doris03-简单使用
doris03-简单使用
1. 设置用户名和密码
1.1) 修改root密码
登陆
mysql -h FE_HOST -P9030 -uroot
fe_host 是任一 FE 节点的 ip 地址。9030 是 fe.conf 中的 query_port 配置。
设置密码:
SET PASSWORD FOR 'root' = PASSWORD('root');
1.2) 创建新用户
CREATE USER 'test' IDENTIFIED BY 'test_passwd';
后续登陆可以使用新创建的用户登陆
mysql -h FE_HOST -P9030 -uwenbronk -pa75
授权: 需要先建库
GRANT ALL ON example_db TO wenbronk;
2 建库建表, 导入数据
2.1) 建库, 此步也是授权的前提
CREATE DATABASE testdb;
2.2) 建表
use testdb;
查看帮助
help create table;
此命令在terminal下可以正常执行, 但在navicat中不可以, 不知道为什么, 为了方便, 贴在最后
Doris支持支持单分区和复合分区两种建表方式。
- 第一级称为 Partition,即分区。用户可以指定某一维度列作为分区列(当前只支持整型和时间类型的列),并指定每个分区的取值范围。
- 第二级称为 Distribution,即分桶。用户可以指定一个或多个维度列以及桶数对数据进行 HASH 分布。
2.2.1) 单分区
CREATE TABLE table1
(
siteid INT DEFAULT '10',
citycode SMALLINT,
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(siteid, citycode, username)
DISTRIBUTED BY HASH(siteid) BUCKETS 32
PROPERTIES("replication_num" = "1");
导入数据
将 table1_data 导入 table1 中
1,1,jim,2
2,1,grace,2
3,2,tom,2
4,3,bush,3
5,3,helen,3
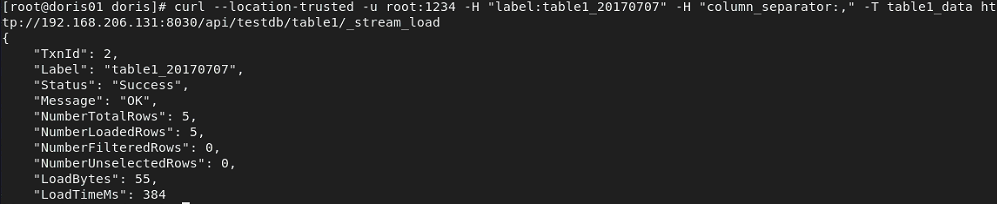
curl --location-trusted -u root:root -H "label:table1_20170707" -H "column_separator:," -T table1_data http://192.168.206.131:8030/api/testdb/table1/_stream_load
2.2.2) 多分区
CREATE TABLE table2
(
event_day DATE,
siteid INT DEFAULT '10',
citycode SMALLINT,
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(event_day, siteid, citycode, username)
PARTITION BY RANGE(event_day)
(
PARTITION p201706 VALUES LESS THAN ('2017-07-01'),
PARTITION p201707 VALUES LESS THAN ('2017-08-01'),
PARTITION p201708 VALUES LESS THAN ('2017-09-01')
)
DISTRIBUTED BY HASH(siteid) BUCKETS 16
PROPERTIES("replication_num" = "1");
replication_num指分区数目, 想要3个分区必须有3个不同节点部署的be
导入数据
将 table2_data 导入 table2 中
2017-07-03|1|1|jim|2
2017-07-05|2|1|grace|2
2017-07-12|3|2|tom|2
2017-07-15|4|3|bush|3
2017-07-12|5|3|helen|3
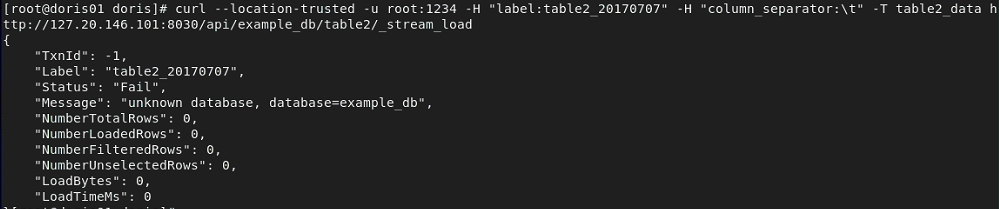
curl --location-trusted -u root:root -H "label:table2_20170707" -H "column_separator:|" -T table2_data http://127.20.146.101:8030/api/testdb/table2/_stream_load
从table1, 和table2中就可以查询到了
3. 简单查询
3.1) 简单查询
SELECT * FROM table1 LIMIT 3;
SELECT * FROM table1 ORDER BY citycode;
3.2) join
SELECT SUM(table1.pv) FROM table1 JOIN table2 WHERE table1.siteid = table2.siteid;
select table1.siteid, sum(table1.pv) from table1 join table2 where table1.siteid = table2.siteid group by table1.siteid;
3.3) 子查询
SELECT SUM(pv) FROM table2 WHERE siteid IN (SELECT siteid FROM table1 WHERE siteid > 2);
4. 高级功能
4.1) 表结构变更
使用alter table 命令, 可进行
- 增加列
- 删除列
- 修改列类型
- 改变列顺序
对上面的table1 添加一列
ALTER TABLE table1 ADD COLUMN uv BIGINT SUM DEFAULT '0' after pv;
之后执行查看进度
show alter table column;
执行中

执行成功

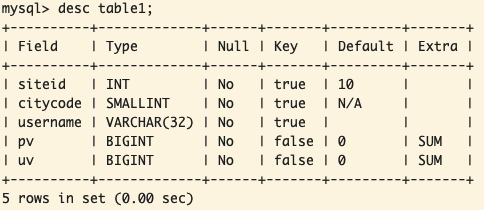
查看数据表结构变更
如果想取消掉正在执行的alter, 则使用
CANCEL ALTER TABLE COLUMN FROM table1
4.2) rollup
Rollup 可以理解为 Table 的一个物化索引结构。物化 是因为其数据在物理上独立存储,而 索引 的意思是,Rollup可以调整列顺序以增加前缀索引的命中率,也可以减少key列以增加数据的聚合度。
对于 table1 明细数据是 siteid, citycode, username 三者构成一组 key,从而对 pv 字段进行聚合;如果业务方经常有看城市 pv 总量的需求,可以建立一个只有 citycode, pv 的rollup。
ALTER TABLE table1 ADD ROLLUP rollup_city(citycode, pv);
通过命令查看完成状态
SHOW ALTER TABLE ROLLUP;
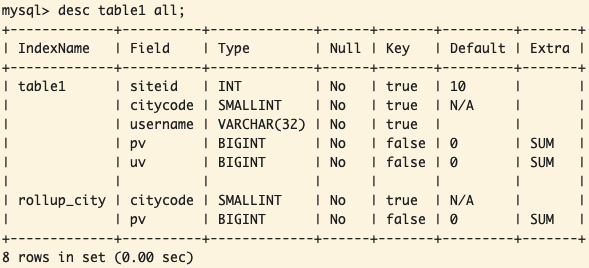
之后可以查看完成情况
DESC table1 ALL
如果不想创建, 可取消掉
CANCEL ALTER TABLE ROLLUP FROM table1;
5. 高级设置
5.1) 增大内存
内存不够时, 查询可能会出现‘Memory limit exceeded’, 这是因为doris对每个用户默认设置内存限制为 2g
mysql> show variables like '%mem_limit%';
+----------------+------------+
| Variable_name | Value |
+----------------+------------+
| exec_mem_limit | 2147483648 |
| load_mem_limit | 0 |
+----------------+------------+
2 rows in set (0.00 sec)
可以修改为 8g
SET exec_mem_limit = 8589934592;
上述设置仅仅在当前session有效, 如果想永久有效, 需要添加 global 参数
SET GLOBAL exec_mem_limit = 8589934592;
5.2) 修改超时时间
doris默认最长查询时间为300s, 如果仍然未完成, 会被cancel掉
mysql> SHOW VARIABLES LIKE "%query_timeout%";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| QUERY_TIMEOUT | 300 |
+---------------+-------+
1 row in set (0.00 sec)
可以修改为60s
SET query_timeout = 60;
同样, 如果需要全局生效需要添加参数 global
set global query_timeout = 60;
5.3) Broadcast/Shuffle Join
doris在join操作的时候时候, 默认使用broadcast的方式进行join, 即将小表通过广播的方式广播到大表所在的节点, 形成内存hash, 然后流式读出大表数据进行hashjoin
但如果小表的数据量也很大的时候, 就会造成内存溢出, 此时需要通过shuffle join的方式进行, 也被称为partition join. 即将大表小表都按照join的key进行hash, 然后进行分布式join
braodcast join
select sum(table1.pv) from table1 join table2 where table1.siteid = 2;
显示制定braodcast
select sum(table1.pv) from table1 join [broadcast] table2 where table1.siteid = 2;
suffle join
select sum(table1.pv) from table1 join [shuffle] table2 where table1.siteid = 2;
5.4) doris的高可用方案
用户可以在多个fe上部署负载均衡实现
或者通过mysql connect 自动重连
jdbc:mysql://[host:port],[host:port].../[database][?propertyName1][=propertyValue1][&propertyName2][=propertyValue2]...
或者应用可以连接到和应用部署到同一机器上的 MySQL Proxy,通过配置 MySQL Proxy 的 Failover 和 Load Balance 功能来达到目的。
http://dev.mysql.com/doc/refman/5.6/en/mysql-proxy-using.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号