rk音频驱动分析之ring buf
1.dma buffer简介
播放时,应用程序把音频数据源源不断地写入dma buffer中,然后相应platform的dma操作则不停地从该buffer中取出数据,经dai送往codec中。录音时则正好相反,codec源源不断地把A/D转换好的音频数据经过dai送入dma buffer中,而应用程序则不断地从该buffer中读走音频数据。

图6.2.1 环形缓冲区
ALSA buffer是采用ring buffer来实现的。ring buffer有多个HW buffer组成,也是上层的说的一个period。
HW buffer一般是在alsa driver的hw_params函数中分配的一块大小为buffer size的DMA buffer,这个buffer size一般由应用程序指定.之所以采用多个HW buffer来组成ring buffer,是防止读写指针的前后位置频繁的互换(即写指针到达HW buffer边界时,就要回到HW buffer起始点)。ring buffer = n * HW buffer.通常这个n比较大,也是由应用指定,在数据读写的过程中,很少会出现读写指针互换的情况。
2.dma buffer管理
alsa driver也使用了该方法对dma buffer进行管理:
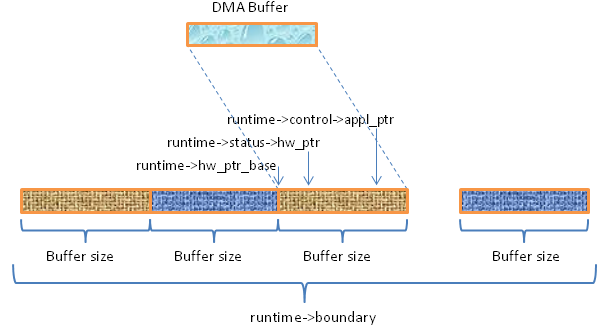
Buffer size:就是一个HW buffer,也是一个period,DMA每次搬运的基本单位(有时候可能搬运比这个size小),也是一个frames
snd_pcm_runtime结构中,使用了四个相关的字段来完成这个逻辑缓冲区的管理:
- snd_pcm_runtime.hw_ptr_base: 环形缓冲区每一圈的基地址,当读写指针越过一圈后,它按buffer size进行移动;
- snd_pcm_runtime.status->hw_ptr: 硬件逻辑位置,播放时相当于读指针,录音时相当于写指针;
- snd_pcm_runtime.control->appl_ptr: 应用逻辑位置,播放时相当于写指针,录音时相当于读指针;
- snd_pcm_runtime.boundary: 扩展后的逻辑缓冲区大小,通常是(2^n)*size, runtime->boundary一般都是较大的数,ALSA中默认接近
LONG_MAX/2.这样FIFO的出队入队指针不是真实的缓冲区的地址偏移,经过转换才得到 物理缓冲的偏移。这样做的好处是简化了缓冲区的管理,只有在更新hw指针的时候才需 要换算到hw_ofs.;
通过这几个字段,我们可以很容易地获得缓冲区的有效数据,剩余空间等信息,也可以很容易地把当前逻辑位置映射回真实的dma buffer中。
例如,获得播放缓冲区的空闲空间:
snd_pcm_sframes_t avail = runtime->status->hw_ptr + runtime->buffer_size - runtime->control->appl_ptr;
这里runtime->status->hw_ptr是读指针(DMA读取buf数据,通过dai,写入到codec),runtime->buffer_size是ring buffer大小,runtime->control->appl_ptr这个是写指针
(应用写到ring buffer里面),这样就可以得到应用可以写入的空间。
例如,获得录音缓冲区的可读的空间:
snd_pcm_sframes_t avail = runtime->status->hw_ptr - runtime->control->appl_ptr;
这里runtime->status->hw_ptr是写指针(DMA通过dai,读取数据到ring buf),runtime->control->appl_ptr这个是读指针
(应用读取ring buffer数据的指针),这样就可以得到应用可以读取的空间。
所以要想通过snd_pcm_playback_avail等函数获得正确的信息前,应该先要调用这个api更新指针位置。
以播放(playback)为例,我现在知道至少有3个途径可以完成对dma buffer的写入:
- 应用程序调用alsa-lib的snd_pcm_writei、snd_pcm_writen函数;
- 应用程序使用ioctl:SNDRV_PCM_IOCTL_WRITEI_FRAMES或SNDRV_PCM_IOCTL_WRITEN_FRAMES;
- 应用程序使用alsa-lib的snd_pcm_mmap_begin/snd_pcm_mmap_commit;
以上几种方式最终把数据写入dma buffer中,然后修改runtime->control->appl_ptr的值。
播放过程中,通常会配置成每一个period size生成一个dma中断,中断处理函数最重要的任务就是:
- 更新dma的硬件的当前位置,该数值通常保存在runtime->private_data中;
- 调用snd_pcm_period_elapsed函数,该函数会进一步调用snd_pcm_update_hw_ptr0函数更新上述所说的4个缓冲区管理字段,然后唤醒相应的等待进程。
录音snd_pcm_lib_read1调试打印:
<4>[ 705.967313] cxw frames=1024, appl_ptr=138240, appl_ofs = 7168, cont=9216
<4>[ 705.967341] cxw buffer_size=16384, runtime->boundary=1073741824, avail = 1024
<4>[ 705.988310] cxw frames=1024, appl_ptr=139264, appl_ofs = 8192, cont=8192
<4>[ 705.988337] cxw buffer_size=16384, runtime->boundary=1073741824, avail = 1024
可以看出:
1.frames就是一个period,buffer_size是ring buf大小,这里有16个period:1024*16 = 16384;
2.appl_ptr是读的指针,这个指针会一值增加,直到 runtime->boundary的界限
3.appl_ofs 是相对于buffer_size的偏移
4.cont = buffer_size - appl_ofs
5.avail 是可读的大小
3.DMA完成一个period后的中断处理函数
我们这里调用kernel/sound/soc/soc-dmaengine-pcm.c中的dmaengine_pcm_dma_complete
struct dmaengine_pcm_runtime_data *prtd = substream_to_prtd(substream);
prtd->pos += snd_pcm_lib_period_bytes(substream); //得到偏移地址,也就是加上刚才的period_size
if (prtd->pos >= snd_pcm_lib_buffer_bytes(substream)) //如果已经比ring buf大,说明已经饶了一圈了
prtd->pos = 0; //回到起点
snd_pcm_period_elapsed(substream); // update the pcm status for the next period
snd_pcm_update_hw_ptr0(substream, 1) //更新缓冲区管理字段,单独分析
4.更新缓冲区管理字段
//它是将hw_ofs转换成FIFO中hw_ptr的过程,同时处理环形缓冲区的回绕,没有中断,中断丢失等情况。
static int snd_pcm_update_hw_ptr0(struct snd_pcm_substream *substream, unsigned int in_interrupt)
old_hw_ptr = runtime->status->hw_ptr; //保存上一次的hw_ptr,在此函数中将更新hw_ptr /*
pos = substream->ops->pointer(substream);//获取hw_ptr在当前HW buffer中的偏移,调用soc_pcm_pointer函数
if (platform->driver->ops && platform->driver->ops->pointer) //现在是获取这个
offset = platform->driver->ops->pointer(substream); //hw_ptr在当前HW buffer中的偏移
delay += cpu_dai->driver->ops->delay(substream, cpu_dai); //调用cpu_dai, codec_dai,platform的delay函数
delay += codec_dai->driver->ops->delay(substream, codec_dai);
delay += platform->driver->delay(substream, codec_dai);
if (pos >= runtime->buffer_size)
pos = 0;
pos -= pos % runtime->min_align; //以runtime->min_align对齐这个pos,位置
hw_base = runtime->hw_ptr_base; //获得基地址
new_hw_ptr = hw_base + pos; //获得新的地址
if (in_interrupt) //DMA传输完成后调用,in_interrupt=1
delta = runtime->hw_ptr_interrupt + runtime->period_size; ///* Position at interrupt time */中断的位置
if (delta > new_hw_ptr) {//如果本次通过中断位置加上period_size计算出来的hw_ptr比当前hw_ptr大的话,则说明有可能hw_base需要更新到下一个HW buffer的基地址。
.....细节不分析了.....
if (new_hw_ptr < old_hw_ptr) {//如果当前的hw_ptr比上一次的hw_ptr小,说明hw_base需要更新到下一个HW buffer的基地址。hw_ptr也要同步更新。
hw_base += runtime->buffer_size;
if (hw_base >= runtime->boundary) {//如果hw_base > boundary,那hw_base回跳到Ring Buffer起始位置。
if (hw_base >= runtime->boundary) {//如果hw_base > boundary,那hw_base回跳到Ring Buffer起始位置。
........细节不分析了.....
__delta:
delta = new_hw_ptr - old_hw_ptr;
if (delta < 0)//如果当前的hw_ptr任然比上一的hw_ptr小,说明hw_ptr走完了Ring buffer一圈。
if (delta < 0)//如果当前的hw_ptr任然比上一的hw_ptr小,说明hw_ptr走完了Ring buffer一圈。
........细节不分析.....
if (delta >= runtime->buffer_size + runtime->period_size) {//如果当前hw_ptr比较上一次相差buffer size + peroid size,说明有错误。
.......细节不分析.....
no_jiffies_check:
if (delta > runtime->period_size + runtime->period_size / 2) {//interupt丢失,delta(如果当前hw_ptr比较上一次之差)>1.5个peroid size
if (delta > runtime->period_size + runtime->period_size / 2) {//interupt丢失,delta(如果当前hw_ptr比较上一次之差)>1.5个peroid size
.......细节不分析.....
snd_pcm_playback_silence(substream, new_hw_ptr);//播放silence if (in_interrupt) {//更新hw_ptr_interrupt
.......细节不分析.....
5.PCM的状态转换
下图是PCM的状态的转换图
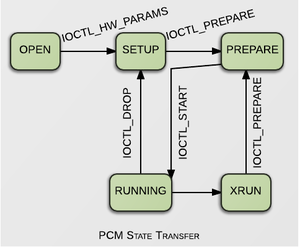
除XRUN状态之后,其它的状态大多都由用户空间的ioctl()显式的切换。
以TinyAlsa的播放音频流程为例。
pcm_open()的对应的流程就是:
open(pcm)后绑定一个substream,处于OPEN状态ioctl(SNDRV_PCM_IOCTL_SW_PARAMS)设定参数pcm_config.配置 runtime 的sw_para.切换到SETUP状态
Tinyalsa的pcm_wirte()流程:
ioctl(SNDRV_PCM_IOCTL_PREPARE)后,substream切换到PREPARE状态。ioctl(SNDRV_PCM_IOCTL_WRITEI_FRAMES)后,substream切换到RUNNING状态。
TinyAlsa的pcm_mmap_write()流程:
ioctl(SNDRV_PCM_IOCTL_PREPARE)后,substream切换到PREPARE状态。ioctl(SNDRV_PCM_IOCTL_START)后,substream切换到RUNNING状态。
TinyAlsa pcm_close流程:
ioctl(SNDRV_PCM_IOCTL_DROP)后,切换回SETUP状态。close()之后,释放这个设备。
XRUN状态又分有两种,在播放时,用户空间没及时写数据导致缓冲区空了,硬件没有 可用数据播放导致UNDERRUN;录制时,用户空间没有及时读取数据导致缓冲区满后溢出, 硬件录制的数据没有空闲缓冲可写导致OVERRUN.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号