shell 编程 && bash 简介(shell 变量、shell操作环境、数据流重导向、管线命令、shell script)
如何学习一门编程语言
-
数据类型
-
运算符
-
关键字
1 认识BASH 这个shell
linux是操作系统核心,用户通过shell与核心进行沟通,达到我们想要的目的。硬件、核心、用户之间的关系:

原理:所谓Shell程序,实际上是提供用户操作系统的一个接口,用户可以通过shell程序操作其他应用程序(eg. ls,chown,etc.),让这些应用程序可以呼叫内核来完成工作。Bash是Linux系统下的其中一种Shell程序。当前系统支持哪些Shell程序,可查看/etc/shells配置文件;查看用户配置使用的哪种shell,可查看/etc/passwd配置文件。
bash:The Bourne Again Shell。
shell:接口程序,是一个命令语言解释器,拥有内建的命令集。
1.1 为何要学文字接口的shell
- Shell操作方式一致,可一法通、万法通;
- 远程管理;
- 主机管理及shell编程;
1.2 bash shell的功能
//历史查看,在[~/.bash_history]中记录前一次登入以前所执行过的指令,本次执行会暂存在内存中,成功注销后,才会记录到bash_history当中。 history //命令补全功能:tab tab //命令别名,自定义设定别名,比如alias lm='ls -al' alias lm='ls -al' //通配符* ls -l /user/bin/X* //查看在/usr/bin底下有多少以X为开头的文件
1.3 bash shell的内建命令:type
//type内建命令,type [-tpa] name,选项与参数 -t:file表示为外部指令;alias 表示命令别名所设定的名称;builtin 表示bash内建的命令 -p:name为外部指令,才会显示完整文件名 -a:PATH变量定义路径中,将所有含name指令都列出来,包含alias eg: //查看一下pwd这个指令是否为bash内建,列出主要使用情况 [wendy@cs011 ~]$ type pwd //内建命令 pwd is a shell builtin [wendy@cs011 ~]$ type -a pwd pwd is a shell builtin pwd is /usr/bin/pwd [wendy@cs011 ~]$ type -t pwd //内建命令,列出执行时的情况 builtin [wendy@cs011 ~]$ type ls ls is aliased to `ls --color=auto` [wendy@cs011 ~]$ type -a ls ls is aliased to `ls --color=auto` //先使用alias ls is /usr/bin/ls //找到外部命令在bin/ls [wendy@cs011 ~]$ type -t ls //别名,列出执行时的情况 alias
2 shell的变量功能
变量:让某一个特定字符串代表不固定的内容。即变量就是以一组文字或符号等,来取代一些设定或者一串保留的数据。比如y=ax+b,y就是变量,ax+b是变量的内容。
取用变量:echo $变量名,比如:echo $PATH 或 echo ${PATH}
变量的有效范围:比如export后的变量,称为环境变量。环境变量可以被子程序所引用,但其他的自定义变量就不会存在于子程序中。全局变量 = 环境变量;自定义变数 = 局部变量
- 当启动一个shell,操作系统会分配一记忆区块给shell使用,内存内的变量可以让子程序取用。
- 父程序利用export功能,可以让自定义变量的内容写入到记忆区块中。
- 当加载另一个shell时,子shell可以将父shell的环境变量所在的记忆区块导入自己的环境变量区块中。
Bash的变量分为2种:环境变量(可分为系统级别或用户级别)、普通变量。
普通变量即用户自定义的变量,变量的设定规则如下:
- 1.变量与变量内容以一个等号=来连接,比如[ myname=VBird ]
- 2.等号两边不能有空格;
- 3.变量名称只能是英文字母与数字,且必须以英文字母开头;
- 4.变量获取使用,可以通过$var或者${var}读取2种写法;
- 5.变量内容若有空格符,可使用单引号或者双引号将变量内容结合在一起;
A.单/双引号的区别在于:双引号内的特殊字符如$, 反引号等,可以保留原本特性;而单引号内的特殊字符则仅作为一般字符(纯文本);
//双引号内的特殊字符如$等,可以保有原本的属性 [wendy@cs011 ~]$ var="lang is $LANG" [wendy@cs011 ~]$ echo $var lang is en_US.UTF-8 [wendy@cs011 ~]$ var='lang is $LANG' [wendy@cs011 ~]$ echo $var lang is $LANG
B.单/双引号使用规则是:
-
-
- 1)双引号之间可有成对双引号,也可有成对单引号,当内外均是双引号时,内部双引号之间不能有空格 ;
- 2)单引号之间可有成对双引号,也可有成对单引号,当内外均是单引号时,内部单引号之间不能有空格;
- 3)双引号内可有单个单引号不能有单个双引号,除非以转移字符转义内部双引号;
- 4)单引号内可有单个双引号,不能有单个单引号,即使转义内部单引号也不行;
-
- 6.可以用转义字符\将特殊符号如ENTER, $, \, 空格等变成一般字符;
- 7.如果在一串指令中,还需要其他指令提供的信息,可以使用反单引号【ESC键正下方】或者$()来实现;
[wendy@cs011 ~]$ v=$(uname -r) [wendy@cs011 ~]$ echo $v 3.10.0-862.2.3.el7.x86_64 [wendy@cs011 ~]$ v1=`uname -r` //``这个是tab键上面的那个顿点 [wendy@cs011 ~]$ echo $v1 3.10.0-862.2.3.el7.x86_64
- 8.如果变量需要在其他子程序中使用,可以用export命令将其变成环境变量;
//该变量在其他子程序执行,需要用export来使变量变成环境变量 export PATH //变量为扩增变量,可用"$变量名称" 或${变量}累加内容 [wendy@cs011 develop]$ version=1 [wendy@cs011 develop]$ echo $version 1 [wendy@cs011 develop]$ version="$version":/第二个参数 [wendy@cs011 develop]$ echo $version 1:/第二个参数 [wendy@cs011 develop]$ version=$version:/第三个参数 [wendy@cs011 develop]$ echo $version 1:/第二个参数:/第三个参数 [wendy@cs011 develop]$ version=$version:/第四个参数 [wendy@cs011 develop]$ echo $version 1:/第二个参数:/第三个参数:/第四个参数
- 9.取消自定义变量命令unset;
- 10.交互获取变量命令read;
- 11.关于bash的补充说明:环境变量可理解为bash的全局变量,在用户取得bash时初始化并赋值。环境变量的初始化配置文件及读取顺序如下:
a.变量类型默认为“字符串”,可用declare申明变量类型
b.bash环境中的数值运算,预设的精度仅能达到整数形态;
- 12.环境变量查看命令env;环境变量及自定义变量查看命令set。
//列出目前的shell环境下的所有环境变量与其内容 env //set观察所有变量(含环境变量与自定义变量) set ps:env 与set 区别:该变量是否会被子程序所继续引用 //export:自定义变量转成环境变量,可以使用declare export //显示所有的环境变量
2.1 影响显示结果的语系变量(locale)
//locale -a :后面可以不加任何选项与参数 [wendy@cs011 ~]$ locale LANG=en_US.UTF-8 LC_CTYPE="en_US.UTF-8"
2.2 变量键盘读取、数组与宣告:read,array,declare
//read :读取来自键盘输入的变量。read [-pt] variable -p:后面可以接提示字符 -t:后面可以接等待的秒数 eg: [wendy@cs011 ~]$ read atest aaaa //等待输入,键盘输入内容 [wendy@cs011 ~]$ echo $atest aaaa [wendy@cs011 ~]$ read -p atest: atest:wendy [wendy@cs011 ~]$ echo $atest aaaa //declare/typeset:宣告变量的类型,declare [-aixr] variable -a:变量定义成为数组类型(array) -i:变量成为整数数字类型(integer) -x:export一样,变成为环境变量 -r:变量设定为readonly类型,该变量不能更改,也不能unset。需要注销在登入才能复原该变量类型 eg: [wendy@cs011 ~]$ declare -i sum=10+20 //-i 定义变量sum为integer [wendy@cs011 ~]$ echo $sum 30 [wendy@cs011 ~]$ declare -x sum //-x 定义变量sum为环境变量 [wendy@cs011 ~]$ export | grep sum declare -ix sum="30" [wendy@cs011 ~]$ declare -r sum //-r 定义变量sum为只读 [wendy@cs011 ~]$ sum=10+20+30 -bash: sum: readonly variable //让sum变成非环境变量的自定义变量 [wendy@cs011 ~]$ declare +x sum //+x 取消变量为自定义变量 [wendy@cs011 ~]$ declare -p sum declare -ir sum="30"
//数组变量类型 [wendy@cs011 ~]$ var[1]="small min" [wendy@cs011 ~]$ var[2]="big min" [wendy@cs011 ~]$ var[3]="nice min" [wendy@cs011 ~]$ echo "${var[1]},${var[2]},${var[3]}" small min,big min,nice min

3 命令别名与历史命令
//命令别名设定:alias, 别名='指令 选项....' alias lm='ls -al | more' //取消命令别名unalias unalias lm //history[n][-c] 或history [-raw] hisfiles n:数字 -c:将目前的shell中的所有history内容全部消除 -a:目前新增的history指令新增入histfiles,若没有加hisfiles,则预设写入~/.bash_history -r:将histfiles的内容读到目前这个shell的history记忆 -w:将目前的history记忆内容写入histfiles中 eg: [wendy@cs011 ~]$ history 3 999 alias 1000 clear 1001 history 3 [wendy@cs011 ~]$ history -w [wendy@cs011 ~]$ echo $HISTSIZE 1000 [wendy@cs011 ~]$ history 3 1002 history -w 1003 echo $HISTSIZE 1004 history 3
4 bash shell 的操作环境
4.1 路径与指令搜索顺序
- 1.以相对/绝对路径执行指令,例如[/bin/ls]或[./ls]
- 2.由alias找到该指令来执行
- 3.由bash内建的builtin指令来执行
- 4.透过$PATH这个变量的顺序搜寻到的第一个指令来执行
//指令执行顺序 [wendy@cs011 ~]$ alias echo='echo -n' [wendy@cs011 ~]$ type -a echo echo is aliased to `echo -n` echo is a shell builtin echo is /usr/bin/echo
4.2 bash的进站与欢迎讯息
// bash进站与欢迎讯息:/etc/issue、/etc/motd [wendy@cs011 ~]$ cat /etc/issue \S Kernel \r on an \m
4.3 环境配置文件
环境配置文件:login、non-login shell、/etc/profile、~/.bash_profile,source,~/.bashrc
//bash的环境配置文件:login、non-login shell、/etc/profile、~/.bash_profile,source,~/.bashrc //login shell读取的配置文件 1、/etc/profile:login shell才会读,这是系统整体的设定,最好不要修改这个档案 2、~/.bash_profile或~/.bash_login或~/.profile:属于使用者个人设定,你要改自己的数据,依次执行
login shell的配置文件读取流程:实现的方向是主线流程 ,虚线的方向则是被呼叫的配置文件。在centos的login shell环境下,最终被读取的配置文件是[~/.bashrc]这个文件。

//source:读入环境配置文件的指令,/etc/profile与~/.bash_profile都是在取得login shell的时候才会读取的配置文件。 //source 配置文件档名,利用source或小数点(.)都可以将配置文件的内容读进来目前的shell环境中。 eg://将home目录的~/.bashrc的设定读入目前的bash环境中,有如下2种方式。 [wendy@cs011 ~]$ source ~/.bashrc [wendy@cs011 ~]$ . ~/.bashrc //non-login shell情况下,bash配置文件仅会读~/.bashrc [wendy@cs011 ~]$ cat ~/.bashrc # .bashrc # Source global definitions //整体的环境设定 if [ -f /etc/bashrc ]; then . /etc/bashrc fi # Uncomment the following line if you don't like systemctl's auto-paging feature: # export SYSTEMD_PAGER= # User specific aliases and functions export NVM_DIR="$HOME/.nvm" [ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh" # This loads nvm [ -s "$NVM_DIR/bash_completion" ] && \. "$NVM_DIR/bash_completion" # This loads nvm bash_completion
4.4 终端机的环境设定
//终端机的环境设定:stty,set 。可以在tty1~tty6这六个文字接口的终端机环境中登入。syyt [-a] -a :将目前所有的stty参数列出来 eg: [wendy@cs011 ~]$ stty -a speed 38400 baud; rows 43; columns 115; line = 0; intr = ^C; quit = ^\; erase = ^H; kill = ^U; eof = ^D; eol = <undef>; eol2 = <undef>; swtch = <undef>; start = ^Q; stop = ^S; susp = ^Z; rprnt = ^R; werase = ^W; lnext = ^V; flush = ^O; min = 1; time = 0; -parenb -parodd -cmspar cs8 -hupcl -cstopb cread -clocal -crtscts -ignbrk -brkint -ignpar -parmrk -inpck -istrip -inlcr -igncr icrnl ixon -ixoff -iuclc -ixany -imaxbel -iutf8 opost -olcuc -ocrnl onlcr -onocr -onlret -ofill -ofdel nl0 cr0 tab0 bs0 vt0 ff0 isig icanon iexten echo echoe echok -echonl -noflsh -xcase -tostop -echoprt echoctl echoke //set [-uvCHhmBx] -u:默认不启用,启用时,未设定变量时,会显示错误信息 -v:默认不启用,启用后,讯息被输出前,会先显示讯息的原始内容 -x:默认不启用,启用后,在指令被执行前,会显示指令内容 -h:默认启用,与历史命令有关 -H:默认启用,与历史命令有关 -m:默认启用,与工作管理有关 -B:默认启用,与刮号[]的作用有关 -C:默认不启用,若使用>等,则若文件存在时,该文件不会被覆盖 //$- :变量内容就是set的所有设定,bash预设是himBH [wendy@cs011 ~]$ echo $- himBH [wendy@cs011 ~]$ set -u [wendy@cs011 ~]$ echo $vbirding -bash: vbirding: unbound variable [wendy@cs011 ~]$ set -x ++ printf '\033]0;%s@%s:%s\007' wendy cs011 '~' [wendy@cs011 ~]$ echo $HOME + echo /home/wendy /home/wendy ++ printf '\033]0;%s@%s:%s\007' wendy cs011 '~'
常用的快捷键:
|
Ctr + C |
终止当前任务 |
|
Ctr + Z |
暂停当前任务 |
|
Ctr + S |
暂停屏幕输出 |
|
Ctr + Q |
回复屏幕输出 |
|
Ctr + U |
删除提示符之前内容 |
|
Ctr + K |
删除提示符之后内容 |
4.5 通配符与特殊符号
特殊符号:
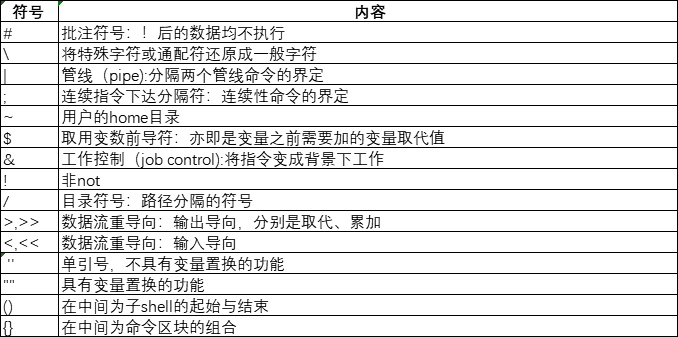
通配符:

eg: //找出/etc/底下文件名刚好是5个字母的文件名 [wendy@cs011 ~]$ ll -d /etc/????? drwxr-x---. 3 root root 4096 Mar 20 2019 /etc/audit //找出/etc/底下以cron为开头的文件名 [wendy@cs011 ~]$ ll -d /etc/cron* drwxr-xr-x. 2 root root 4096 Mar 20 2019 /etc/cron.daily //找出/etc/底下文件名含有数字的文件名 [wendy@cs011 ~]$ ll -d /etc/*[0-9]* -rw-r--r-- 1 root root 228 Oct 18 2017 /etc/m2.conf //找出/etc/底下文件名开头不为大写字母开头的文件名 [wendy@cs011 ~]$ ll -d /etc/[^A-Z]* -rwxrwxrwx 1 root root 1789280 Mar 20 2019 /etc/aayx
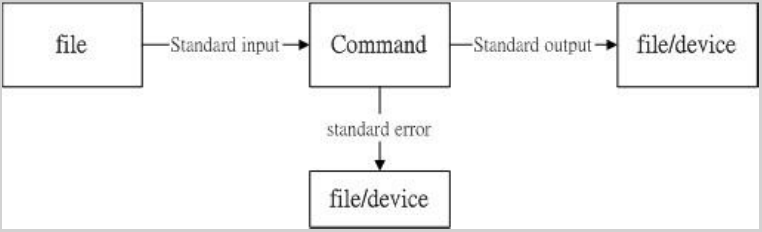
5 数据流重导向(Redirection)
数据流重导向:将某个指令执行后出现在屏幕上的数据。
- 标准输出:指的是指令执行所回传的正确的讯息。
- 标准错误输出:指令执行失败后,所回传的错误讯息。
指令执行过程的数据传输情况示意图:
数据流重导向可以将standard output(简称stdout)与standard error output(简称stderr)分别传送所用的特殊字符如下:
- 1.标准输入(stdin):代码为0,使用< 或 << ;
- 2.标准输出(stdout):代码为1,使用> 或>>;
- 3.标准错误输出(stderr):代码为2,使用2> 或2>>;
- 4./dev/null:垃圾桶黑洞装置与特殊写法
//用cat直接将输入的讯息输出到catfile中,且当由键盘输入eof时,该次输入就结束 cat > catfile << "eof" eg: [wendy@cs011 develop]$ cat >test.txt <<"eof" > wendy001 > wendy002 > wendy003 > eof //输入这关键字,立刻就结束而不需要输入ctrl+d [wendy@cs011 develop]$ vi test.txt [wendy@cs011 develop]$ cat >test.txt <<"eof" > wendy004 > wendy005 > wendy006 > eof [wendy@cs011 develop]$ vi test.txt [wendy@cs011 develop]$ cat >>test.txt <<"eof" > wendy001 > wendy002 > wendy003 > eof
命令执行的判断依据:;.&& ||
//cmd;cmd (不考虑指令相关性的连续指令下达),比如先执行两次sync同步化写入磁盘后才shutdown sync;sync;shutdown -h now // $?(指令回传值) 与 ## 或 || $? =0,若前一个指令执行的结果为正确,在linux底下会回传一个 $?=0 的值 // && ls /tmp/abc && touch /tmp/abc/hehe //ls显示找不到对应的目录,touch还未执行 // || ls /tmp/abc || mkdir /tmp/abc // 不存在该文件
ll /tmp/abc //上面指令执行mkdir命令
指令依序执行的关系示意图:
- 1.上方线段为不存在/tmp/abc,回传$?!=0,因为||执行mkdir,回传$?=0,又遇到&&,执行touch
- 2.下方线段为存在/tmp/abc,回传$?=0,因为||,所以不执行mkdir,$?=0往后继续回传,因为又遇到&&,执行touch

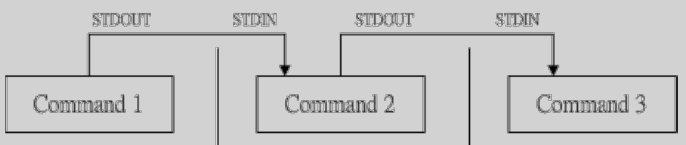
6 管线命令(pipe)
管线命令 | 仅能处理经由前面一个指令传来的正确信息,也就是stdout的信息,对于stderr并没有直接处理的能力。
管线命令的处理示意图:在每个管线后面接的第一个数据必定是指令,而且这个指令必须要能够接受stdin的数据才行,称为管线命令。
比如less,more,head,tail等都是可以接收stdin的管线命令,至于例如ls,cp,mv等就不是管线命令。
6.1 截取命令:cut、grep
截取命令:cut,grep。就是将一段数据经过分析后,取出想要的,或者经由分析关键词,取得我们所想要的那一行。截取信息通常是针对一行一行来分析的。
//cut的用途:在于将同一行里面的数据进行分解,即将一行讯息当中,取出某部分我们想要的。 //cut用于有特定分隔字符,cut -d '分隔字符' -f fields -d:后面接分隔字符,与-f一起使用 -f:依据-d的分隔字符将一段讯息分割成为数段,用-f取出第几段 -c:以字符的单位取出固定字符区间,同时可以处理具有格式的输出数据,比如第12-20的字符,就是:cut -c 12-20 //cut -c 字符区间 eg: [wendy@cs011 jdk]$ echo $PATH /opt/wendy/local/jdk/jdk1.8.0_152/bin:/home/wendy/.nvm/versions/node/v10.18.1/bin:/usr/local/bin:/usr/bin:/usr/local/sbin [wendy@cs011 jdk]$ echo $PATH | cut -d ':' -f 4 //以:作为分隔符,列出第四的内容 /usr/bin [wendy@cs011 jdk]$ echo $PATH | cut -d ':' -f 4,5 //以:作为分隔符,列出第四、第五的内容 /usr/bin:/usr/local/sbin
//grep:分析一行讯息,grep [-acinv][--color=auto]'搜寻字符串' filename -a:将binary文件以test文件的方式搜寻数据 -c:计算找到'搜寻字符串'的次数 -i:忽略大小写的不同,所以大小写视为相同 -n:顺便输出行号 -v:反向选择 --color=auto:可以将找到的关键词部分加上颜色的显示. eg: last | grep 'root'| cut -d '' -f1 //在last的输出讯息中,只要有root就取出,并且以空为分隔符,仅取第一栏。在取出root之后,利用上个指令cut的处理,就能够仅取得第一栏。 last | grep -v 'root' //只要没有root的就取出 last | grep 'root' //将last当中,有出现root的那一行取出来
6.2 排序命令:sort、uniq、wc
场景:计算一次数据里头的相同型态的数据总数,使用last可以查得这个月份有登入主机者的身份。
- sort:排序,根据不同数据型态来排序,比如数字与文字的排序,此外排序的字符与语系的编码有关。
- uniq:排序完成之后,想要将重复的资料仅列出一个显示。
- wc:统计/etc/man.config文件里面有多少字、多少行、多少字符。
//排序命令:sort,wc,uniq。sort [-fbMnrtuk][file or stdin],sort进行排序,可以根据不同的数据型态来排序,比如数字与文字的排序。 -f:忽略大小写的差异,例如A与a 视为编码相同 -b:忽略最前面的空格符部分 -M:以月份的名字来排序,例如JAN,DEC等等的排序方法 -n:使用纯数字进行排序(默认是以文字型态来排序的) -r:反向排序 -u:就是uniq,相同的数据中,仅出现一行代表 -t:分隔符,预设是用tab键来分隔 -k:以哪个区间(field)来进行排序 eg: //sort排序,个人账号都记录在/etc/passwd下,并将账号进行排序,默认是以第一个数据来排序,从a-z进行显示 [wendy@cs011 jdk]$ cat /etc/passwd |sort abrt:x:173:173::/etc/abrt:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin bin:x:1:1:bin:/bin:/sbin/nologin chrony:x:996:994::/var/lib/chrony:/sbin/nologin //sort排序,在/etc/passwd内容是以:来分隔的,以第三栏来排序 [wendy@cs011 jdk]$ cat /etc/passwd |sort -t ':' -k 3 root:x:0:0:root:/root:/bin/bash haishu:x:1000:1000::/home/wendy:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin bin:x:1:1:bin:/bin:/sbin/nologin //uniq [-ic],排序完成,将重复的资料仅列出一个显示.-c表示reboot登录有12次,root登录有41次。wtmp与空白都是last的默认字符,那两个可以忽略。 -i:忽略大小写字符的不同 -c:进行计数 [wendy@cs011 jdk]$ last |cut -d ' ' -f1 | sort | uniq -c 1 12 reboot 41 root 1 wtmp //wc [-lwm],/etc/profile里面到底有多少行、字数、字符数 -l:仅列出行 -w:列出多少字 -m:多少字符 [wendy@cs011 jdk]$ cat /etc/profile | wc 80 261 1903
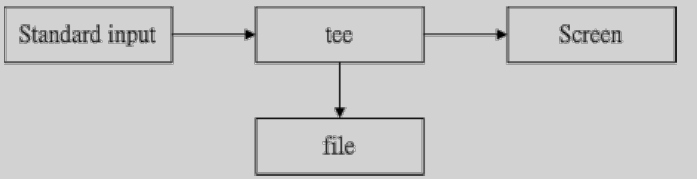
6.3 双向重导向:tee
tee:将数据流的处理过程中的某段讯息存下来。tee会同时将数据流分送到文件与屏幕里去。输出到屏幕的,就是stdout。
tee的工作流程示意图:
//tee:同时将数据流分送到文件去与屏幕(screen),而输出到屏幕的,其实就是stdout //tee [-a] file -a:以累加(append)的方式,将数据加入file当中 last | tee last.list | cut -d " " -f1 //让我们将last的输出存一份到last.list文件中 ls -l /home | tee ~/homefile |more //将ls的数据存一份到~/homefile,同时屏幕也有输出讯息。 ls -l / | tee -a ~/homefile |more //tee后接的文件会被覆盖,若加上-a 这个选项则能将讯息累加。
6.4 字符转换命令:tr、col、join、paste、expand
- tr:可以用来删除一段信息当中的文字,或者是进行文字信息的替换。
- col:用来简单的处理将tab键取代称为空格键。
- join:处理两个文件之间的数据,主要是处理在两个文件当中,有相同数据的那一行,才将他加在一起。
- paste:必须要比对两个文件的数据相关性。paste就直接将两行贴在一起,且中间以tab键隔开。
//字符转换命令:tr,col,join,paste,expand //tr 可以用来删除一段讯息当中的文字,或者是进行文字讯息的替换,tr [-ds] SET1 ... -d:删除讯息当中的[SET1]这个字符串 -s:取代掉重复的字符 eg: //将last输出的讯息中,所有的小写变成大写字符 [wendy@cs011 jdk]$ last | tr '[a-z]' '[A-Z]' //将/etc/passwd输出的讯息中,将冒号(:)删除
源文件显示: [wendy@cs011 ~]$ cat /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin [wendy@cs011 ~]$ cat /etc/passwd | tr -d ':' rootx00root/root/bin/bash binx11bin/bin/sbin/nologin daemonx22daemon/sbin/sbin/nologin //col [-xb] -x:将tab键转换成对等的空格键 -b:在文字内有反斜杠(/)时,仅保留反斜杠最后接的那个字符 cat /etc/profile | col -x | cat -A |more
//join [-ti12] file1 file2 -t:join默认以空格符分隔数据,并且比对[第一个字段]的数据,如果2个文件相同,则将两笔数据联成一行,且第一个字段放在第一个 -i:忽略大小写的差异 -1:数字的1,代表第一个文件要用那个字段来分析 -2:代表第二个档案要用那个字段来分析 test.txt:001:wendy:004、002:wendy:005、003:wendy:006、004:wendy:001、005:wendy:002、006:wendy:003 test001.txt:001:002、002:003、003:004、004:005
//将test.txt与test001.txt相关数据整合成一栏,结果显示为: [wendy@cs011 develop]$ head -n 10 ./test.txt ./test001.txt ==> ./test.txt <== 001:wendy:004 002:wendy:005 003:wendy:006 004:wendy:001 005:wendy:002 006:wendy:003 ==> ./test001.txt <== 001:002 002:003 003:004 004:005 //join使用之前,你所需要处理的文件应该要事先经过排序处理,将两个文件第一个字段相同者整合成一行,第二个文件的相同字段并不会显示 [wendy@cs011 develop]$ join -t ':' ./test.txt ./test001.txt 001:wendy:004:002 002:wendy:005:003 003:wendy:006:004 004:wendy:001:005
//paste [-d] file1 file2 ,选项与参数 -d:后面可以接分隔字符,预设以tab来分隔 -:如果file部分写成-,表示来自stdin的文件 eg:
//将test.txt与test001.txt同一行贴在一起,同一行中间以tab按键隔开 [wendy@cs011 develop]$ paste test.txt test001.txt 001:wendy:004 001:002 002:wendy:005 002:003 003:wendy:006 003:004 004:wendy:001 004:005 005:wendy:002 006:wendy:003
//expand [-t] file,选项要参数。在将tab按键转成空格键 -t:后面可以接数字,一个tab按键可以用8个空格键取代
6.5 分割命令:split
场景:文件太大,导致无法复制,split可以帮你将一个大文件,依据文件大小或行数来分隔,就可以将大文件分割成小文件。
//split分割命令,split [-bl] file PREFIX -b:后面可接文件大小,可加单位,例如b,k,m。 -l:以行数来进行分割。 PREFIX:代表前导符的意思,可作为分割文件的前导文字。 eg: //分割命令split,那个文件名可以随意取,只要写上前导文件,小文件就会以xxxaa,xxxab,xxxac等方式来建立小文件的。 [wendy@cs011 develop]$ split -b 30 ./test.txt test.txt [wendy@cs011 develop]$ ll -k test.txt* -rw-rw-r-- 1 wendy wendy 84 Apr 27 10:55 test.txt -rw-rw-r-- 1 wendy wendy 30 Apr 27 11:20 test.txtaa -rw-rw-r-- 1 wendy wendy 30 Apr 27 11:20 test.txtab -rw-rw-r-- 1 wendy wendy 24 Apr 27 11:20 test.txtac //将三个上面的三个小文件合成一个文件,文件名为testback [wendy@cs011 develop]$ cat test.txta* >> test.txtback [wendy@cs011 develop]$ ll -rw-rw-r-- 1 wendy wendy 84 Apr 27 10:55 test.txt -rw-rw-r-- 1 wendy wendy 30 Apr 27 11:20 test.txtaa -rw-rw-r-- 1 wendy wendy 30 Apr 27 11:20 test.txtab -rw-rw-r-- 1 wendy wendy 24 Apr 27 11:20 test.txtac -rw-rw-r-- 1 wendy wendy 84 Apr 27 11:26 test.txtback
6.6 参数代换:xargs
xargs:x是加减乘除的乘号,args则是arguments(参数)。xargs参数产生某个指令的参数。xargs可以读入stdin的数据,并且以空格符或断行字符作为分隔,将stdin的资料分隔成为arguments。
//xargs [-0epn] command,选项与参数 -0:输入的stdin含有特殊字符,例如'\,空格键等字符时,这个-0参数还原成一般字符。 -e: 这个是EOF(end of file ),后面可以接一个字符串,当xargs分析到这个字符串时,就会结束继续工作。 -n:后面接次数,每次command指令执行时,要使用几个参数。当后面没有参数时,默认是以echo来进行输出。 -p:在执行每个指令的argument时,都会询问使用者的意思 eg: [wendy@cs011 ~]$ cut -d: -f1 < /etc/passwd | sort | xargs echo abrt adm bin chrony daemon dbus ftp games gluster haishu halt libstoragemgmt lp mail named nobody ntp operator polkitd postfix root rpc shutdown sshd sync systemd-bus-proxy systemd-network tcpdump tss
重点:
- 核心在内存中受保护,需要透过shell 将我们输入的指令与核心沟通
- 学习shell的原因:一致性;速度快;shell主导
- 系统合法的shell均写在/etc/shells文件中
- 用户默认登录取得的shell记录在/etc/passwd的最后一个字段
- bash功能的主要有:命令修复能力;命令与档案补全功能;命令别名设定功能;工作控制、前景背景控制;程序后脚本;通配符
- type可以用来找到执行指令为何种类型
- 变量就是以一组文字或符号等,来取代一些设定或者是一串保留的数据
- 变量主要有环境变量与自定义变量,或称为全局变量与局部变量,使用env、export可观察环境变量,export可以将自定义变量转成环境变量
- set可以观察目前bash环境下的所有变量;$?为变量,是前一个指令执行完毕后的回传值,回传值=0表示执行成功
- locale可以观察语系资料;可用read让用户由键盘输入变量的值,ulimit可用以限制用户使用系统的资源情况
- bash的配置文件主要分为login shell与non-login shell.login shell主要读取/etc/profile与~/.bash_profile,non-login shell则仅读取~/.bashrc
- 通配符主要有:*?[]等待
- 数据流重导向透过>,2>,<之类的符号将输出的信息转到其他文件或装置去
- 连续命令的下达:&& 、||
- 管线命令的重点:管线命令仅会处理stdout,对于stderr会予以忽略,同时管线命令必须要能够接受来自前一个指令的数据成为stdin继续处理。
- 管线命令主要包含:cut、grep、sort、wc、uniq、tee、tr、col、join、paste、expand、split、xargs。
7 正规表示法与文件格式化处理
正规表示法[Regular Expression,RE,常规表示法]:处理字符串的方法,以行为单位来进行字符串的处理行为。透过一些特殊字符的排列,用以搜寻/取代/删除一列或多列文字字符串[简单说,正则表示法就是用在字符串的处理上面的一项表达式,是一个字符串处理的标准依据]。比如:vi,sed,awk等等。只要工具程序支持正规表示法,该工具程序就可以用来作为正规表示法的字符串处理之用。
正规表示法的字符串表示方式依照不同的严谨程度分为:基础正规表示法与延伸正规表示法。
- 基础正规表示法:处理字符串的一种表示方式,对字符排序有影响的语系数据就会对正规表示法的结果有影响。比如grep.
- 延伸型正规表示法:除了简单的一组字符串处理之外,还可以作群组的字符串处理。
常见的正规表示法工具有:grep、sed、awk、vim。printf可以透过一些特殊符号来将数据进行格式化输出,awk可以使用字段为依据,进行数据的重新整理与输出。
7.1 grep工具
grep作用:字符串数据比对,将符合用户需要的字符串打印出来。
grep在数据中查寻一个字符串时,是以"整行"为单位来进行数据的截取。比如一个文件内有10行,其中有2行是你所搜寻的字符串,则将那两行显示在屏幕上,其他丢弃。
在关键词显示方面,用--color=auto来将关键词部分使用颜色进行显示。
//grep [-A][-B][--color=auto] '搜寻字符串' filename -A:after的意思,除了列出该行外,后续的n行也列出来 -B:before的意思,除了列出该行外,前面的n行也列出来 --color=auto 可将正确的那个截取数据列出颜色 eg1: //用dmesg列出核心信息,再以grep 找到eth所在行的前2行与后三行也一起进行显示 dmesg | grep -n -A3 -B2 --color=auto 'eth' eg2: test.txt文件内容:001:wendy:004、002:wendy:005、003:wendy:006、004:wendy:001、005:wendy:002、006:wendy:003 //1.搜寻特定字符串,比如从test.txt文件当中取得001这个特定字符串 [wendy@cs011 develop]$ grep -n '001' test.txt 1:001:wendy:004 4:004:wendy:001
//2.反向选择,比如从test.txt文件当中,当该行没有'001'这个字符串时才显示在屏幕上
eg1:
[wendy@cs011 develop]$ grep -vn '001' test.txt
显示结果如图:![]()
eg2://反向选择,从test.txt中搜索不包含001的行
[wendy@cs011 develop]$ grep '[^001]' test.txt
显示结果如图:
//3.利用中括号[]来搜寻集合字符,比如搜索0*:wendy或0*:wendy,*表示随意 //[]里面无论有几个字符,都只代表一个字符
[haishu@cs011 develop]$ grep -n '0[0-9]:wendy' test.txt
显示结果如图:
//4.在g与g之间有2个到3个的o存在的字符串。\{n,m\}:指的是连续n到m个以上的前一个Re字符。
[haishu@cs011 develop]$ grep -n 'go\{2,3\}g' regular_express.txt
正规表示法与通配符完全不一样,通配符代表的是bash操作接口的一个功能,但正规表示法则是一种字符串处理的表示方式。
使用grep或其他工具进行正规表示法的字符串比对时,编码问题会有不同的状态,设置LANG等变量设定为C或是en的英文语系,可利用特殊符号[:upper:]来替代编码范围。
grep与egrep在正规表示法里面常见的两支程序,其中egrep更支持正规表示法的语法。
grep -v '^$' test.txt | grep -v '^#' //egrep进行简化,透过群组功能|来进行一次搜寻。grep -E = egrep 的写法
egrep -v '^$ | ^#' test.txt
基础的正规表示法[grep]:

延伸的正规表示法[egrep]:

7.2 sed 工具
sed是一个管线命令,可以分析stdin等。
sed功能:数据进行取代、删除、新增、截取特定行等等的功能。
// sed [-nefr] [动作],选项与参数说明 -n:使用安静(silent)模式。在一般sed用法中,所有来自STDIN的数据一般都会被列出屏幕上。 -e:直接在指令列模式上进行sed的动作编辑。 -f:直接将sed的动作写在一个文件内,-f filename则可以执行filename内的sed动作 -r:sed的动作支持的是延伸型正规表示法的语法。(预设是基础正规表示法语法) -i:直接修改读取的文件内容,而不是由屏幕输出。 [动作说明]:[n1[,n2]]function n1,n2:不一定存在,代表选择进行动作的行数,比如在10-20行之间进行,则[10,20][动作行为] function有如下参数: a:新增,a的后面接字符串,在新行进行显示 c:替换,接字符串,可以在n1,n2之间替换 i:插入,接字符串,新行出现 d:删除 p:打印,与参数sed -n一起使用 s:替换,直接替换,比如1,20s/old eg1:以行为单位的新增/删除功能 //将etc/passwd的内容列出并且打印行号,请将2~5行删除。 [wendy@cs011 develop]$ nl /etc/passwd | sed '2,5d' //只要删除第2行。 [wendy@cs011 develop]$ nl /etc/passwd | sed '2d' //删除第3行到最后一行,$代表最后一行! [wendy@cs011 develop]$ nl /etc/passwd | sed '3,$d' //新增,在a后面加上的字符串就已将出现在第二行后面。 [wendy@cs011 develop]$ nl /etc/passwd | sed '2a drink tea' //新增,加上的字符串就已将出现在第二行前面,由a改为i即可。 [wendy@cs011 develop]$ nl /etc/passwd | sed '2i drink tea' eg2:以行为单位的取代与显示功能 //将etc/passwd中的第2~5行的内容替换[2,5c]:No 2-5number [wendy@cs011 develop]$ nl /etc/passwd | sed '2,5c No 2-5number' eg3:以行为单位的显示功能 //列出文件内的第5-7行,sed '5,7p'(5-7行会重复输出),所以一般与-n一起使用 [wendy@cs011 develop]$ nl /etc/passwd | sed -n '5,7p' eg4:部分数据的搜寻并取代的功能 //除了整行的处理模式之外,sed还可以用来行为单位进行部分数据的搜寻并取代的功能 //sed 's/要被取代的字符串/新的字符串/g' [wendy@cs011 develop]$ sbin/ifconfig eth0 | grep 'inet addr' | sed 's/^.*addr://g' |sed 's/Bcast.*$//g'
7.3 awk工具
awk:数据处理工具,相较于sed常常作用于一整个行的处理,awk则比较倾向于一行当中分成数个[字段]来处理,即awk不是[以行为一次处理的单位],而[以字段为最小的处理的单位]。
awk处理流程如下:
- 1.读入第一行,并将第一行的资料填入$0,$1,$2...等变数当中。$0表示一整行的内容,$1表示第一个参数
- 2.依据 条件类型 的限制,判断是否需要进行后面的动作
- 3. 做完所有的动作与条件类型
- 4. 若还有后续的行数据,则重复1-3的步骤,直到所有的数据都读完为止
//awk '条件类型1{动作1} 条件类型2{动作2}....' filename 。 awk主要处理每一行的字段内的数据,而默认的字段的分隔符为空格键或tab键。 eg1: //取出前5行,取出第一个参数和第三个参数,tab键隔开,用print的功能将字段数据列出来 last -n 5 | awk '{print $1 'tab' $3}' eg2: //取出前5行,列出每一行的账号($1);列出目前处理的行数(NR变量);该行有多少字段(NF变量) last -n 5 | awk '{print $1 "\tlines:"NR "\t columes:"NF}' eg3://逻辑判断,BEGIN关键字 ///etc/profile当中以冒号来作为字段的分隔,第一个字段是账号,第三个字段是UID //需求:查询第三个参数小于10以下的数据,并且仅列出账号与第三栏 cat /etc/profile | awk 'BEGIN {FS=":"} $3<10 {print $1 "\t" $3}'
awk的逻辑运算字符:

7.4 printf打印
文件进行一些简单的编排,通过数据流重导向配合底下介绍的printf功能,以及awk指令。
//格式化打印:printf '打印格式' 实际内容 \a 警告声音输出 \b 退格键(backspace) \f 清除屏幕(form feed) \n 输出新的一行 \r Enter按键 \t 水平的tab按键 \v 垂直的tab按键 \xNN NN为两位数的数字,可以转换数字成为字符。 //关于C程序语言内,常见的变数格式 %ns:n=number;s=string,指的是多少个字符 %ni:n=number;i=integer,指的是多少整数字数 %N.nf:n、N=number;f=floating(浮点),如果有小数字数,比如%10.2f表示10个位数,但小数点有2位
重点:
- 正规表示法就是处理字符串的方法,以行为单位来进行字符串的处理行为。
- 正规表示法透过一些特殊字符的辅助,能达到搜索、删除、取代某特定字符串的处理程序。
- 只要工具程序支持正规表示法,该工具程序就可以用来作为正规表示法的字符串处理之用。
- 通配符代表的是bash操作接口的一个功能,但正规表示法则是一种字符串处理的表示方式。
- 使用grep或其他工具进行字符串比对,编码问题会有不同的状态。
- 基础正规表示法的特殊字符有:*、?、[]、[-]、[^]、^、$。
- 常见的正规表示法工具:grep、sed、vim。
- printf可以透过一些特殊符号来讲数据进行格式化输出。
- awk可以使用字段为依据,进行数据的重新整理与输出。
- 文件的比对中,可利用diff及cmp进行比对,其中diff及cmp进行比对,其中diff主要用在纯文本文件方面的新旧版本比对。
- patch指令可以将旧版数据更新到新版。
8 shell script
8.1 为什么学习shell script
shell script 是利用shell的功能所写的一个程序,这个程序是使用纯文本文件,将一些shell的语法与指令(含外部指令)写在里面,搭配正规表示法、管线命令与数据流重导向等功能。
shell:文字接口底下让我们与系统沟通的一个工具接口。
shell script的特点:
- 自动化管理的重要性
- 追踪与管理系统的重要工作
- 简单入侵检测功能
- 连续指令单一化
- 简易的数据处理
- 跨平台支持与学习历程较短
shell script的注意事项:
- 1.指令的执行时从上而下、从左而右的分析与执行。
- 2.指令、选项与参数间的多个空白都会被忽略掉。
- 3.空白行也将被忽略掉,并且tab按键所推开的空白同样视为空格键。
- 4.如果读取到一个enter符号(CR),就尝试开始执行该行命令。
- 5.至于如果一行的内容太多,则可以使用[\enter]来延伸至下一行。
shell script的执行:
1.直接指令下达:shell.sh档案必须要具备可读与可执行(rx)的权限,然后:
- 绝对路径:使用/home/dmtsai/shell.sh来下达指令
- 相对路径:假设工作目录在/home/dmtsai/,则使用./shell.sh来执行
- 变量[PATH]功能:将shell.sh放在PATH指定的目录内,例如:~/bin/
2.以bash程序来执行:透过[bash shell.sh]或[sh shell.sh]来执行
PS:script的执行方式差异(source、sh script、./script)
- 1.利用直接执行的方式来执行script:比如sh sh02.sh

- 2.利用source来执行的脚本:在父程序中执行:source sh02.sh
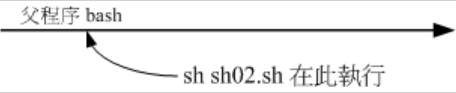
//sh01.sh脚本内容如下: #!/bin/bash #program: # This program shows "Hello World!" in your screen. #History: #2020/04/27 wendy First release echo -e "Hello World!\a\n" // -e开启转义 exit 0 //执行方式一,先赋予权限,在执行 [wendy@cs011 scripts]$ chmod a+x sh01.sh [wendy@cs011 scripts]$ ./sh01.sh Hello World! //执行方式二, /bin/sh 是/bin/bash(连结档),使用sh shell.sh告诉系统,直接bash的功能来执行shell.sh文件内的相关指令。 [wendy@cs011 scripts]$ sh sh01.sh Hello World! [wendy@cs011 scripts]$ bash sh01.sh Hello World!
8.2 善用判断式:$?、&&、||
利用test指令的测试功能
//检测系统上面某些档案或相关的属性时 //比如:检查/dmtsai是否存在,同时透过$? 或&& 及||来展现整个结果。 eg: [wendy@cs011 scripts]$ test -e /dmtsai && echo "exits" || echo "not exist" not exist
[root@www scripts]# vi sh05.sh #!/bin/bash # Program: # User input a filename, program will check the flowing: # 1.) exist? 2.) file/directory? 3.) file permissions # History: PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH # 1. 输入文件名,并且判断是否真的有输入字符串? echo -e "Please input a filename, I will check the filename's type and \ permission. \n\n" read -p "Input a filename : " filename test -z $filename && echo "You MUST input a filename." && exit 0 # 2. 判断文件是否存在?若不存在则显示信息并结束脚本 test ! -e $filename && echo "The filename '$filename' DO NOT exist" && exit 0 # 3. 开始判断文件类型与属性 test -f $filename && filetype="regulare file" test -d $filename && filetype="directory" test -r $filename && perm="readable" test -w $filename && perm="$perm writable" test -x $filename && perm="$perm executable" # 4. 开始输出信息! echo "The filename: $filename is a $filetype" echo "And the permissions are : $perm"
利用判断符号[],注意事项:
- 在中括号[]内的每个组件都需要有空格键来分隔。
- 在中括号内的变数,最好都以双引号括号起来。
- 在中括号内的常数,最好都以单引号或双引号括号起来。
//判断$HOME这个变量是否为空 [ -z "$HOME" ];echo $? //都有空格键,判断2个值是否相等(逻辑判断) [ "$HOME" == "$MAIL" ] 类似于 test $HOME = $MAIL
shell script的默认变数($0,$1,$2...):![]()
- $#:代表后接的参数[个数]
- $@:代表[ "$1" "$2" "$3" "$4" ],每个变量都是独立的(用双引号括起来)
- $*:代表["$1c$2c$3c$4"],其中c为分隔字符,默认为空格键,所以本例中代表[ "$1" "$2" "$3" "$4" ]之意。
8.3 shell 的基础操作
- 对谈式脚本
- 随日期变化
- 数值运算
对谈式脚本:变量内容由用户决定.
//read命令用于从标准输入读取数值(单行数据读取)。 -a:变量[数组],然后给其赋值,默认是以空格为分隔符。 -d:后面跟一个标识符,其实只有其后的第一个字符有用,作为结束的标志 -p:后面跟提示信息 -e:在输入的时候可以使用命令补全功能 -n:数字 eg: //sh02.sh的脚本内容如下 #!/bin/bash #program: # User inputs his first name and last name.Program shows his full name. #History: #2020/4/27 wendy first release PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH read -p "please input your first name:" firstname read -p "please input your last name:" lastname echo -e "\n your full name is :$firstname $lastname" //执行命令,显示结果 [wendy@cs011 scripts]$ sh sh02.sh please input your first name:wendy //输入wendy please input your last name:we //输入we your full name is :wendy we //显示wendy we
sh02.sh在子程序中运作:
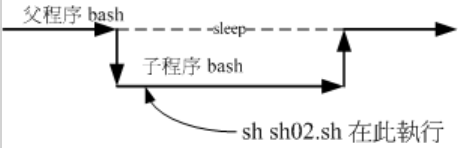
随日期变化:利用date进行文件的建立
//sh03.sh文件内容 #!/bin/bash #program: # program creates three files,which named by user's input and date command #History: #2020/4/27 wendy first release PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH echo -e "I will use touch command to create 3 files" read -p "please input your filename:" fileuser filename=${fileuser:-"filename"} date1=$(date --date='2 days ago' +%Y%m%d)# 前两天的日期 date2=$(date --date='1 days ago' +%Y%m%d)# 前一天的日期 date3=$(date +%Y%m%d) file1=${filename}${date1} file2=${filename}${date2} file3=${filename}${date3} touch "$file1" touch "$file2" touch "$file3" //命令执行结果 [wendy@cs011 scripts]$ sh sh03.sh I will use touch command to create 3 files please input your filename:we [wendy@cs011 scripts]$ ll -rw-rw-r-- 1 wendy wendy 744 Apr 28 12:47 sh03.sh -rw-rw-r-- 1 wendy wendy 0 Apr 28 12:47 we20200426 -rw-rw-r-- 1 wendy wendy 0 Apr 28 12:47 we20200427 -rw-rw-r-- 1 wendy wendy 0 Apr 28 12:47 we20200428
数值运算 :var=$((运算内容)) 或declare -i total=$firstnu*$secnu
//sh04.sh的内容 #!/bin/bash #program: # user inputs 2 integer numbers;program will cross these two numbers. #History: #2020/4/27 wendy first release PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH echo -e "you should input 2 number,I will cross them!\n" read -p "first number:" firstnu read -p "second number:" secnu total=$(($firstnu*$secnu)) echo -e "\nThe result of $firstnu x $secnu is ==$total" //执行结果 [wendy@cs011 scripts]$ sh sh04.sh you should input 2 number,I will cross them! first number:4 second number:4 The result of 4 x 4 is ==16
8.4 条件判断式
- 利用if...then:单层简单条件,多重复杂条件,检验$1内容,网络状态,退伍
- 利用case...esac判断
- 利用function功能
单重条件判断式:
//条件判断式中的内容可以通过 && 或 || 隔开。 if [ 条件判断式 ]; then 当条件判断式成立时,可以进行的指令工作内容 fi //条件判断式内容 [ "$yn" == "Y" -o "$yn" == "y" ] 类似于[ "$yn" == "Y" ] || [ "$yn" == "y" ] eg: if [ "$yn" == "Y" ] || [ "$yn" == "y" ] ;then echo "ok,contine" exit 0 fi
多重、复杂条件判断式:
//一个条件判断,分成功进行与失败进行(else) if [ 条件判断式 ];then 当条件判断式成立时,可以进行的指令工作内容; else 当条件判断式不成立时,可以进行的指令工作内容 fi //多个条件判断(if...elif...elif...else)分多种不同情况执行 if [ 条件判断式一 ];then 当条件判断式成立时,可以进行的指令工作内容; elif [ 条件判断式二 ];then 当条件判断式不成立时,可以进行的指令工作内容 else 当条件判断式一或二都不成立时,可以进行的指令工作内容 fi eg1: if [ "$yn" == "y" ] || [ "$yn" == "Y" ];then echo "ok,continue" else echo "no ok!" fi eg2: if [ "$yn" == "y" ] || [ "$yn" == "Y" ];then echo "ok,continue" elif [ "$yn" == "n" ] || [ "$yn" == "N" ];then echo "no ok!" else echo "I don't know!" fi
case...in...esac判断
ps:[ case $变量 in ]中[$变量]有两种取得的方式:直接下达式和交互式。
- 直接下达式:[ script.sh variable ]的方式来直接给予$1这个变量的内容
- 交互式:透过read这个指令来让用户输入变量的内容
//case...in...esac判断 case $变量名称 in "第一个变量内容") 程序段 ;; "') "第二个变量内容") 程序段 ;; *) 程序段 ;; esac //需求:使用者能够输入one,two,并且将用户的变量显示在屏幕上 eg1:sh12.sh内容如下
#read -p "please your choice:"$choice
#case $choice in //交互式 case $1 in //下达式 "one") echo "is one" ;; "two") echo "is two" ;; *) echo "usage $0 {one|two}" ;; esac
//下达式命令执行:sh sh12.sh two
//显示结果:is two
function()功能
//frame是自定义的执行指令名称,且function一般要放在设定程序的最前面。 function fname(){ 程序段 }
8.5 循环(loop)
- while...do...done,util...do...done(不定循环)
- for...do...done(固定循环):账号检查,网络状态$(seq)
- for...do...done的数值处理
while...do...done,util...do...done(不定循环):
//while...do...done,中括号内的状态condition就是判断式 //当condition条件成立时,就进行循环,直到condition的条件不成立才停止 while [ condition ] do 程序段落 done //until...do...done(不定循环) //当condition条件成立时,就终止循环,否则就持续进行循环的程序段 until[ condition ] do 程序段落 done //求1+2+...+100的和 eg1: s=0 i=0 while [ "$i" != "100" ] do i=$(($i+1)) s=$(($s+$i)) done echo "the result of '1+2+3+...+100'is ==>$s"
for...do...done(固定循环):账号检查,网络状态$(seq)
//for...do...done(固定循环):账号检查,网络状态$(seq) for var in con1 con2 con3... do 程序段 done eg1: for animal in dog cat elephant do echo "there are ${animal}s..." done
for...do...done的数值处理
//初始值:某个变量在循环当中的起始值 for(( 初始值;限制值;执行步阶 )) do 程序段 done
重点:
shell script 是利用shell的功能所写的一个程序,这个程序是使用纯文本文件,将一些shell的语法与指令(含外部指令)写在里面,搭配正规表示法、管线命令与数据流重导向等功能。
shell script执行顺序:从上而下、从左而右的分析与执行
shell script的执行,至少需要有r的权限,若需要直接指令下达,则需要拥有r与x的权限
script 的执行以source来执行时,代表在父程序的bash内执行之意
若需要进行判断式,可使用test或中括号[]来处理
使用sh -x script.sh来进行程序的debug
9 shell 简单操作
9.1 变量
语法:变量名=变量值 PS:=两边不能有空格 1、使用变量:$变量名 ex: Name="wendy"#声明变量 echo $Name 或 echo ${Name} #输出变量 ps:花括号可选 2、只读变量:readonly 变量 3、删除变量:unset 变量 4、字符串变量长度获取:${#字符串变量} ps: string="abcd" echo ${#string} #输出4
5、字符串变量提取部分:${变量:1:4} #表示从第二个字符开始,截取4个字符
ex:string="abcdedfg" echo ${变量:1:4} #输出bcde
在bash中,每一个变量的值都是字符串。
9.2 变量类型
局部变量:只对当前shell有效
环境变量:所有程序都能访问环境变量
shell变量:可设置
9.3 符号问题
单引号:变量无效,任何字符原样输出
双引号:可使用变量,可以出现转义字符
ps:拼接字符串用双引号,且变量需要用{}
注释问题:
单行注释:#
多行注释: :<<EOF 注释内容 EOF(EOF可以替换为其他任意字符)
9.4 数组
定义数组:数据名=(值1 值2 值3...值n)或数组名=(
value0
value1
value2
value3
)或 数据名[0]=value0 数据名[1]=value1
ex:array_name=(value0 value1 value2)
读取数组:${数组名[下标]}
ex:value=${数组名[n]} #@表示获取数组中的单个元素
length=${#数组名[@ || *]}# @、*表示获取数组所有元素的长度
9.5 参数处理
$# 脚本后面接的参数的个数
$* 脚本后面所有参数,参数当成一个整体输出,每一个变量参数之间以空格隔开
$@ 脚本后面所有参数,参数是独立的,也是全部输出
$$ 脚本运行的当前进程ID号
$! 后台运行的最后一个进程的ID号
$? 上一条命令执行后返回的状态,0表示没有错误,0以外其他所有值表示有错误
9.6 运算符:
算数运算符: + - * / % = == !=
关系运算符:-eq -ne -gt -ge -lt -le(= != > >= < <=)
布尔运算符:! -o -a(or and)
逻辑运算符: && ||
字符串运算符:= != -z -n $(= != 判断=0为真 判断!=0为真 判断是空为真)
文件测试运算符:(-e -r -w -x -s -d -f -c -b)+文件名 文件存在且可读、可写、可执行、至少有一个字符、是目录、普通文件、字符型特殊文件、块特殊文件
9.7 shell函数:
[ function ] funname [()]
{
action;
[return int;]
}
或者function fun()
或者fun()
ps:参数返回,可以显示加;
9.8 shell 输入/输出重定向:
command > file 将输出重定向到file
command < file 将输入重定向到file
command >> file 将输出以追加的方式重定向到file
n >& m 将输出文件m和n合并
n <& m 将输入文件m和n合并
<<tag 将开始标记tag和结束tag之间的内容作为输入
/dev/null:不希望在屏幕上显示输出结果 ,重定向到垃圾箱/dev/null
