
Spark DataFrame简介(一)
1. DataFrame
本片将介绍Spark RDD的限制以及DataFrame(DF)如何克服这些限制,从如何创建DataFrame,到DF的各种特性,以及如何优化执行计划。最后还会介绍DF有哪些限制。

2. 什么是 Spark SQL DataFrame?
从Spark1.3.0版本开始,DF开始被定义为指定到列的数据集(Dataset)。DFS类似于关系型数据库中的表或者像R/Python 中的data frame 。可以说是一个具有良好优化技术的关系表。DataFrame背后的思想是允许处理大量结构化数据。DataFrame包含带schema的行。schema是数据结构的说明。
在Apache Spark 里面DF 优于RDD,但也包含了RDD的特性。RDD和DataFrame的共同特征是不可性、内存运行、弹性、分布式计算能力。它允许用户将结构强加到分布式数据集合上。因此提供了更高层次的抽象。我们可以从不同的数据源构建DataFrame。例如结构化数据文件、Hive中的表、外部数据库或现有的RDDs。DataFrame的应用程序编程接口(api)可以在各种语言中使用。示例包括Scala、Java、Python和R。在Scala和Java中,我们都将DataFrame表示为行数据集。在Scala API中,DataFrames是Dataset[Row]的类型别名。在Java API中,用户使用数据集<Row>来表示数据流。
3. 为什么要用 DataFrame?
DataFrame优于RDD,因为它提供了内存管理和优化的执行计划。总结为一下两点:
a.自定义内存管理:当数据以二进制格式存储在堆外内存时,会节省大量内存。除此之外,没有垃圾回收(GC)开销。还避免了昂贵的Java序列化。因为数据是以二进制格式存储的,并且内存的schema是已知的。
b.优化执行计划:这也称为查询优化器。可以为查询的执行创建一个优化的执行计划。优化执行计划完成后最终将在RDD上运行执行。
4. Apache Spark DataFrame 特性
Spark RDD 的限制-
- 没有任何内置的优化引擎
- 不能处理结构化数据.
因此为了克服这些问题,DF的特性如下:
i. DataFrame是一个按指定列组织的分布式数据集合。它相当于RDBMS中的表.
ii. 可以处理结构化和非结构化数据格式。例如Avro、CSV、弹性搜索和Cassandra。它还处理存储系统HDFS、HIVE表、MySQL等。
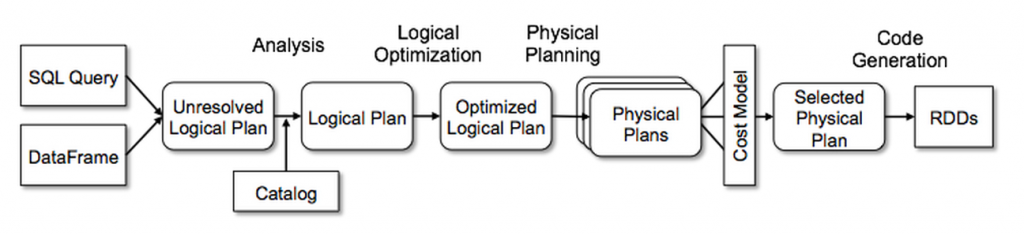
iii. Catalyst的通用树转换框架分为四个阶段,如下所示:(1)分析解决引用的逻辑计划,(2)逻辑计划优化,(3)物理计划,(4)代码生成用于编译部分查询生成Java字节码。 在物理规划阶段,Catalyst可能会生成多个计划并根据成本进行比较。 所有其他阶段完全是基于规则的。 每个阶段使用不同类型的树节点; Catalyst包括用于表达式、数据类型以及逻辑和物理运算符的节点库。 这些阶段如下所示:
5. 创建DataFrames
对于所有的Spark功能,SparkSession类都是入口。所以创建基础的SparkSession只需要使用:
SparkSession.builder()
使用Spark Session 时,应用程序能够从现存的RDD里面或者hive table 或者 Spark 数据源 里面创建DataFrame。Spark SQL能对多种数据源使用DataFrame接口。使用SparkSQL DataFrame 可以创建临时视图,然后我们可以在视图上运行sql查询。
6. Spark中DataFrame的缺点
- Spark SQL DataFrame API 不支持编译时类型安全,因此,如果结构未知,则不能操作数据
- 一旦将域对象转换为Data frame ,则域对象不能重构。
7. 总结
综上,DataFrame API能够提高spark的性能和扩展性。避免了构造每行在dataset中的对象,造成GC的代价。不同于RDD API,能构建关系型查询计划。更加有有利于熟悉执行计划的开发人员,同理不一定适用于所有人。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号