数据类型以及运算符
一、数据类型
1、数字
python3 中的数字分为 int, float, bool, complex(复数) 几大类型,在 python2 中还有一种数字类型为 long
通过 type() 函数可以查询变量对应的对象的数据类型
>>> a,b,c,d = 2,2.0,True,4+3j >>> type(a),type(b),type(c),type(d) (<class 'int'>, <class 'float'>, <class 'bool'>, <class 'complex'>)
2、字符串
python 中的字符串用单引号(')或双引号(")括起来
>>> name1 = 'wenchong' >>> type(name1) <class 'str'> >>> name2 = "wenchong" >>> type(name2) <class 'str'> >>> number = "88" >>> type(number) <class 'str'>
即使是一个数字,使用双引号或单引号括起来,它也会变为 str 类型,而并非 int 类型
格式化
>>> print("My name is %s, I'm Crazy." % name) My name is wenchong, I'm Crazy.
拼接
# 加号(+) 表示前后两个字符串拼接在一起 >>> "wen" + "chong" 'wenchong' # 星号(*) 后跟数字 n,表示星号前面的字符串重复出现 n 次 >>> "wen"*5 'wenwenwenwenwen'
移除空白
# 定义一个字符串左右和中间均有空格 >>> name = " wen chong " # 移除左边的空格 >>> name.lstrip() 'wen chong ' # 移除右边的空格 >>> name.rstrip() ' wen chong' # 移除左右两边的空格 >>> name.strip() 'wen chong' # 移除所有的空格 >>> "".join(name.split()) 'wenchong'
分割
str.split() 方法分割字符串,默认以空白分割
>>> name = "WenChong,Jack,Tom" >>> name.split(",") ['WenChong', 'Jack', 'Tom'] >>>
长度
使用 len() 函数统计字符串的长度
>>> name = "wenchong" >>> len(name) 8
索引
# 输出 name 变量中的第四个字母 >>> name[3] 'c' # 输出 name 变量的最后一个字母 >>> name[-1] 'g'
切片
# 输出 name 变量的第 1 个到第 3 个字母 >>> name[0:3] 'wen' # 输出 name 变量的第 3 个 到第 5 个字母 >>> name[2:5] 'nch'
字符串的索引以及切片都要使用到下标
语法为:变量[开始下标:结束下标]
下标是从 0 开始,-1 是从末尾的开始位置
3、列表
列表是 python 中使用最频繁的数据类型,可以完成大多数集合类的数据结构实现,
列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)。
列表是写在方括号([])之间、用逗号分隔开的元素列表。
列表的创建:
列表的元素可以包含字符串、数字和列表
>>> my_list = ['shanghai','beijing',88,33,['wen','chong',9],'55'] >>> print( type(my_list) ) <class 'list'>
索引
列表的索引【即下标】和字符串的是一样的,都是从 0 开始,-1 为末尾第一个
# 输出列表的第一个元素 >>> print( my_list[0] ) shanghai # 输出列表的最后一个元素 >>> print( my_list[-1] ) 55 # 输出列表的第 5 个元素 >>> print( my_list[4] ) ['wen', 'chong', 9]
通过 list.index() 方法查看元素的下标
>>> my_list = ['shanghai', 'beijing', 'shengzhen', 88, 33, ['wen', 'chong', 9], '55', 'wenchong'] >>> print( my_list.index('shengzhen') ) 2
切片
切片的格式为: 变量名[头下标:尾下标:步长]
头下标:如果不输入,默认为 0
尾下标:默认为取到最后一个;
尾下标大于最大的索引值,则取值到最后一个;
头下标必须在尾下标的左边,否则取值为空列表
步长:每隔几个取一个元素,默认为 1
# 输出第 1 个到第 3 个元素 >>> print( my_list[0:3] ) ['shanghai', 'beijing', 88] >>> print( my_list[:3] ) ['shanghai', 'beijing', 88] # 输出第 3 个到最后一个元素 >>> print( my_list[3:6] ) # 该列表的最大索引为 5 [33, ['wen', 'chong', 9], '55'] >>> print( my_list[3:] ) [33, ['wen', 'chong', 9], '55'] # 输出第 3 个到倒数第二个元素, >>> print( my_list[3:-1] ) [33, ['wen', 'chong', 9]] # 当头下标在尾下标的右边时,取值为空 >>> print( my_list[3:0] ) [] >>> print( my_list[3:-5] ) [] # 每隔一个元素输出,步长为 2 >>> print( my_list[::2] ) ['shanghai', 88, ['wen', 'chong', 9]]
添加【list.append()/list.insert()】
list.append() 在列表的最后追加元素,list.insert() 在列表的某个元素之前插入元素
>>> my_list.append( 'wenchong' ) >>> print( my_list ) ['shanghai', 'beijing', 88, 33, ['wen', 'chong', 9], '55', 'wenchong'] # 第一个参数为下标,即在第 3 个元素前增加 "shengzhen" >>> my_list.insert(2,'shengzhen') >>> print( my_list ) ['shanghai', 'beijing', 'shengzhen', 88, 33, ['wen', 'chong', 9], '55', 'wenchong']
删除【list.pop()/list.remove()/del】
删除列表中的某个元素 list.pop() 方法,参数为下标,默认为 -1
>>> my_list = ['shanghai', 'beijing', 'shengzhen', 88, 33, ['wen', 'chong', 9], '55', 'wenchong'] # pop() 方法默认将列表的最后一个元素取出,并返回[可以赋值给其他的变量] >>> name = my_list.pop() >>> print( name ) wenchong # my_list 列表的最后一个元素 "wenchong" 已经不存在 >>> print( my_list ) ['shanghai', 'beijing', 'shengzhen', 88, 33, ['wen', 'chong', 9], '55'] # 将列表的第一个元素取出,并赋值给 city 变量 >>> city = my_list.pop(0) >>> print( city ) shanghai # my_list 列表的第一个元素已经不存在 >>> print( my_list ) ['beijing', 'shengzhen', 88, 33, ['wen', 'chong', 9], '55']
del 也可以删除列表中的元素,并且也可以删除整个变量
# del 删除元素 >>> del my_list[0] >>> print( my_list ) ['shengzhen', 88, 33, ['wen', 'chong', 9], '55'] # del 删除变量,del 可以删除任何变量 >>> del my_list >>> print( my_list ) Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'my_list' is not defined
list.remove() 方法删除列表中的元素,参数为列表中的元素,list.pop() 方法的参数为下标
>>> my_list = ['shanghai', 'beijing', 'shengzhen', 88, 33, ['wen', 'chong', 9], '55', 'wenchong'] >>> my_list.remove('shanghai') >>> print( my_list ) ['beijing', 'shengzhen', 88, 33, ['wen', 'chong', 9], '55', 'wenchong']
修改
my_list[下标] = value
>>> my_list = ['shanghai', 'beijing', 'shengzhen', 88, 33, ['wen', 'chong', 9], '55', 'wenchong'] # 修改第一个元素 >>> my_list[0] = 'ShangHai' >>> print( my_list ) ['ShangHai', 'beijing', 'shengzhen', 88, 33, ['wen', 'chong', 9], '55', 'wenchong'] # 一次性修改第二个和第三个元素 >>> my_list[1:3] = ['Beijing','ShengZhen'] >>> print( my_list ) ['ShangHai', 'Beijing', 'ShengZhen', 88, 33, ['wen', 'chong', 9], '55', 'wenchong']
长度
len() 函数可以查看任何数据类型的长度
>>> my_list = ['shanghai', 'beijing', 'shengzhen', 88, 33, ['wen', 'chong', 9], '55', 'wenchong'] # 输出 my_list 列表的长度,即元素的个数 >>> print( len(my_list) ) 8 # 输出 my_list 列表的第五个元素的长度,由于第五个元素为 list,则显示这个列表的长度 >>> print( len(my_list[5])) 3 # 输出 my_list 李彪的第一个元素的长度,由于为 string,则显示 string 的长度 >>> print( len(my_list[0])) 8
切片
列表的切片与字符串的切量基本相同
# 输出完整的列表 >>> print( my_list ) ['shanghai', 'beijing', 'shengzhen', 88, 33, ['wen', 'chong', 9], '55', 'wenchong'] # 输出第 2-3 个元素的列表 >>> print( my_list[1:3] ) ['beijing', 'shenzhen'] # 从第一个元素开始,每隔一个元素输出 >>> print( my_list[::2] ) ['shanghai', 'shengzhen', 33, '55'] # 输出第 6 个到最后一个元素 >>> print( my_list[5:]) [['wen', 'chong', 9], '55', 'wenchong']
循环
>>> my_list = ['shanghai', 'beijing', 'shengzhen', 88, 33, ['wen', 'chong', 9], '55', 'wenchong'] >>> for element in my_list: ... print( element ) ... shanghai beijing shengzhen 88 33 ['wen', 'chong', 9] 55 wenchong
enumerate() 函数为可迭代的对象增加上序号,第一个参数为可迭代对象,第二个参数为开始的序号,默认为 0
>>> for k,element in enumerate(my_list): ... print(k,element) ... 0 shanghai 1 beijing 2 shengzhen 3 88 4 33 5 ['wen', 'chong', 9] 6 55 7 wenchong
包含
>>> my_list = ['shanghai', 'beijing', 'shengzhen', 88, 33, ['wen', 'chong', 9], '55', 'wenchong'] >>> 'shanghai' in my_list True >>> 'ShangHai' in my_list False
组合
符号 +
list.extend
>>> list1 = [1,2,3] >>> list2 = [4,5,6] >>> print(list1+list2) [1, 2, 3, 4, 5, 6]
>>> list1 = [1,2,3] >>> list2 = [4,5,6] >>> list1.extend(list2) >>> print( list1 ) [1, 2, 3, 4, 5, 6]
重复
通过 * 号让列表的所有元素重复 N 次
>>> ['a']* 4 ['a', 'a', 'a', 'a']
统计
>>> my_list = [ 1,2,3,3,3,4,5,6] >>> print( my_list.count(3) ) 3 >>> print( my_list.count(1) ) 1
反转
>>> my_list = [1,2,3] >>> my_list.reverse() >>> print( my_list ) [3, 2, 1]
清空
>>> my_list = [1,2,3] >>> my_list.clear() >>> print( my_list ) []
排序
>>> my_list = [5,2,4,1,7] >>> my_list.sort() >>> print( my_list ) [1, 2, 4, 5, 7]
复制
>>> my_list = ['shanghai', 'beijing', 'shengzhen', 88, 33, ['wen', 'chong', 9], '55', 'wenchong'] # 复制 my_list 赋值给变量 my_list_new >>> my_list_2 = my_list.copy() >>> print( my_list_new ) ['shanghai', 'beijing', 'shengzhen', 88, 33, ['wen', 'chong', 9], '55', 'wenchong']
修改 my_list 的第一个元素,my_list 发生变化,my_list_2 不发生变化
>>> my_list[0] = 'ShangHai' >>> print( my_list ) ['ShangHai', 'beijing', 'shengzhen', 88, 33, ['wen', 'chong', 9], '55', 'wenchong'] >>> print( my_list_2 ) ['shanghai', 'beijing', 'shengzhen', 88, 33, ['wen', 'chong', 9], '55', 'wenchong']
修改 my_list 嵌套的第六个元素列表,my_list 和 my_list_2 都发生变化
因为 copy() 方法只会复制第一层,不会复制列表的嵌套,如果需要将嵌套的元素也进行复制,则需借助 copy 模块
>>> my_list[5][0] = 'WEN' >>> print( my_list ) ['ShangHai', 'beijing', 'shengzhen', 88, 33, ['WEN', 'chong', 9], '55', 'wenchong'] >>> print( my_list_2 ) ['shanghai', 'beijing', 'shengzhen', 88, 33, ['WEN', 'chong', 9], '55', 'wenchong']
>>> import copy >>> my_list_3 = copy.deepcopy(my_list) >>> print( my_list ) ['ShangHai', 'beijing', 'shengzhen', 88, 33, ['WEN', 'chong', 9], '55', 'wenchong'] >>> print( my_list_3 ) ['ShangHai', 'beijing', 'shengzhen', 88, 33, ['WEN', 'chong', 9], '55', 'wenchong'] >>> my_list[5][1] = 'CHONG' >>> print( my_list ) ['ShangHai', 'beijing', 'shengzhen', 88, 33, ['WEN', 'CHONG', 9], '55', 'wenchong'] >>> print( my_list_3 ) ['ShangHai', 'beijing', 'shengzhen', 88, 33, ['WEN', 'chong', 9], '55', 'wenchong']
4、元组
与列表类似,区别在于
列表使用方括号,元组使用圆括号
列表的元素可变,元组的元素不可变
创建元组:
>>> tup1 = (1,2,3) >>> tup2 = ('a','b','c') >>> tup3 = 1,2,3; # 创建空元组 >>> tup4 = () # 创建一个元素的元组,最后必须要有一个逗号 >>> tup5 = ('WenChong',)
元组的操作和列表基本相同,除不能修改元素
5、字典
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中 ,格式如下所示:
d = {key1 : value1, key2 : value2 }
字典的特性
字典值可以没有限制地取任何python对象,既可以是标准的对象,也可以是用户定义的
字典键必须遵守下面的条件:
不允许出现两次。创建时如果同一个键被赋值两次,后一个值会被记住
>>> dict = {1:1,2:2,1:3}
>>> print( dict[1] )
3
必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行
>>> idct = {[1]:1}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
创建字典
dict = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
访问字典里的值
通过 key 返回对应的 value
>>> my_dict = {'name':'WenChong','age':999,'gender':'male'}
# 通过 key 获取 value
>>> print( my_dict['name'] )
WenChong
# 当字典中不存在 key 会报错
>>> print( my_dict['job'] )
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'job'
通过 dict.get() 方法获取字典里的值
>>> print( my_dict.get('age') ) 999 # 当 key 不存在时,返回 None >>> print( my_dict.get('job') ) None
通过 dict.setdefault() 方法获取字典里的值,和 dict.get() 方法类型,如果 key 不存在,则添加,value 为第二个参数,默认为 None
>>> my_dict = {'name':'WenChong','age':999,'gender':'male'}
>>> my_dict.setdefault('name')
'WenChong'
>>> my_dict.setdefault('address','ShangHai')
'ShangHai'
>>> print(my_dict)
{'gender': 'male', 'name': 'WenChong', 'age': 999, 'address': 'ShangHai'}
通过 dict.keys() 和 dict.values() 方法返回所有 key 或 value
>>> my_dict = {'name':'WenChong','age':999,'gender':'male'}
# 以列表返回字典所有的 key
>>> print( my_dict.keys() )
dict_keys(['gender', 'age', 'name'])
# 以列表返回字典所有的 value
>>> print( my_dict.values() )
dict_values(['male', 999, 'WenChong'])
通过 dict.items() 方法以列表返回可遍历的(键, 值) 元组数组
>>> my_dict = {'name':'WenChong','age':999,'gender':'male'}
>>> print( my_dict.items() )
dict_items([('gender', 'male'), ('age', 999), ('name', 'WenChong')])
修改字典
向字典中添加新的内容为新增键值对
>>> my_dict = {'name':'WenChong','age':999,'gender':'male'}
# 新增
>>> my_dict['job'] = 'IT'
# 修改
>>> my_dict['age'] = 888
>>> print(my_dict)
{'gender': 'male', 'job': 'IT', 'age': 888, 'name': 'WenChong'}
还可以使用 .update() 方法,参数为一个字典
当 key 存在时,修改 my_dict 字典的值,当 key 不存在时,新增键值对
>>> my_dict = {'name':'WenChong','age':999,'gender':'male'}
>>> my_dict.update({'age':888,'Job':'IT'})
>>> print( my_dict )
{'gender': 'male', 'age': 888, 'Job': 'IT', 'name': 'WenChong'}
删除字典
del 删除整个字典,或者删除字典中的某个键值对
dict.pop() 删除字典中的键值对,参数为 key
dict.clear() 清空整个字典
>>> my_dict = {'name':'WenChong','age':999,'gender':'male'}
# 删除字典的一个键值对
>>> del my_dict['age']
>>> print( my_dict )
{'gender': 'male', 'name': 'WenChong'}
>>> my_dict.pop('gender')
>>> print( my_dict )
{'name': 'WenChong'}
# 删除整个字典,由于字典已经不存在,输出会报错
>>> del my_dict
>>> print( my_dict )
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'my_dict' is not defined
>>> my_dict = {'name':'WenChong','age':999,'gender':'male'}
# 删除字典中的所有键值对
>>> my_dict.clear()
>>> print( my_dict )
获取字典的长度
输出的值为键值对的个数
>>> my_dict = {'name':'WenChong','age':999,'gender':'male'}
>>> print( len(my_dict) )
3
查看字典中是否有 key
python 2.x 中有 dict.has_key() 在 3 中已废弃
>>> my_dict = {'name':'WenChong','age':999,'gender':'male'}
>>> 'name' in my_dict
True
循环输出字典
>>> my_dict = {'name':'WenChong','age':999,'gender':'male'}
>>> for key in my_dict:
... print(key,my_dict[key])
...
gender male
name WenChong
age 999
使用 dict.items() 方法循环,但是效率较低,需要提前将字典转换为列表,不建议使用
>>> for k,v in my_dict.items(): ... print(k,v) ... gender male name WenChong age 999
6、集合
特点:元素无次序,不可重复。
种类:可变集合、不可变集合
创建集合
set() # 创建一个空集合
set(iterable) # 创建一个集合,iterable 是一个可迭代对象
frozenset() # 创建一个不可变的空集合
frozenset(iterable) # 创建一个不可变的集合
# 创建一个空集合 >>> s1 = set() >>> print(s1) set() # 创建一个集合 # 在输出 s2 时,重复的元素 1,2,3 都只出现了一次 >>> s2 = set([1,2,3,4,3,2,1]) >>> print(s2) {1, 2, 3, 4} # 集合的顺序与可迭代对象的顺序无关 >>> s3 = set("wenchong") >>> print(s3) {'n', 'e', 'h', 'c', 'w', 'g', 'o'} # 无序的集合,无法使用索引获取集合内的元素 >>> s3[1] Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'set' object does not support indexing
创建集合时,集合的元素都必须为不可变的,如果 set 的元素中包含 list,dict 等可变数据
>>> s1 = set([1,2,3,[1,2]]) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unhashable type: 'list'
将元素从 list 变更为 tuple
>>> s1 = set([1,2,3,(1,2)]) >>> print(s1) {(1, 2), 1, 2, 3}
set的方法
通过 dir(set) 可以查看 set 的所有方法
>>> dir(set) ['__and__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__iand__', '__init__', '__ior__', '__isub__', '__iter__', '__ixor__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__or__', '__rand__', '__reduce__', '__reduce_ex__', '__repr__', '__ror__', '__rsub__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__xor__', 'add', 'clear', 'copy', 'difference', 'difference_update', 'discard', 'intersection', 'intersection_update', 'isdisjoint', 'issubset', 'issuperset', 'pop', 'remove', 'symmetric_difference', 'symmetric_difference_update', 'union', 'update']
每一个方法都可以通过 help() 函数查看说明
>>> help(set.add) Help on method_descriptor: add(...) Add an element to a set. This has no effect if the element is already present.
下面看下几个常用的方法
add
添加元素到 set 中
# 为 set 集合添加新的元素 >>> s1 = set() >>> s1.add('wenchong') >>> print(s1) {'wenchong'}
update
添加另一个 set 中的元素到自己
>>> s1 = set([1,2,3]) >>> s2 = set([1,2,4,5,6]) # 将 s2 中的元素添加到 s1 中,由于 s2 中的元素 1,2 在 s1 中本身存在,所以只添加了 4,5,6 元素到 s1 中 >>> s1.update(s2) >>> print(s1) {1, 2, 3, 4, 5, 6} >>> print(s2) {1, 2, 4, 5, 6}
pop
随机移除 set 中的一个元素,并返回,如果 set 为空则报错,pop 方法不能移除指定元素
# 定义一个简单的 set >>> s1 = set([1,2,3]) >>> s1.pop() 1 # set.pop() 方法在移除元素时有参数,只能随机移除,报错中 takes no arguments 不需要参数 >>> s1.pop(2) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: pop() takes no arguments (1 given) >>> s1.pop() 2 # 将通过 pop 移除的数据返回给变量 element >>> element = s1.pop() >>> print(element) 3 # 当 set 为空时,使用 pop 方法报错 >>> s1.pop() Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'pop from an empty set'
remove
移除 set 中一个指定的元素,但是如果这个元素不存在,则报错,移除的元素无法赋值给变量
>>> s1 = set([1,2,3]) # 移除 s1 中的元素 1 >>> s1.remove(1) # 之前已经将 1 移除了,再次移除时报错 >>> s1.remove(1) Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 1
discard
移除 set 中一个指定的元素,移除的元素无法赋值给变量,和 remove 的区别是如果元素不存在,不报错
>>> s1 = set([1,2,3]) >>> s1.discard(1) >>> s1.discard(1) >>> print(s1) {2, 3}
clear
移除 set 中的所有元素
copy
返回一个浅拷贝的新 set
difference 【差集】
A.difference(B): 返回一个新的 set ,新 set 的元素为 A 中存在,B 中不存在
>>> s1 = set([1,2,3]) >>> s2 = set([2,3,4]) # 返回新的 set,s1 中有元素1,而 s2 中没有元素 1,故返回 1 >>> s1.difference(s2) {1} # 返回新的 set,s2 中有元素4,而 s1 中没有元素 4,故返回 1 >>> s2.difference(s1) {4}
symmetric_difference 【对差集】
A.symmetric_difference(B): 返回一个新的 set ,新 set 的元素为 A 中存在,B 中不存在,以及 B 中存在,A 中不存在
>>> s1 = set([1,2,3]) >>> s2 = set([2,3,4]) # 元素 1 只存在于 s1 中,元素 4 只存在于 s2 中,故返回一个新的 set: {1,4} # s1 和 s2 谁作为参数无所谓 >>> s1.symmetric_difference(s2) {1, 4} >>> s1.symmetric_difference(s2) {1, 4}
difference_update 【差集】
A.difference_update(B): 与 difference 返回的 set 相同,但是会将 返回的 set 赋值给 A
>>> s1 = set([1,2,3]) >>> s2 = set([2,3,4]) # 返回 s1 中存在,而 s2 中不存在元素集合,再将该集合赋值给 s1 >>> s1.difference_update(s2) >>> print(s1) {1} >>> s1 - s2 {1}
>>> s1 = set([1,2,3]) >>> s2 = set([2,3,4]) # 返回 s2 中存在,而 s1 中不存在元素集合,再将该集合赋值给 s2 >>> s2.difference_update(s1) >>> print(s2) {4} >>> s2 - s1 {4}
symmetric_difference_update【対差集】
A.symmetric_difference_update(B): 与 symmetric_difference 返回的 set 相同,但是会将返回的 set 赋值给 A
>>> s1 = set([1,2,3]) >>> s2 = set([2,3,4]) >>> s1.symmetric_difference_update(s2) >>> print(s1) {1, 4} # 重新定义 s1 >>> s1 = set([1,2,3]) >>> s2.symmetric_difference_update(s1) >>> print(s2) {1, 4}
intersection【交集】
A.intersection(B,C,D...): 返回所有集合的交集,即在所有 set 中都存在的元素集合
>>> s1 = set([1,2,3]) >>> s2 = set([2,3,4]) >>> s3 = set([3,4,5]) >>> s1.intersection(s2) {2, 3} >>> s2.intersection(s1) {2, 3} >>> s1.intersection(s2,s3) {3} >>> s1 & s2 {2, 3} >>> s1 & s2 & s3 {3}
intersection_update【交集】
A.intersection_update(B): 与 intersection 返回的 set 相同,但是会将返回的 set 赋值给 A
union【并集】
A.union(B,C,D...): 返回两个或多个 set 的并集,即所有的 set 中的元素
>>> s1 = set([1,2,3])
>>> s2 = set([2,3,4])
>>> s3 = set([3,4,5])
>>> s1.union(s2,s3)
{1, 2, 3, 4, 5}
>>> s1 | s2 | s3
{1, 2, 3, 4, 5}
isdisjoint
A.isdisjoint(B): 如果 A 与 B 没有交集,则返回 True,有交集则返回 False
>>> s1 = set([1,2,3]) >>> s2 = set([2,3,4]) # 返回 s1 与 s2 的交集 >>> s1.intersection(s2) {2, 3} # s1 与 s2 有交集,返回 False >>> s1.isdisjoint(s2) False
issubset【子集】
A.issubset(B): 集合 A 中的所有元素,是否 B 中都存在,如果存在则返回 True,不存在则返回 False
issuperset【超集/父集】
A.issuperset(B): 集合 A 中包含集合 B 中的所有元素则返回 True,否则返回 False,与 issubset 相反
>>> s1 = set([2,3]) >>> s2 = set([1,2,3,4]) # 判断 s1 是否为 s2 的子集 >>> s1.issubset(s2) True >>> s1 < s2 True # 判断 s2 是否为 s1 的超集 >>> s2.issuperset(s1) True >>> s2 > s1 True
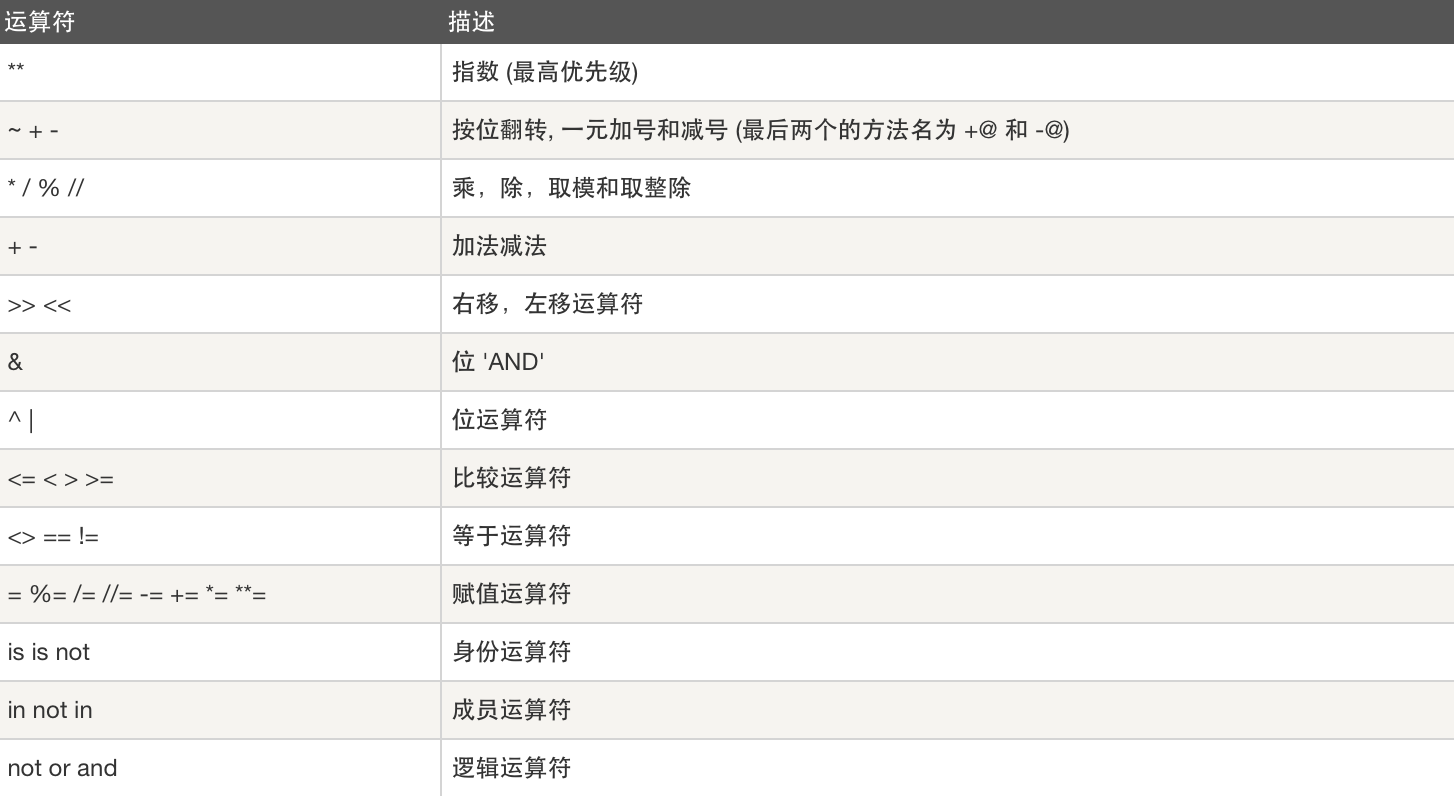
二、运算符
算术运算符
假设 a=10,b=20
比较运算符
假设 a=10,b=20

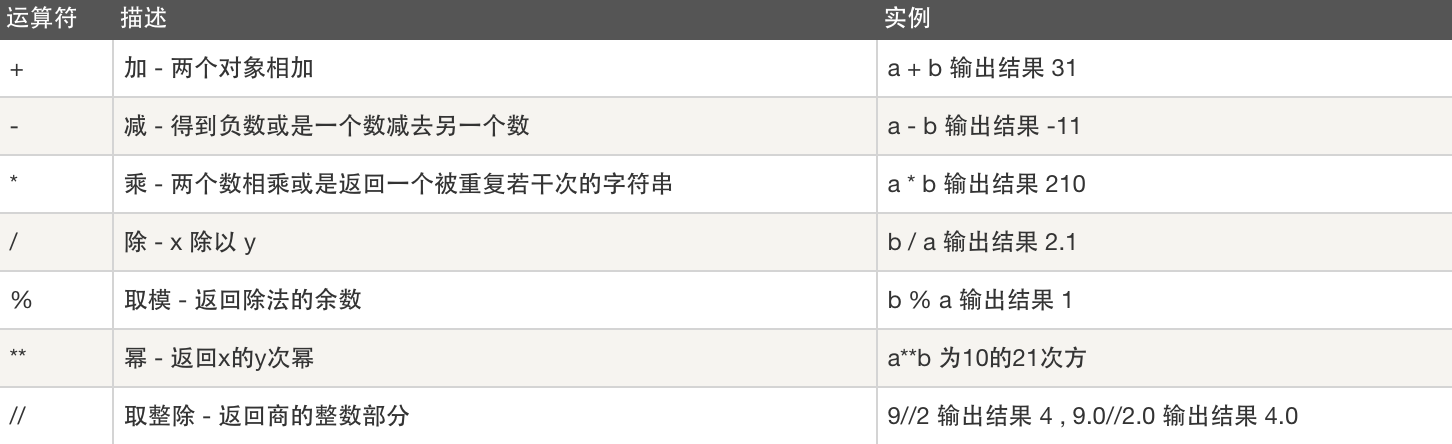
赋值运算符
假设 a=10,b=20
逻辑运算符
假设 a=10,b=20

成员运算符

身份运算符

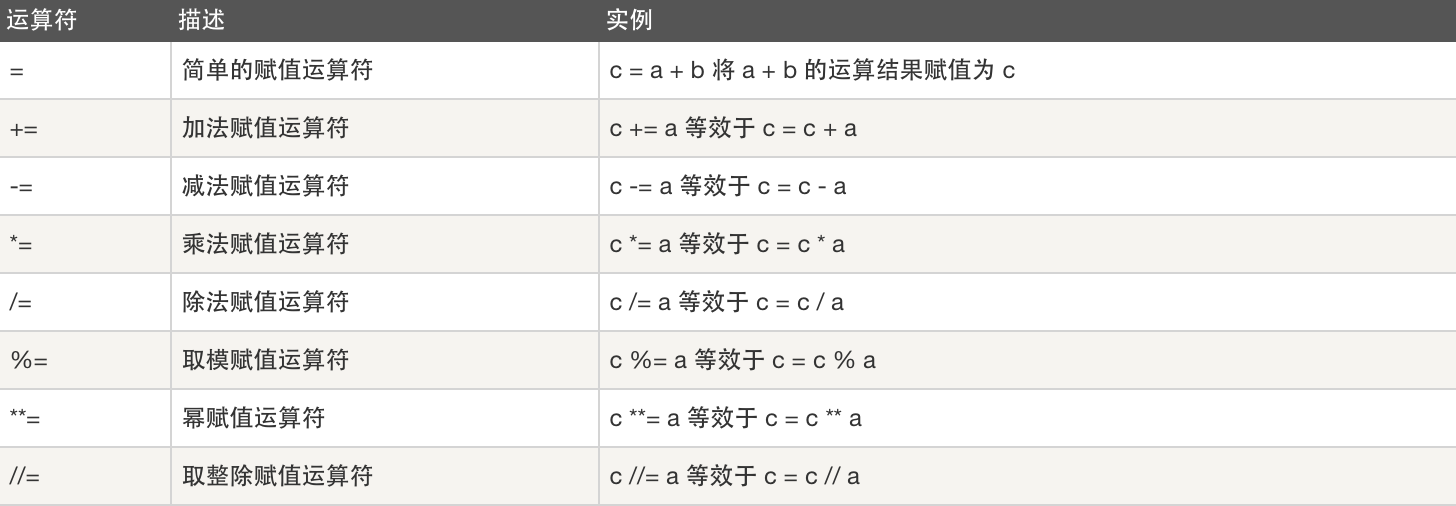
位运算符
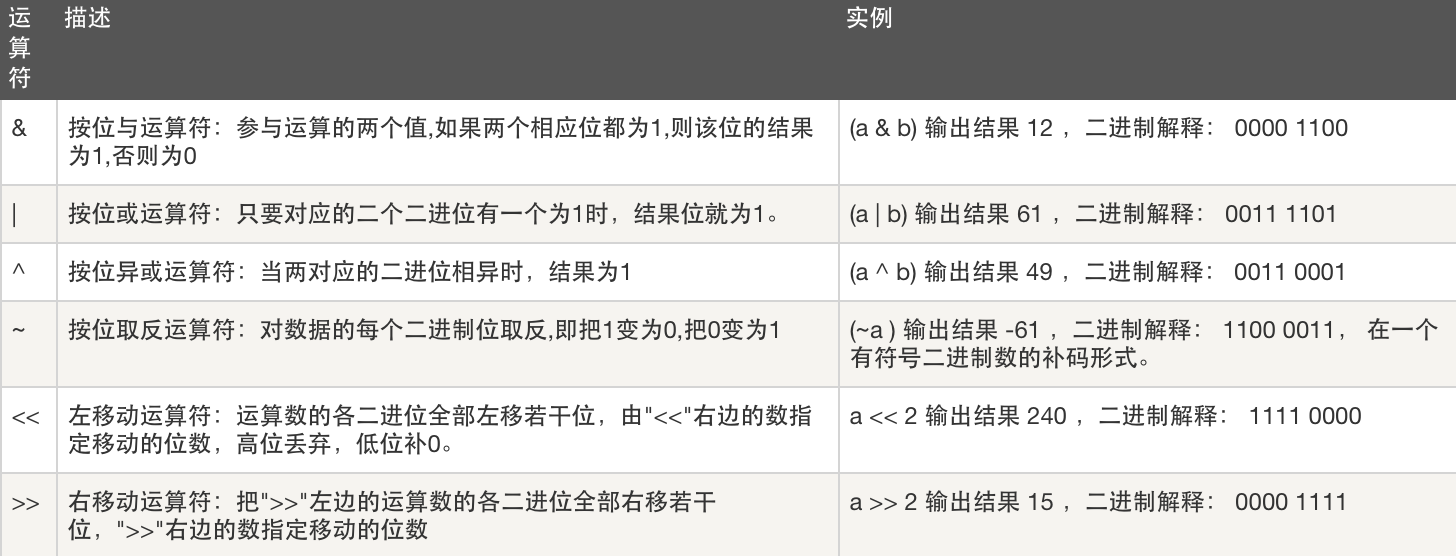
运算符的优先级