
hbase 面试问题汇总
一、Hbase的六大特点:
(1)、表大:一个表可以有数亿行,上百万列。
(2)、无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态增加,同一个表中的不同行的可以有截然不同的列。
(3)、面向列:HBase是面向列的的存储和权限控制,列族独立索引。
(4)、稀疏:空(null)列并不占用空间,表可以设计的非常稀疏。
(5)、数据类型单一:HBase中的数据都是字符串,没有类型。
(6)、数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳。
二、Hbase与Hive的对比:
(1)、整体对比:
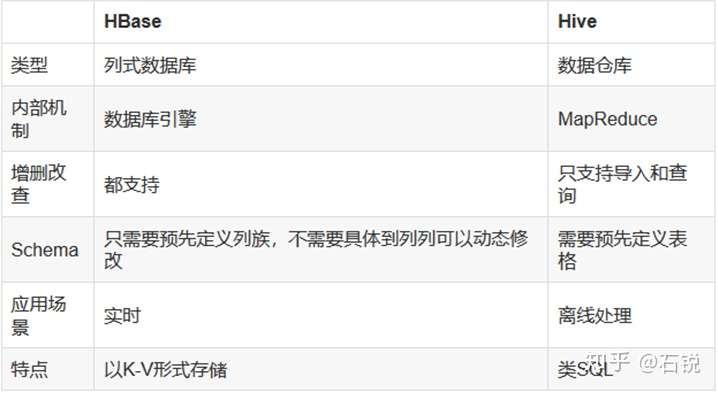
(2)、Hive是一种构建在Hadoop基础设施之上的数据仓库,通过Hive可以使用HQL语言查询存放在HDFS上面的数据。HBase能够在它的数据库上面实时运行,HBase被分区为表格,表格有进一步分割为列簇,列族必须需要用schema定义。一个列簇可以包含很多列,每个key/value在HBase中都被定义成一个cell,每一个cell都有一个rowkey,一个columnFamily,一个value值,一个timestamp。rowkey不能为空且唯一。
(3)、Hive把HQL解析成MR程序,因为它是兼容JDBC,所有可以和很多JDBC程序做集成,它只能做离线查询,不能做实时查询,默认查询Hive是查询所有的数据,这个可以通过分区来控制。HBase通过存储的key/value来工作的,它支持主要的四种操作,增删改查。
(4)、Hive目前不支持更新操作,花费时间长,必须要先设置schema将文件和表映射,Hive和ACID不兼容。HBase必须需要zk的支持,查询语句需要重新学,如果要使用sql查询,可以使用Apache Phonenix,但会以schema作为代价。
(5)、Hive适用于一段时间内的数据进行分析查询,HBase适用于大规模数据的实时查询。
三、Hbase的使用场景:
(1)、半结构化数据和非结构化数据,可以进行动态扩展。
(2)、记录非常的稀疏。
(3)、多版本数据。
(4)、超大数据容量:HBase会自动水平切分扩展,跟Hadoop的无缝集成保证了其数据的可靠性和海量数据分析的高性能。
四、Hbase的rowkey设计原则:
(1)、rowkey长度原则:rowkey是一个二进制流,长度开发者建议是10-100字节,不过建议越短越好,最好不超过16字节。原因是:数据持久化文件HFile中是按照按照key/value存储的,如果rowkey太长的话就会影响HFile的存储效率。Memstore将缓存数据到内存,如果rowkey字段过长内存的有效利用会降低,系统将会无法缓存更多的数据,降低检索的效率。
(2)、rowkey散列原则:如果rowkey是按照时间戳方式递增的话,不要将时间放在二进制码的前面,建议将rowkey的高位作为散列字段,如果没有散列字段就会出现一个regionServer上堆积的热点现象。
(3)、rowkey的唯一原则:rowkey不能为空且唯一。
五、Hbase的查询方式:
1、全表查询:scan tableName
2、基于rowkey的单行查询:get tableName,'1'
3、基于rowkey的范围扫描:scan tableName, {STARTROW=>'1',STOPROW=>'2'}
4、get和scan方法:
(1)、按指定的rowkey获取唯一一条数据,get方法:分为两种,分别是设置了closestRowBefore和没有设置的rowlock,只要保证行的事务性,即每一个get是以一个row来标记的,一个row中可以有多个family和column。
(2)、按指定的条件获取一批记录,条件查询。1、scan可以通过setCaching和setBatch方法来提高速度;2、scan也可以通过setStartRow和setEndRow来限定范围(左闭右开),3、scan还可以通过setFileter方法来添加过滤器。
ps:setCache和setBatch方法:
setCache方法:这个方法设置即一次RPC请求放回的行数,对于缓存操作来说,如果返回行数太多了,就可能内存溢出,那么这个时候就需要setBatch方法,。
setBatch:设置这个之后客户端可以选择取回的列数,如果一行包括的列数超过了设置的值,那么就可以将这个列分片。例如:如果一行17列,如果batch设置为5的话,就会返回四组,分别是5,5,5,2。、
※:Cache设置了服务器一次返回的行数,而Batch设置了服务器一次返回的列数。
ps:Batch参数决定了一行数据分为几个result,它只针对一行数据,Cache决定了一次RPC返回的result个数。
RPC请求次数 = (行数 * 每行列数) / Min(每行的列数,批量大小) / 扫描器缓存
六、Hbase的cell结构:
1、什么是Hbase中的cell:Hbase中通过row和columns确定一个存贮单元成为cell,cell由{{rowkey, column(=<family> + <label>,version)}构成。
2、Hbase中表示行的集合,行是列族的集合,列族是列的集合,列是键值对的集合,如图:

七、Hbase的读写流程:
1、HBase的读流程:
(1)、HRegisonServer保存着.meta.表及数据表,首先client先访问zk,访问-ROOT-表,然后在zk上面获取.meta.表所在的位置信息,找到这个meta表在哪个HRegionServer上面保存着。
(2)、接着client访问HRegionServer表从而读取.meta.进而获取.meta.表中存放的元数据。
(3)、client通过.meta.中的元数据信息,访问对应的HRegionServer,然后扫描HRegionServer的Memstore和StoreFile来查询数据。
(4)、最后把HRegionServer把数据反馈给client。
2、HBase的写流程:
(1)、client访问zk中的-ROOT-表,然后后在访问.meta.表,并获取.meta.中的元数据。
(2)、确定当前要写入的HRegion和HRegionServer。
(3)、clinet向HRegionServer发出写相应的请求,HRegionServer收到请求并响应。
(4)、client先将数据写入到HLog中,以防数据丢失。
(5)、然后将数据写入到MemStore中。
(6)、如果HLog和MemStore都写入成功了,那么表示这个条数据写入成功了。
(7)、如果MemStore写入的数据达到了阈值,那么将会flush到StoreFile中。
(8)、当StoreFile越来越多,会触发Compact合并操作,将过多的StoteFile合并成一个大的StoreFile。
(9)、当StoreFile越来越多时,Region也会越来越大,当达到阈值时,会触发spilit操作,将这个Region一分为二。
ps:HBase中所有的更新和删除操作都会在后续的compact中进行,使得用户的写操作只需要进入内存中就行了。实现了HBase的 I/O高性能。
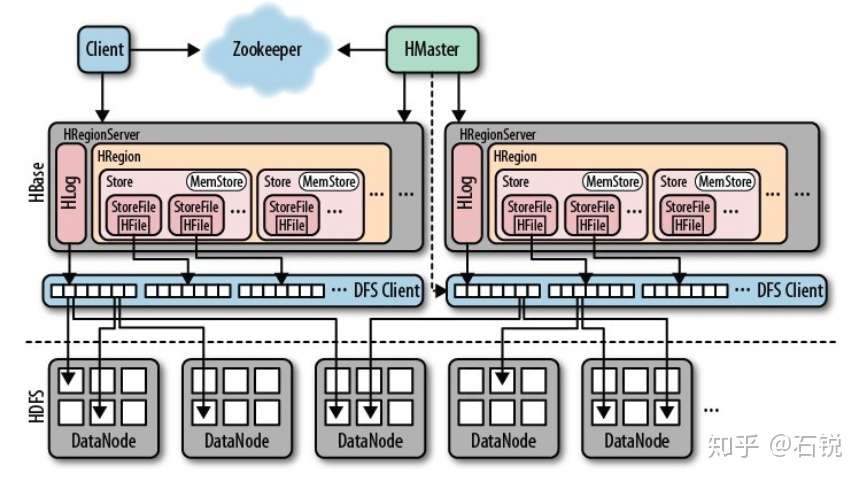
八、Hbase的结构:
1、HMaster:
(1)、为所有的RegionServer分配Region。
(2)、负责RegionServer的负载均衡。
(3)、发现失效的RegionServer并重新分配其上的Region。
(4)、HDFS上的垃圾文件。
(5)、处理Schema更新请求(表的创建,删除,修改,列族的增加等)。
2、HRegionServer:
(1)HRegion:
(1)、简介:Table在行的方向上分隔为多个Region,Region是HBase中分布式存储和负载均衡的最小单元,即不同的Region可以分在不同的RegionServer上面,但同一个Region是不会拆分到多个Server上面的。随着数据的增多,某个列族的达到一个阈值就会分成两个新的Region。结构:<表名,startRowkey,创建时间>,由目录表(-ROOT-,.META.)记录该Region的endRowkey
(2)、Store:
(1)简介:每一个Region由一个或则多个Store组成,至少是一个Store,HBase会把访问的数据存放在Store中,即每一个列族建一个Store,如果有多个ColumnFamily,就多多个Store,一个Store由一个MemStore和0或则多个StoreFile组成。HBase通过Store的大小判断是否需要切分Region。
(2)MemStore:它是放在内存中的,保存修改的数据,即key/values。当MemStore的大小达到一定的阈值的时候(默认128M),MemStore会被Flush到文件,即生成一个快照StoreFile,Flush过程由一个线程完成。
(3)StoreFile:StoreFile底层是HFile,HFile是Hadoop的二进制格式文件,
(2)HLog:WAL文件,用来灾难恢复使用,HLog记录数据的所有变更,一旦RegionServer宕机,就从HLog中进行恢复,HLog文件就是一个普通的Hadoop Sequence File,Sequence File记录了写入数据的归属信息,除了Table和Region名字外,还同时包括了Sequence Number和TimeStamp,Sequence File的value是HBase的key/value对象,即对应的HFile中的key/value。
3、Zookeeper:
(1)、保证任何时候集群中只有一个活跃的Master。
(2)、存储所有的Region的寻址入口,知道哪个Region在哪台机器上。
(3)、实时监控RegionServer的状态,将RegionServer的上下线的信息汇报给HMaster,RegionServer不直接向HMaster汇报信息,减轻HMaster的压力,而是通过向ZK发送信息。
(4)、存储HBase的元数据结构(schema),知道集群中有哪些Table,每个Table有哪些Column Family。
4、结构图:
九、Hbase中的Compact机制:
1、当HBase中的memstore数据flush到磁盘的时候,就会形成一个storefile,当storefile的数量达到一定程度的时候,就需要将storefile文件进行compaction操作,Compact作用:合并文件、清楚过期,多余版本数据、提高读写效率。
2、compact操作的实现:①minor:Minor 操作只用来做部分文件的合并操作以及包括 minVersion=0 并且设置 ttl 的过期版本清理,不做任何删除数据、多版本数据的清理工作。②major:Major 操作是对 Region 下的HStore下的所有StoreFile执行合并操作,最终的结果是整理合并出一个文件。
十、Hbase中的数据模型:
1、逻辑视图:转载:
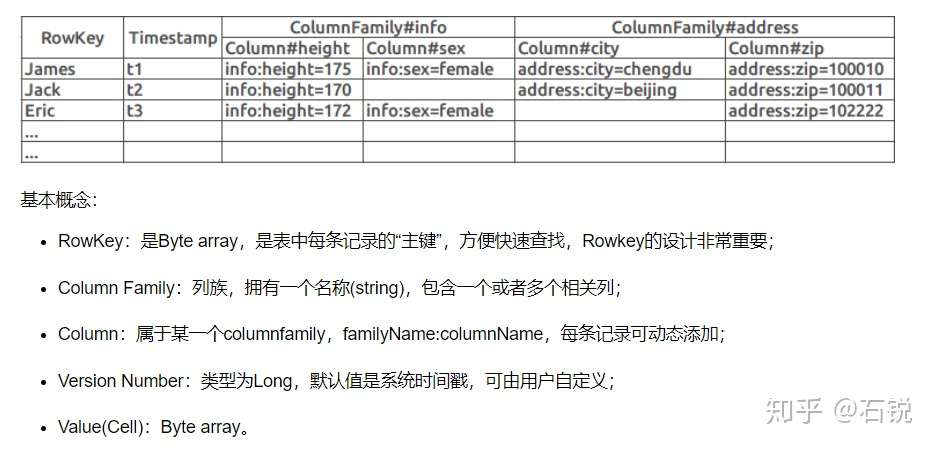
2、物理视图:(1)、每个columnFamily存储在HDFS上的一个单独文件,空值不会被保留。(2)、key和versionNumber在每个columnFamily中单独一份。(3)、HBase每个值维护多级索引,即<key,columnFamily,columnName,timeStamp>。(4)、表在行的方向上分割为多个Region。(5)、Region是HBase分布式存储和负载均衡的最小单元,不同Region分布在不同的RegionServer中。(6)、Region虽然是分布式存储的最小单元,但并不是最小存储单元,一个Region中包含多个Store对象,每个Store包含一个MemStore和若干个StoreFile,StoreFile包含一个或多个HFile。MemStore存放在内存中,StoreFile存储在HDFS上面。
3、HBase中的-ROOT-表和.META.表:HBase中的Region元数据都存储在.META.表中,随着Region的增加,.META.表也会越来越多。为了定位.META.表中各个Region的位置,把.META.表中所有Region的元数据保存在-ROOT-表中,最后由Zookeeper记录-ROOT-表的位置信息。所有客户端访问用户数据前,需要首先访问Zookeeper获得-ROOT-的位置,然后访问-ROOT-表获得.META.表的位置,最后根据.META.表中的信息确定用户数据存放的位置。-ROOT-表是不会分割的,它只有一个Region。为了加快访问速度,.META.表的所有Region全部保存在内存中。客户端会将查询过的位置信息缓存起来,且缓存不会主动失效。如果客户端根据缓存信息还访问不到数据,则询问相关.META.表的Region服务器,试图获取数据的位置,如果还是失败,则询问-ROOT-表相关的.META.表在哪里。
十一、Hbase中的优化:
1、读写性能优化:
(1)、开启bloomfilter过滤器。
(2)、在条件允许的情况下,给HBase足够的内存。修改配置文件hbase-env.sh中的export HBASE_HEAPSIZE=1000
(3)、增加RPC的数量。通过修改hbase-site.xml中的hbase.regionserver.handler.count属性可以适当的放大RPC数量,默认是10。
(4)、HBase中的region太小会造成多次spilit,region就会下线。如果HBase中的region过大,就会发生多次的compaction,将数据读一遍重写一遍到HDFS上面,占用io。
2、预设分区:
(1)、shell方法:例如:create 'tb_split',{NAME=>'cf', VERSION=>3},{SPLITS=>['10','20','30']}
(2)、java程序控制:https://blog.csdn.net/javajxz008/article/details/51913471
3、其他优化方法:
(1)、减少调整:可以调整region和HFile。因为region的分裂会导致I/O开销,如果没有预设分区的话,随着region中条数的增,region会进行分裂,解决方法就是根据rowkey设计来进行预建分区,减少region的动态分裂。HFile会随着memstore进行刷新时生成一个HFile,当HFile增加到一定量的时候,会将属于一个region的HFile合并,HFile是不可避免的,但是如果HFile大于设置得值,就会导致HFile分裂,这样就会导致I/O的开销增大。
(2)、减少启停:对于HBase会有compact机制,会合并HFile,但是我们可以手动关闭compact,减少I/O。如果是批量数据的写入,我们可以用BulkLoad来批量插入数据。(BulkLoad的使用:https://blog.csdn.net/shixiaoguo90/article/details/78038462)
(3)、减少数据量:开启过滤,提高查询效率。(开启BloomFilter,这个是列簇级别的过滤,在生成一个StoreFile同时会生成一个MetaBlock,用于查询时的过滤)。使用压缩,一般使用snappy和lzo压缩。
(4)、合理设计:rowkey的设计:(散列性、简短性、唯一性、业务性),列族的设计:(多列族的优势是:在进行查表的时候,只需要扫描那一列就行了,就不需要全盘扫描,减少I/O,劣势是:降低了写的I/O,原因是:数据写到stroe以后会缓存到memstore中,)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号