基于JDK1.8的HashMap分析
HashMap的强大功能,相信大家都了解一二。之前看过HashMap的源代码,都是基于JDK1.6的,并且知其然不知其所以然,现在趁着寒假有时间,温故而知新。文章大概有以下几个方面:
- HashMap的数据结构
- put方法
- get方法
(一)HashMap的底层数据结构
1 static class Node<K,V> implements Map.Entry<K,V> { 2 final int hash; 3 final K key; 4 V value; 5 Node<K,V> next; 6 7 Node(int hash, K key, V value, Node<K,V> next) { 8 this.hash = hash; 9 this.key = key; 10 this.value = value; 11 this.next = next; 12 } 13 14 public final K getKey() { return key; } 15 public final V getValue() { return value; } 16 public final String toString() { return key + "=" + value; } 17 18 //hashCode等其他代码 19 }
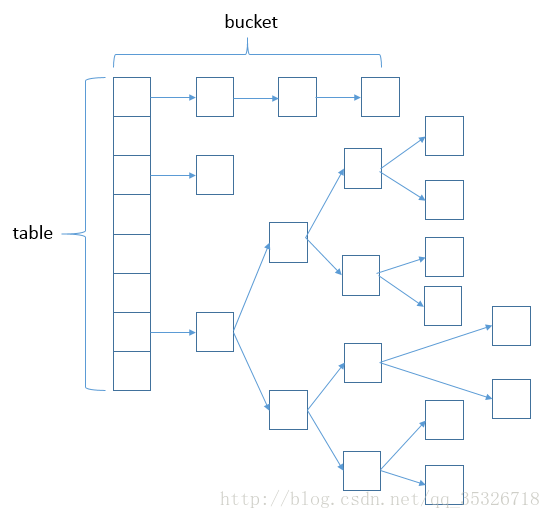
首先,HashMap 是 Map 的一个实现类,它代表的是一种键值对的数据存储形式。Key 不允许重复出现,Value 随意。jdk 8 之前,其内部是由数组+链表来实现的,而 jdk 8 对于链表长度超过 8 的链表将转储为红黑树。
底层数据结构就是 数组 + 链表 + 红黑树(长度>8),其中有一个静态内部类
1 static class Node<K,V> implements Map.Entry<K,V>
这个静态内部类就是一个小的方块,在jdk1.8之前只在构造方法里面初始化的,现在是在第一次put的时候初始化的。
(二)HashMap的put方法
put 方法的源码分析是本篇的一个重点,因为通过该方法我们可以窥探到 HashMap 在内部是如何进行数据存储的,所谓的数组+链表+红黑树的存储结构是如何形成的,又是在何种情况下将链表转换成红黑树来优化性能的。带着一系列的疑问,我们看这个 put 方法:
1 public V put(K key, V value) { 2 return putVal(hash(key), key, value, false, true); 3 }
也就是put方法调用了putVal方法,其中传入一个参数位hash(key),我们首先来看看hash这个方法。
1 static final int hash(Object key) { 2 int h; 3 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); 4 }
是一个静态final方法。这是为什么key可以位null的原因了,当插入的key值为null,他会自动把他当作0进行处理
并且调用了key的hashcode,这就是为什么map的key一定要重写hashcode和equals方法。
并且与h右移16位异或。我们来详细看看这里为什么这样做。
我们知道,按位异或就是把两个数按二进制,相同就取0,不同就取1。
比如:0101 ^ 1110 的结果为 1011。异或的速度是非常快的。
把一个数右移16位即丢弃低16为,就是任何小于2^16的数,右移16后结果都为0(2的16次方再右移刚好就是1)。
任何一个数,与0按位异或的结果都是这个数本身(很好验证)。
所以这个hash()函数对于非null的hash值,仅在其大于等于2^16的时候才会重新调整其值,小于2^16不做调整直接取他的hashcode值。
至于为什么右移16位异或,这是知乎上面的一幅图片
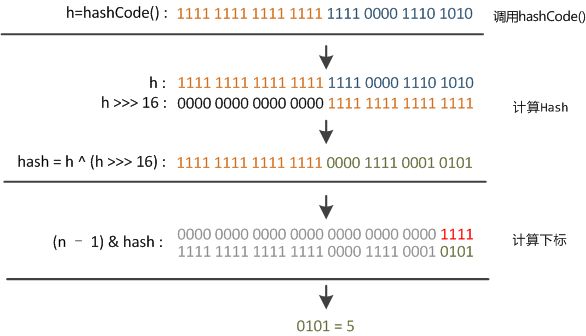
看到没有,变得“松散”了很多,至于为什么,我也不是很清楚。我们继续往下看putVal这个方法。
1 final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) { 2 Node<K,V>[] tab; Node<K,V> p; int n, i; 3 //如果 table 还未被初始化,那么初始化它 4 if ((tab = table) == null || (n = tab.length) == 0) 5 n = (tab = resize()).length; 6 //根据键的 hash 值找到该键对应到数组中存储的索引 7 //如果为 null,那么说明此索引位置并没有被占用 8 if ((p = tab[i = (n - 1) & hash]) == null) 9 tab[i] = newNode(hash, key, value, null); 10 //不为 null,说明此处已经被占用,只需要将构建一个节点插入到这个链表的尾部即可 11 else { 12 Node<K,V> e; K k; 13 //当前结点和将要插入的结点的 hash 和 key 相同,说明这是一次修改操作 14 if (p.hash == hash && 15 ((k = p.key) == key || (key != null && key.equals(k)))) 16 e = p; 17 //如果 p 这个头结点是红黑树结点的话,以红黑树的插入形式进行插入 18 else if (p instanceof TreeNode) 19 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); 20 //遍历此条链表,将构建一个节点插入到该链表的尾部 21 else { 22 for (int binCount = 0; ; ++binCount) { 23 if ((e = p.next) == null) { 24 p.next = newNode(hash, key, value, null); 25 //如果插入后链表长度大于等于 8 ,将链表裂变成红黑树 26 if (binCount >= TREEIFY_THRESHOLD - 1) 27 treeifyBin(tab, hash); 28 break; 29 } 30 //遍历的过程中,如果发现与某个结点的 hash和key,这依然是一次修改操作 31 if (e.hash == hash && 32 ((k = e.key) == key || (key != null && key.equals(k)))) 33 break; 34 p = e; 35 } 36 } 37 //e 不是 null,说明当前的 put 操作是一次修改操作并且e指向的就是需要被修改的结点 38 if (e != null) { 39 V oldValue = e.value; 40 if (!onlyIfAbsent || oldValue == null) 41 e.value = value; 42 afterNodeAccess(e); 43 return oldValue; 44 } 45 } 46 ++modCount; 47 //如果添加后,数组容量达到阈值,进行扩容 48 if (++size > threshold) 49 resize(); 50 afterNodeInsertion(evict); 51 return null; 52 }
注释已经很清楚了,我想说下这个初始化的问题
//如果 table 还未被初始化,那么初始化它 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length;
这个resize()方法既可以初始化,也可以扩容,都是这个函数完成的。并且在多线程下,不会出现之前的死锁导致cpu飙升至100%,只会出现数据丢失的问题。
首先,我们看 resize 这个方法是如何对 table 进行初始化的
1 //第一部分 2 final Node<K,V>[] resize() { 3 Node<K,V>[] oldTab = table; 4 //拿到旧数组的长度 5 int oldCap = (oldTab == null) ? 0 : oldTab.length; 6 int oldThr = threshold; 7 int newCap, newThr = 0; 8 //说明旧数组已经被初始化完成了,此处需要给旧数组扩容 9 if (oldCap > 0) { 10 //极限的限定,达到容量限定的极限将不再扩容 11 if (oldCap >= MAXIMUM_CAPACITY) { 12 threshold = Integer.MAX_VALUE; 13 return oldTab; 14 } 15 //未达到极限,将数组容量扩大两倍,阈值也扩大两倍 16 else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && 17 oldCap >= DEFAULT_INITIAL_CAPACITY) 18 newThr = oldThr << 1; 19 } 23 else if (oldThr > 0) 24 newCap = oldThr; 25 //数组未初始化并且阈值也为0,说明一切都以默认值进行构造 26 else { 27 newCap = DEFAULT_INITIAL_CAPACITY; 28 newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); 29 } 32 if (newThr == 0) { 33 float ft = (float)newCap * loadFactor; 34 newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? 35 (int)ft : Integer.MAX_VALUE); 36 } 37 threshold = newThr; 38 //根据新的容量初始化一个数组 39 Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; 40 table = newTab; 41 //旧数组不为 null,这次的 resize 是一次扩容行为 42 if (oldTab != null) { 43 //将旧数组中的每个节点位置相对静止地拷贝值新数组中 44 for (int j = 0; j < oldCap; ++j) { 45 Node<K,V> e; 46 //获取头结点 47 if ((e = oldTab[j]) != null) { 48 oldTab[j] = null; 49 //说明链表或者红黑树只有一个头结点,转移至新表 50 if (e.next == null) 51 newTab[e.hash & (newCap - 1)] = e; 52 //如果 e 是红黑树结点,红黑树分裂,转移至新表 53 else if (e instanceof TreeNode) 54 ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); 55 //这部分是将链表中的各个节点原序地转移至新表中 56 else { 57 Node<K,V> loHead = null, loTail = null;// 代表原来的地方 58 Node<K,V> hiHead = null, hiTail = null;// 代表高位 59 Node<K,V> next; 60 do { 61 next = e.next;
62 if ((e.hash & oldCap) == 0) { // 以oldCap来区分将数据放到原来的地方还是放到高位 63 if (loTail == null) 64 loHead = e; 65 else 66 loTail.next = e; 67 loTail = e; 68 } 69 else { 70 if (hiTail == null) 71 hiHead = e; 72 else 73 hiTail.next = e; 74 hiTail = e; 75 } 76 } while ((e = next) != null); 77 if (loTail != null) { 78 loTail.next = null; 79 newTab[j] = loHead; 80 } 81 if (hiTail != null) { 82 hiTail.next = null; 83 newTab[j + oldCap] = hiHead; 84 } 85 } 86 } 87 } 88 } 89 //不论你是扩容还是初始化,都可以返回 newTab 90 return newTab;
JDK大神真的是太厉害了,膜拜啊膜拜。
将冲突多的,比如链表或者红黑树,放到扩容后的那一半,那么以后冲突就会减少很多。
就是判断旧的数组那一位到底为不为一。比如4(0100),只要第二位为1,全部放到highHead那里,否则lowHead.
我们看上面代码的第62行
这个oldCap表示扩容之前数组的长度,一定是为2的倍数。即二进制中只有一位为1,其他位都位0
1 if ((e.hash & oldCap) == 0)
如果原 oldCap 为 10000 的话,那么扩容后的 newCap 则为 100000,会比原来多出一位。所以我们只要知道原索引值的前一位是 0 还是 1 即可,如果是 0,那么它和新容量与后还是 0 并不改变索引的值,如果是 1 的话,那么索引值会增加 oldCap。
这样就分两步拆分当前链表,一条链表是不需要移动的,依然保存在当前索引值的结点上,另一条则需要变动到 index + oldCap 的索引位置上。
既假如原数组前一位是0那么还是原index位置,否则就是两倍。
这一块真的写的很好,如下图扩容
table[1] = 1 -> 5 -> 9 -> 13
扩容后,1,9留在了原来的地方、
5,13去了高位 table[5] = 1 + 4
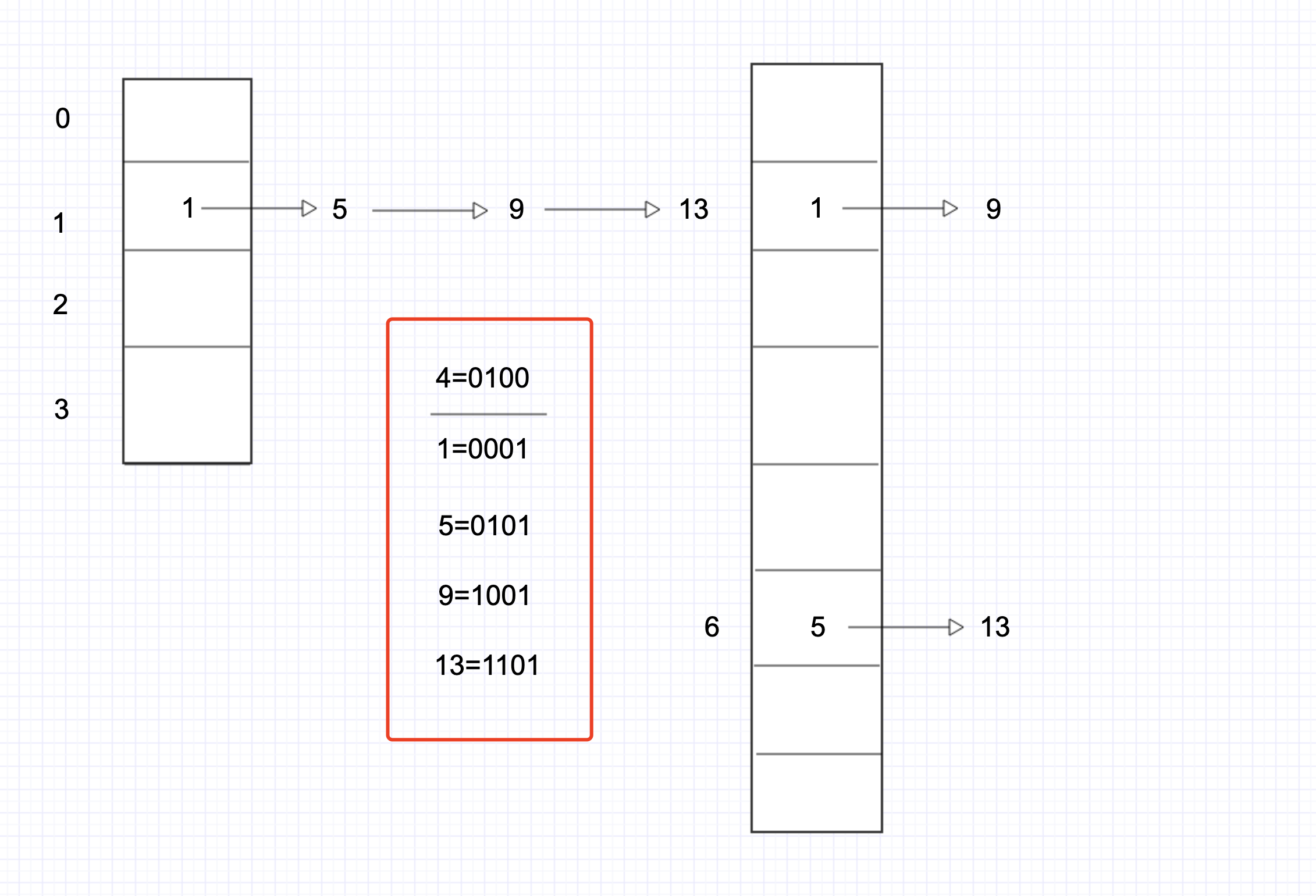
至此,put方法就差不多了。可以详细的看下代码的注释,结合jdk来理解。
ps. 我其实看的时候有一个疑问。为何不把冲突的全部放到扩容的另外一半呢。这也许就是JDK1.8的新特性吧
我去网上找了找1.8之前的扩容,就是把链表全部放进后面。
所以会产生死循环。而你1.8以后,分成了两个,肯定不会出现指向同一个元素,所以不会出现死循环。
不过我觉得这是一个鸡肋,HashMap线程不安全,没必要考虑这些。
将冲突多的全部放到扩容后的另外一半,我觉得是最好的。(只是个人建议哈)
(三)HashMap的get方法
相对于put方法,get方法就简单很多了。
public V get(Object key) { Node<K,V> e; //直接调用了getNode() return (e = getNode(hash(key), key)) == null ? null : e.value; }
1 final Node<K,V> getNode(int hash, Object key) { 2 Node<K,V>[] tab; Node<K,V> first, e; int n; K k; 3 //先判断数组是否为空,长度是否大于0,那个node节点是否存在 4 if ((tab = table) != null && (n = tab.length) > 0 && 5 (first = tab[(n - 1) & hash]) != null) { 6 //如果找到,直接返回 7 if (first.hash == hash && // always check first node 8 ((k = first.key) == key || (key != null && key.equals(k)))) 9 return first; 10 if ((e = first.next) != null) { 11 //如果是红黑树,去红黑树找 12 if (first instanceof TreeNode) 13 return ((TreeNode<K,V>)first).getTreeNode(hash, key); 14 //链表找 15 do { 16 if (e.hash == hash && 17 ((k = e.key) == key || (key != null && key.equals(k)))) 18 return e; 19 } while ((e = e.next) != null); 20 } 21 } 22 return null; 23 }
总结:
终于写完了,也是自己的第一篇博文,写了自己比较熟悉的HashMap,花了自己挺久的时间。
之前一直在github wenbochang888 上面写,发觉排版很是麻烦,所以来到了博客园,博客园也是我经常逛的博客之一,没有广告,博文质量高,反正就是非常的喜欢。
希望自己可以坚持下去,无聊就去写写,没有必要说一天几篇,几天几篇什么的,自己开心就好。
自己文笔不好,很多东西表达不出来,望见谅。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号