
redis系列之------对象
前言
Redis 并没有直接使用数据结构来实现键值对数据库, 而是基于这些数据结构创建了一个对象系统, 这个系统包含字符串对象、列表对象、哈希对象、集合对象和有序集合对象这五种类型的对象, 每种对象都用到了至少一种我们前面所介绍的数据结构。
通过这五种不同类型的对象, Redis 可以在执行命令之前, 根据对象的类型来判断一个对象是否可以执行给定的命令。 使用对象的另一个好处是, 我们可以针对不同的使用场景, 为对象设置多种不同的数据结构实现, 从而优化对象在不同场景下的使用效率。
除此之外, Redis 的对象系统还实现了基于引用计数技术的内存回收机制: 当程序不再使用某个对象的时候, 这个对象所占用的内存就会被自动释放; 另外, Redis 还通过引用计数技术实现了对象共享机制, 这一机制可以在适当的条件下, 通过让多个数据库键共享同一个对象来节约内存。
对象的类型与编码
Redis 使用对象来表示数据库中的键和值, 每次当我们在 Redis 的数据库中新创建一个键值对时, 我们至少会创建两个对象, 一个对象用作键值对的键(键对象), 另一个对象用作键值对的值(值对象)。
Redis 中的每个对象都由一个 redisObject 结构表示, 该结构中和保存数据有关的三个属性分别是 type 属性、 encoding 属性和 ptr 属性:

1 typedef struct redisObject { 2 3 // 类型 4 unsigned type:4; 5 6 // 编码 7 unsigned encoding:4; 8 9 // 指向底层实现数据结构的指针 10 void *ptr; 11 12 // ... 13 14 } robj;
我们可以看到一个对象中主要包含了三种字段。
type: 表示对象的类型。比如String,List,Hash等等
encoding:表示对象底层用的是什么数据结构。如INT(整数),EMBSTR(简洁版sds),RAW(sds),HT(map)等等
ptr:ptr是一个指针,指向对象所用的数据结构。
如下图所示:
set k v
k是String类型,embstr数据结构,也就是简洁版的sds,后续讲。
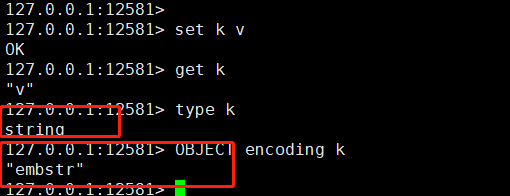
embstr与sds区别
之前我们讲数据结构,都没有见到过embStr,是的,我也是看到这一节才知道有这个东西的。
Redis为了优化,搞了一个embStr,他是为了专门存短字符串的一种编码优化方式。
embstr编码将创建字符串对象所需的内存分配次数从raw编码的两次降低为一次。raw编码会调用两次内存分配函数来分别创建redisObject结构和sdshdr结构, 而embstr编码则通过调用一次内存分配函数来分配一块连续的空间, 空间中依次包含redisObject和sdshdr两个结构。因为一个连续,一个不连续。
- 释放
embstr编码的字符串对象只需要调用一次内存释放函数, 而释放raw编码的字符串对象需要调用两次内存释放函数。理由同上
- 因为
embstr编码的字符串对象的所有数据都保存在一块连续的内存里面, 所以这种编码的字符串对象比起raw编码的字符串对象能够更好地利用缓存带来的优势。
总的来说,因为embstr分配的是一段连续的内存,使得它分配释放内存都是一次,所以效率会有所提高。同时embste <==> sds 为44个字节。
从下图中,我们可以明确看到。 len <= 44 都是embster的数据结构,如果len > 44 则转变为raw。至于为啥44。
大家可以去算一下。参考文章:
https://zhuanlan.zhihu.com/p/67876900
https://xiaoyue26.github.io/2019/01/19/2019-01/redis%E7%9A%84embstr%E4%B8%BA%E4%BB%80%E4%B9%88%E6%98%AF39B/
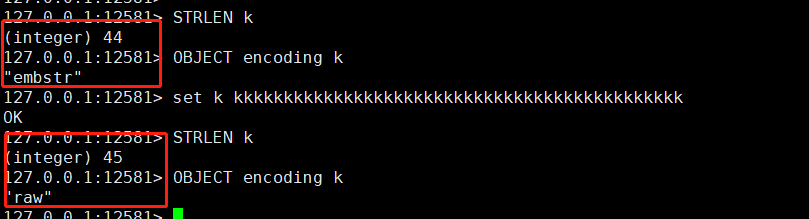
内存
Redis为了节省内存,真的是操碎了心。
c语言不像Java,Go等语言,本身不具备自动回收内存机制。Java的内存回收导致STW一直被人诟病,最近看了ZGC的数据,Java真的是崛起了。
因此Redis 在自己的对象系统中构建了一个引用计数(reference counting)技术实现的内存回收机制, 通过这一机制, 程序可以通过跟踪对象的引用计数信息, 在适当的时候自动释放对象并进行内存回收。
但熟悉JVM的都知道,引用计数他有一种缺陷就是,解决不了循环引用的问题。
如 A <==> B 但已经没有其他任何节点引用AB了,但AB由于相互引用,计数为1,永远不会被回收。所以Java用了GC ROOT。
但Redis不知道为啥不存在这个问题,找了资料,也没找出什么原因。大多都说Redis没有复杂的结构,所以?有大佬能解答下不?
引用计数我们可以通过 OBJECT refcount token 命令,查询到token被引用了几次,如果为0,那么则可以回收了。
还有最重要的一点是,Redis对整数 0-9999(共1W个整数)做了缓存。类似于Java对-128-127做缓存一样。
但是没有对值的字符串,如aaaaa的这种缓存,毕竟判断一个字符串是否在库里面,需要扫整个库,非常耗时,并且cpu压力非常的大。
处于优化,折中的考虑,也就缓存了0-9999吧。其实看看淘宝商品的价格,缓存0-100足矣,毕竟0-100占据了99%的商品。
具体可看:http://redisbook.com/preview/object/share_object.html
后言
- Redis 数据库中的每个键值对的键和值都是一个对象。
- Redis 共有字符串、列表、哈希、集合、有序集合五种类型的对象, 每种类型的对象至少都有两种或以上的编码方式, 不同的编码可以在不同的使用场景上优化对象的使用效率。
- 服务器在执行某些命令之前, 会先检查给定键的类型能否执行指定的命令, 而检查一个键的类型就是检查键的值对象的类型。
- Redis 的对象系统带有引用计数实现的内存回收机制, 当一个对象不再被使用时, 该对象所占用的内存就会被自动释放。
- Redis 会共享值为 0 到 9999 的整数对象。
- 对象会记录自己的最后一次被访问的时间, 这个时间可以用于计算对象的空转时间。
参考:


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步