
Kimball与Inmon对比
一、数据仓库的相关概念
1.什么是数据仓库
数据仓库一种面向分析的环境,是一种把相关的各种数据转换成有商业价值的信息的技术。
数据仓库理论的创始人W.H.Inmon在其《Building the Data Warehouse》一书中,给出了数据仓库的四个基本特征:面向主题,数据是集成的,数据是不可更新的,数据是随时间不断变化的。
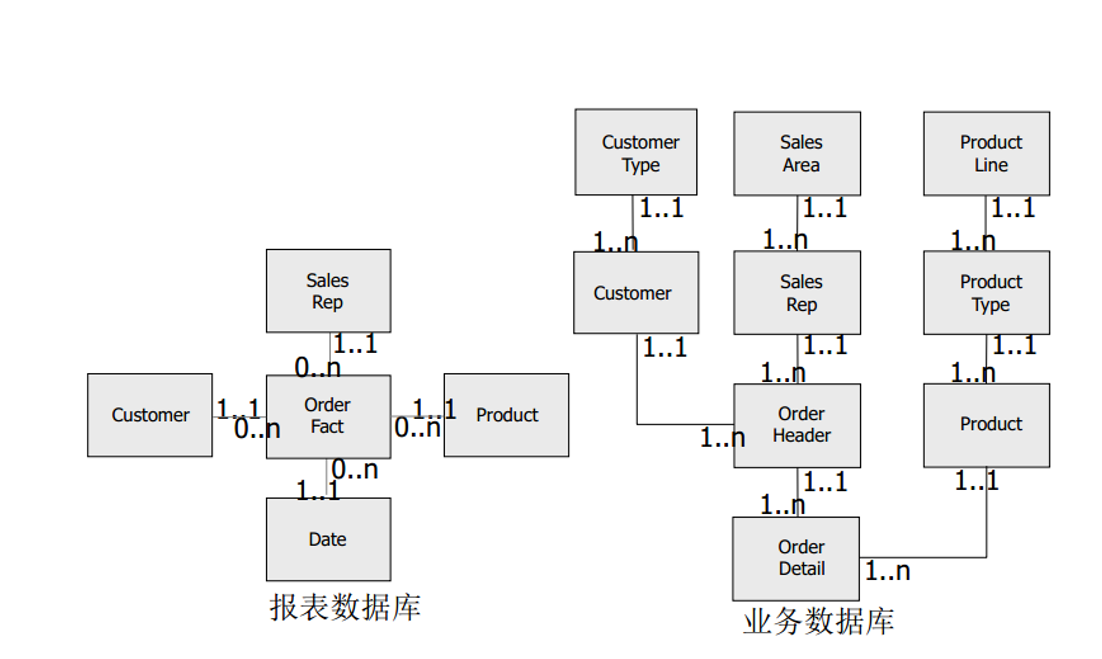 报表数据库与业务数据库的区别
报表数据库与业务数据库的区别
业务数据库的特点:
- 用于减少冗余和提高精度 。
- 适合于数据的写入和更新而不是数据的读取。
- 数据被细分为很多表(为了消除冗余),大的查询执行起来比较慢。
分析型数据库的特点:
- 报表型数据源通常使用星型结构布局。所有事务型数据,大部分数值型数据存储在事实表中,所有的参考数据,例如产品信息等,存储在独立的维度表中。
- 星型结构数据库比完全标准化数据库含有的表少,查询性能更快。
2.维度
维度是一个与业务相关的观察角度,依赖于数据的有效性和表达业务成效的关键性能指标。
能够回答类似下列问题:

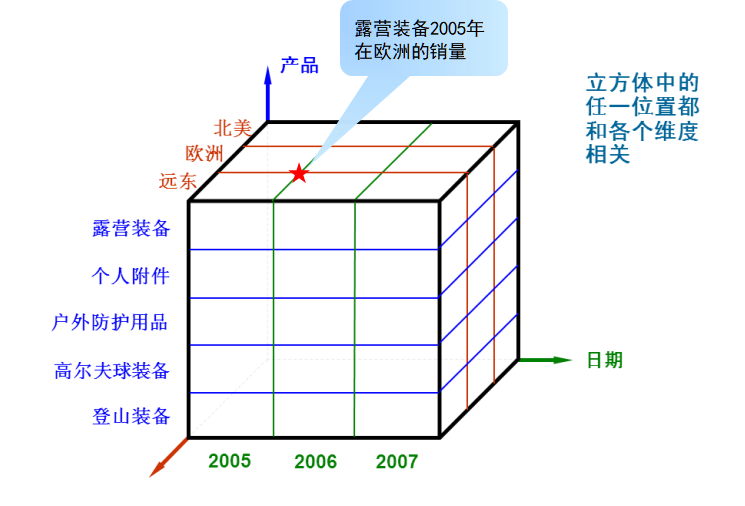
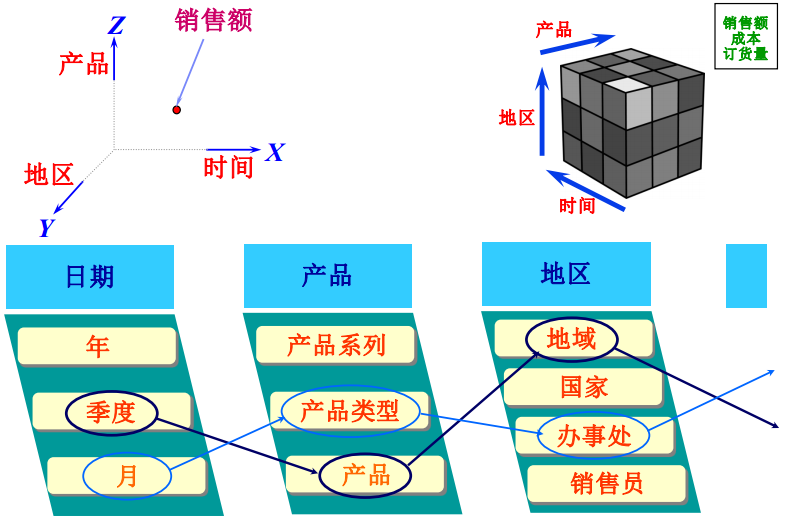
可将业务的每个方面构造成一个维度,如时间维度由年、季度、月构成。所有维度在一起提供了业务的多维视图。这个多维视图的数据被存为一个立方体。
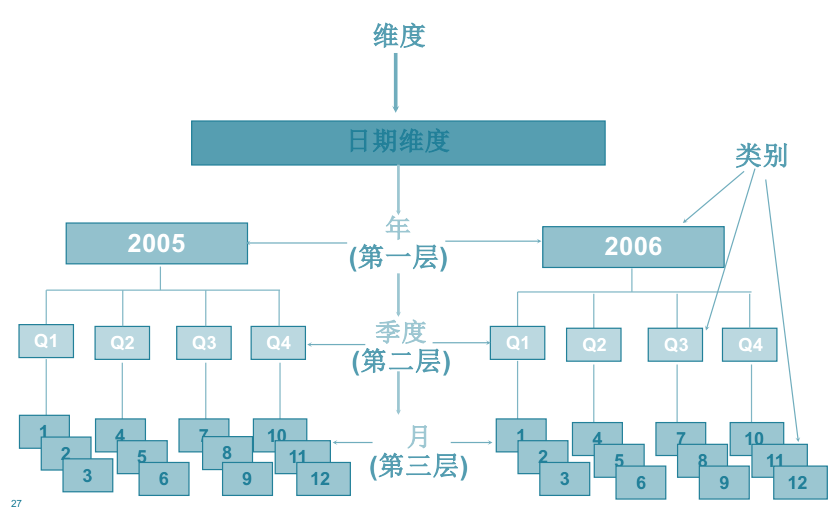
一个维度下设有若干层。如地区维度下有地域、国家、办事处、销售员4层。
3.度量
- 度量也叫事实,是用于评价业务状况的数值型数据。如销售额、成本、利润、库存量、交易数。
- 在企业活动中通常是通过如销售额、费用、库存量和定额一类的关键性能指标,度量来监测业务的成效。
- 不同的度量反映出不同的业务性质。度量之间相互独立。
- 度量是业务量化的表示。
4.多维立方体
5.多维分析
6.维度、层和类别
二、数据仓库的体系结构
业界存在Kimball与Inmon各自倡导的两种体系结构。
1、Inmon的企业信息化工厂

左边是操作型系统或者事务系统,有数据库在线系统,有文本文件系统等。这些系统的数据经过ETL的过程,加载数据到企业数据仓库中,ETL的过程是整合不同系统的数据,经过整合,清洗和统一,因此我们可以称之为数据集成。
企业数据仓库是企业信息化工厂的枢纽,是原子数据的集成仓库,但是由于企业数据仓库不是多维格式,因此不适合分析型应用程序,BI工具直接查询。他的目的是将附加的数据存储用于各种分析型系统。
数据集市,是针对不同的主题区域,从企业数据仓库中获取的信息,转换成多维格式,然后通过不同手段的聚集、计算,最后提供最终用户分析使用,因此Inmon把信息从企业数据仓库移动到数据集市的过程描述为“数据交付”。
2.Kimball的维度数据仓库
kimball的维度数据仓库是基于维度模型建立的企业级数据仓库,它的架构有的时候可以称之为“总线体系结构”,和inmon提出的企业信息化工厂有很多相似之处,都是考虑原子数据的集成仓库。
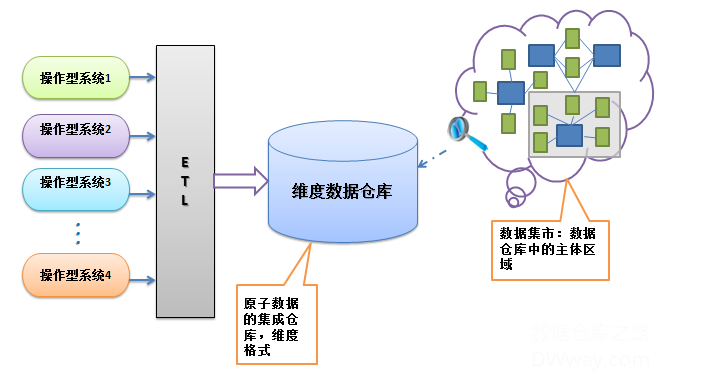
这两种结构的相似之处:一、都是假设操作型系统和分析型系统是分离的;二、数据源(操作型系统)都是众多;三、ETL整合了多种操作型系统的信息,集中到一个企业数据仓库。
最大的不同就是企业数据仓库的模式不同:inmon是采用第三范式的格式,kimball采用了多维模型–星型模型,并且还是最低粒度的数据存储。其次,维度数据仓库可以被分析系统直接访问(这种访问方式毕竟在分析过程中很少使用)。最后就是数据集市的概念有逻辑上的区别,在kimball的架构中,数据集市用维度数据仓库的高亮显示的表的子集来表示。
在kimball的架构中,有一个可变通的设计,就是在ETL的过程中加入ODS层,使得ODS层中能保留第三范式的一组表来作为ETL过程的过度。但是这个思想,Kimball看来只是ETL的过程辅助而已。另外,还可以把数据集市和企业维度数据仓库分离开来,这样多一层所谓的展现层(presentationlayer),这些变通的设计都是可以接受的,只要符合企业本身分析的需求。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号