

模块
模块基本知识
模块是实现某个功能的代码集合
模块分为三种:
内置模块:安装 python 时自带的模块
自定义模块:之前我们所写的所有函数也都可以被当做自定义模块
第三方模块:非安装 python 时自带的模块
1、模块的导入
Python之所以应用越来越广泛,在一定程度上也依赖于其为程序员提供了大量的模块以供使用,如果想要使用模块,则需要导入
导入模块的方法:
import module #导入模块的所有内容 from module.xx import xx # 导入模块的某一个功能 from module.xx import xx as rename # 导入模块的某一个功能,并将该功能重命名 from module.xx import * # 导入模块的所有内容,不建议使用
导入模块是让解释器在当前的搜索路径中寻找模块文件。
搜索路径是解释器会先进行搜索所有目录的列表,搜索路径是在 python 编译或安装的时候确认的,安装新的库应该也会修改。
搜索路径被存储在 sys 模块中的 path 变量
>>> import sys >>> print(sys.path) ['', '/usr/local/Cellar/python3/3.5.0/Frameworks/Python.framework/Versions/3.5/lib/python35.zip', '/usr/local/Cellar/python3/3.5.0/Frameworks/Python.framework/Versions/3.5/lib/python3.5', '/usr/local/Cellar/python3/3.5.0/Frameworks/Python.framework/Versions/3.5/lib/python3.5/plat-darwin', '/usr/local/Cellar/python3/3.5.0/Frameworks/Python.framework/Versions/3.5/lib/python3.5/lib-dynload', '/usr/local/lib/python3.5/site-packages']
sys.path 输出的是一个列表,第一个元素为空字符串,代表当前目录。
因此若在当前目录下创建与要导入的模块同名的文件,就会把要导入的模块屏蔽掉【没验证通过】
既然 sys.path 是一个列表,那么也就可以进行修改,当 sys.path 中没有我们需要导入模块的路径时,可以通过 list.append 添加。
常用模块
1、sys
用于提供对 python 解释器进行相关的操作
sys.argv # 命令行参数List,第一个元素是程序本身路径 sys.exit(n) # 退出程序,正常退出时exit(0) sys.version # 获取Python解释程序的版本信息 sys.maxint # 最大的Int值 【python3 取消了】 sys.path # 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform # 返回操作系统平台名称 sys.stdin # 输入相关 sys.stdout # 输出相关 sys.stderror # 错误相关
输出进度百分比
def view_bar(num, total): rate = float(num) / float(total) rate_num = int(rate * 100) # \r 表示将指针移动到开始 r = '\r%d%%' % (rate_num, ) # 输出时不换行 sys.stdout.write(r) # 刷新输出内容,如果没有 flush,write 会等待程序结束后一次性输出所有的结果 sys.stdout.flush() if __name__ == '__main__': for i in range(0, 100): time.sleep(1) view_bar(i, 100)
2、random
生成随机验证码
def create_verification_code(): li = [] for i in range(4): r = random.randrange(0,5) if r == 1 or r == 3: num = random.randrange(0,10) li.append(str(num)) else: temp = random.randrange(65,91) li.append(chr(temp)) code = "".join(li) return code
3、序列号
python 中的序列号模块有两个
- json 用于【字符串】和 【python 基本数据类型】间转换
- pickle 用于【python 特有类型】和【python 所有类型】之间的转换
json 和 pickle 都提供了 4 个方法:dumps, dump, loads, load
import json data = {1:1,2:2,3:3} # dumps 方法将 python 的基本数据类型转换为字符串 j_str = json.dumps(data) # loads 方法将字符串转换为 python 的基本数据类型 dic = json.loads(j_str) # load 方法将文件中的字符串转换为 python 的基本数据类型 j_str = json.load(open('file')) # dump 方法将 python 的基本数据类型已字符串的格式写入文件 json.dump(data,open('file'),'w')
import pickle data = {1:1,2:2,3:3} # dumps 方法将 python 的基本数据类型转换为只有 python 能认识的特有字符串格式 p_str = pickle.dumps(data) # loads 方法将数据通过特有的转换方式转换为 python 的对象 dic = pickle.loads(p_str) # load 方法将文件中的内容通过特殊的方式转为 python 的对象 p_obj = pickle.load(open('file')) # dump 方法将 python 的对象通过特殊的转换方式存入文件 pickle.dump(data,open('file'),'w')
4、requests
Python标准库中提供了:urllib等模块以供Http请求,但是,它的 API 太渣了。它是为另一个时代、另一个互联网所创建的。它需要巨量的工作,甚至包括各种方法覆盖,来完成最简单的任务


import urllib.request f = urllib.request.urlopen('https://www.baidu.com') result = f.read().decode('utf-8') print(result)
import urllib.request req = urllib.request.Request('http://www.baidu.com/') req.add_header('Referer', 'http://www.python.org/') r = urllib.request.urlopen(req) result = r.read().decode('utf-8') print(result)
注:更多见Python官方文档:https://docs.python.org/3.5/library/urllib.request.html#module-urllib.request
Requests 是使用 Apache2 Licensed 许可证的 基于Python开发的HTTP 库,其在Python内置模块的基础上进行了高度的封装,从而使得Pythoner进行网络请求时,变得美好了许多,使用Requests可以轻而易举的完成浏览器可有的任何操作。
1、安装模块
pip3 install requests
2、使用模块
# 无参数实例 import requests ret = requests.get('https://github.com/timeline.json') print(ret.url) print(ret.text) # 有参数实例 import requests payload = {'key1': 'value1', 'key2': 'value2'} ret = requests.get("http://httpbin.org/get", params=payload) print(ret.url) print(ret.text)
# 基本POST实例 import requests payload = {'key1': 'value1', 'key2': 'value2'} ret = requests.post("http://httpbin.org/post", data=payload) print(ret.text) # 发送请求头和数据实例 import requests import json url = 'https://api.github.com/some/endpoint' payload = {'some': 'data'} headers = {'content-type': 'application/json'} ret = requests.post(url, data=json.dumps(payload), headers=headers) print(ret.text) print(ret.cookies)
requests.get(url, params=None, **kwargs) requests.post(url, data=None, json=None, **kwargs) requests.put(url, data=None, **kwargs) requests.head(url, **kwargs) requests.delete(url, **kwargs) requests.patch(url, data=None, **kwargs) requests.options(url, **kwargs) # 以上方法均是在此方法的基础上构建 requests.request(method, url, **kwargs)
更多requests模块相关的文档见:http://cn.python-requests.org/zh_CN/latest/
5、logging
用于便捷记录日志且线程安全的模块
import logging logging.basicConfig(filename='log.log', format='%(asctime)s - %(name)s - %(levelname)s - %(module)s[%(lineno)s]: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', level=10) logging.debug('debug') logging.info('info') logging.warning('warning') logging.error('error') logging.critical('critical') # 通过 logging.log 直接传递日志级别,日志级别必须为 int 型 logging.log(10,'log')
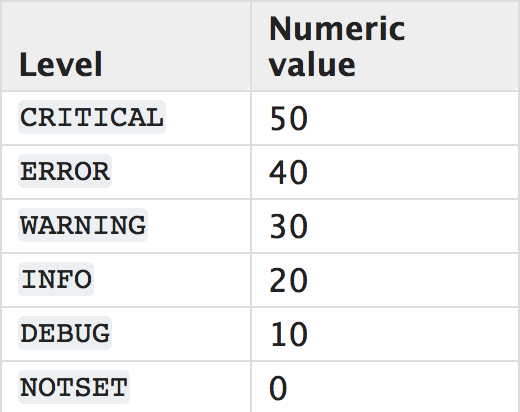
日志的级别以及级别对应的数字
只有记录日志的级别大于日志等级时内容才会被记录
日志的格式
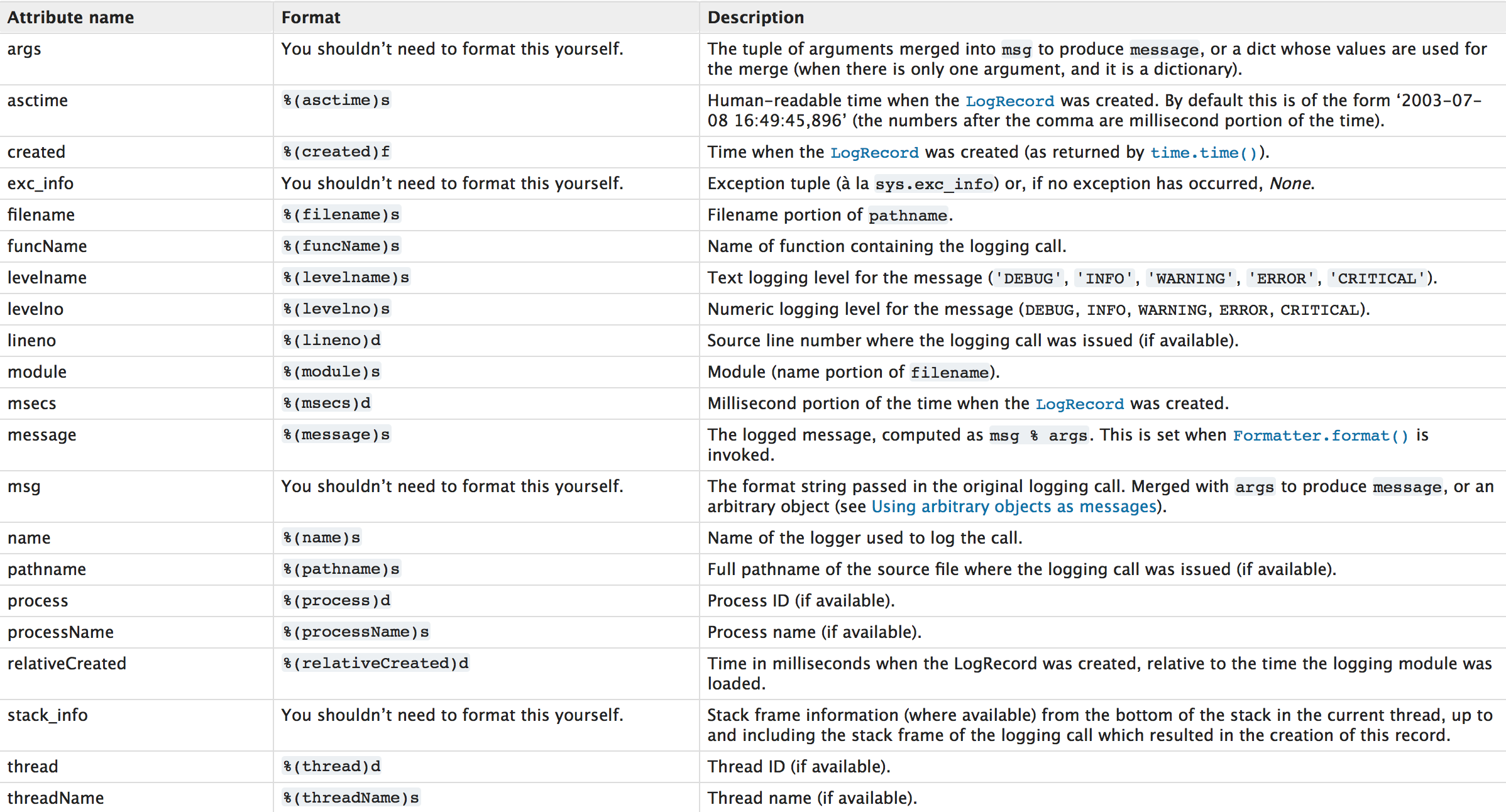
更多信息:https://docs.python.org/3/library/logging.html
对于上述记录日志的功能,只能将日志记录在单文件中,如果想要设置多个日志文件,logging.basicConfig将无法完成,需要自定义文件和日志操作对象。
import logging # 定义两个不同的日志文件句柄 file_handler1 = logging.FileHandler(filename='log1.log',mode='a',encoding='utf-8') fmt = logging.Formatter(fmt='%(asctime)s - %(name)s - %(levelname)s - %(module)s[%(lineno)s]: %(message)s') file_handler1.setFormatter(fmt) file_handler2 = logging.FileHandler(filename='log2.log',mode='a',encoding='utf-8') fmt = logging.Formatter() file_handler2.setFormatter(fmt) # 定义日志文件的名称以及级别,并将之前定义的文件句柄添加,日志的级别也可以通过 logger.setLevel(logging.DEBUG) 单独设置 logger = logging.Logger("WenChong",level=logging.DEBUG) logger.addHandler(file_handler1) logger.addHandler(file_handler2) # 日志会同时写入到两个文件 logger.error('aaaaaaaaa') logger.setLevel(logging.DEBUG)
6、time
时间有三种表现形式
时间戳 1970年1月1日之后的秒,即:time.time()
格式化字符串 2016-08-31 23:49:44, 即:time.strftime('%Y-%m-%d %H:%M:%S')
结构化时间 元组包含了:年、日、星期等... time.struct_time 即:time.localtime()
import time print(time.time()) # 输出当前的时间戳 print(time.mktime(time.localtime())) # 将 struct_time 结构化时间转换为时间戳 print(time.localtime()) # 参数可为时间戳,将时间戳转换为 struct_time 结构化时间 print(time.strptime('2016-08-31', '%Y-%m-%d')) # 将格式化的时间转换为 struct_time 结构化时间 print(time.gmtime()) # 将时间戳转换为 struct_time 结构化时间,默认是 UTC print(time.ctime()) # 返回当前系统时间,参数为时间戳,默认为当前,输出为格式化时间 print(time.strftime('%Y-%m-%d')) # 将时间戳格式的时间转换为格式化时间,默认为当前时间 time.sleep() # 程序在此等待 N 秒
import datetime print(datetime.datetime.now()) # 返回当前时间 2016-09-01 00:11:35.628752 print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2016-09-01 print(datetime.datetime.now() + datetime.timedelta(3)) # 当前时间+3天 print(datetime.datetime.now() + datetime.timedelta(-3)) # 当前时间-3天 print(datetime.datetime.now() + datetime.timedelta(hours=3)) # 当前时间+3小时 print(datetime.datetime.now() + datetime.timedelta(minutes=30)) # 当前时间+30分 c_time = datetime.datetime.now() print(c_time.replace(year=2019,minute=3,hour=2)) # 时间替换
7、os
os.getcwd() # 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") # 改变当前脚本工作目录;相当于shell下cd os.curdir # 返回当前目录: ('.') os.pardir # 获取当前目录的父目录字符串名:('..') os.makedirs('dir1/dir2') # 可生成多层递归目录 os.removedirs('dirname1') # 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir('dirname') # 生成单级目录;相当于shell中mkdir dirname os.rmdir('dirname') # 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir('dirname') # 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() # 删除一个文件 os.rename("oldname","new") # 重命名文件/目录 os.stat('path/filename') # 获取文件/目录信息 os.sep # 操作系统特定的路径分隔符,win下为"\\",Linux下为"/" os.linesep # 当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" os.pathsep # 用于分割文件路径的字符串 win下为分号,Linux下为冒号 os.name # 字符串指示当前使用平台。win->'nt'; Linux->'posix' os.system("bash command") # 运行shell命令,直接显示 os.environ # 获取系统环境变量 os.path.abspath(path) # 返回path规范化的绝对路径 os.path.split(path) # 将path分割成目录和文件名二元组返回 os.path.dirname(path) # 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) # 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) # 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) # 如果path是绝对路径,返回True os.path.isfile(path) # 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) # 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) # 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) # 返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) # 返回path所指向的文件或者目录的最后修改时间
8、hashlib
用于加密相关的操作,代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
通过 md5 加密 admin 并返回一个数据
import hashlib # hashlib 的方法还有 sha1,sha256, sha384, sha512 m = hashlib.md5() m.update(bytes('admin',encoding='utf-8')) print(m.hexdigest())
md5 等加密是可以通过撞库的方式反解的,所以在加密的时候可以添加上自定义的字符串
import hashlib m = hashlib.md5(bytes('WenChong',encoding='utf-8')) m.update(bytes('admin',encoding='utf-8')) print(m.hexdigest())
python 内部的加密模块 hmac
import hmac m = hmac.new(bytes("WenChong",encoding='utf-8')) m.update(bytes('admin',encoding='utf-8')) print(m.hexdigest())
9、configparser
python2.x 模块名为:ConfigParser
创建一个 mysql 配置文件
import configparser # 生成实例 conf = configparser.ConfigParser() # 添加 client 部分配置 conf['client'] = {} client = conf['client'] client['port'] = '3306' client['socket'] = '/opt/mysql/mysql.sock' # 添加 mysqld_safe 部分配置 conf['mysqld_safe'] = {} conf['mysqld_safe']['user'] = 'mysql' conf['mysqld_safe']['nice'] = '0' # 添加 mysqld 部分配置 conf['mysqld'] = { 'server-id': '1', 'bind-address':'192.168.1.1', 'port':'3306', 'pid-file':'/opt/mysql/mysql.pid', 'socket': '/opt/mysql/mysql.socket', 'basedir':'/opt/mysql/', 'datadir':'/opt/mysql' } # 将配置写入文件 conf.write(open('my.cnf','x'))
生成的配置文件:
[client] port = 3306 socket = /opt/mysql/mysql.sock [mysqld_safe] user = mysql nice = 0 [mysqld] socket = /opt/mysql/mysql.socket server-id = 1 pid-file = /opt/mysql/mysql.pid port = 3306 bind-address = 192.168.1.1 datadir = /opt/mysql basedir = /opt/mysql/
读取配置文件
import configparser conf = configparser.ConfigParser() conf.read('my.cnf') # 获取所有的 sections print(conf.sections()) # 获取 client 部分下的所有参数 print(conf.options('client')) print(conf.items('client')) # 获取 mysqld 部分的 bind-address 值 print(conf['mysqld'].get('bind-address')) print(conf.get('mysqld','bind-address')) # 获取值为数字的参数,并转换为 int 型 port = conf.getint('mysqld','port')
修改配置文件
import configparser conf = configparser.ConfigParser() conf.read('my.cnf') # 添加 sections,无返回 conf.add_section('TestSections') test_sections = conf['TestSections']['Test1'] = 'WenChong' # 检查是否有 sections,有则返回 True print(conf.has_option('TestSections','Test1')) # 修改已有的参数 conf.set('mysqld','port','3307') # 删除 sections 或 options,删除 sections 会连带删除下面所有的 options conf.remove_option('mysqld','datadir') conf.remove_section('TestSections') # 写入文件 conf.write(open('my.cnf','w'))
10、shutil
高级的文件,文件夹,压缩包处理模块
shutil.copyfileobj(fsrc,dsrc[,length])
将文件的内容拷贝到另一个文件中,至于是覆盖,还是追加,新建在于 dsrc 打开的方式
shutil.copyfileobj(open('a'),open('aa','w'))
shutil.copyfile(src,dst)
拷贝文件,如果 dst 已经存在,则会直接覆盖,不复制权限,时间等信息
shutil.copyfile('a','aa')
shutil.copymode(src,dst)
复制 src 的权限到 dst,文件的内容,用户组均不变化
shutil.copymode('a','aa')
shutil.copystat(src,dst)
复制 src 的权限,最后存取时间,最后修改时间,标志到 dst,文件的内容,用户组均不变化
shutil.copystat('a','aa')
shutil.copy(src,dst)
将文件src复制到文件或目录dst。如果dst是一个目录,将在该指定的目录中创建(或覆盖)一个具有和src相同名称的文件。权限位也被复制
shutil.copy('a','lib') shutil.copy('a','lib/aa')
shutil.copy2(src,dst)
类似于 shutil.copy()但元数据也复制 — 事实上,它只是 shutil.copy() 加上 shutil.copystat() 这是类似于Unix 的命令 cp -p
shutil.copy2('a','lib') shutil.copy2('a','lib/aa')
shutil.copytree(src,dst,symlink=False,ignore=None)
以递归方式复制以src为根的整个目录树。目标目录dst必须不存在;它和父目录将一起创建。复制权限和目录使用 shutil.copystat() 的,单个文件的复制使用 shutil.copy2()
如果 syslinks 为真,源树中的软链接表示为新树中的软链接,但不复制原始链接的元数据;如果为假或被省略,链接的文件内容和元数据将复制到新树
ignore 配置为一个函数的返回,shutil.ignore_patterns()
# 将 t1 目录以及文件递归的赋值到 t2 ,但是忽略以 a 和 b 开头的文件 shutil.copytree('t1','t2',ignore=shutil.ignore_patterns('a*','b*'))
shutil.rmtree(path, ignore_errors=False, onerror=None)
删除整个目录树;path必须指向一个目录(不可以是指向目录的软链接)。如果ignore_errors为真,将忽略删除失败产生的错误;如果为假或被省略,这些错误将通过调用onerror指示的处理程序处理,或者如果省略onerror,它们将会引发异常
shutil.rmtree('t2')
shutil.move(src,dst)
类似 unix 中的 mv
shutil.move('t1','t2')
shutil.make_archive(base_name, format[, root_dir[, base_dir[, verbose[, dry_run[, owner[, group[, logger]]]]]]])
创建存档文件 (如.zip 或者 tar) 并返回它的名称。
base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径
format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
root_dir: 要压缩的文件夹路径(默认当前目录)
shutil.make_archive('a','zip','t2') shutil.make_archive('lib/a','zip','t2')
shutil 的压缩其实是调用 zipfile 和 tarfile 两个模块实现的,但是 shutil 并不能在压缩包中添加文件,或者解压某一个文件
import zipfile # 压缩文件 z = zipfile.ZipFile('z.zip','w') z.write('t2/a') z.write('t2/aa') z.close() # 在已经存在的压缩文件中新增文件 z = zipfile.ZipFile('z.zip','a') z.write('t2/aaa') z.close() # 解压所有的文件 z = zipfile.ZipFile('z.zip','r') z.extractall() z.close() # 获取压缩文件中的文件列表 z = zipfile.ZipFile('z.zip','r') print(z.namelist()) z.close() # 解压单个的文件 z = zipfile.ZipFile('z.zip','r') z.extract('t2/a') z.close()
import tarfile # 打包文件 tar = tarfile.open('t.tar','w') tar.add('t2/a',arcname='tar_a') tar.add('t2/b',arcname='tar_b') tar.close() # 在已经存在的打包文件中添加文件 tar = tarfile.open('t.tar','a') tar.add('t2/aa',arcname='tar_aa') tar.close() # 列出打包文件中的所有文件名 tar = tarfile.open('t.tar','r') print(tar.getnames()) # 单独解包 tar = tarfile.open('t.tar','r') tar.extract(tar.getmember('tar_a'),path='t') tar.close() # 解包 tar = tarfile.open('t.tar','r') tar.extractall() tar.close()
11、xml
xml 模块是针对 xml 文件的操作模块
xml 文件的格式:
<?xml version="1.0"?> <data> <country name="Liechtenstein"> <rank>1</rank> <year>2008</year> <gdppc>141100</gdppc> <neighbor name="Austria" direction="E"/> <neighbor name="Switzerland" direction="W"/> </country> <country name="Singapore"> <rank>4</rank> <year>2011</year> <gdppc>59900</gdppc> <neighbor name="Malaysia" direction="N"/> </country> <country name="Panama"> <rank>68</rank> <year>2011</year> <gdppc>13600</gdppc> <neighbor name="Costa Rica" direction="W"/> <neighbor name="Colombia" direction="E"/> </country> </data>
解析 xml 文件
from xml.etree import ElementTree as ET # 通过文件解析 xml tree = ET.parse('country.xml') root = tree.getroot() # 通过字符串解析 xml xml_str = open('country.xml','r').read() # xml_str 也可以是通过 requests 获取到的 xml 字符串 root = ET.XML(xml_str)
操作 xml 文件
xml 是节点嵌套节点的方式,对于每一个节点都有相同的方法,具体的方法可以参考 Element 类
遍历 xml 中所有的节点
# 通过字符串解析 xml xml_str = open('country.xml','r').read() # xml_str 也可以是通过 requests 获取到的 xml 字符串 root = ET.XML(xml_str) # 每一个节点都会有 tag,attrib,text 属性 # 输出根节点的 tag print(root.tag) # 遍历 root 节点下的所有节点,并输出 tag 和 attrib for child in root: print(child.tag, child.attrib) # 遍历子节点下的所有子节点,并输出 tag,attrib,text 属性 for node in child: print(node.tag, node.attrib, node.text)
遍历 xml 中指定的节点
# 遍历 xml 中所有的 year 节点,并输出 text for node in root.iter('year'): print(node.text)
修改 xml 节点的内容
# 通过字符串解析 xml xml_str = open('country.xml','r').read() # xml_str 也可以是通过 requests 获取到的 xml 字符串 root = ET.XML(xml_str) for node in root.iter('year'): # 修改年份 +1 new_year = int(node.text) + 1 # xml 获取的值均为 str node.text = str(new_year) # xml 存储的值也必须是 str # 为 year 节点增加属性 node.set('name', 'WenChong') node.set('age', '8') # 删除节点的 name 属性 del node.attrib['name'] # 保存文件 # 保存文件时: # 如果是以字符串解析的 xml,则需要在保存时,先生成 ElementTree # 如果是以文件解析的 xml,因为获取 root 节点时以及创建了 ElementTree,则不需要重复生成 tree = ET.ElementTree(root) tree.write('new_country.xml')
删除指定的节点
# 通过字符串解析 xml xml_str = open('country.xml','r').read() # xml_str 也可以是通过 requests 获取到的 xml 字符串 root = ET.XML(xml_str) for country in root.findall('country'): rank = int(country.find('rank').text) if rank > 50: root.remove(country) tree = ET.ElementTree(root) tree.write('new_country.xml')
创建 xml
方法一:
from xml.etree import ElementTree as ET # 创建根节点 root = ET.Element('family') # 创建 son 节点 son1 = ET.Element('son', {'name': 'Wen', 'age': '10'}) son2 = ET.Element('son', {'name': 'Chong', 'age': '20'}) # 创建 grandson 节点 grandson1 = ET.Element('grandson', {'name': 'Tom', 'age': '1'}) grandson2 = ET.Element('grandson', {'name': 'Greed', 'age': '2'}) # 上面创建的 5 个节点,目前是没有任何关系的,使用 append() 方法创建父子关系 root.append(son1) root.append(son2) son1.append(grandson1) son1.append(grandson2) # 保存文件 tree = ET.ElementTree(root) tree.write('family.xml')
方法二
from xml.etree import ElementTree as ET # 创建根节点 root = ET.Element('family') # 创建 son 节点, 并将 son节点添加到 root节点下 son1 = ET.SubElement(root, 'son', {'name': 'Wen', 'age': '10'}) son2 = ET.SubElement(root, 'son', {'name': 'Chong', 'age': '20'}) # 创建 grandson 节点,并将 grandson 添加到 son1 节点下 grandson1 = ET.SubElement(son1, 'grandson', {'name': 'Tom', 'age': '1'}) grandson2 = ET.SubElement(son1, 'grandson', {'name': 'Greed', 'age': '2'}) # 保存文件 tree = ET.ElementTree(root) tree.write('family.xml')
由于原生的 xml 保存时没有缩进的,如果要缩进,就需要修改保存方式
from xml.etree import ElementTree as ET from xml.dom import minidom def prettify(elem,filename): """将节点转换成字符串,并添加缩进。 """ rough_string = ET.tostring(elem, 'utf-8') reparsed = minidom.parseString(rough_string) # 写入文件 f = open(filename,'w',encoding='utf-8') f.write(reparsed.toprettyxml(indent="\t")) f.close() # 创建根节点 root = ET.Element('family') # 创建 son 节点, 并将 son节点添加到 root节点下 son1 = ET.SubElement(root, 'son', {'name': 'Wen', 'age': '10'}) son2 = ET.SubElement(root, 'son', {'name': 'Chong', 'age': '20'}) # 创建 grandson 节点,并将 grandson 添加到 son1 节点下 grandson1 = ET.SubElement(son1, 'grandson', {'name': 'Tom', 'age': '1'}) grandson2 = ET.SubElement(son1, 'grandson', {'name': 'Greed', 'age': '2'}) # 保存文件 prettify(root,'family.xml')
12、yaml
saltstack 的 sls 文件格式为 yaml
参考官方文档:http://pyyaml.org/wiki/PyYAMLDocumentation
13、subprocess
subprocess.run(args, *, stdin=None, input=None, stdout=None, stderr=None, shell=False, timeout=None, check=False)
在之前的 python 版本中的方法均可用 run() 方法实现
call() 执行命令返回状态码
check_all() 执行命令,如果状态码为 0,则返回 0,否则报错
check_output() 执行命令,如果返回码为 0,则输出命令结果,否则报错
import subprocess # subprocess.run() 返回的是一个 CompleteProcess 实例 # 简单执行 ls -l ret1 = subprocess.run(['ls','-l']) ret2 = subprocess.run('ls -l',shell=True) # 如果 check=True,当返回结果不为 0 时,会报错 ret3 = subprocess.run('exit 1',shell=True,check=True) # stdout=subprocess.PIPE,将执行的结果保存在 ret 实例中,不进行直接输出,不带此参数会直接输出,无法捕获 ret4 = subprocess.run('ls -l',shell=True,stdout=subprocess.PIPE) print(ret4.check_returncode()) # 和 check=True 参数相似,如果不为 0 ,则 raise 一个 calledProcessError print(ret4.args) # 返回执行的命令 print(ret4.returncode) # 返回返回码 print(ret4.stdout) # 命令输出结果
subprocess.popen(...)
用于执行复杂的系统命令
- args:shell命令,可以是字符串或者序列类型(如:list,元组)
- bufsize:指定缓冲。0 无缓冲,1 行缓冲,其他 缓冲区大小,负值 系统缓冲
- stdin, stdout, stderr:分别表示程序的标准输入、输出、错误句柄
- preexec_fn:只在Unix平台下有效,用于指定一个可执行对象(callable object),它将在子进程运行之前被调用
- close_sfs:在windows平台下,如果close_fds被设置为True,则新创建的子进程将不会继承父进程的输入、输出、错误管道。所以不能将close_fds设置为True同时重定向子进程的标准输入、输出与错误(stdin, stdout, stderr)。
- shell:同上
- cwd:用于设置子进程的当前目录
- env:用于指定子进程的环境变量。如果env = None,子进程的环境变量将从父进程中继承。
- universal_newlines:不同系统的换行符不同,True -> 同意使用 \n
- startupinfo与createionflags只在windows下有效,将被传递给底层的CreateProcess()函数,用于设置子进程的一些属性,如:主窗口的外观,进程的优先级等等
执行简单的命令
import subprocess ret1 = subprocess.Popen(["mkdir","t1"]) ret2 = subprocess.Popen("mkdir t2", shell=True) ret3 = subprocess.Popen("mkdir t3", shell=True, cwd='t2',)
执行命令与捕获输出有三种方式
################## 第一种方式 ################## obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True) obj.stdin.write("print(1)\n") obj.stdin.write("print(2)") obj.stdin.close() # 获取 stdout 和 stderr 并输出 cmd_out = obj.stdout.read() obj.stdout.close() cmd_error = obj.stderr.read() obj.stderr.close() print(cmd_out) print(cmd_error) ################# 第二种方式 ################## obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True) obj.stdin.write("print(1)\n") obj.stdin.write("print(2)") # obj.communicate() 返回一个元组 (stdout_data, stderr_data) out_error_list = obj.communicate() print(out_error_list) ################# 第三种方式 ################## obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True) out_error_list = obj.communicate('print(1)') print(out_error_list)
14、re
python 的 re 模块提供的是正则表达式相关的操作,正则表达式是一个特殊的字符序列,是我们方便的检查一个字符串是否与某种模式匹配
常用的正则表达式符号
# 字符匹配相关 '.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行 '\A' 只从字符开头匹配,同^ re.search("\Aabc","alexabc") 是匹配不到的 '\Z' 匹配字符结尾,同$ '\d' 匹配数字0-9 '\D' 匹配非数字 '\w' 匹配[A-Za-z0-9] '\W' 匹配非[A-Za-z0-9] 's' 匹配空白字符、\t、\n、\r , re.findall("\s+","abc\t1\n3") 结果 ['\t', '\n'] '^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE) '$' 匹配字符结尾,或re.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以 # 字符重复相关 '*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a'] '+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb'] '?' 匹配前一个字符1次或0次 '{m}' 匹配前一个字符m次 '{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb'] '|' 匹配|左或|右的字符,re.findall("abc|ABC","ABCBabcCD") 结果['ABC', 'abc']
常用的函数
re.match() 和 re.search()
re.match 从字符串的起始位置开始匹配,如果开头不匹配则返回 None
re.search 扫描整个字符串,返回第一个成功的匹配
函数语法:
# pattern 匹配的正则表达式 # string 需要匹配的字符串 # flags 标志位,用于控制正则表达式的匹配方式,如忽略大小写 re.match(pattern,string,flags=0) re.search(pattern,string,flags=0)
可通过下面的方法获取匹配的结果
string = 'WenChong' print(re.search('Wen', string)) print(re.search('Wen', string).group()) print(re.search('Wen', string).start()) print(re.search('Wen', string).end()) print(re.search('Wen', string).span()) print(re.search('Wen', string).groups()) # group(num=0) 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 # start() 返回匹配开始的位置 # end() 返回匹配结束的位置 # span() 以元组的方式返回开始和结束的位置 # groups() 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 # 关于组号稍后在分组中说明 ########## 对比输出结果 ########## <_sre.SRE_Match object; span=(0, 3), match='Wen'> Wen 0 3 (0, 3) ()
re.findall() 和 re.finditer()
re.findall 遍历所有字符串,将匹配到的结果依次存放在一个列表中进行返回
re.finditer 遍历所有的字符串,将匹配到的结果依次存放在一个 iterator 中进行返回
函数的语法
# pattern 匹配的正则表达式 # string 需要匹配的字符串 # flags 标志位,用于控制正则表达式的匹配方式,如忽略大小写 re.findall(pattern,string,flags=0) re.finditer(pattern,string,flags=0)
匹配的结果会直接返回为列表或 iterator
string = 'abcABCAbcabcABCAbc' print(re.findall('abc',string)) print(re.finditer('abc',string)) ########## 对比输出结果 ########## ['abc', 'abc'] <callable_iterator object at 0x10c1a9da0>
re.split()
以匹配到的字符作为列表分隔符
函数的语法
# pattern 匹配的正则表达式 # string 需要匹配的字符串 # maxsplit 最大分割 # flags 标志位,用于控制正则表达式的匹配方式,如忽略大小写 re.split(pattern,string,maxsplit=0,flags=0)
实例
string = 'One1Two2Three3Four4' print(re.split('\d',string)) print(re.split('\d',string,maxsplit=1)) # ########## 对比输出结果 ########## ['One', 'Two', 'Three', 'Four', ''] ['One', 'Two2Three3Four4']
re.sub()
替换匹配到的字符串
函数语法
# pattern 匹配的正则表达式 # repl 替换后的字符串 # string 需要匹配替换的字符串 # count 最大替换 # flags 标志位,用于控制正则表达式的匹配方式,如忽略大小写 re.sub(pattern,repl,string,count=0,flags=0)
实例
string = 'ABCDEFGFEDCBA' print(re.sub('D','\t',string)) print(re.sub('D','\t',string,1)) ########## 对比输出结果 ########## ABC EFGFE CBA ABC EFGFEDCBA
re.compile()
将需要匹配的正则表达式进行编码,提高重复利用率
函数语法
# pattern 匹配的正则表达式 # flags 标志位,用于控制正则表达式的匹配方式,如忽略大小写 re.compile(pattern,flags=0)
实例
string = 'abcABCAbcabcABCAbc' p = re.compile('abc') print(p.findall(string)) ########## 对比输出结果 ########## ['abc', 'abc']
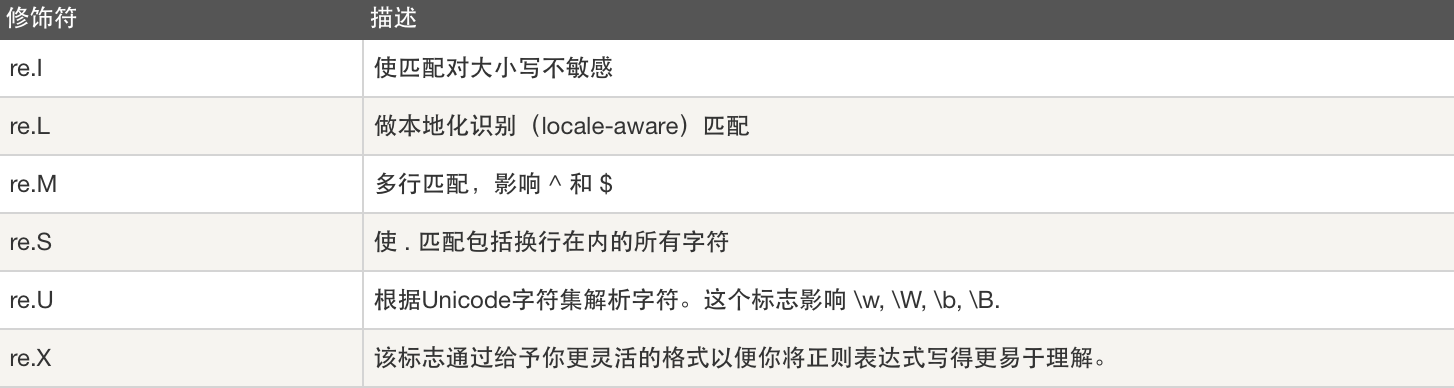
正则表达式修饰符
分组
(…) 用来匹配符合条件的字符串。并且将此部分,打包放在一起,看做成一个组 group,分组即在已经匹配的数据里面再提取数据
re.match 与 re.search 在分组的用法上一样
string = 'abcdefgh' # (?P<name>...) 为分组命名 # (...) 分组按组号,0 表示所有匹配,第一个括号内的组号为 1,依次类推 ret = re.search('a(\w{3})ef(?P<test>.*)',string) print(ret.group()) print(ret.group(1)) print(ret.group(2)) print(ret.groups()) print(ret.groupdict()) # ret.group(num=0) 输出匹配到的整个字符串 # ret.group(1) 在匹配的字符串中输出第一个()内的匹配结果 # ret.group(2) 在匹配的字符串中输出第二个()内的匹配结果 # ret.groups() 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号 # ret.groupdict() 如果分组中有命名,则按照字典的形式输出匹配名称与字符串 ########## 对比输出结果 ########## abcdefgh bcd gh ('bcd', 'gh') {'test': 'gh'}
re.findall 分组情况
string = 'abcABCAbcabcABCAbc' print(re.findall('Abcabc',string)) print(re.findall('A(bcab)c',string)) print(re.findall('A(b(ca)b)c',string)) print(re.findall('A(b(c(a))b)c',string)) # 当 pattern 中的括号内不包含其他括号时,输出括号内的匹配 # 当 pattern 中的括号内包含括号时,会依次按照括号从外到内的顺序生成元组 ########## 对比输出结果 ########## ['Abcabc'] ['bcab'] [('bcab', 'ca')] [('bcab', 'ca', 'a')]
re.split 分组情况
string = 'One1Two2Three3Four4' print(re.split('Two2',string)) print(re.split('(Two2)',string)) print(re.split('(Two(2))',string)) # 在 split 切割时,不包含分组则不输出匹配的字符串 # 包含分组则会输出匹配的字符串 # 分组中再分组,则会依次写入列表 ########## 对比输出结果 ########## ['One1', 'Three3Four4'] ['One1', 'Two2', 'Three3Four4'] ['One1', 'Two2', '2', 'Three3Four4']
反斜杠转译
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
常用正则匹配
IP: ^(25[0-5]|2[0-4]\d|[0-1]?\d?\d)(\.(25[0-5]|2[0-4]\d|[0-1]?\d?\d)){3}$ 手机号: ^1[3|4|5|8][0-9]\d{8}$ 邮箱: [a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+
