Zookeeper的基本原理(zk架构、zk存储结构、watch机制、独立安装zk、集群间同步复制)
1、Hbase集群的高可用性与伸缩性
HBase可以实现对Regionserver的监控,当个别Regionserver不可访问时,将其负责的分区分给其他Regionsever,其转移过程较快,因为只需要将分区的相关信息转移。Hlog和表中数据实际存储在HDFS上,本身具有多副本机制容错。
Master节点以及HDFS中的Namenode节点,如果只部署一个,可能造成单点故障,可以依托Zookeeper实现这两种关系主节点的高可用性配置。
Zookeeper实现的方法是:部署多个Master或Namenode,并区别为活跃节点和待命节点。当活跃节点发生故障后,待命节点自动提升为活跃节点。由Zookeeper负责监控活跃节点、选择新的活跃节点等功能。
- 活跃节点:接收读写操作。
- 待命节点:从活跃节点实现同步数据。
HBase还可以通过集群间的同步机制,实现(列族)数据的分布式热备份。
2、Zookpeeper的基本原理
场景:为了实现分布式服务中的数据同步与一致性、群组管理监控、分布投票协商与锁(如分布式事务中的二阶段提交)、命令寻址等,需要在集群中提供分布式协调服务。
Zookeeper:一款提供分布式协调服务的开源软件。Zookeeper以Fast Paxos算法为基础,提供分布式协调、选举和锁服务,并基于此扩展出配置维护、组服务、分布式消息队列、分布式通知/协调等功能。
2.1 Zookeeper架构
Zookeeper采用集群化部署方式,一般部署在多台服务器上,以防止单点失效。(一般采用奇数台服务器部署,目的是用于投票时收敛)
服务器可以看做是proposer和acceptor(Zookeeper称为follower)角色的综合。
- 1.在服务器中选出leader进行提案和主持投票,如果leader失效,就重新选举。选举可以通过paxos或fastpaxos进行。
- 2. 理论上全体服务器可以对提案投票,但为了控制网络开销,一般选择部分节点进行投票,而其他节点称为observer,只观察结果进行同步。
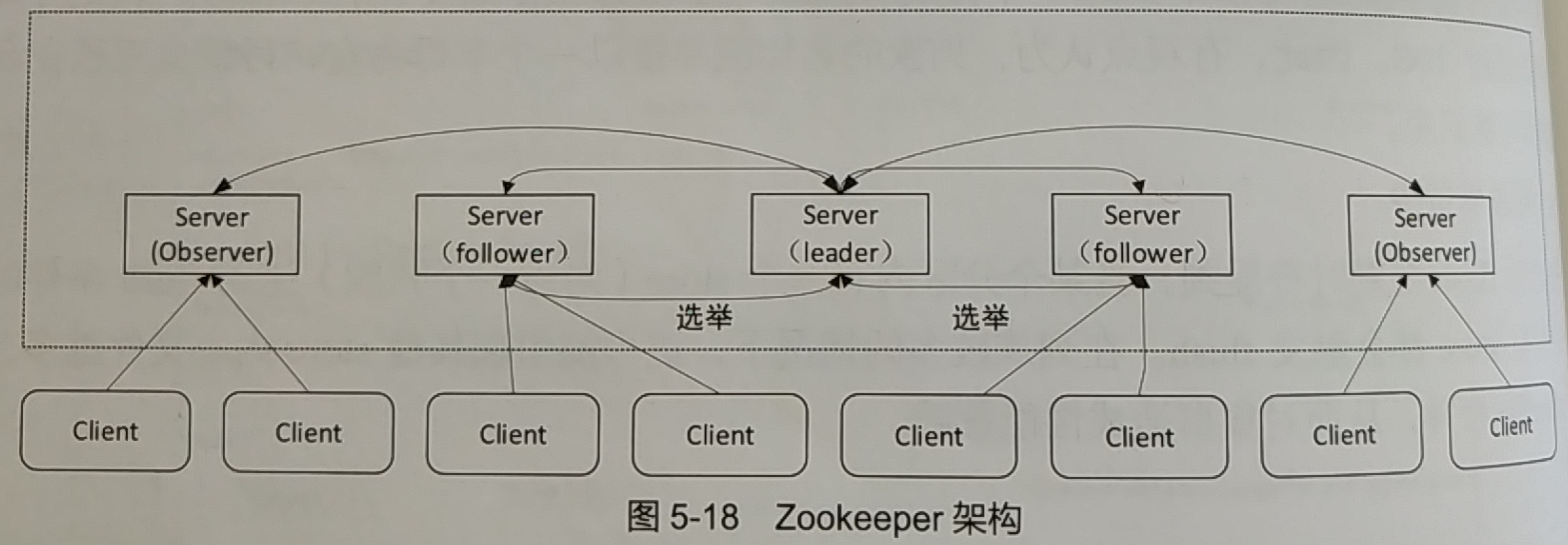
PS:Zookeeper会在集群内同步数据,并通过所谓的watch机制实现对数据更新的监控,因此客户端可以连接到任何一台服务器来监测数据变化,以实现客户端集群内数据的最终一致性、原子性和顺序性等保障。
Zookeeper提供了分布式独享锁、选举、队列等API接口,可以实现配置同步、集群管理等协调性服务。
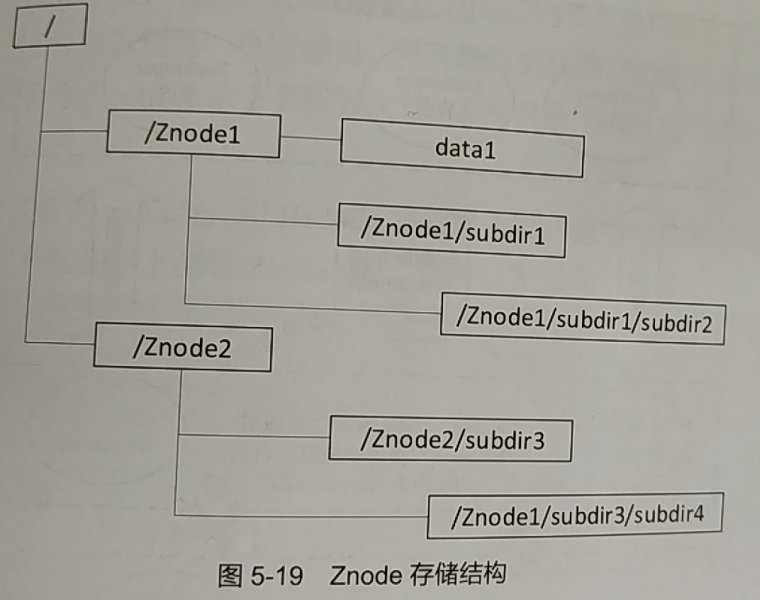
2.2 Znode存储结构
Zookeeper采用层次化目录结构存储数据。目录 ==节点,在zookeeper中称为Znode。
Znode的特点:
- 一次写入、多次读取,数据写入后不可更改。
- 可以存储多个版本的数据,以实现更新顺序性。
- 一次性读取整个Znode,不支持部分读取。
- 根据数据的生命周期,具有4种节点,在创建时确定并且不能再修改。
- 临时节点(EPHEMERAL):不支持子节点,会在客户端会话结束时被删除。
- 临时顺序节点(EPHEMERAL_SEQUENTIAL):临时节点,但父节点会为一级子节点记录创建时间,记录节点的创建顺序。
- 持久节点(PERSISTENT):持久存储,一般根据客户端需求删除。
- 持久顺序节点(PERSISTENT_SEQUENTIAL):持久节点,但父节点会为一级子节点记录创建时间,记录节点的创建顺序。
2.3 Watch机制
客户端可以通过watch机制关注Znode的信息变化,实现配置管理、数据同步和分布式锁等功能。
客户端首先需要注册一个watch,来观察某个Znode。当出现数据更新或被删除、子节点发生变化等情况时,Zookeeper集群会通过异步消息向客户端发送事件通知。通知发送后,该watcher就会失效,如果此时再发送信息变化,客户端就无法获取新的通知,除非客户端在进行新的注册。可见,watch机制能够确保消息的顺序性(旧消息被接收之前,客户端无法获得新消息)以及最终一致性,但无法确保所有的数据变化都能够被观察到。
2.4 Hadoop和HBase对Zookeeper的利用
Hadoop在默认情况下并不会使用Zookeeper。
场景:HDFS和MapReduce采用主从结构,由主节点进行集群管理,子节点之间不会自主进行协调、同步和监控等。这种结构使得子节点易于横向扩展,但主节点存在单点故障问题,即主节点宕机后,整个集群就失效了。Hadoop可以通过Zookeeper的协调能力实现主节点的高可用性,来解决这一个问题。
HBase中自带Zookeeper服务,但也可以禁用后选择外部独立安装的Zookeeper为其提供服务。HBase利用Zookeeper实现Regionserver监控、多Master高可用性管理以及META表入口存储等功能。
3、基于Zookeeper的高可用性
由于HDFS采用分布式部署和数据多副本机制,因此当出现少量Datanode故障或少量机架故障时,并不会出现数据损失或数据处理任务失败等情况。但Namenode角色在集群中只有一个,因此存在单点故障风险。HDFS的NamenodeHA(高可用性,High Available)方案:
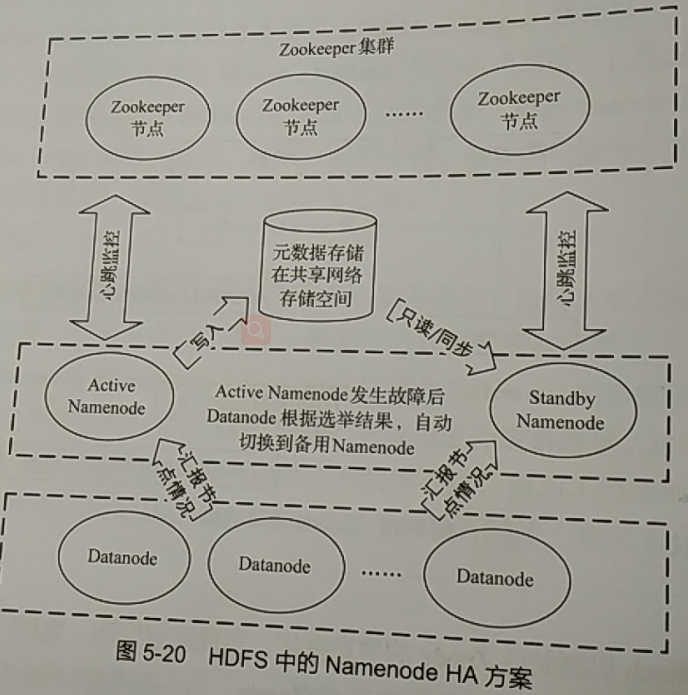
该方案中存在2个Namenode,其中Active Namenode向集群提供服务,Stanby Namenode为待命状态。Fsimage等信息存储在一个可共享的网络位置,Active Namenode写入数据,Stanby Namenode则只能读取,以防Fsimage出现多版本不一致的情况,即脑裂(brainsplit)。
Zookeeper分布式协调服务器可以监控Active Namenode的健康状态,当发送故障时,通过分布式选举机制将Stanby Namenode提升为Active Namenode,如果原Active Namenode从故障中恢复,则自动降级Stanby Namenode。整个过程自动进行,不需要人工干预。
HBase Hmaster 的高可用性原理与此类似,且在HBase中配置Master高可用性较为简单,只需要在各节点的配置目录下建立一个文本文件,命名为backup-masters,并在其中每行写入一个主机名,即可完成配置。
//当执行start-hbase.sh命令时,直接在作为Master节点的主机上 hbase-daemon.sh start master
4、独立安装Zookeeper
Zookeeper的基本安装步骤:
- 软件部署
- 软件配置
- 启动与使用方法
- HBase使用独立的Zookeeper服务
4.1 软件部署
独立安装Zookeeper是为向Hadoop和HBase共同提供服务的,Zookeeper对操作系统、软件和网络环境的要求与这些组件基本一致,能够安装Hadoop和HBase的节点也可以直接安装Zookeeper。下载Zookeeper之后,可以得到一个压缩包,将其解压到权限合适的目录即可完成基本部署。其中bin目录下为可执行命令,conf目录下为配置文件,lib目录下为对应的库包。
4.2 软件配置
Zookeeper的配置文件为zoo.cfg,纯文本格式。
PS:三台服务器的zoo.cfg文件配置内容完全一致,但在每台服务器的conf下还需要各建立一个myid文件,该文件为纯文本文件,内容分别为1,2,3,对应下文配置的id与本机IP地址的关系。
//假设需要在三台服务器上部署Zookeeper,配置文件 tickTime =2000 dataDir = /zookeeper /data dataLogDir = /zookeeper/logs clientPort = 2181 initLimit = 5 syncLimit = 2 server.1=192.168.10.1:2888:3888 server.2=192.168.10.2:2888:3888 server.3=192.168.10.3:2888:3888 //tickTime=2000 配置内容为超时时间的基础值,单位为毫秒。 //initLimit=5 配置follower与leader之间建立连接后进行同步的最长时间,数值5表示实际时间为5*tickTime。 //syncLimit=5 为leader和follower之间等待回复消息的最大时间,数值2表示2*tickTime。 //dataDir=/tmp/zookeeper 表示zookeeper服务器存储快照文件的目录 //dataLogDir 表示配置 zookeeper事务日志的存储路径,默认指定在dataDir目录下 //clientPort 表示客户端和服务端建立连接的端口号: 2181,为Znode的访问入口地址。 //server.id=host:port1:port2表示Zookeeper集群中有三个节点及其id、ip地址。port1是follower和leader交换消息的端口,port2表示follower选举leader使用的端口。
4.3 启动与使用方法
//在各个节点的linux命令行依次执行启动: zkServer.sh start //jps 或zkServer.sh status 命令查看进程是否成功启动 zkServer.sh status //进入zk命令行环境 zcCli.sh -server 192.168.10.1:2181 //help命令是查看命令列表 help //ls <path> 指令,可以查看各个Znode信息 ls /hbase
4.4 HBase使用独立的Zookeeper服务
默认情况下,HBase利用自带的ZK提供分布式协调服务。默认使用自带ZK命令参数为:HBASE_MANAGES_ZK=true,随着HBase的启动而启动。
//手动控制其Zookeeper的启停 hbase-daemons sh {start,stop} zookeeper
如果使用独立的ZK服务,则需要确保ZK集群先于HBase集群启动。如果有多个HBase集群共享一个Zookeeper服务,则需要在各自的配置文件中,配置不同的Znode入口,方法是hbase-site.xml中配置'zookeeper.znode.parent'为不同的路径。(默认值为/hbase)
5、集群间同步复制
集群间同步(Replication机制),指同时配置两个HBase集群,其中一个为主集群,负责接收所有的写操作。从集群不断从主集群同步数据,但尽可读取。类似于关系型数据库中的读写分离。
集群间同步采用主集群推送方式进行,推送的过程:主集群节点进行flush时,向从集群某个节点发送同步通知,从集群节点获取通知后,读取主集群相应节点上的WAL预写日志,在本地重建数据。
主集群节点发送通知之后,会在Zookeeper中记录已备份WAL的偏移量,使得从集群可以确认备份的位置。如果主集群节点发现之前联系的从集群节点无响应,则会更换另一个从集群节点再次发出备份通知,并回滚WAL的偏移量记录信息。集群复制原理:
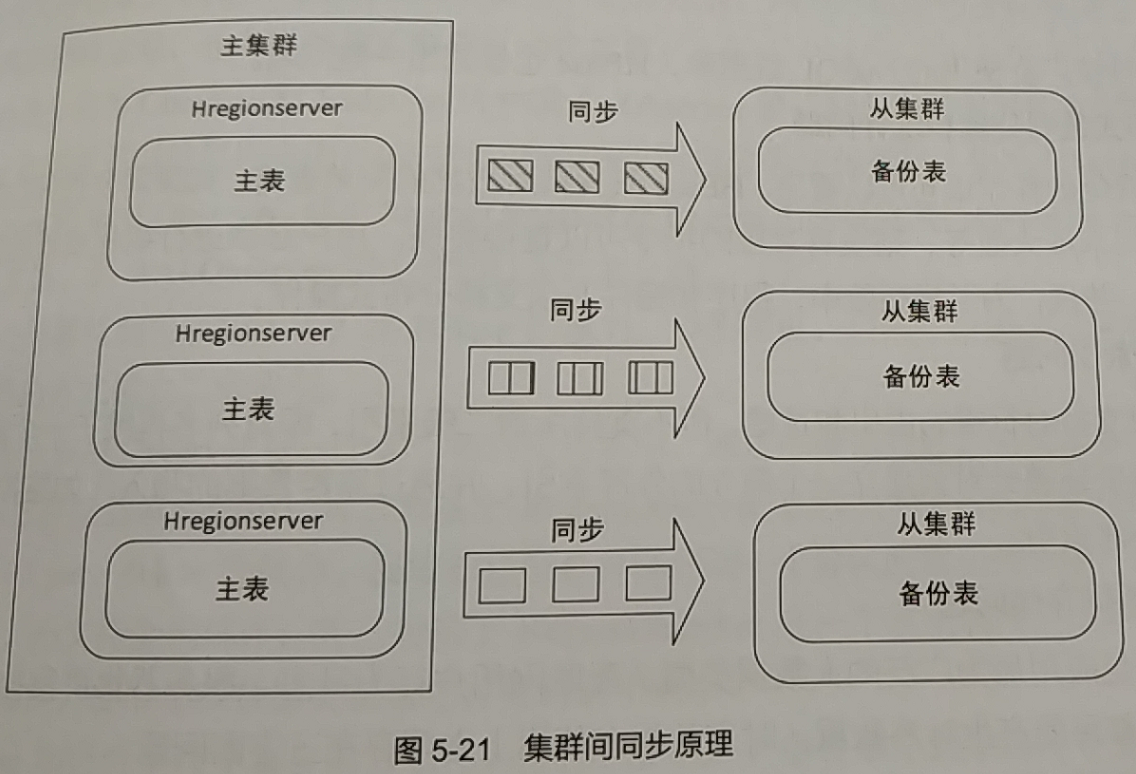
同步工作是异步进行的,即主从集群之间只能保证数据的最终一致性。
配置集群间复制的基本方法:
1、要确保两个集群之间的网络互通。
2、在从集群建立同名、同结构(具有相同列族)的表。
3、主集群的hbase-site.xml中配置hbase.replication参数为true,即设置为允许跨集群同步。
4、在主节点集群的HBase Shell中修改表结构。
disable 'Test' //Test为表名 alter 'Test',{NAME =>'basic',REPLICAITON_SCOPE => '1'} //列族basic,集群复制的配置是针对列族的,REPLICATION_SCOPE属性不能在建表时设置,只能通过alter命令设置。 enable 'Test'
5、在主集群节点HBase Shell中执行命令。
add_peer '1',"slave-zk-1,slave-zk-2,...:2181:/hbase"
让主集群看到从集群的Zookeeper地址、端口、HBase使用的Znode入口(默认为/hbase)等。主从集群可以使用两套Zookeeper,也可以使用同一套Zookeeper,但使用同一套Zookeeper时,主从集群的Znode入口必须是不同的,即hbase-site.xml中zookeeper.znode.parent配置内容是不同的,一般体现在/hbase这一部分不同。
使用编号1(peerid)可以用来完成复制同步的监控管理:
remove_peer '1' enable_peer '1' disable_peer '1'
此外,通过list_peers命令,可以查看复制同步关系列表。
通过stop_replication和start_replication命令用来控制主集群上所有的复制同步启停。
6、HBase的扩展
HBase存在的问题:
- 分布式数据处理和统计问题
- 二级索引问题
- 时序数据存储问题
- 提供类似关系型数据库的功能和操作方式
6.1 协处理器机制(Coprocessor)
协处理器是一个类似于MapReduce的并行处理组件,其基本思想:移动计算的代码远比移动数据低。通过把子任务(类似Map)代码分发到各个Regionserver上,让子任务独立地在各个服务器、表或分区上运行,来实现对数据的监控和操作。
协处理器机制提供了一套编程框架,用户可以非常灵活地编写自动给你一的Coprocessor任务,并且用户还可以级联使用多个Corprocessor组件,完成更复杂的自定义功能。
协处理器分别是Observer和Endpoint两种模式,Observer模式就如同关系型数据库中的触发器,Endpoint模式就如同关系型数据库中的存储过程。Observer可以分给三种类型,分别为RegionObserver、MasterObserver、WALObserver。其中Regionserver是region上的触发器,MasterObserver 是master服务器的触发器,而WALObserver用于预写日志的触发器。
应用协处理器机制可以极大地扩展HBase的能力,举例来说,用户可以通过三种思路,以自动开发协处理器的方式建立二级索引。
- 1.基于WALObserver在一个索引表内生成索引,通过拦截预写日志的写入操作,把相应的键值对更新信息存储到索引表中。
- 2.基于RegionObserver在同一个分区内维护一个索引列族,通过拦截分区的put、delete等操作,提取相应信息存储到同一个分区的索引列族中,这种方式的索引是局部索引,不支持全局排序。
- 3.基于RegionObserver在一个索引表内生成索引,通过拦截put、delete等操作,提取相应数据更新信息存储到索引表中。
HBase中已经实现了集合函数组件、多行事务组件、多行条件删除组件等基于协处理器框架的组件。如phoenix、openTSDB等独立的HBase扩展软件也通过利用协处理器机制,实现更丰富的功能。
6.2 基于HBase的分布式处理
HBase只提供了数据管理和查询功能,如果对数据进行统计、聚合等操作则需要借助分布式处理架构。
大数据领域常见的分布式处理架构:MapReduce、Spark等的输入输出一般都是HDFS上的文件,但也可设置为从HBase表读取数据,或将数据写入HBase.
1.基于MapReduce的分布式处理
HBase中的数据导入导出、行计数操作等都是调用MapReduce实现的。
用户也可以自定义开发MapReduce程序,指示器连接HBase的Zookeeper地址,并获得目标表格和分区信息。通过在MapReduce代码中嵌入scan和put的方法,实现并行从HBase表中查询数据,或将数据并行写入到HBase表中。
2.基于Spark的分布式处理
Spark是一种新兴的开源分布式处理框架,其性能优于MapReduce。
3.与Hive工具联合使用
Hive是基于Hadoop系统的分布式数据仓库,能够提供增删改查等数据操作。它将结构化的数据文件映射为一张数据库表,并提供简单的类似SQL中语法的HiveQL语言进行数据查询。Hive通过对Hive QL语句进行语法分析、编译、优化、生成查询计划、最后大部分任务转换为MapReduce或Tez任务,小部分Hive QL语句直接进行处理,不转化为MapReduce。
Hive和HBase可以很方便的结合使用,其方式是使用Hive自带的hive-hbase-handler组件把hive和hbase结合起来。将数据存储到HBase,在进行复杂数据处理时,通过使用hive对hive QL语句进行操作,把Hive QL命令转化为操作Hbase指令或MapReduce任务,实现数据的写入、查询或其他复杂操作。
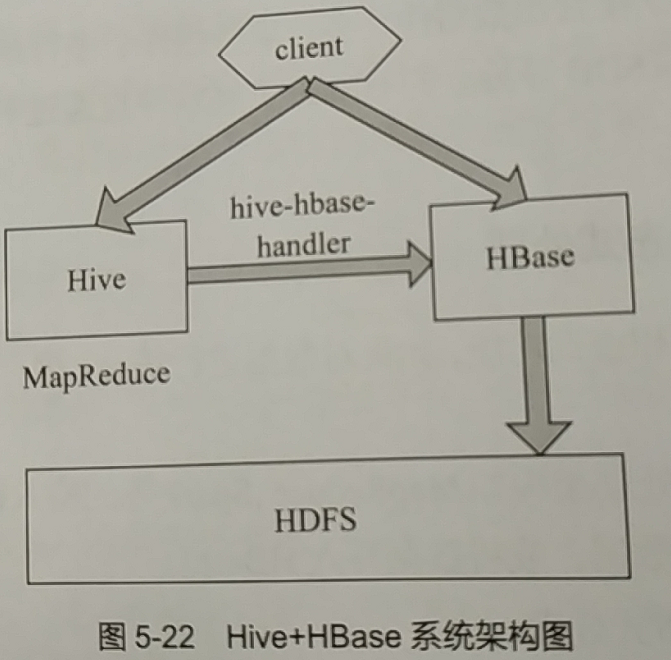
Hive工具提供了类似HBase Shell的命令行环境,通过下面的命令可以在启动Hive的Shell环境时,建立和HBase主节点或Zookeeper集群中的META表的联系:
//在Hive的shell环境下执行Hive QL语句
hive --hiveconfhbase.master=nodel:16000 hive --hiveconfhbase.zookeeper.quorum=node1
CREATE TABLE thehivetable(key int,value string) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping"=":key,cf1:val") TBLPROPERTIES ("hbase.table.name" = "thehbasetable "); //建立一个Hive-HBase联合表,关键参数:STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler',指明了存储方式。
//该表在Hive中的表名为thehivetable,可以看做一个普通的面向行的表(即类似关系型数据库表)。具有key 和 value两个列,前者为整型,后者为字符串类型。 //hbase的表名为thehbasetable,将thehivetable表中的第一列映射为行键,第二列映射列族cf1中的列val
//在Hive的Shell,通过下面命令看到thehivetable表,描述其结构 showtables describethehivetable //在hive中删除表,hbase的表也会被删掉 droptablethehivetable //在hbase的shell命令 list desc 'thehbasetable'
