不严谨的概念解释----深度学习
目前AI人工智能盛行,深度学习四个字经常出现在人们茶余饭后的聊天里,但究竟深度学习的原理和机制是什么?作为一只涉坑未深的小牛犊,在学习和了解这个东西一段之后,想在这里介绍什么是深度学习,旨在以浅显但可能不太准确的语言描述,让身边的人都能大概明白它到底做了一件什么样事情,以增加聊天资本。而且,一个事物的特点和表现,都是由它的基本属性所决定的,以后自己如果遇到什么瓶颈,回头来看看它的基本机制,也许可以找到答案。
一句话概括:
深度学习就是在搭建一个神经网络后,往该网络喂大量的数据对其进行训练,训练到后面,你再给它扔一个数据,它就会告诉你这数据的类别(比如西瓜还是苹果)、或者一个你想让它预测的数值(比如明天的股票价格),模型好的话你发现它还挺准的。
详细介绍:
想要比较好地理解上面的一句话概括,主要理解几个问题:
1、搭建的是什么样的神经网络?
2、给它扔的数据是什么样的数据?
3、怎么样进行训练?
4、训练好了后怎么用它预测?
下面逐一进行阐述:
1、搭建的是什么样的神经网络?
神经网络大概长这个样子:
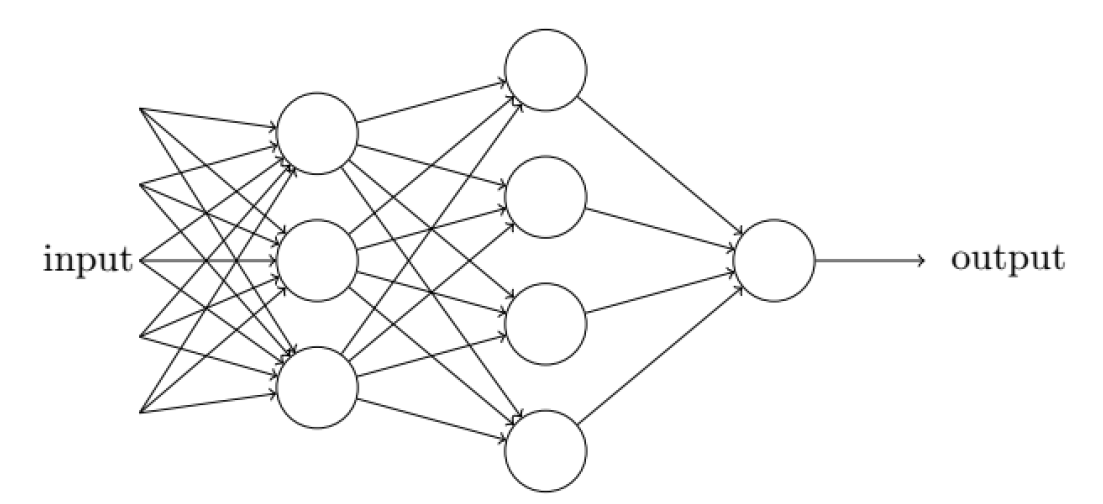
图里面:input是指输入数据,带箭头的连线是一些数字,圆形的节点是对数字进行转化,output是它的输出---也是一个数字。也就是说,模型在接收了输入的数据input后,那些连线就是把这个数据进行了加减乘除平方,节点就是对它进行log取对数之类的变化,最后再得到输出output再给出去,大概就是下面这个图:
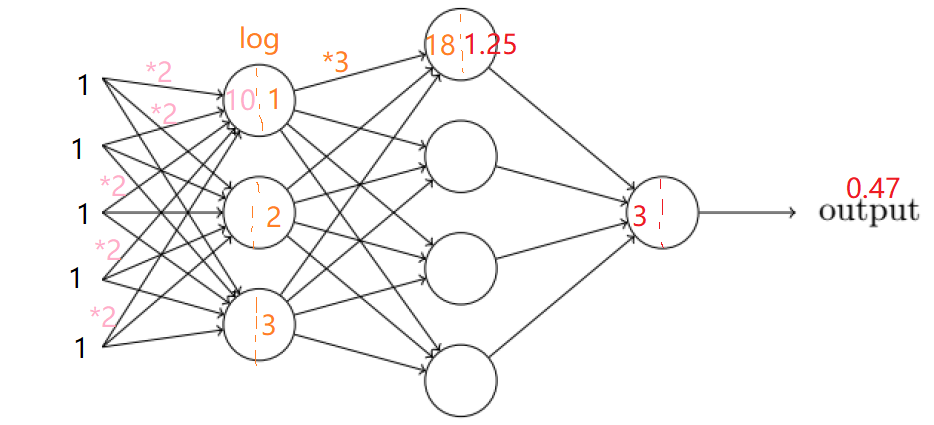
最左边的【1,1,1,1,1】,这5个1就是你的输入,假如最左边的连线都是将数据进行乘2操作,那到第一排圈圈(神经元)上面第一个圈的数就会是5个1*2加起来,就是10,然后它不是简单就把10给到下一层,它还做了一些非线性转换,比如这个例子里的log,log(10)=1,也就变成了1。后面的也是一样,假如第一层的三个圈输出分别是【1,2,3】,到第二排圈圈的最上面那个数就是18,做了非线性转换log后就是1.25。最后一排圆圈假如得到的是3,同样做个非线性转换就可以得到0.47,然后就把0.47这个数给出去了。
神经网络,大概就是这样子的一个东西:最左边是输入数据,连线是加减乘除变换,圈圈 代表神经元来接收线性变换后的数,再把它做一个非线性变换激活给到下一层。
也就是说,假如你输入一个1,经过一个神经网络就类似于经过了一个数学公式变换,log(1*2)这样子,当然,这里的2是连线上的数字,这个数字我们其实是不知道的,这个数字也是网络后面训练要调的数字,我们就把它当成是一个未知数x,这样子的话,假如你输入一个1,那么你会得到一个log(1*x)。神经网络就做了这么一件事而已。
至于这里面的输入数据,它可能是很复杂的一些矩阵,黑色线上这些乘2乘3这些变换就可以看成是矩阵相乘,非线性转换不仅仅是log,可能是一些复杂的sigmoid函数,relu函数这些。但这些不管,它们只是形式变复杂了而已,本质没有变,它就是做了一些加减乘除这些线性变换和一些类似log取对数这种曲线变换。
2、训练数据是怎么样的
输入数据就是1,2,3这些数字,毕竟计算机只识得这些数字(这种说法不严谨,但过过过)。一般是会以矩阵的形式输入进去。常处理的数据类型有文字和图像两种,这里说明一下文字和图像都是什么样的数据。
首先是图像,图像本身是由一些像素点组成,像素点的颜色在RGB的表示里面,就是3个数字,比如(255,255,255)就表示这个图像点是白色。一张图像可能有上万个像素点,每个像素点都是由3个RGB数字叠加起来的,所以图像就是一个三维矩阵,它的形状类似于是32*32*3,这里32是指图像的长和宽上的像素点个数,你也可以理解为就是图像的长和宽,3就是上面说的RGB三通道。所以,一张图像不需要经过处理,它本来就是一堆数字,大概是下面这个样子(一个3*3*3的图像):

对于文本的话,比如【我帅吗?】这三个字加一个问号,它是要先查字典,这个字典是预先准备好的文本,里面包含了全部的汉字和标点符号。比如‘我’这个字在字典里是第49个,帅是第512个,吗是第1150个,问号在字典里是第5个,那么【我帅吗?】就会转化成【49,512,1150,5】这样子的数据。
这个数据经过神经网络的变换后,它还是会得到一个数,这个数就是512,神经网络就是只负责给返回512,然后计算机再拿512这个数字去查字典,得到‘帅’这个字,再输出。所以当你问一个聊天机器人说“我帅吗?‘,它内部大概经过的流程就是这样子,流程走完了再回答你:’帅‘。这个过程,以现在的计算能力,一秒种不到就做完了。
3、训练模型
如果你理解了第一点的内容(毕竟我还标了红色),那么你不难想到,模型的训练过程,其实就是调神经网络那些连线上的数字的过程。所以,这里要把上面那个图拿来再说明一下:

想象计算机就是上面那个小孩,他在最左边的时候,拿到了你给他的一张苹果的图片【1,1,1,1,1】,他拿着这些数字,跑过一条黑线就把这些数字按黑色的连线和神经元上的加减乘除等进行变换,同时跑过所有连线和神经元,一直跑到最右边,他发现他手上的数字变成了0.47,然后你其实已经准备好答案在最右边这里了,他过来对答案,发现答案是5(5是你提前设置的,5代表苹果,答案是苹果)。于是此时他知道了一个事情——0.47这个数小了。所以他按原路跑回去,在跑回去的路上,把连线上的数字给改了,往能够使得最后输出的0.47变大的方向上去改。这么一改,下次再给模型传苹果的图片,【1,1,1,1,1】的时候,他跑到最右边的时候,可能得到的就是3或者3.5这样子的数字了。当然这样子还是小了,就还是再跑回去把连线上的数字调一下,调到让这个数变得更大一些的方向上去改。当然如果得到的是6,比答案5还要大了,那么就反过来调。来来回回,每次给他传不同的数据和答案,每次都按这个靠近答案的方向去调,传几十万个图像和答案给模型后,让模型调个几十万次后,你再给他一组数字,假如答案是10(你提前设置了10代表梨)的话,它从最左边跑到最右边后,它可以得到大概9.98这样子的数,然后在你最先设置好的【1到10】里面选了一个最接近的10,计算机再转成‘这张图像是梨’的结果给你。此时精度达到了最高水准,同时满足了我们的要求,就当模型已经训练好了,可以拿去预测了。
当然实际的模型可能很深,可能会有好几十层,而连线上的这些要调的变量的数量很多,也就是参数量也很大,可能在几十万个参数到上亿个参数不等。
在数学上,调参数的方向就是按损失函数的导数变小的方向去调。损失函数就是答案和小孩报的数的差值的平方。比如上面说的转换后log(1*x),答案是5,那么损失函数就是y=(log(1+x)-5)^2,这个损失函数有点像是一个二次函数,最小值是0,而调就是把未知数向最低点调,使得损失函数值最小,导数值变为0。

通常数据在被转换的过程,我们称之为特征提取的过程。比如你传入一张猴子的图像,它会提取到毛、尾巴、眼睛这些特征。当然模型和计算机并不知道它在做这些事情,人类其实也是根据理解说他在做特征提取的这个事情,实际上是不是,人类也说不清楚。对于计算机而言,它只知道你给他图片,它就把数字转化转化再给你一个数字而已。只不过,在经过前面的训练过程后,它会把猴子的图片里一些比较重要的数据放大出来,经过训练后的模型的连线上的参数就是已经调整到可以突显这一部分数据对最张答案的影响,所以模型才可以让输出比较接进答案。
所以,训练到最后,模型达到这样子的效果:当你传入猴子的图片时,猴子特有的特征的那部分数据就会在转换地过程中被放大,导致模型得到的结果就是猴子,当传入狮子时,狮子的专有特征比如它的毛的形态这些部分的数字,就会被放到比较重要的位置,导致模型得到的结果是狮子。所以,人们常说神经元网络做了一个特征提取的作用。
要注意到,训练数据有一个特点:既要包括问题,也要包括答案。比如你给他传了一张西瓜的图片的同时,要给他传西瓜的答案。西瓜就是这张图像的标签。这些标签往往是需要人力去标注的。而且,如果你的训练数据里只有十种水果,那么这个网络得到的结果就只会是这十种水果中的一种,所以,你再给他传一张苹果的图片,他可能可以得到’这张图像是苹果’的结果,但如果你给他传一张猴子的图片,他可能 还是会得到‘这是一个苹果’的结果。也就是说,每个神经网络都有它的适用范围,这个范围就是由你的训练数据的范围所决定的。
还有,图上这个小孩回来奔跑和计算调整的快慢,就是代表了算力的大小。现在跑一个来回的计算,可能只要0.1秒。所以网络结构本身其实并不复杂,关键还是看算力。深度学习网络能够快速发展最大的推动力就是计算机算力的大幅提升。要不然,如果你问一个聊天机器人:现在几点了,它要过五分钟才回答你:现在是8点整,那估计也没人去研究神经网络了。
4、模型预测
模型训练好后,预测就非常简单了。比如你想知道一张图片的水果是什么水果,直接把图像传给模型,模型就会给你一个水果类别的结果。因为模型训练好后,连线上的数字就不变了,测试时来任何数据 都是经过过相同的变换然后得到一个结果,至于这个结果是否准确,那就要靠测试者自己来评判了。如果想知道它的测试准确率,那就让计算机记录下它每次预测的结果,再让它和答案再对比一下,计算一下比值就得到准确率了。一般来说,现在能用的模型的准确率都是90%以上,而且越来越高。
至此,深度学习神经网络的基本原理就介绍完了。
第一天听到深度学习神经网络原理的,后面的,可以不看了其实。
----------------------------------------------------------------------------------------------华丽的分割线------------------------------------------------------------------------------------------------------------------------------------------------------------------------
其它东西:
1、目前深度学习的研究和改进点:
目前关于深度学习网络的论文很多,目的都是为了提高模型的准确率,这里大概介绍一下他们的研究点
(1)研究损失函数,比如用绝对值损失、交叉熵损失、二进制损失,或者在损失函数里加一些约束条件,让模型在训练的时候更严苛。
(2)研究学习率或梯度的改变方式,也就是会影响小孩每次调连线上的数字的幅度,刚开始可能一下调了10,连线上的数字由2变成了12,到后面慢慢的学习率最小,一次只调1,7就调成8这样子
(3)研究神经元的激活函数,也就是非线性转换的函数,有GELU、RELU、PRELU、sigmoid、tanh、maxout各种
(4)研究数据增强,10张图片变成100张图片,增加训练数据量
(5)研究防止模型过拟合的方法,比如输入过来有5个数,我随机找三个数进行相加,而不是5个数相加,下次再找另外 三个数,这样子可以学习到有些神经元并不重要,而且可能去掉反而对结果有好处。
(6)增加模型深度的方法:把转换后的数据 和转换前的数据再加回来,我们称之为残差网络,让模型知道,有时候,整个层神经元都不要,可能对模型结果反而好。
(7)研究一下图像卷积的各种卷来卷去的操作,自然语言处理的时序网络、注意力机制、自注意力机制
(8)研究一下图像的方法在自然语言处理的应用,再研究一下自然语言处理的方法在图像中的应用
(9)研究一下怎么用少量的带 标签的数据 或者根本就没有标签的数据 ,去训练 一个模型,人称无监督学习,或者半监督学习。
(10)研究强化学习,也是因为不想打标签。让一个训练得比较好的大的模型,去做老师,这个模型给的答案就给小模型去学习,以此达到师带徒共同学习大量数据的目的。
(11)研究一下如何减少脱发,如何治疗颈椎病、鼠标手、如何逐步向送外卖转型。
2、深度学习神经元网络以后的发展
正如开篇所说,一个事物的特点和表现,都是由它的基本属性所决定的。
这样子的神经元网络,导致了他有一个特点——莫名其妙。目前所使用的网络都是具有一定的经验意义在里面,你在用模型之前 ,你并不敢断言这个模型一定好,而是跑了训练 数据 后,发现它效果确实不错,然后才自己再做了一番自己的解析,比如说他引入了什么什么信息,再加入了一些什么什么机制,让模型学习到了什么什么。然而真实的情况是不是这样子,不好说。而且对于特定的数据,到底应该构建一个多少层,每层多少个神经元的网络才是科学合理有效的,没有人能给出答案。目前就是研究人员自己搭个10层或者12层都跑一下,发现12层效果好,就拿12层的网络结果去发表论文。所以,有人提出,神经元网络的再进一步发展,需要靠自然科学的发展,从数学或生物学或者其它学科的角度,去研究和证明它里面的作用机理并建立科学的理论体系。
目前,神经元网络结构根本已经到达一个瓶颈,也有可能由于整个网络结构的局限性,导致这种神经元网络结构可能会被它的网络结构完全替代,神经元网络结构退出历史舞台。
嗯,还是考虑一下怎么转做送外卖吧!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号