16-hadoop-mapreduce简介
mapreduce是hadoop的核心组件, 设计理念是移动计算而不是移动数据,
mapreduce的思想是'分而治之', 将复杂的任务分解成几个简单的任务去执行
1, 数据和计算规模大大减少 2, 就近计算, 移动计算 3, 小任务并行计算, 彼此间没有依赖
共分为4个步骤:

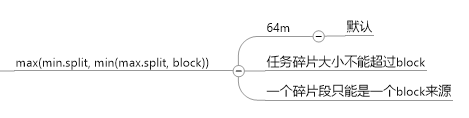
1, split
切分blcok, 切分为数据片段, split0, split1, split2
计算公式为:
2, map
自定义的程序, 根据业务需求来的,
map任务的多少, 根据碎片的多少来的, 即上一步切分为多少个split , 每个split位一个线程, split传递的数据为 key-value的形式, 输出形式也为键值对

相同key的数据, 输出为一组数据, 然后将数据进行下一步, 洗牌(sharp)
3, shuffler
包括 sort 和 merger, 把mapper输出的的数据进行切分, 排序, 组合等操作, 吧key符合某种范围的输出到特定的reducer那里
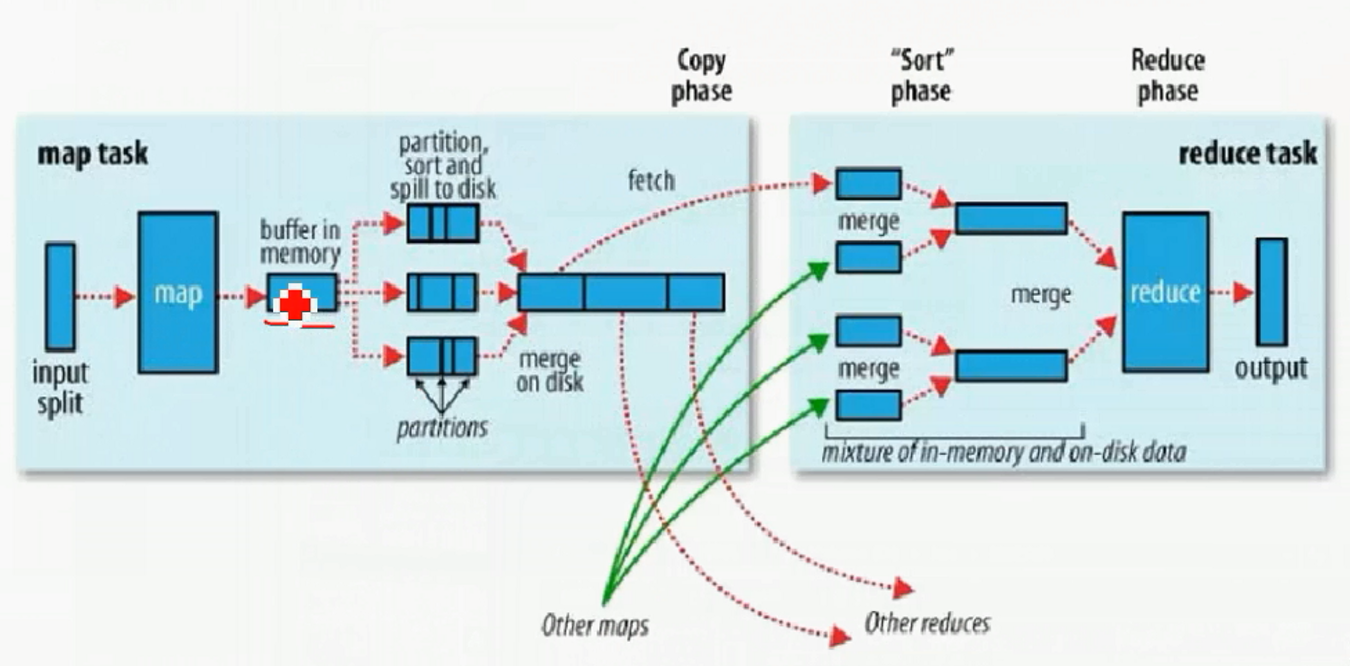
过程为:
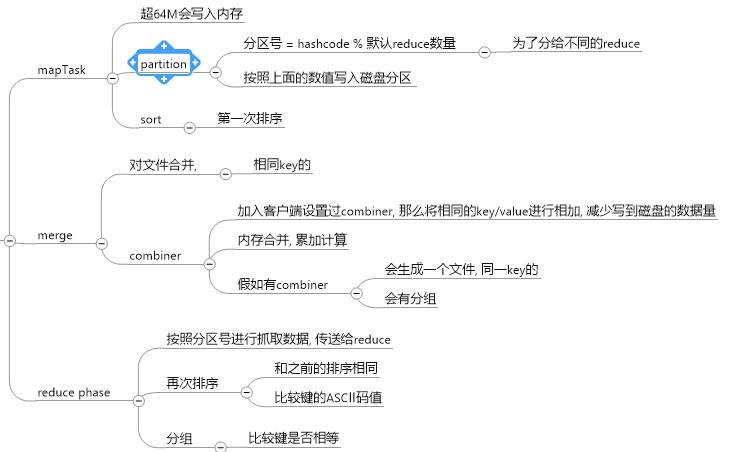
4, reduce
reduce的数量, 
一个mapreduce 默认 只有一个reduce , 可通过配置分区数来更改reduce的数量

 浙公网安备 33010602011771号
浙公网安备 33010602011771号