利用scrapy爬取汽车排行榜的所有信息并保存至本地数据库(详解)
创建scrapy项目:scrapy startproject car
创建spider文件:scrapy genspider suv price.pcauto.com.cn
当前项目的目标站点:https://price.pcauto.com.cn/top/k75-p1.html(太平洋汽车suv销量排行榜),获取数据并保存至本地的MySQL数据库。
在配置文件settings里进行相关参数的配置。
关闭爬虫协议 ---> ROBOTSTXT_OBEY = False
禁用cookie ---> COOKIES_ENABLED = False
关于下载延时:DOWNLOAD_DELAY = 1.5 推荐设置为2到3秒
开启请求头默认配置:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Trident/7.0; rv 11.0) like Gecko',
}
启用管道配置信息:
ITEM_PIPELINES = {
'movie.pipelines.MoviePipeline': 300,
}
至此当前阶段的配置完成。
开始写要获取的数据参数文件 items.py
1 import scrapy
2
3
4 class CarItem(scrapy.Item):
5 # define the fields for your item here like:
6
7 ranking=scrapy.Field() #排名
8 car_name = scrapy.Field() #车名
9 price=scrapy.Field() #价格
10 hot=scrapy.Field() #热度
11 brand=scrapy.Field() #品牌
12 style=scrapy.Field() #类型
13 dispt=scrapy.Field() #排量
14 gear=scrapy.Field() #变速箱
15
16
开始spider文件的编写 suv.py
1 # -*- coding: utf-8 -*-
2 import scrapy
3 from car.items import CarItem
4
5 class SuvSpider(scrapy.Spider):
6 name = 'suv'
7 # allowed_domains = ['price.pcauto.com.cn'] #此处最好注释掉,否者可能无法爬取翻页后的数据
8 offset=1 #为页面偏移量 用于拼接新url
9 url='https://price.pcauto.com.cn/top/k75-p{0}.html'.format(str(offset))
10 start_urls = [url] #爬虫起始站点,仅执行一次
11
12 def parse(self, response):
13 item=CarItem() #实例化的一个数据字典对象用于存储数据
14 car=response.xpath('//div[@class="tbA"]/ul/li') #当前页20个节点对象
15
16 for each in car: #遍历并取其对应节点数据值
17
18 item['ranking']=each.xpath('./span/text()').extract()[0]
19 item['car_name']=each.xpath('./div[@class="info"]/p[@class="sname"]/a/text()').extract()[0]
20 item['price']=each.xpath('./div[@class="info"]/p[@class="col col1 price"]/em/text()').extract()[0]
21 item['hot']=each.xpath('./div[@class="info"]/p[@class="col rank"]/span[@class="fl red rd-mark"]/text()').extract()[0]
22 item['brand']=each.xpath('./div[@class="info"]/p[@class="col col1"][1]/text()').extract()[0]
23 item['style']=each.xpath('./div[@class="info"]/p[@class="col"][1]/text()').extract()[0]
24 item['dispt']=each.xpath('./div[@class="info"]/p[@class="col col1"]/em')
25 item['gear'] = each.xpath('./div[@class="info"]/p[@class="col"]/em')
26
27 # dispt排量、gear变速箱的值可能为空,直接赋值可能抛异常,必须对其判断后在赋值
28 if len(item['dispt'])!=0:
29 item['dispt'] =each.xpath('./div[@class="info"]/p[@class="col col1"]/em')[0].xpath('string(.)').extract()[0]
30 else:
31 item['dispt']='暂无信息'
32
33 if len(item['gear']) != 0:
34 item['gear'] = each.xpath('./div[@class="info"]/p[@class="col"]/em')[0].xpath('string(.)').extract()[0]
35 else:
36 item['gear'] = '暂无信息'
37
38 yield item #返回字典携带的数据
39
40 if self.offset<30: #获取后续页面数据
41 self.offset+=1
42 url = 'https://price.pcauto.com.cn/top/k75-p{0}.html'.format(str(self.offset))
43 self.url=url
44 yield scrapy.Request(self.url,callback=self.parse) #递归调用,发送请求
在xpath获取数据的时候,有些情况需要注意:
比如在获取排量和变速箱数据的时候,因为这两处都可能是一个或多个结果,而在迭代原始节点的时候,
我们只需要20个子节点对象,而子节点取多个数据时若直接转化取文本值text,数据就混乱了,最后就报错。
我们采取子节点下取子元素的所有数据,xpath下默认取到的数据都存在列表下,于是取[0]数据,并将其转化为字符串,
在存储其值。代码表现为:
item['dispt'] =each.xpath('./div[@class="info"]/p[@class="col col1"]/em')[0].xpath('string(.)').extract()[0]
要注意获取的数据是否为空,为空则用列表取值的方式容易报错。会报:index error:out of range 索引取值超范围
数据获取完成后,去pipelines里面操作数据。
1 import pymysql
2 import re
3
4 class CarPipeline(object):
5 def table_exists(self,con,table_name):
6 #判断数据表是否已经创建
7 sql='show tables;'
8 con.execute(sql)
9 tables=[con.fetchall()]
10 table_list=re.findall('(\'.*?\')',str(tables))
11 table_list=[re.sub("'" ,'',each) for each in table_list] #遍历并获得数据库表
12 if table_name in table_list:
13 return 1 #创建了返回1
14 else:
15 return 0 #不创建返回0
16
17 def process_item(self, item, spider):
18 connect=pymysql.connect(
19 user='root', # 用户名
20 password='root1234', # 密码
21 db='lgweb', # 数据库名
22 host='127.0.0.1', # 地址
23 port=3306, # 端口
24 charset='utf8')
25
26 conn=connect.cursor() #创建一个数据游标
27 conn.execute('use lgweb') #选择指定的数据库
28 table_name='db_suv' #指定数据表
29
30 ranking=item['ranking'] #取出管道里的数据
31 car_name=item['car_name']
32 price=item['price']
33 hot=item['hot']
34 brand=item['brand']
35 style=item['style']
36 dispt=item['dispt']
37 gear=item['gear']
38
39 if (self.table_exists(conn,table_name)!=1):
40 sql='create table db_suv(排名 VARCHAR (20),车名 VARCHAR (50),价格 VARCHAR (40),人气度 VARCHAR (30),品牌 VARCHAR (40),车型 VARCHAR (40),排量 VARCHAR (50),变速箱 VARCHAR (50))'
41 conn.execute(sql) #不存在则创建数据库表
42
43 try:
44 sql="insert into db_suv(排名,车名,价格,人气度,品牌,车型,排量,变速箱)VALUES ('%s','%s','%s','%s','%s','%s','%s','%s')"%(ranking,car_name,price,hot,brand,style,dispt,gear)
45 conn.execute(sql) #执行插入数据操作
46 connect.commit() #提交保存
47
48 finally:
49 conn.close() #关闭数据库链接
50
51 return item
执行到此,数据便能写入创建好的数据表了。
为了防止网站反爬虫,还可以在下载中间件里添加相关配置,user-agent请求头和proxy代理。
在settings配置文件中加入待匹配的中间件信息。
DOWNLOADER_MIDDLEWARES = {
'car.middlewares.RandomUserAgent':100, #获取随机的user-agent
'car.middlewares.RandomProxy':200,
}
USER_AGENT=[
"User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"User-Agent: Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"User-Agent: Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"User-Agent: Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36"
]
PROXIES=[
{'ip_port':'123.139.56.238:9999','user_psd':None},
# {'ip_port':'183.148.137.11:9999','user_psd':None},
# {'ip_port':'218.28.58.150:53281','user_psd':None},
# {'ip_port':'14.23.58.58:443','user_psd':None},
# {'ip_port':'163.125.69.146:8888', 'user_psd': None},
# {'ip_port':'223.156.114.84:9000', 'user_psd': None},
]
值得商榷的是:选择的免费代理IP服务器很容易就被封,建议有条件还是购买代理IP
然后在 ---> middlewares.py里面去编写中间件。
中间件的代码实现:
1 class RandomUserAgent(object):
2 def process_request(self,request,spider):
3 user_agent=random.choice(USER_AGENT)
4 request.headers.setdefault("User-Agent",user_agent)
5
6 class RandomProxy(object):
7 def process_request(self,request,spider):
8 proxy=random.choice(PROXIES)
9 if proxy['user_psd']is None: #没有用户名和密码则不需要认证
10 request.meta['proxy']='http://'+proxy['ip_port']
11 else:
12 bs64_user_psd=base64.b64encode(proxy['user_psd'])
13 request.meta['proxy']='http://'+proxy['ip_port']
14 request.headers['Proxy-Authorization']='Basic '+bs64_user_psd
注意:中间件里类下必须实现 def process_request(self,request,spider):方法,且配置在settings里的中间件必须全部实现,此处是两个。在此处配置的None必须与settings中的相对应,否则会报错。
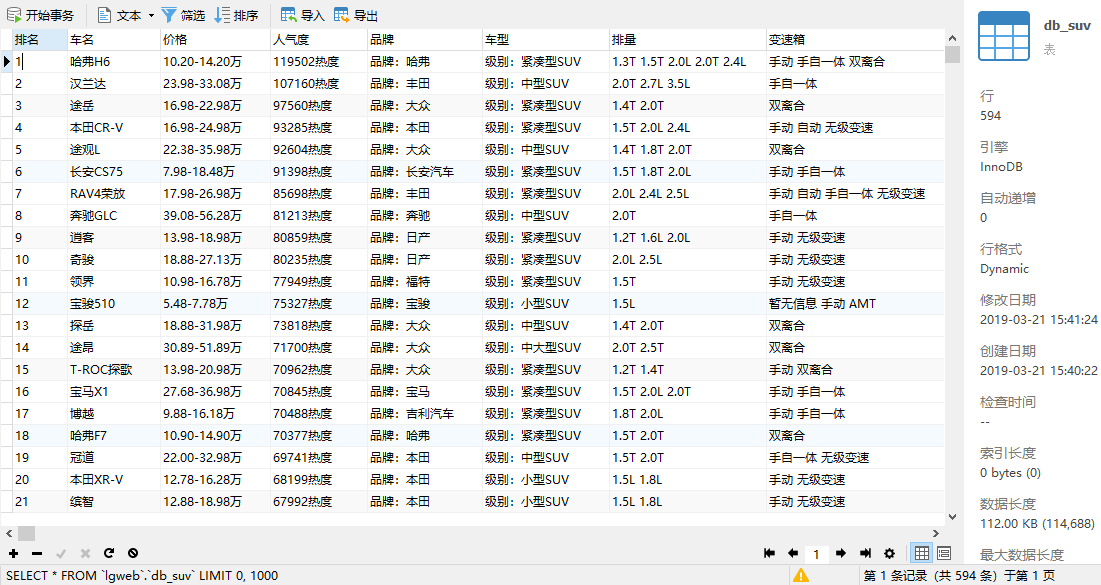
自此项目基本就能正常运行了。效果如图所示: