Python学习笔记【第五篇】:基础函数
一、函数:函数定义关键字def 后跟函数名称
定义函数:
1、申请内存空间保存函数体代码
2、将上述内存地址绑定到函数名
3、定义函数不会执行函数体代码,但是会检测函数体语法
调用函数:
1、通过函数名找到函数的内存地址
2、然后加上括号就是在触发函数体代码的执行
def 函数名(参数):
... 函数体 ... 返回值案例:
# 定义函数
def say_hei():
print('hello world!!')
# 函数调用
say_hei()
调用函数
函数的调用:函数名加括号 1 先找到名字 2 根据名字调用代码
函数的定义主要有如下要点:
- def:表示函数的关键字
- 函数名:函数的名称,日后根据函数名调用函数
- 函数体:函数中进行一系列的逻辑计算,如:发送邮件、计算出 [11,22,38,888,2]中的最大数等...
- 参数:为函数体提供数据
- 返回值:当函数执行完毕后,可以给调用者返回数据。
二、参数
形参与实参
形参:函数定义的参数称之为形式参数 ,相当于变量名。
实参:在调用函数阶段传入的值称之为实际参数,相当于变量值。
形参与实参关系:
1:在调用阶段,实参(变量值)会绑定给形参(变量名)
2:这种绑定关系只会在函数体内使用
3:实参与形参的绑定关系在函数调用生效,函数调用结束后解除绑定关系。
1:位置参数
在函数定义阶段:按照从左到右顺序依次定义的参数称之为位置参数
在函数调用阶段:按照从左到右顺序位置实参必须从左到右依次传值
2:关键字参数
在函数定义阶段:按照从左到右顺序依次定义的参数,每个参数必须被传参,可以不按顺序。
在函数调用阶段:按照key=value的形式传入的值,可以不按照定义的顺序。
如:func(a=1,b=2,c=3)
3:默认形参
在函数定义阶段:在函数定义阶段已经被赋值。
在函数调用阶段:在调用函数的时候可以不用传值。
4:可变参数(*和**)
在函数定义阶段:
*args :用来接收溢出的位置实参 ,会被*保存成元组的格式
**kwargs:用来接收溢出的关键字实参,会被**保存成字典格式
在函数调用阶段:在函数调用时候参数不固定。如:
a=[1,2,3]
func(*a) # 调用
函数调用注意:
1:位置实参必须放在关键字实参前
2:不能为同一个形参重复传值
3:*args必须在**kwargs之前
函数的有三种不同的参数:
- 普通参数
-
# ######### 定义函数 ######### # name 叫做函数func的形式参数,简称:形参 def func(name): print('%s hello!'%name) # ######### 执行函数 ######### # 'zhangsan' 叫做函数func的实际参数,简称:实参 func('zhangsan') - 默认参数
-
def func(name, age = 18): print("%s:%s" %(name,age)) # 指定参数 func('zhangsan', 19) # 使用默认参数 func('lisi') 注:默认参数需要放在参数列表最后 - 动态参数
def func(*args):
print (args)
# 执行方式一
func(11,33,4,4454,5)
# 执行方式二
li = [11,2,2,3,3,4,54]
func(*li)
def func(**kwargs):
print (args)
# 执行方式一
func(name='zhangsan',age=18)
# 执行方式二
li = {'name':'zhangsan', age:18, 'gender':'male'}
func(**li)
def func(*args, **kwargs):
print(args)
print(kwargs)
内置函数
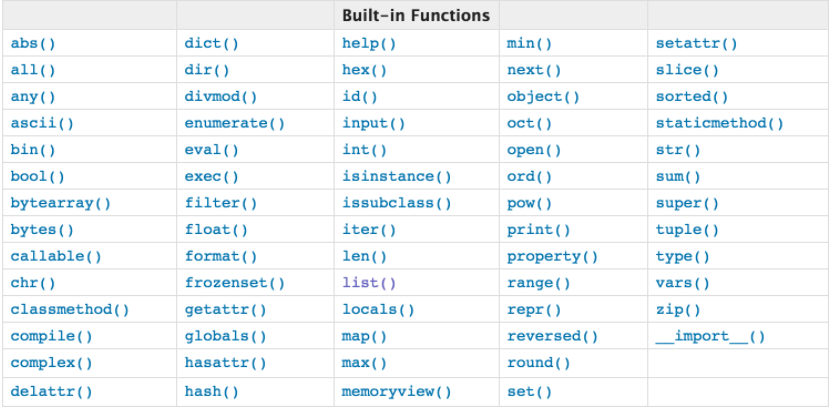
函数分类
#1、内置函数 为了方便我们的开发,针对一些简单的功能,python解释器已经为我们定义好了的函数即内置函数。对于内置函数,我们可以拿来就用而无需事先定义,如len(),sum(),max() ps:我们将会在最后详细介绍常用的内置函数。 #2、自定义函数 很明显内置函数所能提供的功能是有限的,这就需要我们自己根据需求,事先定制好我们自己的函数来实现某种功能,以后,在遇到应用场景时,调用自定义的函数即可。例如
函数使用的原则:先定义,再调用
函数即“变量”,“变量”必须先定义后引用。未定义而直接引用函数,就相当于在引用一个不存在的变量名
#测试一
def test():
print('from test')
func()
test() #报错
#测试二
def func():
print('from func')
def test():
print('from test')
func()
test() #正常
#测试三
def test():
print('from test')
func()
def func():
print('from func')
test() #会报错吗?
#结论:函数的使用,必须遵循原则:先定义,后调用
#我们在使用函数时,一定要明确地区分定义阶段和调用阶段
#定义阶段
def test():
print('from test')
func()
def func():
print('from func')
#调用阶段
test()
名称空间 :存放名字的地方,是对栈区的划分,把栈区换分成了不同的片
1:内置名称空间
存放的名字:存放的式python解析器内置的名字
生命周期:python解析器启动的时候产生,python解析器关闭则销毁
2:全局名称空间
存放的名字:只要不是函数内定义的,也不是内置的,剩下的都是全局名称空间的名字
生命周期:python文件执行则产生,执行完毕则销毁
3:局部名称空间
存放的名字:在调用函数时,运行函数体代码过程中产生的函数内的名字
生命周期:在调用函数式存活,调用完毕后则销毁
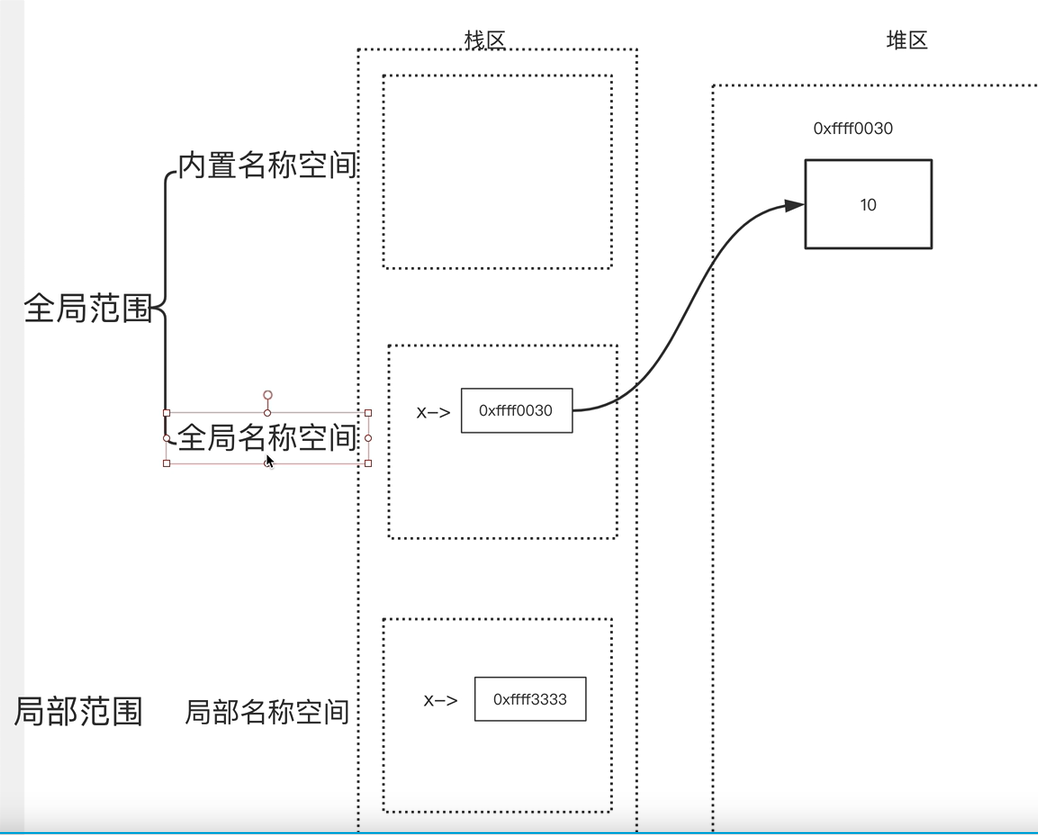
名称空间加载顺序:内置名称空间>全局名称空间>局部名称空间
名称空间销毁顺序:内置名称空间<全局名称空间<局部名称空间
名称空间的查找顺序: 当前所在的位置向上一层一层查找
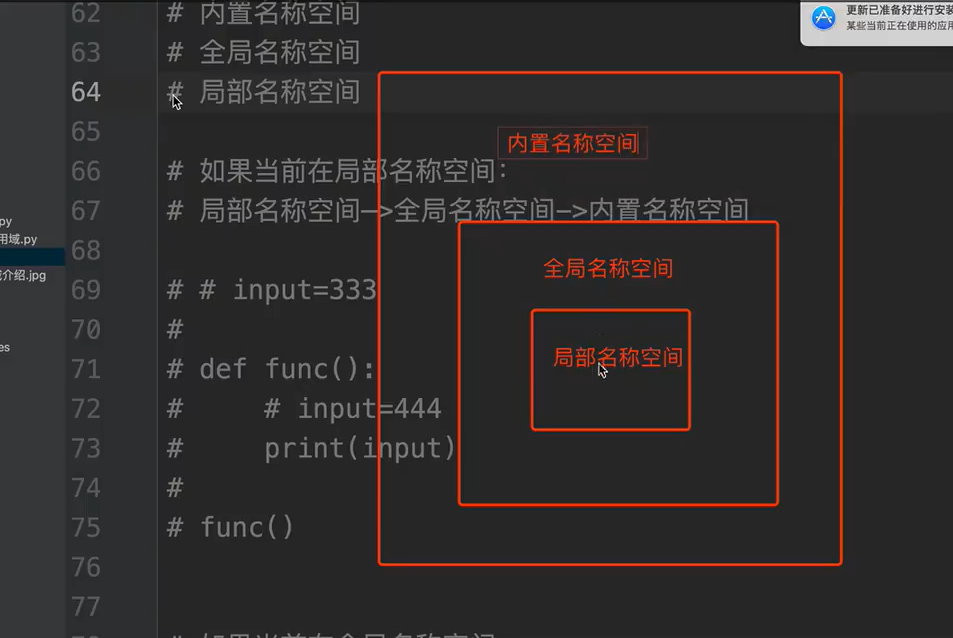
注意:名称空间的“嵌套”关系是以函数定义阶段为准,与调用关系无关。
如下:
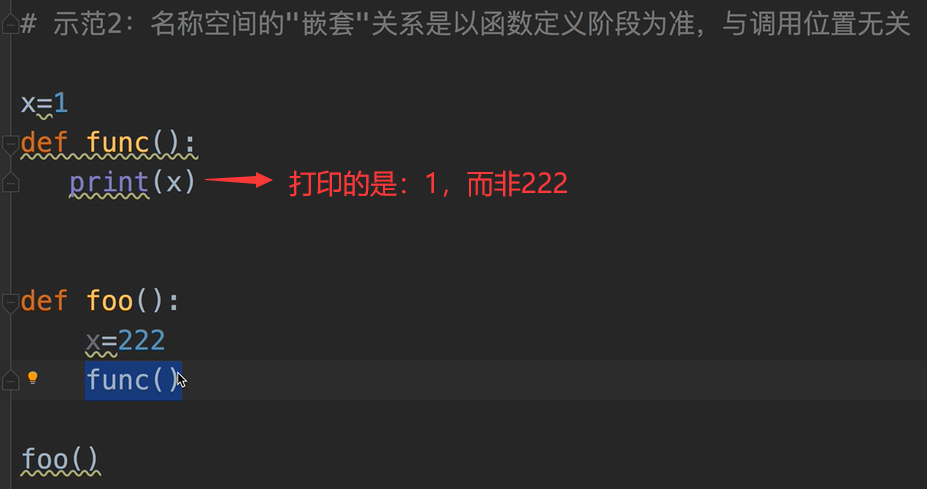
函数嵌套定义:

函数的嵌套调用
def testB():
print('---- testB start----')
print('这里是testB函数执行的代码...(省略)...')
print('---- testB end----')
def testA():
print('---- testA start----')
testB()
print('---- testA end----')
testA()
结果:
---- testA start----
---- testB start----
这里是testB函数执行的代码...(省略)...
---- testB end----
---- testA end----
小总结:
- 一个函数里面又调用了另外一个函数,这就是所谓的函数嵌套调用

- 如果函数A中,调用了另外一个函数B,那么先把函数B中的任务都执行完毕之后才会回到上次 函数A执行的位置
应用
# 求3个数的和
def sum3Number(a,b,c):
return a+b+c # return 的后面可以是数值,也可是一个表达式
# 完成对3个数求平均值
def average3Number(a,b,c):
# 因为sum3Number函数已经完成了3个数的就和,所以只需调用即可
# 即把接收到的3个数,当做实参传递即可
sumResult = sum3Number(a,b,c)
aveResult = sumResult/3.0
return aveResult
# 调用函数,完成对3个数求平均值
result = average3Number(11,2,55)
print("average is %d"%result)
局部变量
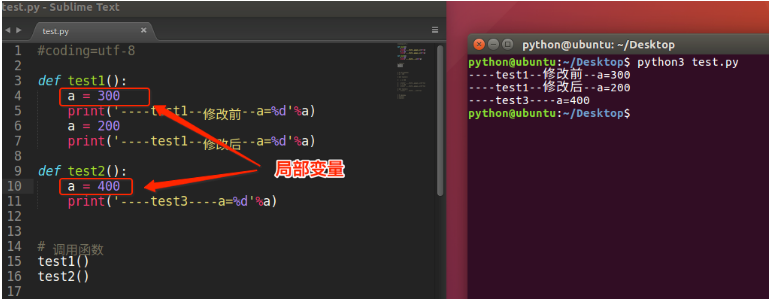
- 局部变量,就是在函数内部定义的变量
- 不同的函数,可以定义相同的名字的局部变量,但是各用个的不会产生影响
- 局部变量的作用,为了临时保存数据需要在函数中定义变量来进行存储,这就是它的作用
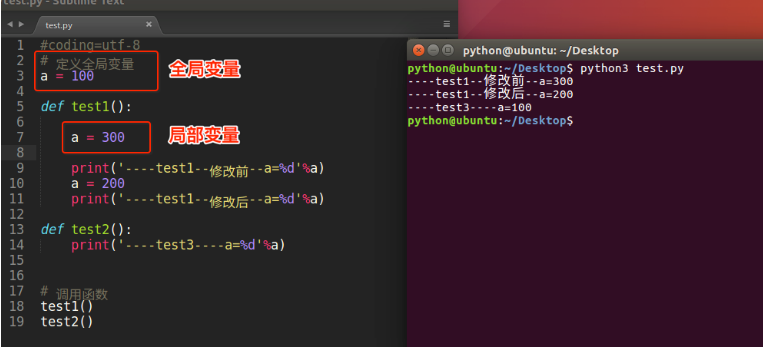
全局变量
# 定义全局变量
a = 100
def test1():
print(a)
def test2():
print(a)
# 调用函数
test1()
test2()
全局变量和局部变量名字相同问题
修改全局变量 关键字:global
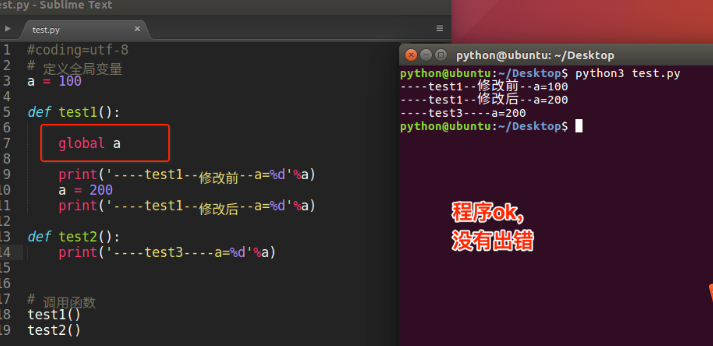
- 在函数外边定义的变量叫做
全局变量 - 全局变量能够在所有的函数中进行访问
- 如果在函数中修改全局变量,那么就需要使用
global进行声明,否则出错 - 如果全局变量的名字和局部变量的名字相同,那么使用的是局部变量的,小技巧
强龙不压地头蛇
可变类型的全局变量
>>> a = 1 >>> def f(): ... a += 1 ... print a ... >>> f() Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 2, in f UnboundLocalError: local variable 'a' referenced before assignment >>> >>> >>> li = [1,] >>> def f2(): ... li.append(1) ... print li ... >>> f2() [1, 1] >>> li [1, 1]
- 在函数中不使用global声明全局变量时不能修改全局变量的本质是不能修改全局变量的指向,即不能将全局变量指向新的数据。
- 对于不可变类型的全局变量来说,因其指向的数据不能修改,所以不使用global时无法修改全局变量。
- 对于可变类型的全局变量来说,因其指向的数据可以修改,所以不使用global时也可修改全局变量。
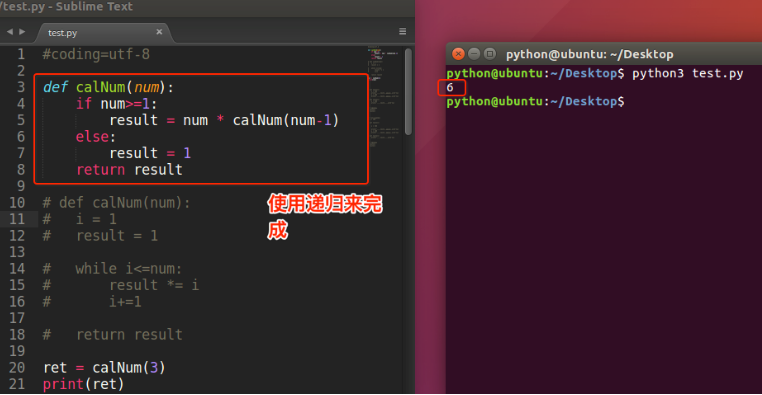
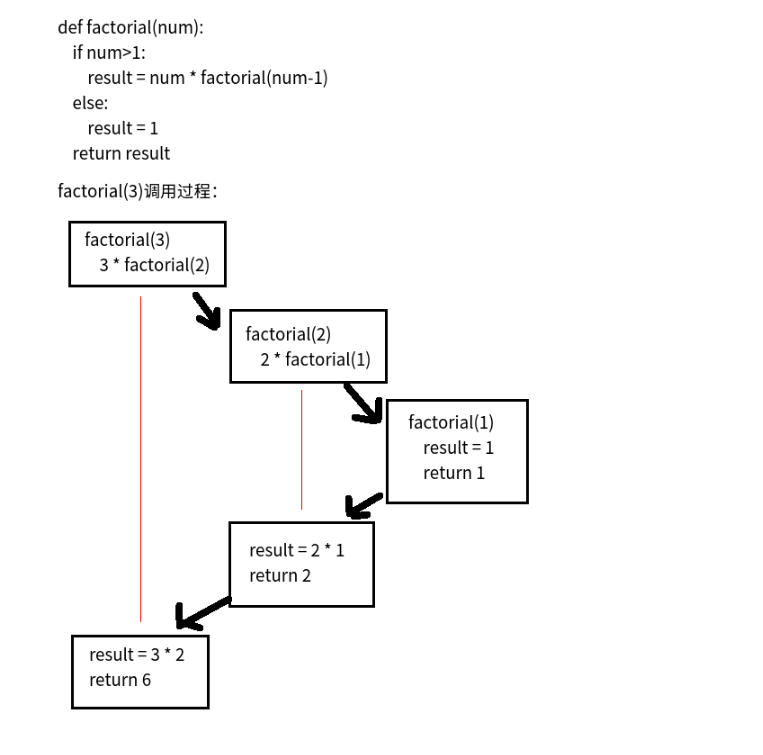
递归函数
如果一个函数在内部不调用其它的函数,而是自己本身的话,这个函数就是递归函数。
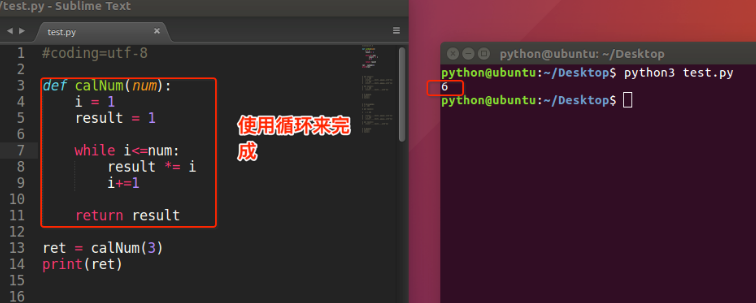
看阶乘的规律
1! = 1 2! = 2 × 1 = 2 × 1! 3! = 3 × 2 × 1 = 3 × 2! 4! = 4 × 3 × 2 × 1 = 4 × 3! ... n! = n × (n-1)!
原理
匿名函数
用lambda关键词能创建小型匿名函数。这种函数得名于省略了用def声明函数的标准步骤。
lambda函数的语法只包含一个语句,如下:
lambda [arg1 [,arg2,.....argn]]:expression
例题
sum = lambda arg1, arg2: arg1 + arg2
#调用sum函数
print ("Value of total : ", sum( 10, 20 ))
print ("Value of total : ", sum( 20, 20 ))
# 匿名函数 关键字:lambda
l = lambda x: x + 1
print(l(5))
print("=================== map函数==============")
jia = lambda x: x + 1;
jian = lambda x: x - 1
chen = lambda x: x * 1
chu = lambda x: x / 1
def map_text(func, array):
arr1 = []
for i in array:
f = func(i)
arr1.append(f)
return arr1
arr = [1, 2, 3, 4, 5]
new_array = map_text(lambda x: x - 1, arr)
print(new_array)
print("=================== filter函数==============")
def filter_text(func, array):
new_array = []
for i in array:
if func(i):
new_array.append(i)
return new_array
str_array = ['zhangsan_sb', 'lisi_sb', 'wanger', 'mazi']
s = filter_text(lambda x: x.endswith('sb'), str_array)
print(s)
print("=================== reduce函数==============")
def reduce_text(func, array, init=None):
if init is None:
sum = array.pop(0)
else:
sum = init
for i in array:
sum = func(sum, i)
return sum
int_array = [1, 2, 3, 4, 5, 6, 7, 8, 9]
su = reduce_text(lambda x, y: x + y, int_array)
print(su)
闭包函数
#内部函数包含对外部作用域而非全局作用域的引用
#提示:之前我们都是通过参数将外部的值传给函数,闭包提供了另外一种思路,包起来喽,包起呦,包起来哇
def counter():
n=0
def incr():
nonlocal n
x=n
n+=1
return x
return incr
c=counter()
print(c())
print(c())
print(c())
print(c.__closure__[0].cell_contents) #查看闭包的元素
闭包的意义与应用
#闭包的意义:返回的函数对象,不仅仅是一个函数对象,在该函数外还包裹了一层作用域,这使得,该函数无论在何处调用,优先使用自己外层包裹的作用域
#应用领域:延迟计算(原来我们是传参,现在我们是包起来)
from urllib.request import urlopen
def index(url):
def get():
return urlopen(url).read()
return get
baidu=index('http://www.baidu.com')
print(baidu().decode('utf-8'))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号