
phoenix 索引实践
准备工作
创建测试表
CREATE TABLE my_table ( rowkey VARCHAR NOT NULL PRIMARY KEY, v1 VARCHAR, v2 VARCHAR, v3 VARCHAR ); UPSERT INTO my_table values('1','value1','value2','value3'); UPSERT INTO my_table values('2','value1','value2','value3'); UPSERT INTO my_table values('3','value1','value2','value3'); UPSERT INTO my_table values('4','value1','value2','value3'); UPSERT INTO my_table values('5','value1','value2','value3');
开启索引支持
HBase --> 配置 --> 高级 --> 搜索 hbase-site.xml。
在服务端添加下面配置:
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
在这里插入图片描述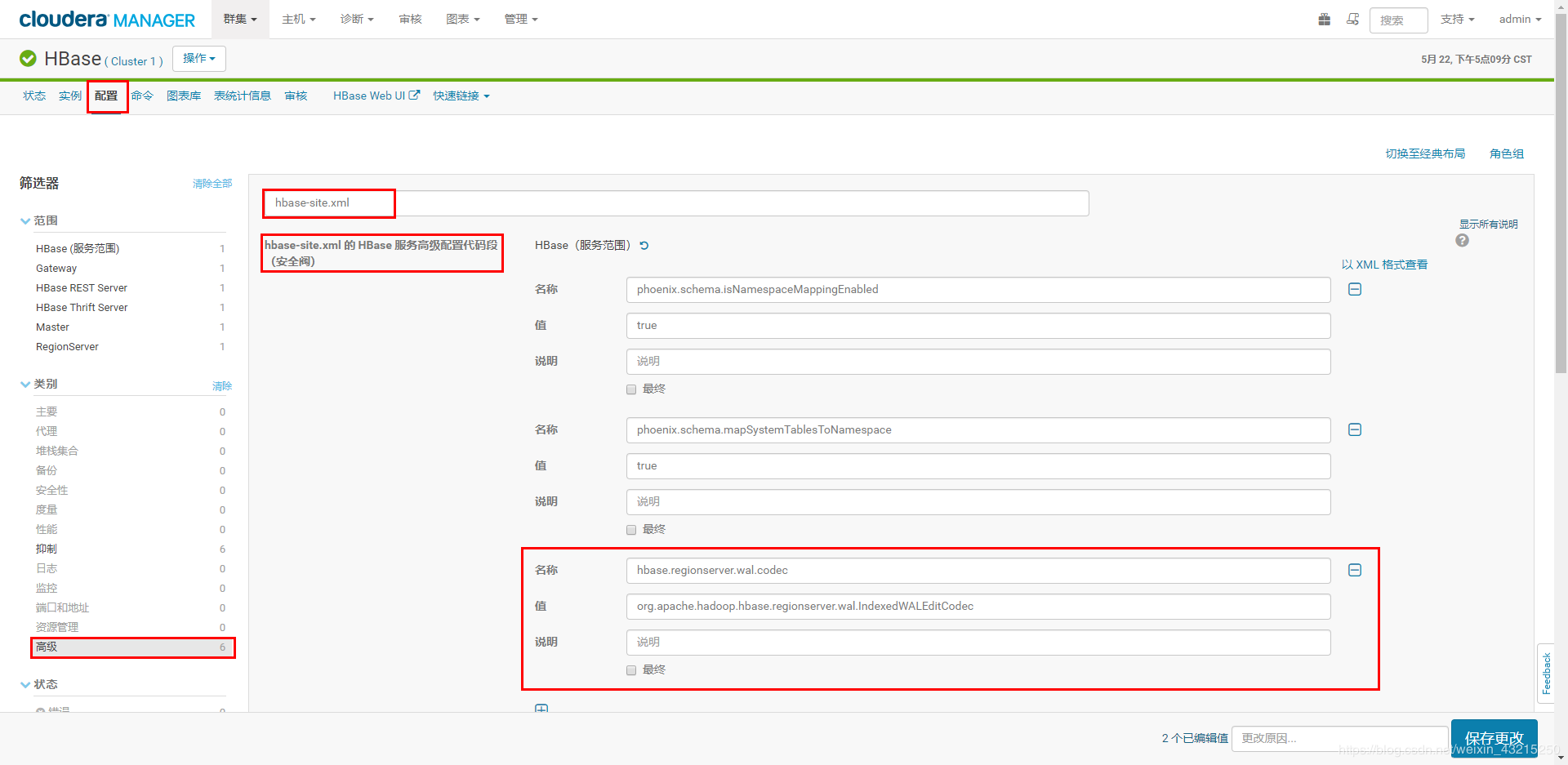
创建索引
全局索引
全局索引适合读多写少的场景。如果使用全局索引,读数据基本不损耗性能,所有的性能损耗都来源于写数据。数据表的添加、删除和修改都会更新相关的索引表(数据删除了,索引表中的数据也会删除;数据增加了,索引表的数据也会增加)。
注意:
对于全局索引在默认情况下,在查询语句中检索的列如果不在索引表中,Phoenix不会使用索引表将,除非使用hint。
创建全局索引
CREATE INDEX my_index ON my_table ( v3 );
查看效果
0: jdbc:phoenix:> select v3 from my_table where v3 = '13000010030'; +--------------+ | V3 | +--------------+ | 13000010030 | +--------------+ 1 row selected (2.155 seconds) 0: jdbc:phoenix:> select * from my_table where v3 = '13000010030'; +-------------------+------+--------+--------------+ | ROWKEY | V1 | V2 | V3 | +-------------------+------+--------+--------------+ | 77a9ede22e169683 | aaa| bbb| 13000010030 | +-------------------+------+--------+--------------+ 1 row selected (2.337 seconds) 0: jdbc:phoenix:> CREATE INDEX my_index ON my_table ( v3 ); 1,076,190 rows affected (33.875 seconds) 0: jdbc:phoenix:> select * from my_table where v3 = '13000010030'; +-------------------+------+--------+--------------+ | ROWKEY | V1 | V2 | V3 | +-------------------+------+--------+--------------+ | 77a9ede22e169683 | aaa| bbb| 13000010030 | +-------------------+------+--------+--------------+ 1 row selected (3.296 seconds) 0: jdbc:phoenix:> select v3 from my_table where v3 = '13000010030'; +--------------+ | V3 | +--------------+ | 13000010030 | +--------------+ 1 row selected (0.02 seconds)
本地索引
本地索引适合写多读少的场景,或者存储空间有限的场景。和全局索引一样,Phoenix也会在查询的时候自动选择是否使用本地索引。本地索引因为索引数据和原数据存储在同一台机器上,避免网络数据传输的开销,所以更适合写多的场景。由于无法提前确定数据在哪个Region上,所以在读数据的时候,需要检查每个Region上的数据从而带来一些性能损耗。
注意:
对于本地索引,查询中无论是否指定hint或者是查询的列是否都在索引表中,都会使用索引表。
创建本地索引
CREATE LOCAL INDEX LOCAL_IDEX ON my_table(v3);
查看效果
0: jdbc:phoenix:> select * from my_table where v3 = '13000010030'; +-------------------+------+--------+--------------+ | ROWKEY | V1 | V2 | V3 | +-------------------+------+--------+--------------+ | 77a9ede22e169683 | aaa| bbb| 13000010030 | +-------------------+------+--------+--------------+ 1 row selected (3.545 seconds) 0: jdbc:phoenix:> select v3 from my_table where v3 = '13000010030'; +--------------+ | V3 | +--------------+ | 13000010030 | +--------------+ 1 row selected (2.946 seconds) 0: jdbc:phoenix:> CREATE LOCAL INDEX LOCAL_IDEX ON my_table(v3); 1,076,190 rows affected (24.67 seconds) 0: jdbc:phoenix:> select * from my_table where v3 = '13000010030'; +-------------------+------+--------+--------------+ | ROWKEY | V1 | V2 | V3 | +-------------------+------+--------+--------------+ | 77a9ede22e169683 | aaa| bbb| 13000010030 | +-------------------+------+--------+--------------+ 1 row selected (0.055 seconds) 0: jdbc:phoenix:> select v3 from my_table where v3 = '13000010030'; +--------------+ | V3 | +--------------+ | 13000010030 | +--------------+ 1 row selected (0.013 seconds)
覆盖索引
覆盖索引是把原数据存储在索引数据表中,这样在查询时不需要再去HBase的原表获取数据就,直接返回查询结果。
注意:
查询是 select 的列和 where 的列都需要在索引中出现。
创建覆盖索引
CREATE INDEX my_index ON my_table ( v2,v3 ) INCLUDE ( v1 );
添加索引后提升到毫秒级
0: jdbc:phoenix:> select * from my_table where v3 = '13308117837' and v2 = '北京顺义'; +-------------------+-----+-------+--------------+ | ROWKEY | V1 | V2 | V3 | +-------------------+-----+-------+--------------+ | 3f65283ed7553909 | wenyuan | ccc| 13308117837 | +-------------------+-----+-------+--------------+ 1 row selected (2.42 seconds) 0: jdbc:phoenix:> CREATE INDEX my_index ON my_table (v2,v3) INCLUDE ( v1 ); 1,076,190 rows affected (47.432 seconds) 0: jdbc:phoenix:> select * from my_table where v3 = '13308117837' and v2 = '北京顺义'; +-------------------+-----+-------+--------------+ | ROWKEY | V1 | V2 | V3 | +-------------------+-----+-------+--------------+ | 3f65283ed7553909 | wenyuan| ccc| 13308117837 | +-------------------+-----+-------+--------------+ 1 row selected (0.031 seconds)
函数索引
从Phoenix4.3版本就有函数索引,特点是索引的内容不局限于列,能根据表达式创建索引。适用于对查询表时过滤条件是表达式。如果你使用的表达式正好就是索引的话,数据也可以直接从这个索引获取,而不需要从数据库获取。
创建索引
CREATE INDEX my_index ON my_table(substr(v3,1,9)) INCLUDE ( v1 );
查看效果
0: jdbc:phoenix:> select v1,substr(v3,1,9) from my_table where substr(v3,1,9) = '130000109'; +-----+-------------------+ | V1 | SUBSTR(V3, 1, 9) | +-----+-------------------+ | wenyuan| 130000109 | +-----+-------------------+ 1 row selected (3.656 seconds) 0: jdbc:phoenix:> select v1,v3 from my_table where substr(v3,1,9) = '130000109'; +-----+--------------+ | V1 | V3 | +-----+--------------+ | wenyuan| 13000010979 | +-----+--------------+ 1 row selected (3.969 seconds) 0: jdbc:phoenix:> CREATE INDEX my_index ON my_table(substr(v3,1,9)) INCLUDE ( v1 ); 1,076,190 rows affected (45.833 seconds) 0: jdbc:phoenix:> select v1,v3 from my_table where substr(v3,1,9) = '130000109'; +-----+--------------+ | V1 | V3 | +-----+--------------+ | wenyuan| 13000010979 | +-----+--------------+ 1 row selected (3.44 seconds) 0: jdbc:phoenix:> select v1,v3,substr(v3,1,9) from my_table where substr(v3,1,9) = '130000109'; +-----+--------------+-------------------+ | V1 | V3 | SUBSTR(V3, 1, 9) | +-----+--------------+-------------------+ | wenyuan| 13000010979 | 130000109 | +-----+--------------+-------------------+ 1 row selected (3.327 seconds) 0: jdbc:phoenix:> select v1,substr(v3,1,9) from my_table where substr(v3,1,9) = '130000109'; +-----+--------------------+ | V1 | " SUBSTR(V3,1,9)" | +-----+--------------------+ | wenyuan | 130000109 | +-----+--------------------+ 1 row selected (0.013 seconds) 0: jdbc:phoenix:> select v1 from my_table where substr(v3,1,9) = '130000109'; +-----+ | V1 | +-----+ | wenyuan| +-----+ 1 row selected (0.011 seconds)
索引Building
同步索引
CREATE INDEX ASYNC_IDX ON SCHEMA_NAME.TABLE_NAME(BASICINFO."s1",BASICINFO."s2") ;
创建同步索引超时怎么办?
在客户端配置文件hbase-site.xml中,把超时参数设置大一些,足够 Build 索引数据的时间。
<property> <name>hbase.rpc.timeout</name> <value>60000000</value> </property> <property> <name>hbase.client.scanner.timeout.period</name> <value>60000000</value> </property> <property> <name>phoenix.query.timeoutMs</name> <value>60000000</value> </property>
异步索引
异步Build索引需要借助MapReduce,创建异步索引语法和同步索引相差一个关键字:ASYNC。
创建异步索引
CREATE INDEX ASYNC_IDX ON SCHEMA_NAME.TABLE_NAME ( BASICINFO."s1", BASICINFO."s2" ) ASYNC;
运行MapReduce
执行MapReduce
hbase org.apache.phoenix.mapreduce.index.IndexTool \ --schema SCHEMA_NAME\ --data-table TABLE_NAME\ --index-table ASYNC_IDX \ --output-path ASYNC_IDX_HFILES
日志:
Java HotSpot(TM) 64-Bit Server VM warning: Using incremental CMS is deprecated and will likely be removed in a future release SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-5.12.1-1.cdh5.12.1.p0.3/jars/phoenix-4.14.0-cdh5.12.2-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-5.12.1-1.cdh5.12.1.p0.3/jars/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 19/05/22 15:38:41 INFO log.QueryLoggerDisruptor: Starting QueryLoggerDisruptor for with ringbufferSize=8192, waitStrategy=BlockingWaitStrategy, exceptionHandler=org.apache.phoenix.log.QueryLoggerDefaultExceptionHandler@dd0c991... 19/05/22 15:38:41 INFO query.ConnectionQueryServicesImpl: An instance of ConnectionQueryServices was created. ... 19/05/22 15:41:19 INFO index.IndexTool: Loading HFiles from INDEX_PERSONAS_TAG_HFILES/MY_SCHEMA.INDEX_PERSONAS_TAG 19/05/22 15:41:19 WARN mapreduce.LoadIncrementalHFiles: Skipping non-directory hdfs://bigdata-dev-41:8020/user/root/INDEX_PERSONAS_TAG_HFILES/MY_SCHEMA.INDEX_PERSONAS_TAG/_SUCCESS 19/05/22 15:41:19 INFO hfile.CacheConfig: CacheConfig:disabled 19/05/22 15:41:19 INFO mapreduce.LoadIncrementalHFiles: Trying to load hfile=hdfs://bigdata-dev-41:8020/user/root/INDEX_PERSONAS_TAG_HFILES/MY_SCHEMA.INDEX_PERSONAS_TAG/0/e1f766365b4f4c7cb6cfc6e0d18328b8 first=0\x0010\x00\xE4\xB8\x9A\xE4\xB8\xBB\x000\x000\x0010\x000\x00\xE6\xAD\xA3\xE5\xB8\xB8\xE4\xB8\x9A\xE4\xB8\xBB\x001001.99\x000\x001\x003\x00\xE8\x80\x81\xE5\xAE\xA2\xE6\x88\xB7\x00\xE6\x9C\xAA\xE7\x9F\xA5\x0042471415705946377 last=2\x009\x00\xE7\xA7\x9F\xE5\xAE\xA2\x002\x002\x009\x002\x00\xE9\x95\xBF\xE6\x9C\x9F\xE4\xB8\x8D\xE4\xBA\xA4\xE7\x89\xA9\xE4\xB8\x9A\xE7\xAE\xA1\xE7\x90\x86\xE8\xB4\xB9\x00988.56\x000\x001\x004\x00\xE6\x9C\xAA\xE7\x9F\xA5\x00\xE5\x9C\x9F\xE8\xB1\xAA\x0044ff3613003558171 19/05/22 15:41:20 INFO index.IndexToolUtil: Updated the status of the index INDEX_PERSONAS_TAG to ACTIVE
遇到问题
Error: Could not find or load main class org.apache.phoenix.mapreduce.index.IndexTool
解决办法
将 phoenix-4.14.0-cdh5.12.2-client.jar 包复制到 hbase 的 lib 目录下
[root@node00 ~]# cd /opt/cloudera/parcels/
[root@node00 parcels]# cd APACHE_PHOENIX/lib/phoenix
[root@node00 phoenix]# cp phoenix-4.14.0-cdh5.12.2-client.jar /opt/cloudera/parcels/CDH/jars/
[root@node00 phoenix]# cd /opt/cloudera/parcels/CDH/lib/hbase/lib/
[root@node00 lib]# ln -s ../../../jars/phoenix-4.14.0-cdh5.12.2-client.jar phoenix-4.14.0-cdh5.12.2-client.jar
索引用法总结
Phoenix 的二级索引主要有两种,即全局索引和本地索引。
全局索引适合读多写少的场景,如果使用全局索引,读数据基本不损耗性能,所有的性能损耗都来源于写数据。
本地索引适合写多读少的场景,或者存储空间有限的场景。
索引定义完之后,一般来说,Phoenix自己会判定使用哪个索引更加有效。
但是,全局索引必须是查询语句中所有列都包含在全局索引中,它才会生效。
索引为:
create index my_index on my_table (v3); select v1 from my_table where v3 = '13406157616';
上面语句怎样才能使用索引呢?
有以下三种方法使它使用索引:
使用覆盖索引
CREATE INDEX cover_index ON my_table(v3) INCLUDE (v1);
查看效果
0: jdbc:phoenix:> select v1 from my_table where v3 = '13406157616'; +------+ | V1 | +------+ | wenyuan| +------+ 1 row selected (0.01 seconds)
使用 Hint 强制索引
SELECT /*+ INDEX(my_table my_index) */ v1 FROM my_table WHERE v3 = '13406157616';
查看效果
0: jdbc:phoenix:> SELECT /*+ INDEX(my_table my_index) */ v1 FROM my_table WHERE v3 = '13406157616'; +------+ | V1 | +------+ | wenyuan| +------+ 1 row selected (0.044 seconds)
使用本地索引
CREATE LOCAL INDEX local_index on my_table (v3);
查看效果
0: jdbc:phoenix:> select v1 from my_table where v3 = '13406157616'; +------+ | V1 | +------+ | wenyuan| +------+ 1 row selected (0.025 seconds)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号