
结对第二次—文献摘要热词统计及进阶需求
作业情况
• 课程名称:软件工程1916|W(福州大学)
• 作业要求:结对第二次—文献摘要热词统计及进阶需求
• 结对学号:041602421 翁昊 | 221600432 邱志勇
• 作业目标:
一、基本需求:实现一个能够对文本文件中的单词的词频进行统计的控制台程序。(完成)
二、进阶需求:在基本需求实现的基础上,编码实现顶会热词统计器。(未完成)
##分工 翁昊:完成了部分代码(行数计算,以及单词爬取与排序函数)的编写和调试和博客的编写 邱志勇:完成了部分代码的编写(字符数计算,以及修改行数计算,以及单词爬取与排序函数)和调试和博客的编写,同时也完成了测试和代码嵌入的部分内容
##作业重要内容 • 作业完成工具:vs 2017& github • 博客编辑器: MARKDOWN • PSP:文末 • github: [https://github.com/teamwengqiu/PairProject1-C](https://github.com/teamwengqiu/PairProject1-C)
##需求 (一)WordCount基本需求 实现一个命令行程序,不妨称之为wordCount。 统计文件的字符数: • 只需要统计Ascii码,汉字不需考虑 • 空格,水平制表符,换行符,均算字符
统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
英文字母: A-Z,a-z
字母数字符号:A-Z, a-z,0-9
分割符:空格,非字母数字符号
例:file123是一个单词,123file不是一个单词。file,File和FILE是同一个单词
统计文件的有效行数:任何包含非空白字符的行,都需要统计。
统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
按照字典序输出到文件result.txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
输出的单词统一为小写格式
输出的格式为
characters: number
words: number
lines: number
<word1>: number
<word2>: number
(二)WordCount进阶需求
新增功能,并在命令行程序中支持下述命令行参数。说明:字符总数统计、单词总数统计、有效行统计要求与个人项目相同
- 使用工具爬取论文信息
从CVPR2018官网爬取今年的论文列表,输出到result.txt(一定叫这个名字),内容包含论文题目、摘要,格式如下:
为爬取的论文从0开始编号,编号单独一行
两篇论文间以2个空行分隔
在每行开头插入“Title: ”、“Abstract: ”(英文冒号,后有一个空格)说明接下来的内容是论文题目,或者论文摘要
后续所有字符、单词、有效行、词频统计中,论文编号及其紧跟着的换行符、分隔论文的两个换行符、“Title: ”、“Abstract: ”(英文冒号,后有一个空格)均不纳入考虑范围 - 附加题(20')
本部分不参与自动化测试,如有完成,需在博客中详细描述,并在博客中附件(.exe及.txt)为证。附加功能的加入不能影响上述基础功能的测试,分数取决于创意和所展示的完成度,创意没有天花板,这里不提出任何限制,尽你们所能去完成。
##githup代码签入(团队)记录: 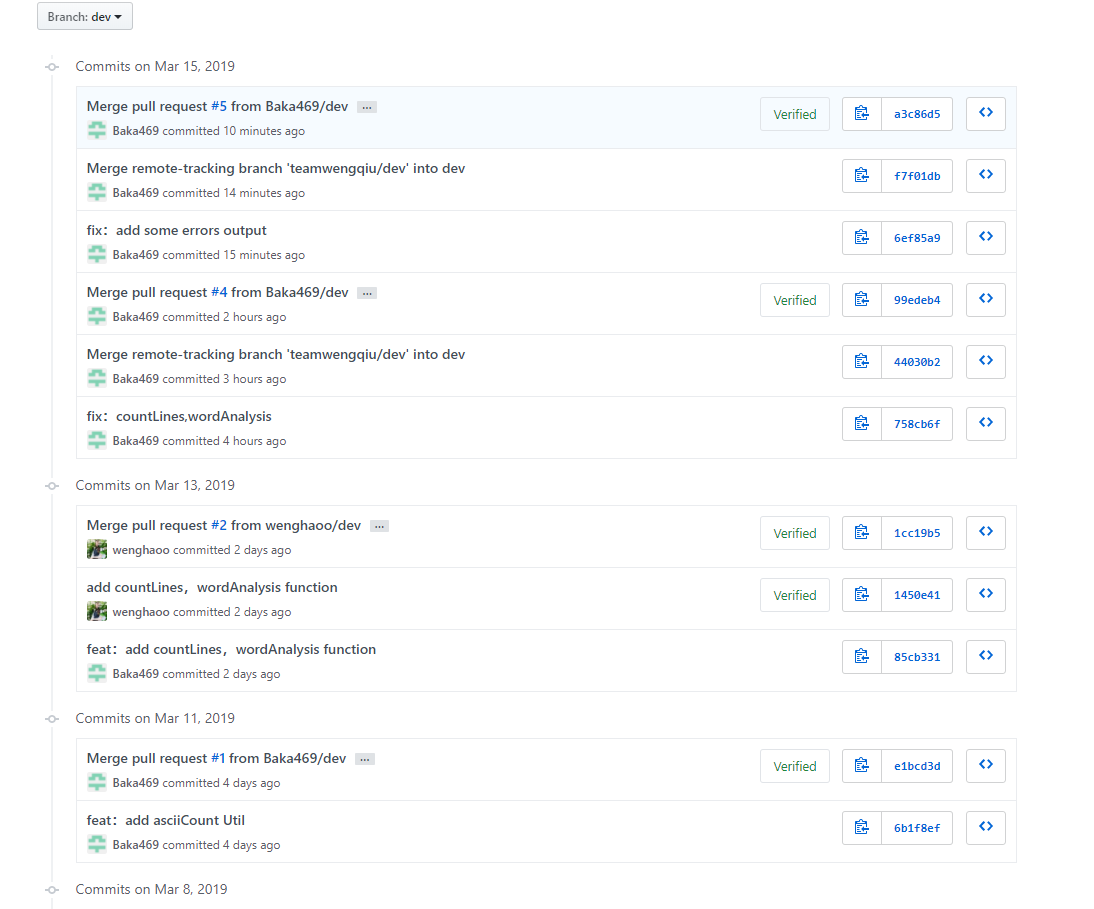
1 . 解题思路
总体上先完成大致的函数框架,再对框架进行细节填补和调试。
随后WordCount基本需求:爬取单词我采用输入流ifstream每次读单个字符,并用状态机的方式分类各类型的字符串,从而实现爬取单词。由于爬取单词代码是依照状态机思路完成的,测试数据主要是各类型字符串(开头为字母或者数字或者非字母数字,各种类型的中间过程,末尾的过滤)的爬取是否有没有问题。以及检测字典排序是否有问题。
2 . 设计过程
总体类图:
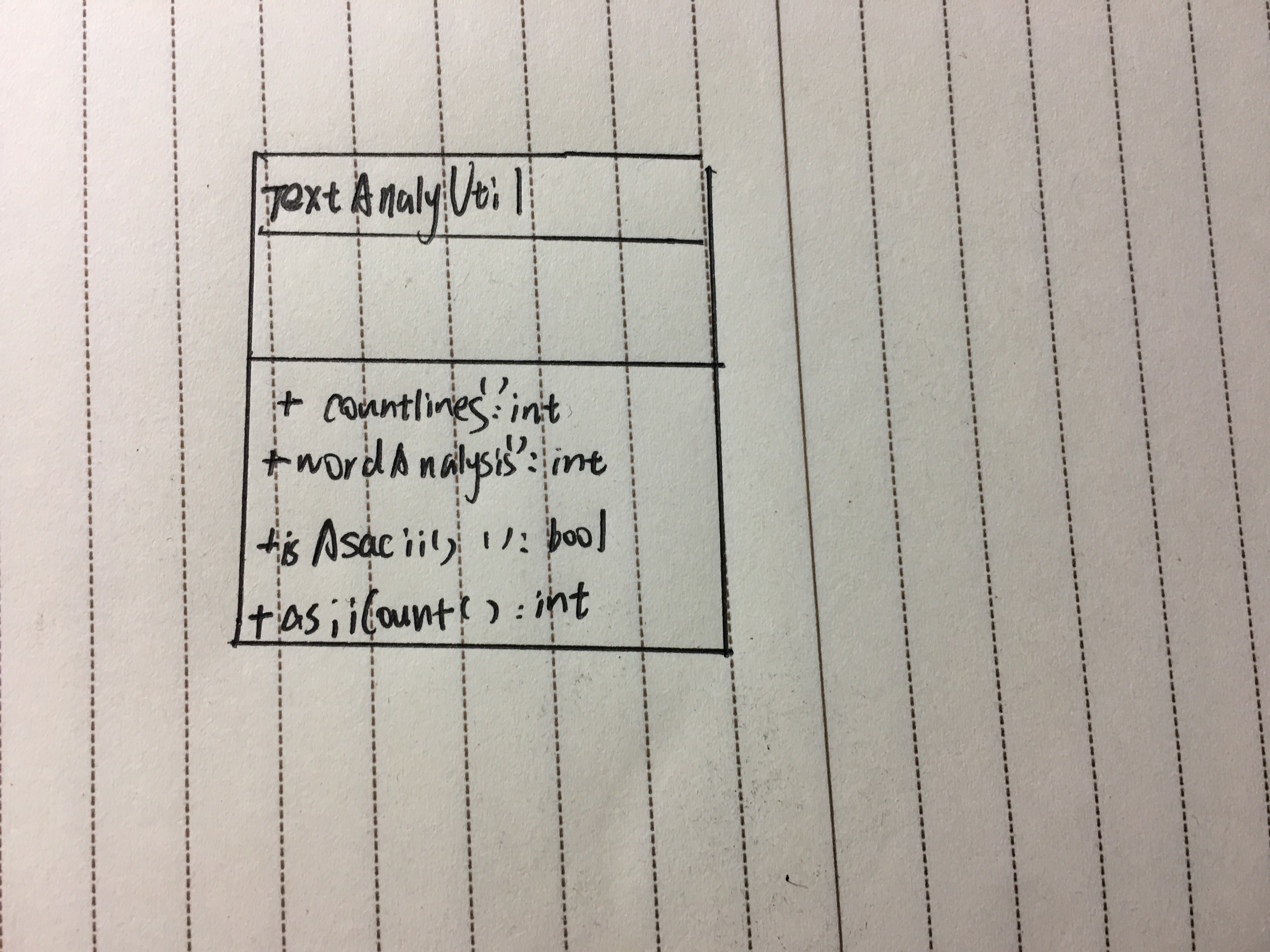
关于最困难的单词分析函数会在下面代码中解释。
单元测试的设计:查阅并学习单元测试的方法,读文件数据,在判断程序调用类中函数进行相等断言判断。
• 阶段一
o 共同讨论WordCount的基本功能需求
o 代码基本实现WordCount的基本需求
o 将项目各个功能分离成独立函数并进行相应的测试调整
o 对代码进行相应的测试和调整优化
• 阶段二
o 将项目按照作业格式上传github
o 撰写博客
3 . 关键代码
WordCount基本需求
爬取单词我采用输入流ifstream每次读单个字符,并用状态机的方式分类各类型的字符串,从而实现爬取单词。
选择了实际存储模式为哈希表的unordered_map,因为在爬取单词时并不需要随时更新排序,而最终目标是选出top10,所以我们考虑得出在爬取完成后不采取整个排序而是,采取遍历原数据,并新设一个10大小结构数组,自己设计比较大小的函数,对每个新遍历元素,进行在10大小结构数组冒泡排序,这样平均复杂度是o(10n)。
//爬取单词
int TextAnalysisUtil::wordAnalysis(char * fileName, WordInf * tempArr)
{
ifstream fin(fileName);
if (!fin)
{
cout << "cuowu";
return -1;
}
char ch;
string str;
int state = 0;
int nflag;
int wordCount = 0;
unordered_map<string, int> map;
while (fin.get(ch))
{
switch (state)
{
case 0:
//查找单词首的状态
if (isdigit(ch))
{
//转入找到数字开头的过滤状态
state = 1;
}
else if (isalpha(ch))
{
//找到单词,转入爬取单词状态
state = 2;
str = ch;
nflag = 1;//记录单词开头字母数
}
break;
case 1:
//转入找到数字开头或不符合单词开头有4个字母的过滤状态
if (!(isdigit(ch)||isalpha(ch)))
{
state = 0;
}
break;
case 2:
//爬取单词状态
if (isalpha(ch))
{
++nflag;
str += ch;
if (nflag >= 4)
//进入爬取单词尾部状态
state = 3;
}
else
{
//不满足单词开头有4个字母
state = 1;
}
break;
case 3:
//爬取单词尾部状态
if (isdigit(ch) || isalpha(ch))
{
str += ch;
}
else
{
//处理和存入字符串
transform(str.begin(), str.end(), str.begin(), ::tolower);
state = 0;
wordCount++;
map[str]++;
}
break;
default:
break;
}
}
if (state == 3)
//处理最后阶段3跳出没来的及处理的字符串
{
transform(str.begin(), str.end(), str.begin(), ::tolower);
wordCount++;
map[str]++;
}
//遍历找出频率最高的top10单词
for (auto iter = map.begin(); iter != map.end(); iter++)
{
if (isWordGreater(iter->first, iter->second, tempArr[9].word, tempArr[9].count))
{
tempArr[9].word = iter->first;
tempArr[9].count = iter->second;
for (int i = 9; i >= 1; i--)
{
if (isWordGreater(tempArr[i].word, tempArr[i].count, tempArr[i - 1].word, tempArr[i - 1].count))
{
swap(tempArr[i], tempArr[i - 1]);
}
}
}
}
fin.close();
return wordCount;
}
//主函数
int main(int argc, char *argv[])
{
TextAnalysisUtil TA;
ifstream infile;
WordInf tempArr[10] = {
};
infile.open(argv[1], ifstream::binary | ifstream::in);
if (!infile) {
cout << "失败" << endl;
return 1;
}
infile.close();
ofstream outFile;
outFile.open("result.txt");
if (!outFile) {
cout << "失败" << endl;
return 1;
}
outFile << "characters: " << TA.asciiCount(argv[1]) << endl;
outFile << "words: " << TA.wordAnalysis(argv[1],tempArr) << endl;
outFile << "lines: " << TA.countLines(argv[1]) << endl;
for (int d = 0; d < 10; d++)
{
if(tempArr[d].count>0)
outFile <<"<"<<tempArr[d].word << ">: " << tempArr[d].count << endl;
}
}
程序改进的思路:
![]()
花费最长时间的函数毫无疑问的是爬取单词并排序的wordAnalysis。对于此函数的优化我们在设计之初便尽自己目前的知识所能进行优化。
首先字典是毫无疑问使用的map类型的容器。
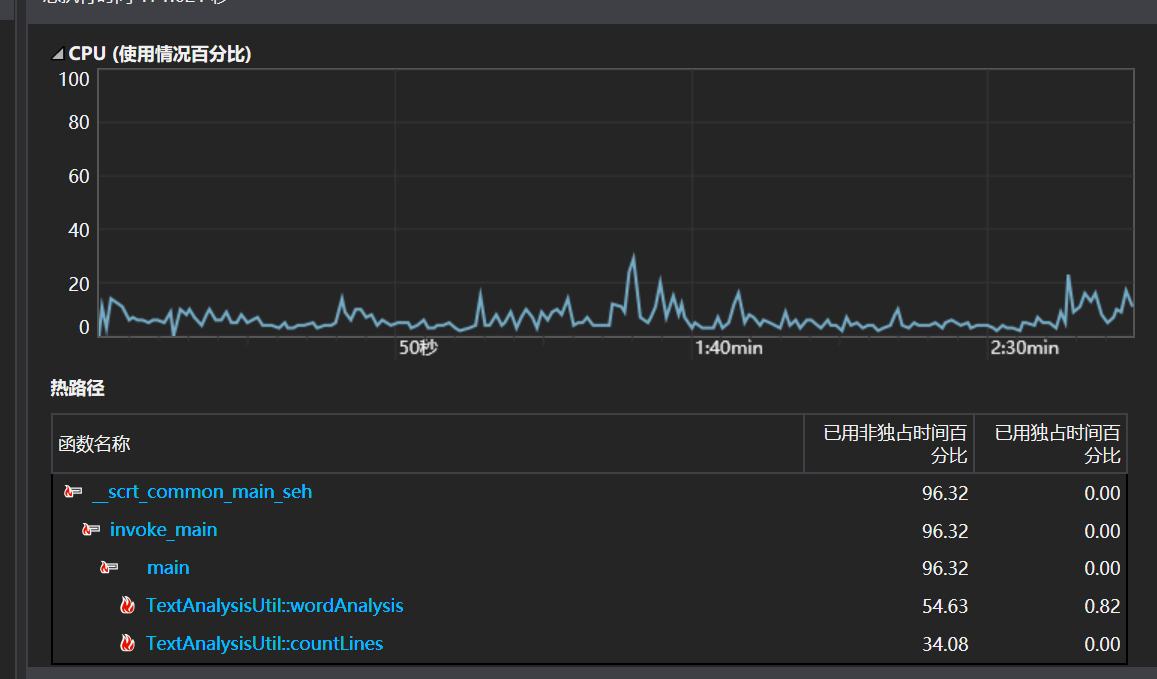
map: map内部实现了一个红黑树,该结构具有自动排序的功能,因此map内部的所有元素都是有序的,红黑树的每一个节点都代表着map的一个元素,因此,对于map进行的查找,删除,添加等一系列的操作都相当于是对红黑树进行这样的操作,故红黑树的效率决定了map的效率。
unordered_map: unordered_map内部实现了一个哈希表,因此其元素的排列顺序是杂乱的,无序的
通过查阅资料我们选择了unordered_map,因为在爬取单词时并不需要随时更新排序,而最终目标是选出top10,所以我们考虑得出在爬取完成后不采取整个排序而是,采取遍历原数据,并新设一个10大小结构数组,自己设计比较大小的函数,对每个新遍历元素,进行在10大小结构数组冒泡排序,这样平均复杂度是o(10n)。
###4.WordCount基本需求单元测试
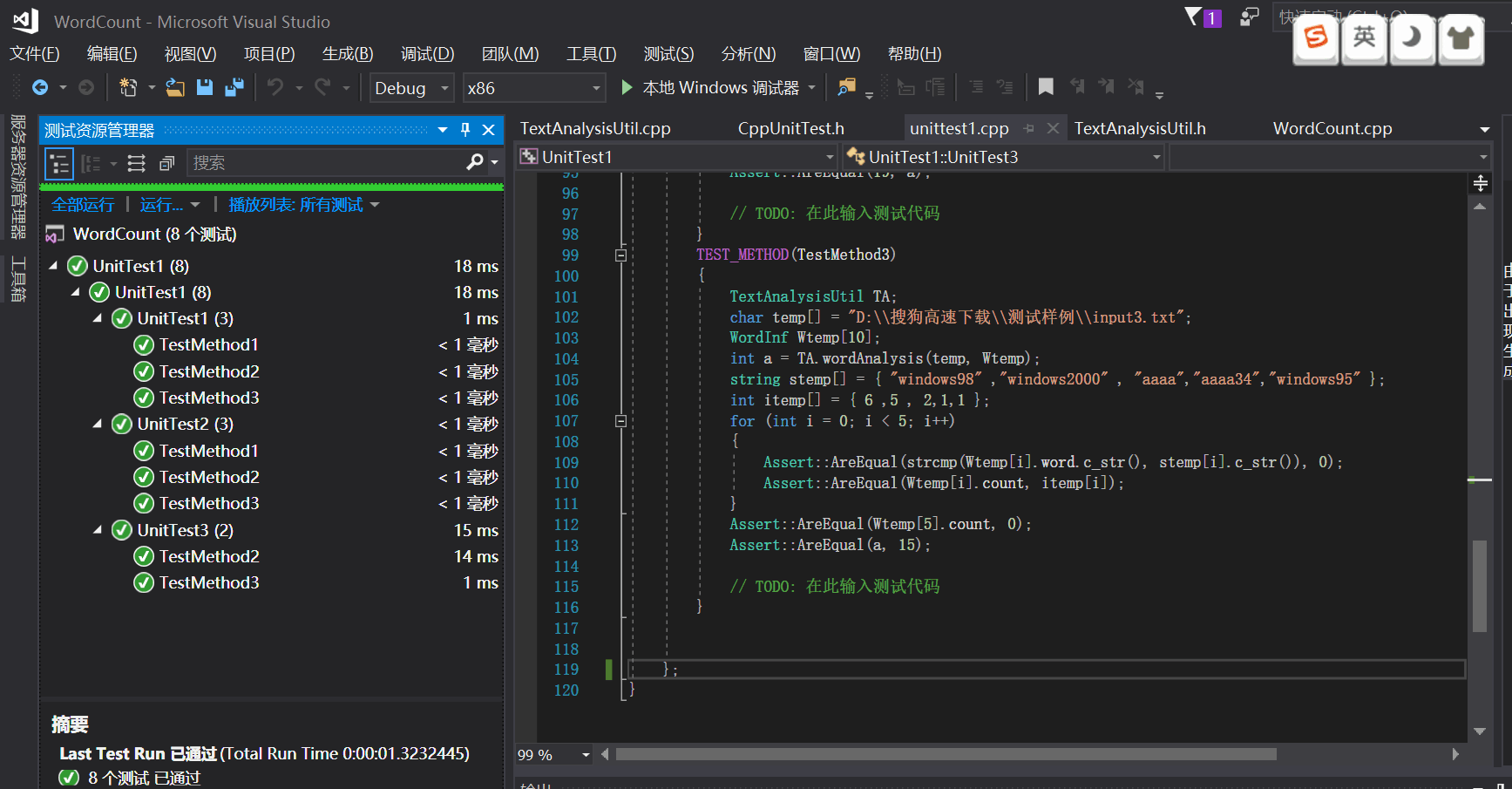
部分代码
TEST_METHOD(TestMethod1)
{
TextAnalysisUtil TA;
char temp[] = "D:\\搜狗高速下载\\测试样例\\input2.txt";
int a = TA.asciiCount(temp);
Assert::AreEqual(76, a);
// TODO: 在此输入测试代码
}
TEST_METHOD(TestMethod2)
{
TextAnalysisUtil TA;
char temp[] = "D:\\搜狗高速下载\\测试样例\\input2.txt";
int a = TA.countLines(temp);
Assert::AreEqual(3, a);
// TODO: 在此输入测试代码
}
TEST_METHOD(TestMethod3)
{
TextAnalysisUtil TA;
char temp[] = "D:\\搜狗高速下载\\测试样例\\input2.txt";
WordInf Wtemp[10];
int a = TA.wordAnalysis(temp, Wtemp);
Assert::AreEqual(strcmp(Wtemp[0].word.c_str(), "abcdefghijklmnopqrstuvwxyz"), 0);
Assert::AreEqual(Wtemp[0].count, 1);
Assert::AreEqual(Wtemp[1].count, 0);
Assert::AreEqual(a, 1);
}
Input2.txt(测试样例)
windows95
windows98
windows2000
windows98
windows2000
windows2000 windows98 windows98
windows2000
windows2000
windows98
windows98
a34
aa34
aaa34
aaaa34
1234
1aaaa4
aaaa
{1fafad
Aaaa
解释:
由于爬取单词代码是依照状态机思路完成的,测试数据主要是各类型字符串(开头为字母或者数字或者非字母数字,各种类型的中间过程,末尾的过滤)的爬取是否有没有问题。以及检测字典排序是否有问题。
5.困难与解决
1.一开始不知道从哪里开始下手。就对需求进行了细读分析,发现需求也分成了较大的版块。于是就对大的板块着手进行分析。调出关键部分函数进行分析构建,也就有了入手之处。
2.由于没找到适合储存单词的类,就构造了一个类来存储,解决了单词存储问题。
3.对分隔符一开始理解不够,以为就是空格。后来才发现分隔符在需求上有定义。所以认真看需求也很重要。
4.对于成为单词的条件没有完全使用正则表达式来实现,而是使用了标志位加正则表达式实现,想来是复杂了。
5.有一些细节问题,开始编码的时候未发现,后来通过步入调试一一解决了。
6.心得与总结
虽然只完成了基础需求部分。但从需求到实现,也动了很多脑筋。比如字符的读入,正则表达式的读入,数据的存放,排序和命令行参数。中间的调试也花了不少时间。最后测试完,也对代码进行了一些调整。总之,就是不会就上网搜索学习,有好的方法也要跟着吸收。
自己:完成了部分代码的编写和调试,编程能力得到了提升,同时也完成了测试和代码嵌入的部分内容,也认识到自己的能力上的不足又学到复习了很多实用的知识。进阶部分没来得及完成还是很遗憾的。
队友:认真负责,积极提供了重要的帮助,也完成了另一部分的工作,合作很愉快。
总结
这次任务让我们的队伍接触到了并了解到了外界具体需求到底是什么样子,为以后做了微小的一点点准备。
同时也让我们复习到了以前的知识,培养了动手能力,很合理。
psp
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 40 | 20 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 300 | 240 |
| • Design Spec | • 生成设计文档 | 30 | 30 |
| • Design Review | • 设计复审 | 10 | 20 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| • Design | • 具体设计 | 200 | 350 |
| • Coding | • 具体编码 | 500 | 300 |
| • Code Review | • 代码复审 | 120 | 100 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 500 | 540 |
| Reporting | 报告 | 30 | 50 |
| • Test Report | • 测试报告 | 30 | 20 |
| • Size Measurement | • 计算工作量 | 30 | 20 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 20 | 15 |
| 合计 | 1820 | 1715 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号