大多数人不知道的:HashMap链表成环的原因和解决方案
引导语
在 JDK7 版本下,很多人都知道 HashMap 会有链表成环的问题,但大多数人只知道,是多线程引起的,至于具体细节的原因,和 JDK8 中如何解决这个问题,很少有人说的清楚,百度也几乎看不懂,本文就和大家聊清楚两个问题:1:JDK7 中 HashMap 成环原因,2:JDK8 中是如何解决的。
JDK7 中 HashMap 成环原因
成环的时机
1:HashMap 扩容时。
2:多线程环境下。
成环的具体代码位置
在扩容的 transfer 方法里面,有三行关键的代码,如下:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
//e为空时循环结束
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
// 成环的代码主要是在这三行代码
// 首先插入是从头开始插入的
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
假设原来在数组 1 的下标位置有个链表,链表元素是 a->b->null,现在有两个线程同时执行这个方法,我们先来根据线程 1 的执行情况来分别分析下这三行代码:
-
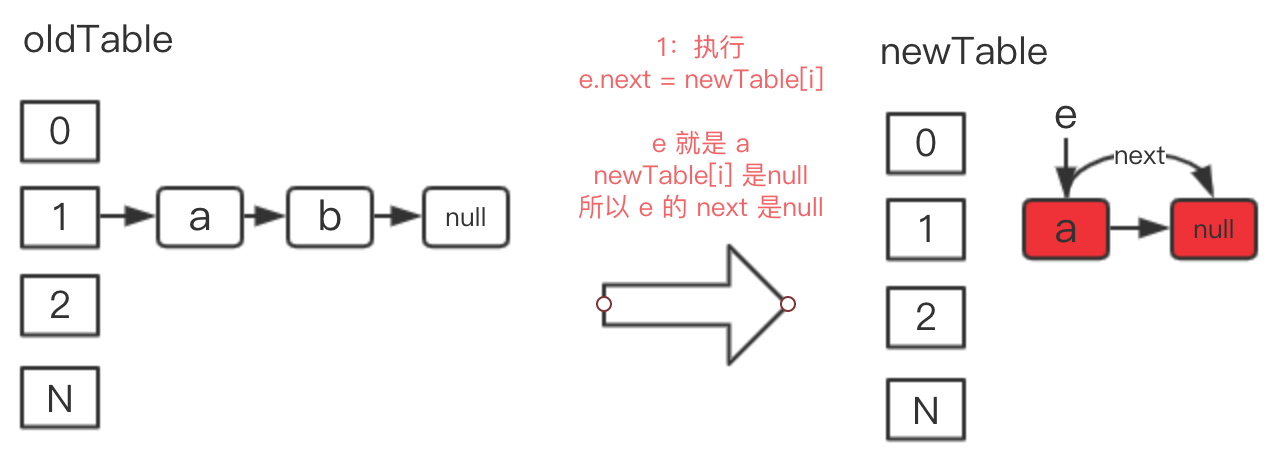
e.next = newTable[i];
newTable 表示新的数组,newTable[i] 表示新数组下标为 i 的值,第一次循环的时候为 null,e 表示原来链表位置的头一个元素,是 a,e.next 是 b,
e.next = newTable[i] 的意思就是拿出 a 来,并且使 a 的后一个节点是 null,如下图 1 的位置:
-
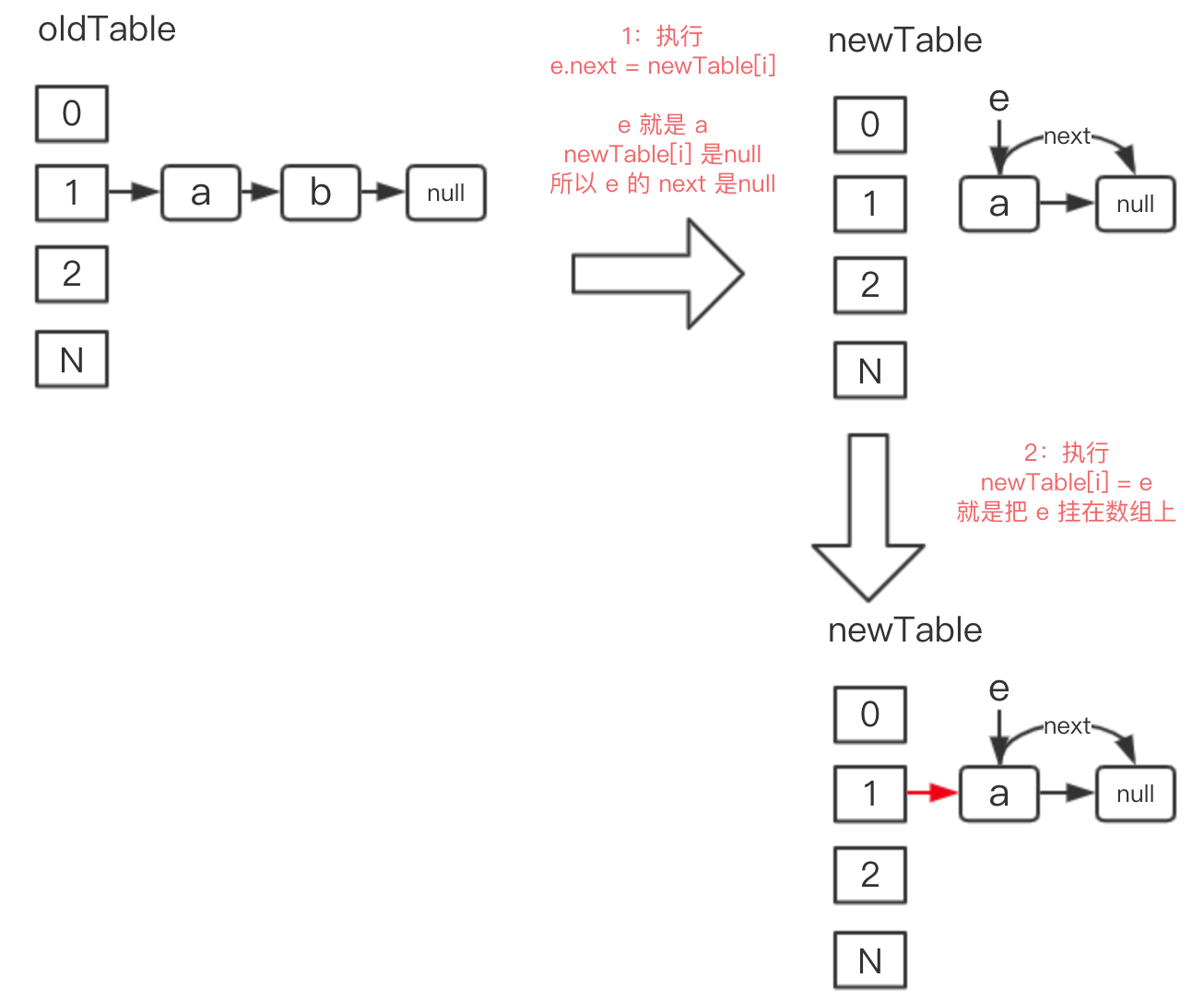
newTable[i] = e;
就是把 a 赋值给新数组下标为 1 的地方,如下图 2 的位置:
-
e = next;
next 的值在 while 循环一开始就有了,为:Entry<K,V> next = e.next; 在此处 next 的值就是 b,把 b 赋值给 e,接着下一轮循环。 -
从 b 开始下一轮循环,重复 1、2、3,注意此时 e 是 b 了,而 newTable[i] 的值已经不是空了,已经是 a 了,所以 1,2,3 行代码执行下来,b 就会插入到 a 的前面,如下图 3 的位置:
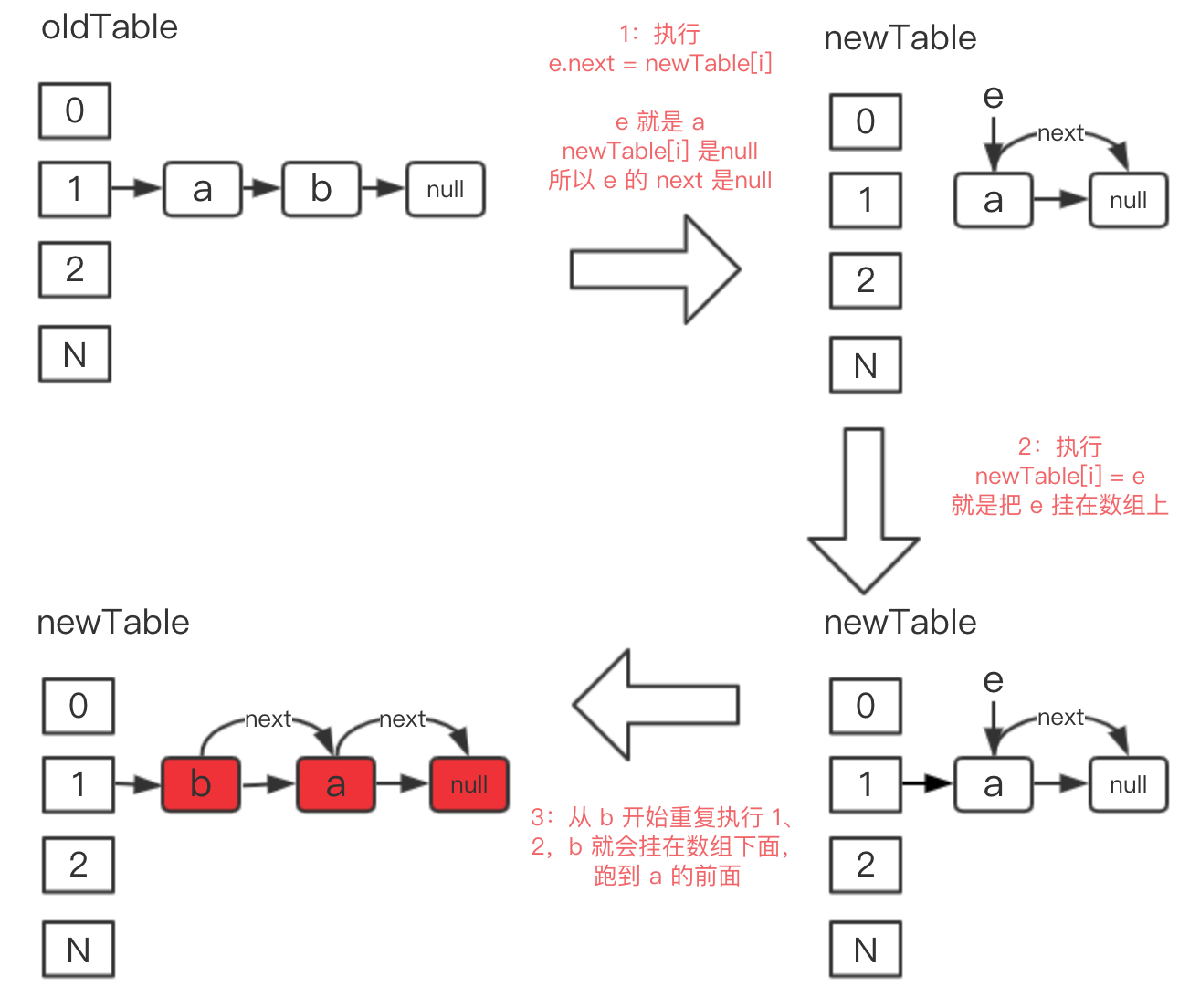
这个就是线程 1 的插入节奏。



重点来了,假设线程 1 执行到现在的时候,线程 2 也开始执行,线程 2 是从 a 开始执行 1、2、3、4 步,此时数组上面链表已经形成了 b->a->null,线程 2 拿出 a 再次执行 1、2、3、4,就会把 a 放到 b 的前面,大家可以想象一下,结果是如下图的:

从图中可以看出,有两个相同的 a 和两个相同的 b,这就是大家说的成环,自己经过不断 next 最终指向自己。
注意!!!这种解释看似好像很有道理,但实际上是不正确的,网上很多这种解释,这种解释最致命的地方在于 newTable 不是共享的,线程 2 是无法在线程 1 newTable 的基础上再进行迁移数据的,1、2、3 都没有问题,但 4 有问题,最后的结论也是有问题的
因为 newTable 是在扩容方法中新建的局部变量,方法的局部变量线程之间肯定是无法共享的,所以以上解释是有问题的,是错误的。
那么真正的问题出现在那里呢,其实线程 1 完成 1、2、3、4 步后就出现问题了,如下图:

总结一下产生这个问题的原因:
- 插入的时候和平时我们追加到尾部的思路是不一致的,是链表的头结点开始循环插入,导致插入的顺序和原来链表的顺序相反的。
- table 是共享的,table 里面的元素也是共享的,while 循环都直接修改 table 里面的元素的 next 指向,导致指向混乱。
接下来我们来看下 JDK8 是怎么解决这个问题。
JDK8 中解决方案
JDK 8 中扩容时,已经没有 JDK7 中的 transfer 方法了,而是自己重新写了扩容方法,叫做 resize,链表从老数组拷贝到新数组时的代码如下:
//规避了8版本以下的成环问题
else { // preserve order
// loHead 表示老值,老值的意思是扩容后,该链表中计算出索引位置不变的元素
// hiHead 表示新值,新值的意思是扩容后,计算出索引位置发生变化的元素
// 举个例子,数组大小是 8 ,在数组索引位置是 1 的地方挂着一个链表,链表有两个值,两个值的 hashcode 分别是是9和33。
// 当数组发生扩容时,新数组的大小是 16,此时 hashcode 是 33 的值计算出来的数组索引位置仍然是 1,我们称为老值
// hashcode 是 9 的值计算出来的数组索引位置是 9,就发生了变化,我们称为新值。
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
// java 7 是在 while 循环里面,单个计算好数组索引位置后,单个的插入数组中,在多线程情况下,会有成环问题
// java 8 是等链表整个 while 循环结束后,才给数组赋值,所以多线程情况下,也不会成环
do {
next = e.next;
// (e.hash & oldCap) == 0 表示老值链表
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// (e.hash & oldCap) == 0 表示新值链表
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 老值链表赋值给原来的数组索引位置
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 新值链表赋值到新的数组索引位置
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
解决办法其实代码中的注释已经说的很清楚了,我们总结一下:
-
JDK8 是等链表整个 while 循环结束后,才给数组赋值,此时使用局部变量 loHead 和 hiHead 来保存链表的值,因为是局部变量,所以多线程的情况下,肯定是没有问题的。
-
为什么有 loHead 和 hiHead 两个新老值来保存链表呢,主要是因为扩容后,链表中的元素的索引位置是可能发生变化的,代码注释中举了一个例子:
数组大小是 8 ,在数组索引位置是 1 的地方挂着一个链表,链表有两个值,两个值的 hashcode 分别是是 9 和 33。当数组发生扩容时,新数组的大小是 16,此时 hashcode 是 33 的值计算出来的数组索引位置仍然是 1,我们称为老值(loHead),而 hashcode 是 9 的值计算出来的数组索引位置却是 9,不是 1 了,索引位置就发生了变化,我们称为新值(hiHead)。
大家可以仔细看一下这几行代码,非常巧妙。
总结
本文主要分析了 HashMap 链表成环的原因和解决方案,你学会了吗?
想知道 HashMap 底层数据结构是什么样的么?想了解 ConcurrentHashMap 是如何保证线程安全的么?想阅读更多 JUC 的源码么,请关注我的新课:面试官系统精讲Java源码及大厂真题,带你一起阅读 Java 核心源码,了解更多使用场景,为升职加薪做好准备。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号