Python学习笔记【第八篇】:Python内置模块、日志模块、三元表达式、列表生成式
什么时模块
Python中的模块其实就是XXX.py 文件
模块分类
Python内置模块(标准库)
自定义模块
第三方模块
使用方法
import 模块名
form 模块名 import 方法名
说明:实际就是运行了一遍XX.py 文件
导入模块也可以取别名
如: import time as t
import time as t print(t.time())
定位模块
- 当前目录
- 如果不在当前目录,Python则搜索在shell变量PYTHONPATH下的每个目录。
- 如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为/usr/local/lib/python/
- 模块搜索路径存储在system模块的sys.path变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。
自定义模块
我们自己写的XX.py 文件就是一个模块,在项目中可以引用这个模块调用里面的方法。
__all__[]关键字
__all__ = ["函数名","类名","方法名"]
没有all关键字 所有方法都可以访问到
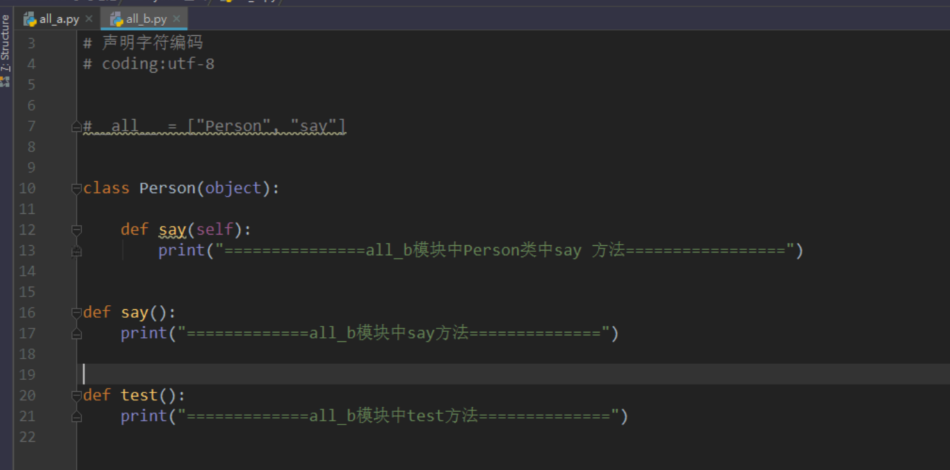
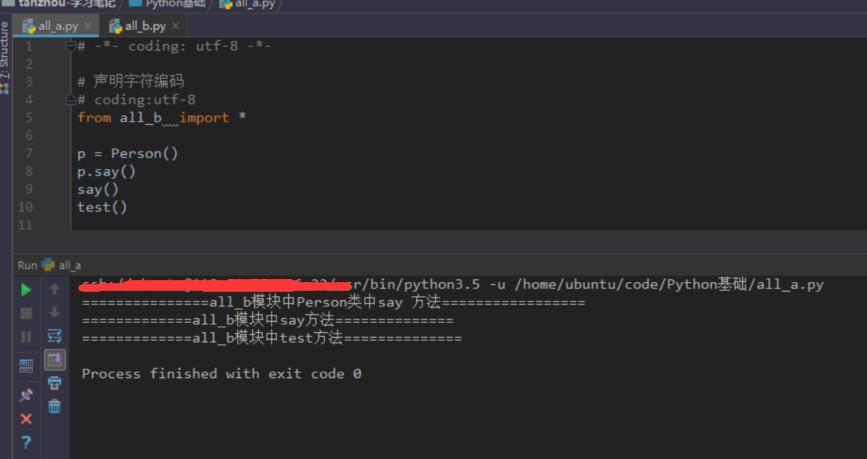
使用all关键字
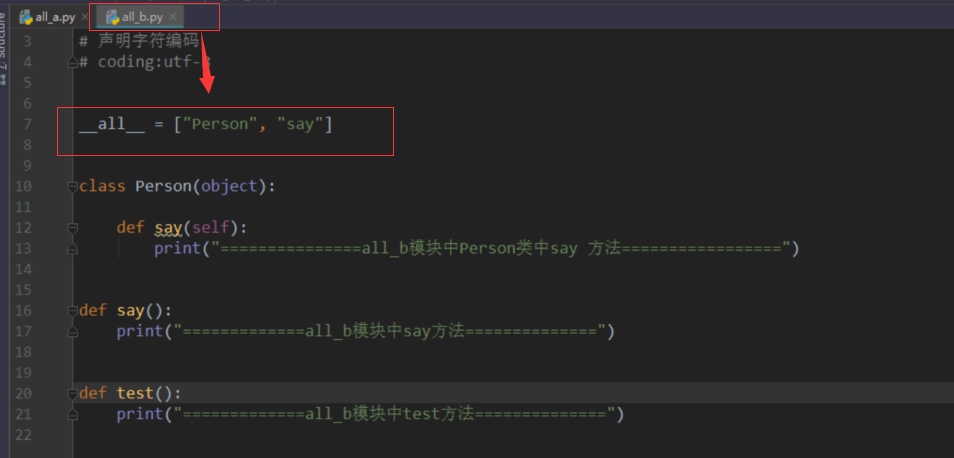
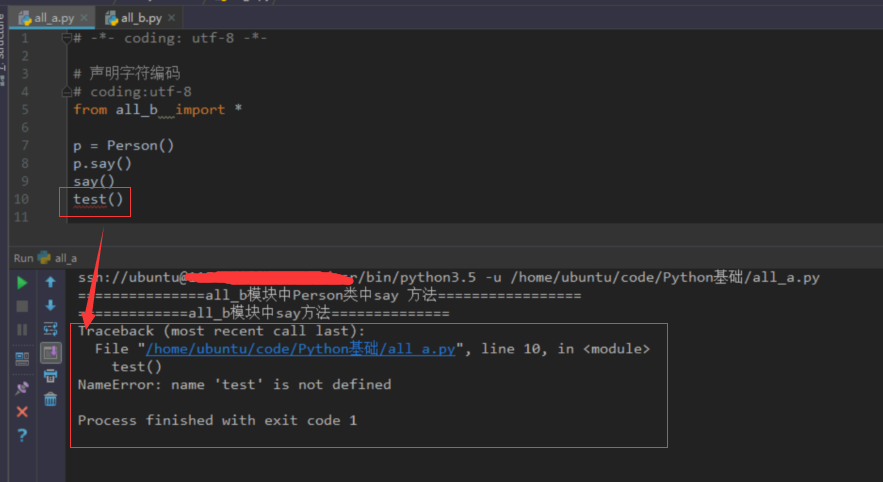
总结
- 如果一个文件中有__all__变量,那么也就意味着不在这个变量中的元素,不会被from xxx import *时导入
模块包
模块包就是为了防止模块重名
两个模块在同一个文件夹里 并且有个__init__.py 文件
__init__.py 文件内容
# -*- coding: utf-8 -*-
# 声明字符编码
# coding:utf-8
# 在外部文件中 import all中的模块
__all__ = ["receMsage","myModelDemo"] #"myModelDemoOne"
import sys
sys.path.append('/home/ubuntu/code/Python核心编程')
print(sys.path)
# 外部文件中访问模块中的方法
from.import receMsage
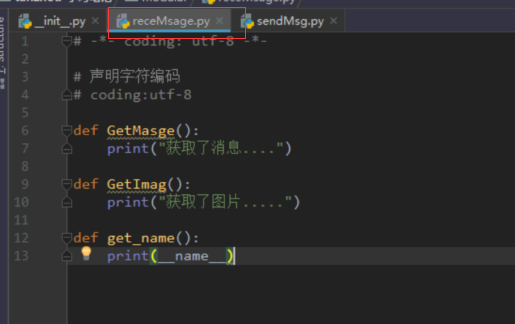
使用:

总结:
- 包将有联系的模块组织在一起,即放到同一个文件夹下,并且在这个文件夹创建一个名字为
__init__.py文件,那么这个文件夹就称之为包 - 有效避免模块名称冲突问题,让应用组织结构更加清晰
标准库
import os import sys import random import time import datetime import json import pickle import shelve import xml.etree.ElementTree as et import xml import configparser import hashlib import logging import re
模块笔记
def time_test():
print('\r\n============time时间模块测试============\r\n')
"""
1:时间戳:time.time() 1970 1 1 0点 秒数
2:结构化时间: time.localtime() 和 time.gmtime() 返回的是时间对象(tm_year,tm_mon,tm_wday)
3:字符串时间
"""
print("时间戳:%s" % time.time())
t1 = time.localtime()
# print(dir(t1))
print('返回时间对象:%s 年 %s 月 %s 日' % (t1.tm_year, t1.tm_mon, t1.tm_mday))
# t2 = time.gmtime()
# print(dir(t2))
# 时间戳转为时间对象(结构化时间)
t3 = time.localtime()
print(t3)
# 将结构化时间转为时间戳
t4 = time.mktime(t3)
print(t4)
# 将结构化时间转字符串时间
t5 = time.strftime("%Y-%m-%d %X", t3)
print(t5)
t8 = time.asctime(t3)
print(t8)
# 将字符串时间转为结构化时间
t6 = time.strptime(t5, '%Y-%m-%d %X')
print(t6)
# 将时间戳转为特定的字符串时间
t7 = time.ctime(t4)
print(t7)
# 睡眠多少秒才继续执行
# time.sleep(2)
def random_test():
print('\r\n============random模块测试============\r\n')
print(random.random()) # 0-1 返回float类型
print(random.randint(1, 10)) # 1-10 整形
print(random.randrange(1, 10))
print(random.choice([1, 'a', 3, 'w', 5])) # 随机返回列表中的数据
print(random.sample(['b', 'z', 1, 3, 'he', 4, '我'], 4)) # 随机返回集合中的内容4个
# 验证码
def v_code(n):
result = ""
for i in range(n):
# 随机数字
num = random.randint(0, 9)
# 随机字母
f = chr(random.randint(65, 122))
s = str(random.choice([num, f]))
result += s
return result
# 调用
print("随机验证码:%s" % (v_code(5)))
# 生成验证码2
def random_code(number):
# 随机生成一个大写字符
cap_str = chr(random.randint(65, 90))
# 随机生成一个小写字符
lowr_str = chr(random.randint(97, 122))
# 随机生成一个数字
num_str = str(random.randint(0, 9))
rand_out = []
i = 0
for i in range(number):
# 根据上面三个字符再次随机生成一个
rand_str = random.choice([cap_str, lowr_str, num_str])
rand_out.append(rand_str)
return ''.join(rand_out)
r = random_code(4)
print(r)
def os_test():
print('\r\n============OS模块测试============\r\n')
# 获取当前文件路径
print(os.getcwd())
# 创建文件夹
# os.makedirs("makdir")
# 删除文件夹
# os.removedirs('makdir')
# 获取当前文件同级的所有文件
print(os.listdir())
# 获取文件信息
print(os.stat("11-lnh-python模块.py"))
print(os.name)
# 获取绝对路径
print(os.path.abspath("makdir"))
a = "User/Administrator"
c = "python/基础"
print(os.path.join(a, c))
def sys_test():
print('\r\n============sys模块测试============\r\n')
"""
sys.argv # 执行参数List ,第一个元素是程序本身路径
sys.exit(n) # 退出程序,正常退出时exit(0)
sys.version # 获取Python解析程序的版本信息
sys.maxint # 最大的Int值
sys.path # 返回模块的搜索路径,初始时使用Python环境变量的值
sys.platform # 返回操作系统平台名称
"""
print(sys.platform)
print(sys.path)
print(sys.version)
# print("程序准备退出...")
# sys.exit(0)
# print('程序退出后....')
# 接收参数 ['11-lnh-python模块.py', 'select', '12']
print(sys.argv)
for i in range(100):
# 打完后一次性显示
sys.stdout.write('#')
# time.sleep(1)
# # 立刻刷新
# sys.stdout.flush()
def json_test():
print("\r\n==================json模块测试==================\r\n")
js = {
'name': 'BeJson',
"url": "http://www.bejson.com",
"page": 88,
"isNonProfit": True,
"address": {
"street": "科技园路.",
"city": "江苏苏州",
"country": "中国"
},
"links": [
{
"name": "Google",
"url": "http://www.google.com"
},
{
"name": "Baidu",
"url": "http://www.baidu.com"
},
{
"name": "SoSo",
"url": "http://www.SoSo.com"
}
]
}
# # json 转字符串(将所有的单引号转为双引号)
# jd = json.dumps(js)
# print(jd)
# with open("../files/BeJson", "w", encoding="utf-8") as f:
# f.write(jd) # ----------->json.dump(js,f)
# print("保存磁盘完成")
# 读取数据
with open("../files/BeJson", "r", encoding="utf-8") as f:
# 将字符串转为字典
jl = json.loads(f.read()) # -------->json.load(f)
print(jl)
print(type(jl))
# 简单写法
# 将python中数据序列化后存入磁盘
json_dict = {'name': '张三', 'age': 18, 'aihao': ['打篮球', '唱歌'], 'sex': True}
with open('test.json', mode='wt', encoding='utf-8') as f:
json.dump(json_dict, f)
# 将磁盘中json数据反序列化
with open("test.json", mode='rt', encoding='utf-8') as ff:
rest = json.load(ff)
print(rest,type(rest))
def pickle_test():
print("\r\n==================pickle模块测试==================\r\n")
js = {
'name': 'BeJson',
"url": "http://www.bejson.com",
"page": 88,
"isNonProfit": True,
"address": {
"street": "科技园路.",
"city": "江苏苏州",
"country": "中国"
},
"links": [
{
"name": "Google",
"url": "http://www.google.com"
},
{
"name": "Baidu",
"url": "http://www.baidu.com"
},
{
"name": "SoSo",
"url": "http://www.SoSo.com"
}
]
}
# 将字符串序列化为字节
data = pickle.dumps(js)
print(data)
print("序列化后类型为:%s" % type(data))
# 将字符串字节转为字典
da = pickle.loads(data)
print(da)
print("loads序列化类型为:%s" % type(da))
def shelve_test():
print("\r\n==================shelve模块测试==================\r\n")
# # 数据传输
# js = {
# 'name': 'BeJson',
# "url": "http://www.bejson.com",
# "page": 88,
# "isNonProfit": True,
# "address": {
# "street": "科技园路.",
# "city": "江苏苏州",
# "country": "中国"
# },
# "links": [
# {
# "name": "Google",
# "url": "http://www.google.com"
# },
# {
# "name": "Baidu",
# "url": "http://www.baidu.com"
# },
# {
# "name": "SoSo",
# "url": "http://www.SoSo.com"
# }
# ]
# }
# # 拿到文件的句柄返回的是一个字典类型
# f = shelve.open(r"../files/ShelveJson") # 将字典放入文本
# f["Info"] = js
# f.close()
# 取值
f = shelve.open(r"../files/ShelveJson")
print(f.get("Info")["name"])
def xml_test():
print("\r\n==================XML模块测试==================\r\n")
# 读取xml文件
tree = et.parse("../files/app")
root = tree.getroot()
for i in root:
print(i.tag)
print(i.attrib)
a = 0
for j in i: # ---> i.iter('add') 只便利指定节点
# 获取节点名称
print(j.tag)
# 获取属性值
print(j.attrib)
# 获取便签内容 <name>张三</name> ----> 得到:张三
print(j.text)
# 新增节点属性
# j.set("index", '1')
a += 1
# tree.write("../files/app")
# 遍历指定节点内容
tree = et.parse("../files/app")
root = tree.getroot()
for i in root:
print(i.tag)
print(i.attrib)
a = 0
for j in i.iter('add'): # ---> i.iter('add') 只便利指定节点
print(j.attrib)
def regex_test():
print("\r\n==================re模块测试==================\r\n")
# 正则就是做模糊匹配
with open("../files/retext", "r", encoding="utf-8") as f:
str = f.read()
print(str)
print(re.findall('href', str))
# 分组 返回匹配的第一个
r1 = re.search("(?P<name>[a-z]+)\d+", "zhangsan15lisi23").group('name')
print(r1)
r2 = re.search("(?P<name>[a-z]+)(?P<age>\d+)", "zhangsan15lisi23").group('age')
print(r2)
# 返回匹配的第一个
r3 = re.match("\d+", "154alix12lisi45xiaoming25").group()
print(r3)
# 以什么分割返回分割的数组
r4 = re.split('[ |]', 'rer|eabc jiklabc|ljiabcjijk')
print(r4)
r5 = re.split('[ab]', 'asdabcd')
print(r5)
# 替换:匹配规则 替换内容 原类容 匹配次数
r6 = re.subn('\d', 'A', 'fjlfjsl212jkj343ljlj', 3)
print(r6)
# 编译 (可多次使用)
r7 = re.compile('\d+')
f1 = r7.findall('sfsf4sfsf455sffs451dfsa5')
print(f1)
# 功能方法和findall一样,只不过返回的是一个迭代器(适用于大数据的处理)
rf = re.finditer('\d', 'fsdf1fsf151sfsfasf84885afasf874af')
r8 = next(rf).group()
print(r8)
# ?: 表示去掉优先级
r9 = re.findall('www\.(?:baidu|163)\.com', 'www.baidu.com')
print(r9)
def logging_test():
print('\n==================logging模块测试=====================\n')
"""
可见在logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有
filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open('test.log','w')),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
"""
# ====================basicConfig=====================
# 日志级别 debug info warning error critical
# print('默认等级输出:')
# logging.debug('debug日志')
# logging.info('info日志')
# logging.warning('warning日志')
# logging.error('error日志')
# logging.critical('critical日志')
#
# # 以上默认打印warning以上级别的日志会输出
# 设置等级后
print('设置等级后')
# 日志配置
logging.basicConfig(level=logging.DEBUG, # 日志等级
filename='../files/Log/logger.log', # 日志路径及文件名
filemode='a', # a:追加 w:覆盖
format="%(asctime)s [%(filename)s 行:%(lineno)d] %(message)s \n" # 日志输出格式
)
logging.debug('debug日志')
# logging.info('info日志')
# logging.warning('warning日志')
# logging.error('error日志')
# logging.critical('critical日志')
# ====================logger对象=======================
# 1:创建对象
logger = logging.getLogger()
# 2:创建文件Handler
fh = logging.FileHandler('../files/Log/logger.log')
# 3:创建屏幕输出Handler
ch = logging.StreamHandler()
# 4:屏幕文件输出日志格式
fm = logging.Formatter("%(asctime)s [%(filename)s 行:%(lineno)d] %(message)s \n")
fh.setFormatter(fm)
ch.setFormatter(fm)
# :5:将文件屏幕添加到logger对象中
logger.addHandler(fh)
logger.addHandler(ch)
# 设置logger输出等级
logger.setLevel("DEBUG")
# 使用logger打印信息
logging.info('info日志')
logging.warning('warning日志')
logging.error('error日志')
logging.critical('critical日志')
def configparse_test():
print('\n==================configparse模块测试=====================\n')
# 新增一个配置文件
config = configparser.ConfigParser()
# config['DEFAULT'] = {'ServerAliveInterval': '45', 'Compression': 'yes',
# 'CompressionLevel': '9',
# 'ForwardX11': 'yes'}
# config['bitbucket.org'] = {'User': 'ZhangSan'}
# config['topsecret.server.com'] = {'Port': 50022,
# 'ForwardX11': 'no'}
#
# with open('../files/config.init', 'w') as f:
# config.write(f)
# 查
print(config.sections())
config.read('../files/config.init')
# DEFULT 不打印
config_sect = config.sections()
print(config_sect)
print('bytebong.com' in config)
print(config['bitbucket.org']['User'])
print('遍历节点新消息,无论是遍历哪个节点,DEFAULT的节点下的信息也会被遍历出来')
for key in config['topsecret.server.com']:
print(key)
# 返回key列表
print(config.options('topsecret.server.com'))
# 返回 key value 列表
print(config.items('topsecret.server.com'))
# 增
# config.add_section('address')
# config.set('address', 'UTC', '10212')
# config.add_section('INFO')
# config.set('INFO', 'Name', 'Lisi')
# config.set('INFO', 'Age', '18')
# config.set('INFO', 'Sex', '男')
# 删
# config.remove_section('address')
# config.remove_option('INFO', 'Sex')
# 改
config['INFO']['Name'] = '雷锋'
# 重新写入文件
with open('../files/config.init', 'w') as cf:
config.write(cf)
def hashib_test():
print('\n==================hashib模块测试=====================\n')
# has 算法 ----->摘要算法
md = hashlib.md5()
md.update('hello'.encode('utf8'))
print(md.hexdigest()) # 5d41402abc4b2a76b9719d911017c592
# 当前文件调用 modular.receMsage 模块下的 get_name方法,打印__name__值为:modular.receMsage
# 如果在receMsage.py 文件中执行,打印__name__值为:__main__
# 作用1:测试代码,外部引用调用的时候,就不会运行我的测试代码 2:
if __name__ == '__main__':
# get_name()
time_test()
random_test()
os_test()
sys_test()
json_test()
pickle_test()
shelve_test()
xml_test()
regex_test()
logging_test()
configparse_test()
hashib_test()
时间模块补充:
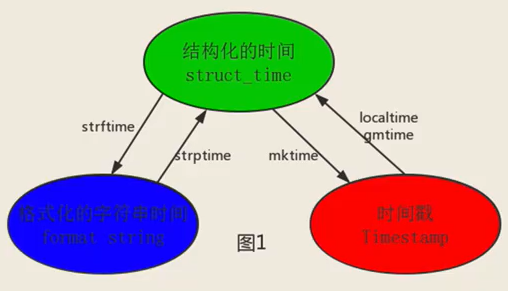
# 1:时间模块
import time
import datetime
# 时间戳(时间计算)
print(time.time())
t1 = time.time()
time.sleep(1)
t2 = time.time()
print(t2 - t1)
# 格式化时间(时间的展示)
print(time.strftime('%Y-%m-%d %H:%M:%S'))
print(time.localtime())
# 结构化时间(时间戳与格式化时间直接的转换中间量)
print(datetime.datetime.now())
print(datetime.datetime.now() + datetime.timedelta(days=-3))
# 案例:将 '2021-01-06 12:30:22' 减去1天22分11秒
# 将'2021-01-06 12:30:22' 先转换为结构化时间
t1 = time.strptime('2021-01-06 12:30:22', '%Y-%m-%d %H:%M:%S')
# 将t1转为 时间戳
t2 = time.mktime(t1)
# 在时间戳的基础上进行计算
t3 = t2 - (24 * 60 * 60 + 60 * 24 + 11)
# 将时间戳转为结构化时间
t4 = time.localtime(t3)
# 将结构化时间转为格式化时间
t5 = time.strftime('%Y-%m-%d %H:%M:%S', t4)
print(t1)
print(t2)
print(t3)
print(t4)
print(t5)
序列化及猴子补丁补充
"""
1:什么式序列化
序列化指的式把内存的数据类型转换成一个特定的格式内容
该格式的内容可用于存储或者传输给其他平台使用
内存中的数据类型----> 序列化 ----->特定的格式(json格式或者是pickle格式)
内存中的数据类型<---- 反序列化 <-----特定的格式(json格式或者是pickle格式)
2:为何要序列化
序列化得到结果 => 特定的格式的内容两种用途
1:可用于存储
2:传输给他平台
"""
import json
# 猴子补丁:在程序的入口处打猴子补丁
# 例如:将json 模块 替换为 ujson
import ujson
def monkey_path_json():
json.__name__ = "ujson"
json.dumps = ujson.dumps
json.loads = ujson.loads
# 在程序入口执行
monkey_path_json()
# 在程序其它地方虽然使用的是json.dumps或者json.loads方法,但是我们已经替换为了ujson
# 将python中数据序列化后存入磁盘
json_dict = {'name': '张三', 'age': 18, 'aihao': ['打篮球', '唱歌'], 'sex': True}
with open('test.json', mode='wt', encoding='utf-8') as f:
json.dump(json_dict, f)
# 将磁盘中json数据反序列化
with open("test.json", mode='rt', encoding='utf-8') as ff:
rest = json.load(ff)
print(rest,type(rest))
执行命令模块补充
# 执行命令模块
import subprocess
rest = subprocess.Popen('dir',
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
# 正确管道里的内容
msg = rest.stdout.read()
# 错误管道里的内容
err_msg = rest.stderr.read()
print(msg.decode('gbk'))# 编码是系统默认编码
print(err_msg.decode('gbk'))
日志模块补充 :日志字典、日志命名、日志轮转

日志配置文件 logsetting.py文件
import os
# 1、定义三种日志输出格式,日志中可能用到的格式化串如下
# %(name)s Logger的名字
# %(levelno)s 数字形式的日志级别
# %(levelname)s 文本形式的日志级别
# %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
# %(filename)s 调用日志输出函数的模块的文件名
# %(module)s 调用日志输出函数的模块名
# %(funcName)s 调用日志输出函数的函数名
# %(lineno)d 调用日志输出函数的语句所在的代码行
# %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
# %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
# %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
# %(thread)d 线程ID。可能没有
# %(threadName)s 线程名。可能没有
# %(process)d 进程ID。可能没有
# %(message)s用户输出的消息
# 2、强调:其中的%(name)s为getlogger时指定的名字
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]'
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
test_format = '%(asctime)s] %(message)s'
# 3、日志配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
'test': {
'format': test_format
},
},
'filters': {},
'handlers': {
# 打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
# 打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,日志轮转
'formatter': 'standard',
# 可以定制日志文件路径
# BASE_DIR = os.path.dirname(os.path.abspath(__file__)) # log文件的目录
# LOG_PATH = os.path.join(BASE_DIR,'a1.log')
'filename': 'syslog.log', # 日志文件
'maxBytes': 1024 * 1024 * 5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
'other': {
'level': 'DEBUG',
'class': 'logging.FileHandler', # 保存到文件
'formatter': 'test',
'filename': 'syslog.log',
'encoding': 'utf-8',
},
},
'loggers': {
# logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG', # loggers(第一层日志级别关限制)--->handlers(第二层日志级别关卡限制)
'propagate': False, # 默认为True,向上(更高level的logger)传递,通常设置为False即可,否则会一份日志向上层层传递
},
'专门的采集': {
'handlers': ['other', ],
'level': 'DEBUG',
'propagate': False,
},
},
}
日志使用文件
import logsetting
# !!!强调!!!
# 1、logging是一个包,需要使用其下的config、getLogger,可以如下导入
# from logging import config
# from logging import getLogger
# 2、也可以使用如下导入
import logging.config # 这样连同logging.getLogger都一起导入了,然后使用前缀logging.config.
# 3、加载配置
logging.config.dictConfig(logsetting.LOGGING_DIC)
# 4、输出日志
logger1=logging.getLogger('用户登录')
logger1.info('张三登录了系统')
正则表达式补充
重复匹配:| . | * | ? | .* | .*? | + | {m,n} |
1、. 匹配左侧字符串除了\n 以外任意一个字符
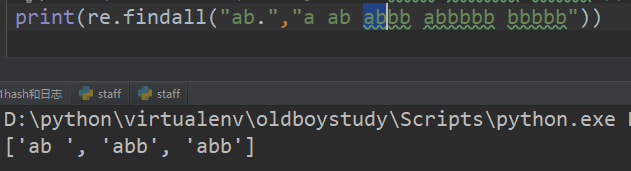
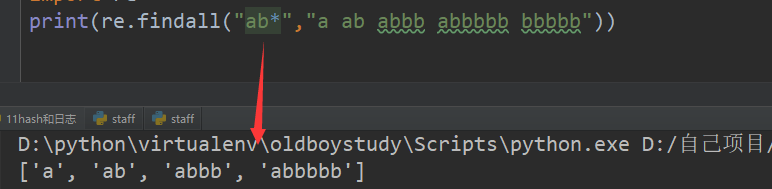
2、* 匹配左侧字符串出现0次或无限次 贪婪模式
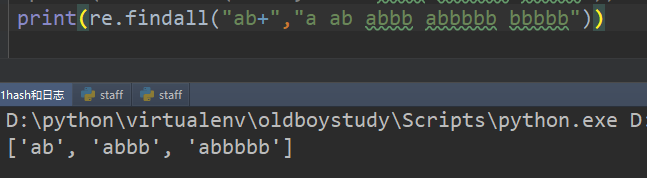
3、+ 匹配左侧字符串至少有一次或无限次 贪婪模式
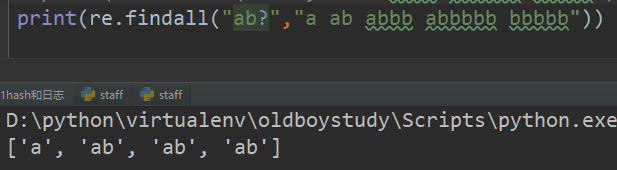
4、?匹配左侧字符串出现0次或一次 贪婪模式
5、{n,m} 匹配左侧字符串从n次到m次 贪婪模式
注:{n} => n次
{0,} => *
{1,} => +
{0,1} => ?
正则表达式匹配规则
re.match 从头开始匹配
re.search 匹配包含
re.findall 把所有匹配到的字符串放入到列表中返回
re.split 以匹配到的字符串当作分隔符
re.sub 匹配到的字符串替换
re.fullmatch 全部匹配
三元表达式与列表生成式
# 普通表达式
a = 70
if a > 60:
print('科目及格')
else:
print('科目不及格')
# 三元表达式
res = '科目及格' if a > 60 else '科目不及格'
print(res)
# 列表生成式(生成一个1-100的质数列表)
l = [i for i in range(1, 101, 2)]
# 列表生成式(生成一个1-100的偶数列表)
ll = [i for i in range(1, 101) if i % 2 == 0]
print(ll)
# 字典生成式
t = [('name','小明'),('age',18),('sex',1)]
dt = { k:v for k,v in t}
print(dt)
# 集合生成式
item = [1,2,4,6,7,9,7]
st ={key for key in item}
print(st)# 集合不可重复所以7只有一个
# 生成器表达式
item = [1,2,4,6,7,9,7]
t =(key for key in item)# 此刻t 内部一个值也没有,只有当next后才会取一个值
print(t)
print(next(t))
print(next(t))
print(next(t))
#案例:统计文本字数
print("案例:统计文本字数")
with open('b.txt',mode='rt',encoding='utf-8') as f:
# # 方式一:不占内存但是代码过多
# res =0
# for lin in f:
# res+=len(lin)
# print(res)
# #方式二:如果文件过大占内存,代码精简
# res = sum([len(line) for line in f])
# print(res)
# 方式三:转化成生成器 代码精简效率也高
res = sum((len(line) for line in f))
print(res)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号