第二次作业
| 这个作业属于哪个课程 | 至诚软工实践F班 |
|---|---|
| 这个作业要求在哪里 | 第二次作业-个人编程 |
| 这个作业的目标 | 培养良好编码习惯,并通过抓包工具分析post、get协议,并模拟请取数据对进行json解析 |
| Github 地址 | https://github.com/WeZhengTing/uml-homework02 |
1.必做题:朴朴商品信息获取
(1)准备工作阶段
-
一、软件安装
-
二、环境搭建与需求分析,解题思路描述。
-
1.选取语言与工具及理由:
Python:在大家目前学习的c,java,python中个人认为python是功能行强,方面广,最方便上手的语言,基本语法会基本就没问题了。
PyCharm:纯粹是因为我个人用的习惯,导入包时候没有的会自己下载。
小蓝鸟:是在移动端比较方便的抓包工具,可以指定抓包,小窗口操作。
fidder:很全面的抓包工具,配合模拟器也能够很快完成。这次作业推荐下载PC端微信然后进入朴朴小程序抓包。
-
2.实现目标效果与需求分析:
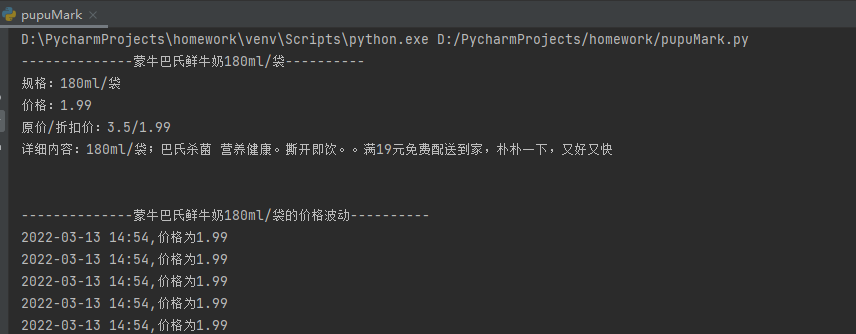
- 我们的目标是能够爬取商品的名字,规格,当前价格,市场价格,详细信息等信息形成如下图的文字输出
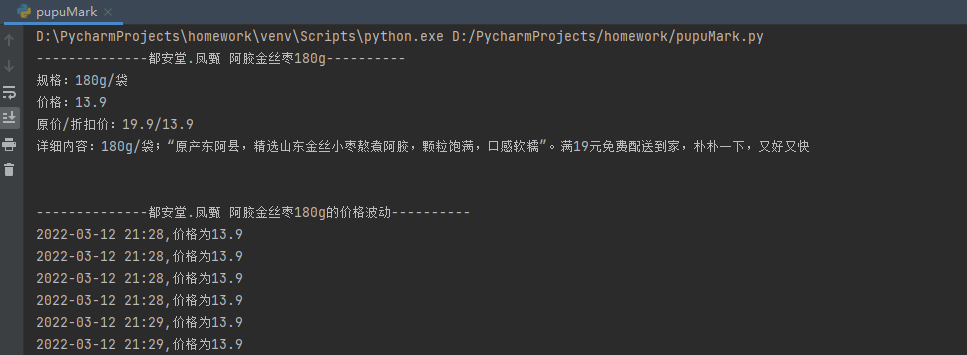
1.所以我们至少要实现能得到商品的名字,规格,当前价格,市场价格,详细信息。
2.能够得到实时价格。
3.考虑到商品下架,不存在的输出提示。
- 我们的目标是能够爬取商品的名字,规格,当前价格,市场价格,详细信息等信息形成如下图的文字输出
-
(2)功能实现阶段
-
一、抓包分析
-
1.抓取需要的链接:
我们使用fidder抓包,大家可以想想页面的参数不可能不变的,是实时更新的。他其实就是根据不同的参数实现回传数据的不同。大家应该能发现我们需要信息的返回链接是https://j1.pupuapi.com/client/product/storeproduct/detail/7c1208da-907a-4391-9901-35a60096a3f9/b3fc4708-3f1d-412a-8d18-efc4b6951fa7我们经过多次实验可以看出前面大家都是一样的,最后的7c1208da-907a-4391-9901-35a60096a3f9/b3fc4708-3f1d-412a-8d18-efc4b6951fa7是商品id,通过修改商品id可以实现得到不同商品的信息。
-
2.商品id正确时信息分析:

通过链接得到上图显示信息,可以清晰的看到商品的各种信息。
name:商品名
spec:商品规格
price:商品当前价格
market_price:商品市场价格
share_content:商品详细信息 -
3.商品id错误时信息分析

可以看到提示已经下架。
-
4.设计实现过程
综上所述,打算通过两个函数实现代码功能
pupuMessage(productId)实现通过商品ID得到商品各种信息
now_price(productId)实现通过商品ID得到商品实时价格
-
-
二、代码实现
-
1.得到链接反馈
大家可以看看视频学习
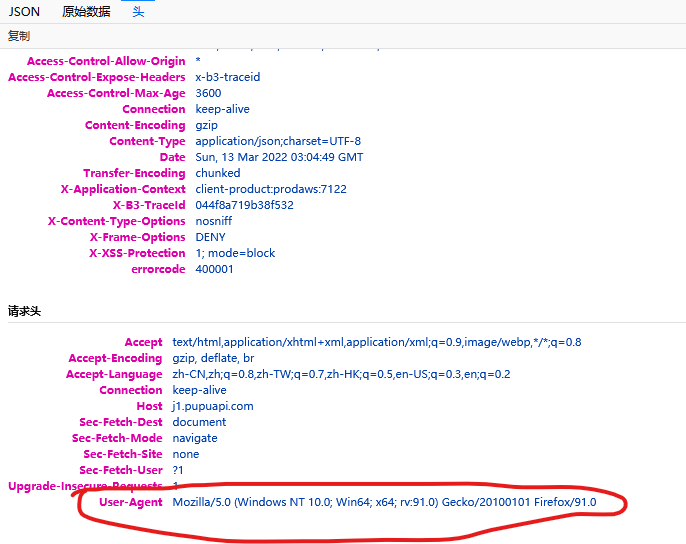
大家抓包时候会发现前面有表明get或者post方法,我们这次是get,所以使用requests.get(url, headers="User-Agent中的内容")得到信息反馈。User-Agent按F12然后查看头,在最下面的就是,这是标识你的访问设备信息。
-
2.提取自己需要的信息
正则表达式或json解析 (ps:json不会的去学一下)
# 正则表达式re.fandall(r,'需要的前面文子':(.*?)"需要的后面文子" ,查找的来源)[第几个] # 得到商品名字 name = re.findall(r'name":"(.*?)",', res.text)[0] # 得到商品规格 spec = re.findall(r'spec":"(.*?)",', res.text)[0] # 得到商品当前价格 price = re.findall(r'price":(.*?),', res.text)[0] price = str(int(price) / 100) # 得到商品市场价格 market_price = re.findall(r'market_price":(.*?),', res.text)[0] market_price = str(int(market_price) / 100) # 得到商品市场详细信息 share_content = re.findall(r'share_content":"(.*?)",', res.text)[0]
#(2)json解析提取 jsonshopping = json.loads(res.text) # res.encoding="utf-8" # 得到商品名字 name = jsonshopping['data']['name'] # 得到商品规格 spec = jsonshopping['data']['spec'] # 得到商品当前价格 # price = re.findall(r'price":(.*?),', res.text)[0] price = str(int(price) / 100) # 得到商品市场价格 # market_price = re.findall(r'market_price":(.*?),', res.text)[0] market_price = str(int(market_price) / 100) # 得到商品市场详细信息 share_content = jsonshopping['data']['share_content']-
最终实现代码
点击查看代码
import json from time import strftime, sleep import requests import re def pupuMessage(productId): try: url = "https://j1.pupuapi.com/client/product/storeproduct/detail/" + productId head = { # headerUser-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36' } res = requests.get(url, headers=head) jsonshopping = json.loads(res.text) # res.encoding="utf-8" # 得到商品名字 # name = re.findall(r'name":"(.*?)",', res.text)[0] name = jsonshopping['data']['name'] # 得到商品规格 # spec = re.findall(r'spec":"(.*?)",', res.text)[0] spec = jsonshopping['data']['spec'] # 得到商品当前价格 # price = re.findall(r'price":(.*?),', res.text)[0] price = jsonshopping['data']['price'] price = str(int(price) / 100) # 得到商品市场价格 # market_price = re.findall(r'market_price":(.*?),', res.text)[0] market_price = jsonshopping['data']['market_price'] market_price = str(int(market_price) / 100) # 得到商品市场详细信息 # share_content = re.findall(r'share_content":"(.*?)",', res.text)[0] share_content = jsonshopping['data']['share_content'] print("--------------" + name + "----------") print("规格:" + spec) print("价格:" + price) print("原价/折扣价:" + market_price + "/" + price) print("详细内容:" + share_content) print("\n\n--------------" + name + "的价格波动----------") except: url = "https://j1.pupuapi.com/client/product/storeproduct/detail/" + productId head = { # headerUser-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36' } res = requests.get(url, headers=head) errmsg = re.findall(r'errmsg":"(.*?)"', res.text)[0] print(errmsg) def now_price(productId): try: while (1): url = "https://j1.pupuapi.com/client/product/storeproduct/detail/" + productId head = { # headerUser-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36' } res = requests.get(url, headers=head) price = re.findall(r'price":(.*?),', res.text)[0] price = str(int(price) / 100) #获取时间 nowTimeAndPrint = strftime('%Y' + '-' + '%m' + '-' + '%d' + ' %H:%M,价格为' + price) print(nowTimeAndPrint) #休眠6秒 sleep(6) except: print("进程结束") if __name__ == '__main__': productId = "7c1208da-907a-4391-9901-35a60096a3f9/44e7652b-a90e-4328-a89f-74471de7e218" pupuMessage(productId) now_price(productId)
-
(3)作业提交阶段
-
一、GitHub推送
-
1.git提交,git代码参考
-
2.使用专业版PyCharm的git提交
-
3.精益求精,自己多改改,代码迭代优化下
-
-
二、运行结果图
-
三、后续完善优化
- 商品价格检测时间太短,时间跨度大一点。最好使用数据库保存数据。
- 商品更新太快,商品下架很快,当前还没有好的思路。就做了个返回商品下架信息。
2.选做题:知乎收藏夹
(1)准备工作阶段
- 一、环境搭建与需求分析,解题思路描述。
- 1.环境与工具:
环境就是与朴朴超市一样,工具用Fidder:考虑到知乎有网页端,不用如朴朴超市一样要热点或者弄虚拟机,模拟器抓包。在PC端fidder的便利性,强大性就体现出来了。
浏览器强烈推荐火狐:控制台是中文,json看的特别舒服。 - 2.解题思路:
首先观察知乎个人首页,能发现有主收藏夹标题以及其主链接。然后点击主收藏夹能跳转看见主收藏夹里的收藏贴标题与其子链接。那思路就很清晰了,我们只要能获取主收藏夹标题与链接,然后再获取其收藏贴标题与子链接就行了。
- 1.环境与工具:
(2)功能实现阶段
- 一、抓包分析
-
1.抓取需要的链接:
首先,知乎我们直接到收藏界面就能得到自己的收藏夹链接是https://www.zhihu.com/people/shuai-qi-66-47/collections,这时候可以用正则直接抓取主文件夹名与链接,不会正则的选下一步。
然后我们使用fidder抓包,打开菜单栏Decode,点击,fidder有个搜索功能,直接搜索主文件夹名字,能看见https://www.zhihu.com/api/v4/people/shuai-qi-66-47 /collections?include=data%5B%5D.updated_time%2Canswer_count%2Cfollower_count%2Ccreator%2Cdescription%2Cis_following%2Ccomment_count%2Ccreated_time%3Bdata%5B%5D.creator.vip_info&offset=0&limit=20返回json,这个用json解析也很方便。抓包完一定要把fidder关掉!!!
下一步就是分析主收藏夹里收藏的贴子的链接可以由头部https://www.zhihu.com/api/v4/collections/,中间是一窜数字,尾部固定为:/items?offset=0&limit=20构成的链接返回的信息里有子链接与标题。这个建议另外写一个函数通过这链接得到子链接与标题。
-
2.最终实现代码
点击查看代码
import json import requests import re def request_url(userName): url = 'https://www.zhihu.com/people/' + userName + '/collections' head = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:91.0) Gecko/20100101 Firefox/91.0' } res = requests.get(url, headers=head) #收藏夹的名字数组 name = re.findall(r'"noreferrer noopener">(.*?)</a>', res.text) #收藏夹链接数组 href = re.findall(r'href="/collection(.*?)"', res.text) for i in range(0, len(name)): print("收藏夹名:"+name[i]) href_head = 'https://www.zhihu.com/api/v4/collections' #构造子链接 url_collection = href_head +href[i]+'/items?offset=0&limit=20' sonTitleAndUrlByHref(url_collection) #通过子链接得到子文件的链接与标题 def sonTitleAndUrlByHref(href): try: head = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:91.0) Gecko/20100101 Firefox/91.0' } res = requests.get(href, headers=head) titlesAndUrl = re.findall(r'NORMAL",(.*?)","question', res.text) for i in range(0,len(titlesAndUrl)): #得到链接 url=re.findall(r'rl":"(.*?)","created_time',titlesAndUrl[i]) #得到标题 title = re.findall(r'title":"(.*)', titlesAndUrl[i]) print(title+url) except: return 0 if __name__ == '__main__': # 我的用户名 userName = "shuai-qi-66-47" request_url(userName)
-
(3)作业提交阶段
-
一、GitHub推送
-
1.git提交,git代码参考
-
2.使用专业版PyCharm的git提交
-
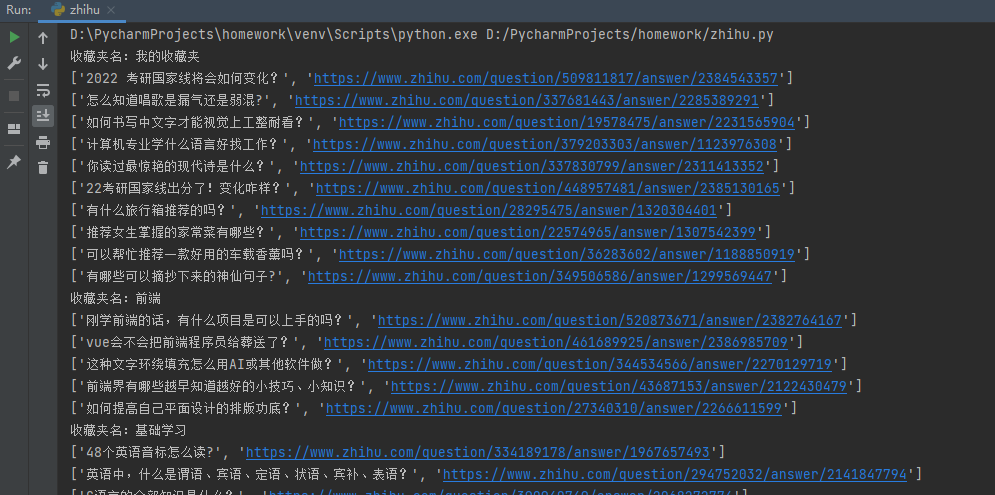
3.运行效果展示
-
-
二、后续完善优化
- 1.知乎用户名生成规则不是很了解,如果有朋友知道希望留言下,后续继续修改。(目前按照个人观察发现初始是汉字拼英+数字,或者就是纯数字,后期可以自己修改,但是还是对其初始生成规则感兴趣)。之前是因为说想爬别人的,发现昵称与用户名有关,现在发现能改用户名价值就低了,研究看看能不能通过手机号或者邮箱来爬。
- 2.可以尝试本地记录存储,但是现在流行云盘,还没有接触,看看能不能记录上传到云盘上。
3.选做题:拉勾网
努力了被封号了emmmm猝
总结
这次作业很好的锻炼了我的各方面能力。在开始搭建的过程,时间花的比较久,参考CSDN与博客园里的帖子,大家可能也会发现我们会出现不同的报错,网络上没有解决方案,别急慢慢来,问问同学,助教和老师,你遇到的问题别人也会遇到,互相沟通交流团队协作能让自己更快成长。提倡大家把遇到的问题或者难题发出来,然后集思广益挑选合适的方案解决。
这次作业下来,发现get或者post都一样是不安全的,数据资源没有安全。以前的学习中只知道get不安全,特意去看了看反爬虫,常见的有:
1.IP限制(但是配置IP池好像就被解了);
2.验证码;
3.登录限制;
4.隐藏验证;
还有许多,以后搭建网站要考虑下安全性,有能力的情况下多考虑一下数据加密,资源隐藏的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号