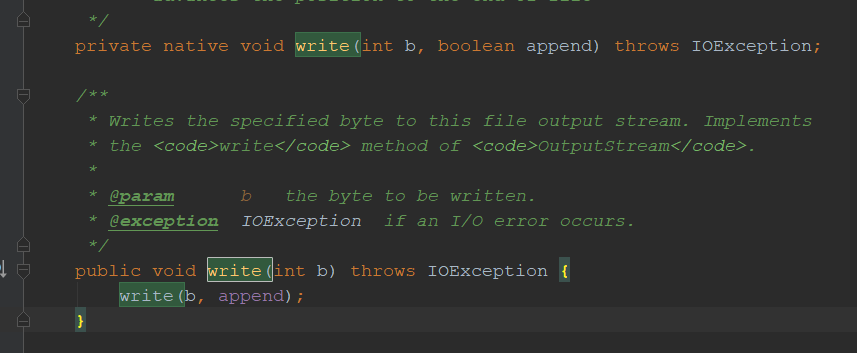
点进去我们可以看到wirte方法有个native的修饰符,这说明底层实现是用C来实现的了,是交给系统做的了,这里就不深究了,不是不看,我们看了C,C底层是汇编,汇编底层是二进制,我们精力有限稍微了解一下就好了,不可能面面俱到。
还有带有缓冲流(buffer)时候要注意flush,使用任何流完后要关闭流。
PS:有些流在源码中close方法中做了flush所以不会丢失,但是有些流没有,所以一致还是加上吧。
如果是文件读写完的同时缓冲区(上边的buf数组)刚好装满 , 那么缓冲区会把里面的数据朝目标文件自动进行读或写 , 这种时候你直接调用close()方法不会出现问题 ; 但是如果文件在读写完成时 , 缓冲区没有装满 , 就直接调用close()方法 , 这个时候装在缓冲区的数据就不会自动的朝目标文件进行读或写 , 从而造成缓冲区中的这部分数据丢失 , 所以这个是时候就需要在close()之前先调用flush()方法 , 手动使缓冲区数据读写到目标文件. 举个例子: 如果一个文件大小是20kb , 我们的缓冲区大小是15kb , 如果Close()方法之前没有先调用flush()方法 , 那么这个时候剩余的5kb数据就会丢失 .

