


lucene-01-简介
1, 介绍
hadoop作者开发的
hdfs最开始作为netch的文件存储来使用的
2, 存储结构
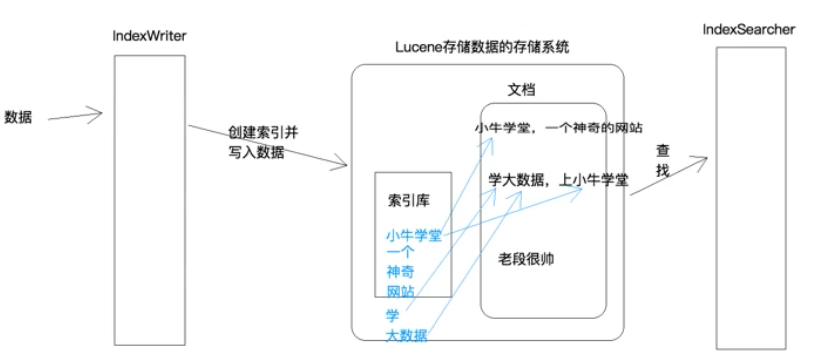
lucene快的原因, 是因为添加数据的时候会对数据进行分词, 将分词后的词建立索引,
存储到索引库中, 然后将真正的内容即文档保存起来, 存储在文档中
查找时, 将查询条件分词, 先在索引库中查找, 如果查找到会返回 document_id, 然后根据文档id再到
存储文档的区域, 查找真正的内容
3, 数据库和全文检索的区别
数据库 模糊查询不走index, 速度慢, 不准确
全文检索: 快速, 准确的找到想要的数据
快: 先从索引库中查找
准: 对查询条件进行分词, 然后对查询的结果进行相关度查询

