语义分割Semantic Segmentation研究综述
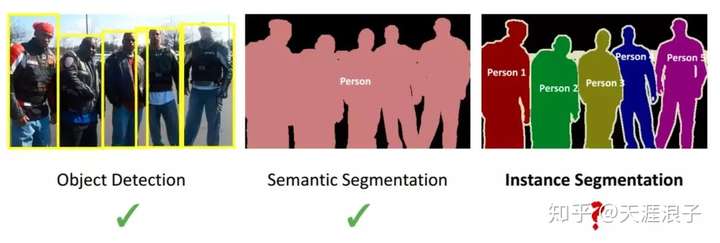
语义分割和实例分割概念
语义分割:对图像中的每个像素都划分出对应的类别,实现像素级别的分类。
实例分割:目标是进行像素级别的分类,而且在具体类别的基础上区别不同的实例。
语义分割(Semantic Segmentation)
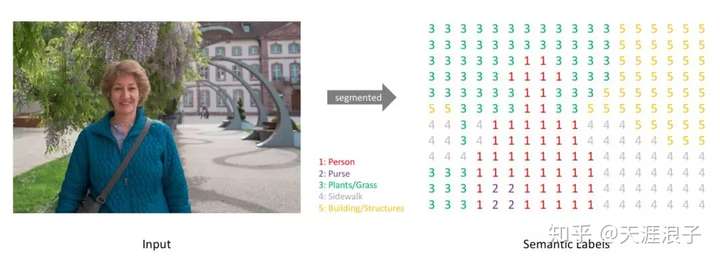
输入:一张原始的RGB图像
输出:带有各像素类别标签的与输入同分辨率的分割图像
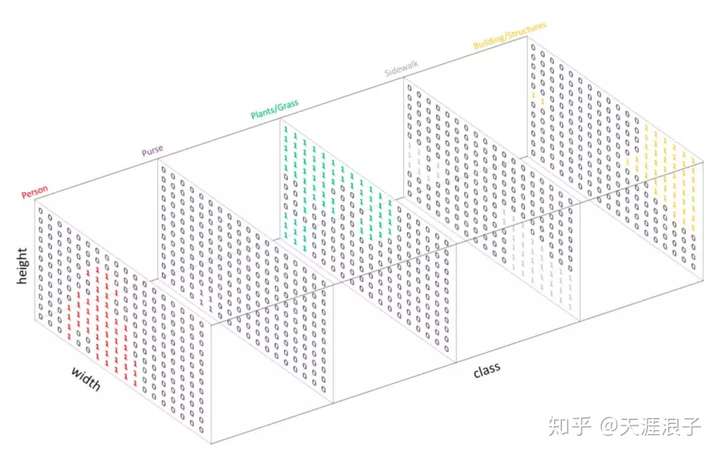
对预测的分类目标采用one-hot编码,为每个分类类别创建一个输出的channel。
将分割图相加到原始图像上的效果。

语义分割的难点
在经典的网络中,需要经过多层卷积和池化进行提取特征工作,从而找到分类目标,这个过程会使图像尺寸逐渐减小。需要将分类后的特征图还原到原图尺寸。
通常的做法是编码和解码网络结构。
卷积核池化操作可以看图像编码的过程,也就是下采样过程。
解码理解为编码的逆运算,对输出的特征图不断上采样,逐渐得到一个与原始图像同分辨率的分割图。
卷积动图
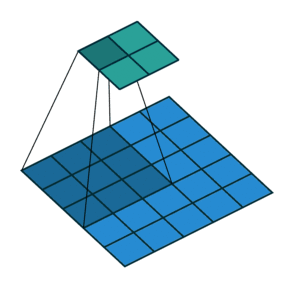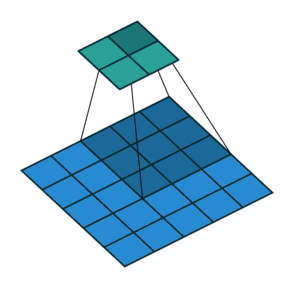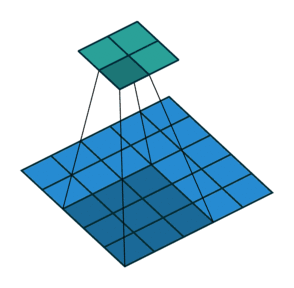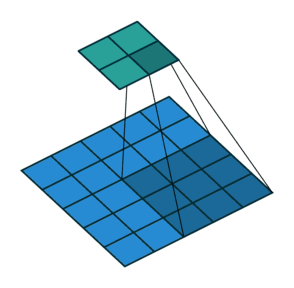
最大池化和最大池化的示意图(池化上采样是通过将单个值分配更高的分辨率来达到扩充的目的)
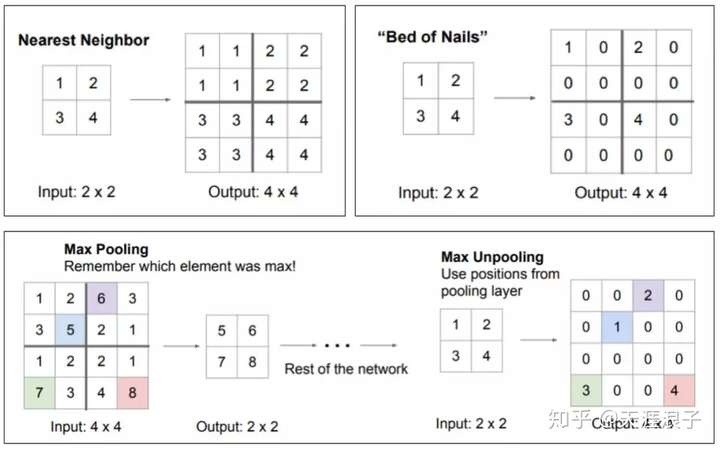
反卷积(转置卷积)

Dilated convolution(空洞卷积)

1. FCN全卷积网络简介
1.1 关键技术:卷积化(convolutionalization)
分类所使用的网络通常会在最后连接全连接层,它会将原来二维的矩阵(图片)压缩成一维的,从而丢失了空间信息,最后训练输出一个标量,这就是我们的分类标签。
语义分割的输出是个分割图,至少是二维的。通常是一个类别为一个通道。
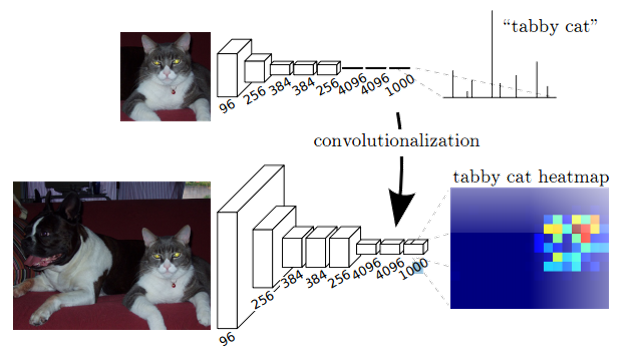
1.2 关键技术:上采样(Upsampling)
需要得到一个与原图像size相同的分割图,需要对最后一层进行上采样。
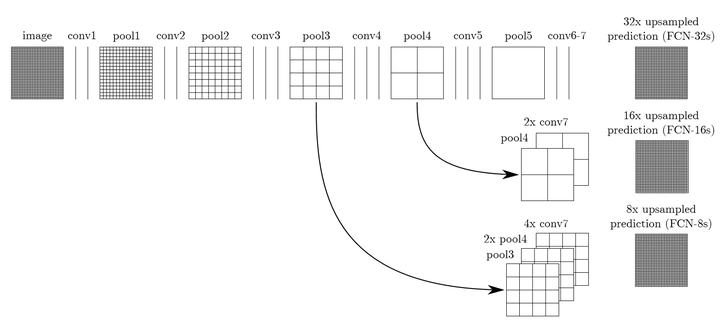
1.3 关键技术:跳跃结构(Skip Architecture)
由于直接将全卷积的结果上采样后的结果很粗糙。采用跳跃结构,将不同池化层的结果进行上采样,然后结合这些结果来优化输出。(出发点:由于池化层会丢失信息,将不同池化层结果上采样,从而弥补部分信息)
2. u-net简介
u-net作为FCN的改进,通过扩大网络解码器容量来改进了全卷积网络结构,并给编码和解码模块添加了收缩路径(contracting path),从而实现更精准的像素边界定位。
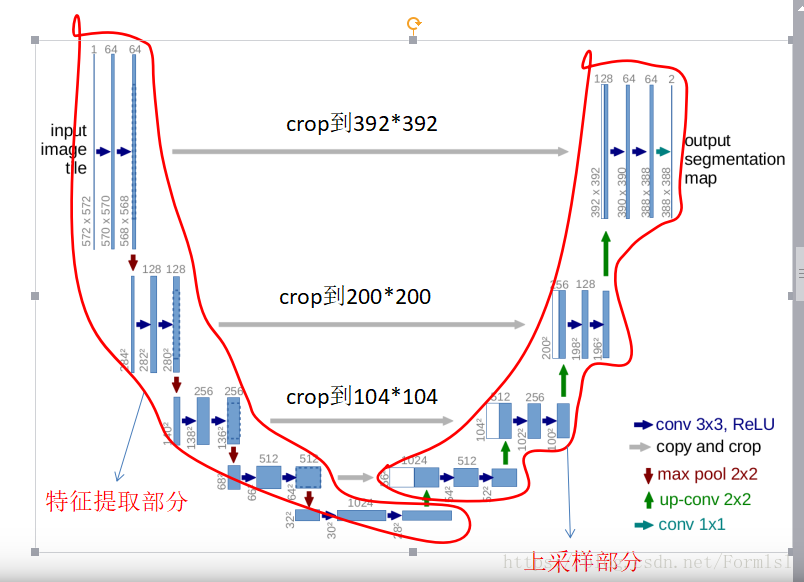
融合之前要crop到对应的层相同尺寸。(思考:融合操作是不是对应通道的相加,具体需要看论文和代码。有没有更合理的特征融合方法)
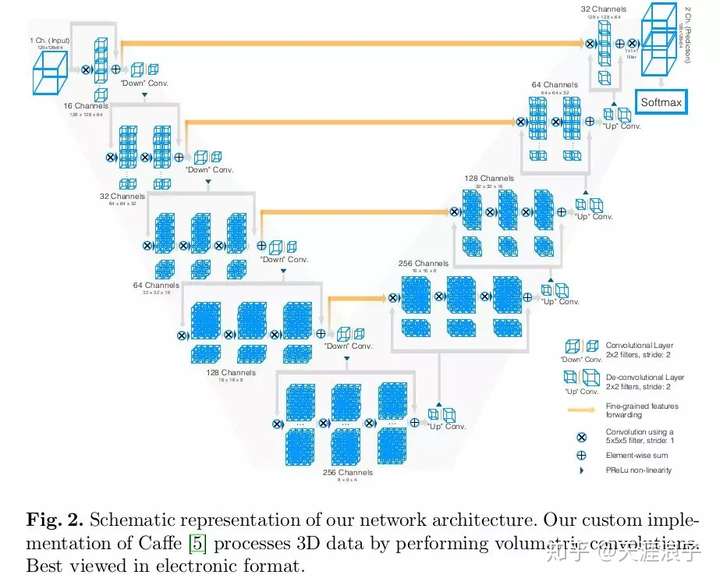
3. v-net简介
v-net 可以理解为 3D 版本的 u-net ,适用于三维结构的医学影像分割。v-net 能够实现 3D 图像端到端的图像语义分割,加了一些像残差学习一样的trick来进行网络改进,总体结构上与 u-net 差异不大。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号