nginx日志分析
nginx是常见的web、缓存、代理等服务,以功能强大、服务稳定、占用资源少等优点著称。然而实际使用中,大家对nginx有一种误解:认为它很简单,以至于很少会有人系统的去学习它。
本篇博文主要讲解nginx日志分析,日志的格式可以经过自定义以适用自己的需求。nginx日志主要分为访问日志(access)、错误日志等(error),当nginx作为反向代理,前面使用cdn时,默认的nginx日志格式无法获取到用户端IP,需要修改。下面是我修改的nginx日志格式,请参考:
log_format main 'WebAcessLogInformation dateTime="[$time_local]" ' 'xForwardedFor="$http_x_forwarded_for" sourceAddress=$remote_addr ' 'dstAddress=$server_addr dstHostName="$server_name" dstPort="$server_port" ' 'userAgent="$http_user_agent" bytesOutInfo=$bytes_sent sourceUserName="$remote_user" ' 'responseCode=$status httpRerfer="$http_referer" logSessionNum="-" ' 'responseTimems=$request_time responseTimes=- requestRInfo="$request" ';
说明:“=”前面的字符串是个人定义的常量名,可以为任意名称,如:“WebAcessLogInformation”可以写成“nginx-log”等字样,之所以这样写,是为了更方便用awk、cut等工具对日志截取。
访问日志分析,常见的需求有:1.统计pv(当天访问nginx的次数,即:access日志的行数);2.最活跃的前n个IP;3.访问最频繁的前n个url;4.各网页状态码数目;5.最活跃的前n个IP的每个IP访问的最频繁的前n个URL;6.访问最频繁的前n个url的每个url最活跃的前n个IP(有点拗口,哈哈);7.以上各参数统计结果占比......可能对有些同学来说,乍一看这些需求无从下手的样子,实际上很简单——就是一些linux命令的组合——就是awk、sort、uniq、cut、head等命令的组合。
运维这件事儿,很简单~ 难得是没有需求,目标不明确,就会感觉无从下手。很多时候,脚本可以帮助我们处理大部分事情,脚本写的好与坏,关系到使用者能否准确定位到问题,所以请对脚本加上足够的备注及说明。
下面是我贡献的一份脚本,在使用之前,请将nginx日志改成上面格式,脚本使用方式:sh nginx_access_analyze.sh { simple | detail | help }。说明:“simple”选项是简单分析(简单输出)的意思;“detail”选项是详细分析(详细输出)的意思,“help”选项是帮助文档,包括脚本使用说明、日志格式。
#!/bin/bash
# func: analyze nginx access log.
# version: v1.2
# auth: 任小为
# tel: 18658160015
# date: 2018.07.11
public(){
echo ""
read -p "请输入要分析的访问日志: " log_file
echo ""
if [ ! -f $log_file ];then
echo -e "未找到: ${log_file} \n"
exit 1
fi
if [ ! -s $log_file ];then
echo -e "${log_file}是空文件 \n"
exit 1
fi
top_num=10
input_file=`echo $log_file | awk -F '/' '{print $(NF)}'`
analyze_dir=/tmp/nginx_log_analyze
top_ip_file=$analyze_dir/ngx_log_top_ip_${input_file}.txt
top_src_url_file=$analyze_dir/ngx_log_top_src_url_${input_file}.txt
top_dest_url_file=$analyze_dir/ngx_log_top_dest_url_${input_file}.txt
top_code_file=$analyze_dir/ngx_log_top_code_${input_file}.txt
mkdir -p $analyze_dir
start_time=`head -1 $log_file | awk '{print $2}'|cut -d "[" -f2`
end_time=`tail -1 $log_file | awk '{print $2}'|cut -d "[" -f2`
total_nums=`wc -l $log_file | awk '{print $1}'`
size=`du -sh $log_file | awk '{print $1}'`
#获取起始与截止时间
echo -e "访问起始时间: $start_time ; 截止时间: $end_time \n"
#获取总行数与大小
echo -e "共访问 $total_nums 次 ; 日志大小: $size \n"
#获取最活跃IP
awk -F "sourceAddress=" '{print $2}' $log_file | awk '{print $1}' | sort | uniq -c | sort -rn | head -${top_num} > $top_ip_file
#获取访问来源最多的url
awk -F "httpRerfer=" '{print $2}' $log_file | awk -F '"' '{print $2}' | sort | uniq -c | sort -rn | head -${top_num} > $top_src_url_file
#获取请求最多的url
awk -F 'requestRInfo=' '{print $2}' $log_file | awk '{print $2}' | sort | uniq -c | sort -rn | head -${top_num} > $top_dest_url_file
#获取返回最多的状态码
awk -F " responseCode=" '{print $2}' $log_file | cut -d " " -f1 | sort | uniq -c | sort -rn | head -${top_num} > $top_code_file
}
simple(){
echo -e "\033[44;36m+-+-+-+-+-+- 下面是粗略分析 +-+-+-+-+-+-\033[0m \n"
#获取最活跃IP
printf "\033[44;36m最活跃的前${top_num}个访问IP: \033[0m \n"
cat $top_ip_file
echo ""
#获取访问来源最多的url
printf "\033[44;36m访问来源最多的前${top_num}个url: \033[0m \n"
cat $top_src_url_file
echo ""
#获取请求最多的url
printf "\033[44;36m请求最多的前${top_num}个url: \033[0m \n"
cat $top_dest_url_file
echo ""
#获取返回最多的状态码
printf "\033[44;36m返回最多的前${top_num}个状态码: \033[0m \n"
cat $top_code_file
echo ""
}
detail(){
echo -e "\033[44;36m+-+-+-+-+-+- 下面是详细分析 +-+-+-+-+-+-\033[0m \n"
printf "\033[44;36m最活跃的前${top_num}个访问IP详情: \033[0m \n"
ip_nums=`wc -l $top_ip_file | awk '{print $1}'`
for ((i=1; i<=$ip_nums; i++))
do
ip_num=`head -$i $top_ip_file | tail -1 | awk '{print $1}'`
ip_addr=`head -$i $top_ip_file | tail -1 | awk '{print $2}'`
ip_percent=`awk 'BEGIN { printf "%.1f%",('$ip_num'/'$total_nums')*100 }'`
#分别计算访问最多的url所占百分比
echo ""
echo -e "共有来自 ${ip_addr} 的 ${ip_num} 条访问,占比:\033[31;49;1m ${ip_percent} \033[31;49;0m \n"
#分别计算每个访问最多的IP的最多来源url
echo -e "\033[32;49;1m+=+=+=+= ${ip_addr} \033[31;49;0m访问来源最多的前${top_num}个url: "
grep ${ip_addr} $log_file | awk -F "httpRerfer=" '{print $2}' | awk -F '"' '{print $2}' | sort | uniq -c | sort -rn | head -${top_num}
echo ""
#分别计算每个请求最多的IP的最多来源url
echo -e "\033[32;49;1m#+#+#+#+\033[31;49;0m${ip_addr}请求最多的前${top_num}个url: "
grep ${ip_addr} $log_file | awk -F 'requestRInfo=' '{print $2}' | awk '{print $2}' | sort | uniq -c | sort -rn | head -${top_num}
done
echo ""
printf "\033[44;36m访问来源最多的前${top_num}个url详情: \033[0m \n"
url_src_nums=`wc -l $top_src_url_file | awk '{print $1}'`
for ((k=1; k<=$url_src_nums; k++))
do
url_src_num=`head -$k $top_src_url_file | tail -1 | awk '{print $1}'`
url_src_addr=`head -$k $top_src_url_file | tail -1 | awk '{print $2}'`
url_src_percent=`awk 'BEGIN { printf "%.1f%",('$url_src_num'/'$total_nums')*100 }'`
#分别计算访问来源最多的url所占百分比
echo ""
echo -e "共有 ${url_src_num} 条 ${url_src_addr} 的访问,占比:\033[31;49;1m ${url_src_percent} \033[31;49;0m \n"
#分别计算每个访问来源最多的url的最多ip
echo -e "\033[32;49;1m#-#-#-#-\033[31;49;0m${url_src_addr}访问最多的前${top_num}个ip: "
grep "${url_src_addr}" $log_file | awk -F 'sourceAddress=' '{print $2}' | awk '{print $1}' |sort | uniq -c | sort -rn | head -${top_num}
done
echo ""
printf "\033[44;36m请求最多的前${top_num}个url详情: \033[0m \n"
url_dest_nums=`wc -l $top_dest_url_file | awk '{print $1}'`
for ((j=1; j<=$url_dest_nums; j++))
do
url_dest_num=`head -$j $top_dest_url_file | tail -1 | awk '{print $1}'`
url_dest_addr=`head -$j $top_dest_url_file | tail -1 | awk '{print $2}'`
url_dest_percent=`awk 'BEGIN { printf "%.1f%",('$url_dest_num'/'$total_nums')*100 }'`
#分别计算访问请求最多的url所占百分比
echo ""
echo -e "共有 ${url_dest_num} 条 ${url_dest_addr} 请求的访问,占比:\033[31;49;1m ${url_dest_percent} \033[31;49;0m \n"
#分别计算每个访问请求最多的url的最多ip
echo -e "\033[32;49;1m#.#.#.#.\033[31;49;0m${url_dest_addr}访问最多的前${top_num}个ip: "
grep "${url_dest_addr}" $log_file | awk -F 'sourceAddress=' '{print $2}' | awk '{print $1}' |sort | uniq -c | sort -rn | head -${top_num}
done
echo ""
printf "\033[44;36m返回最多的前${top_num}个状态码详情: \033[0m \n"
code_nums=`wc -l $top_code_file | awk '{print $1}'`
for ((h=1; h<=$code_nums; h++))
do
code_num=`head -$h $top_code_file | tail -1 | awk '{print $1}'`
code_name=`head -$h $top_code_file | tail -1 | awk '{print $2}'`
code_percent=`awk 'BEGIN { printf "%.1f%",('$code_num'/'$total_nums')*100 }'`
#分别计算请求最多的状态码百分比
echo ""
echo -e "状态码为 ${code_name} 的共有 ${code_num} 条,占比:\033[31;49;1m ${code_percent} \033[31;49;0m \n"
#分别计算每个最多状态码的最多ip
echo -e "\033[32;49;1m*.*.*.*.\033[31;49;0m状态码为${code_name}访问最多的前${top_num}个ip: "
grep "responseCode=${code_name}" $log_file | awk -F "sourceAddress=" '{print $2}' | awk '{print $1}' | sort | uniq -c | sort -rn | head -${top_num}
done
echo ""
}
log_format(){
cat << EOF
log_format main 'WebAcessLogInformation dateTime="[\$time_local]" '
'xForwardedFor="\$http_x_forwarded_for" sourceAddress=\$remote_addr '
'dstAddress=\$server_addr dstHostName="\$server_name" dstPort="\$server_port" '
'userAgent="\$http_user_agent" bytesOutInfo=\$bytes_sent sourceUserName="\$remote_user" '
'responseCode=\$status httpRerfer="\$http_referer" logSessionNum="-" '
'responseTimems=\$request_time responseTimes=- requestRInfo="\$request" ';
EOF
echo ""
}
case $1 in
simple)
public
simple
;;
detail)
public
detail
;;
help)
echo ""
echo -e "\033[44;36m1. 脚本使用方法: sh $0 { simple | detail | help }\033[0m"
echo -e "\033[44;36m simple选项代表错略分析; detail代表详细分析.\033[0m \n"
echo -e "\033[44;36m2. 请确保日志必须为如下格式: \033[0m \n"
log_format
;;
*)
echo ""
echo -e $"Usage: $0 { simple | detail | help }\n"
esac
exit 0
几点建议:
1.请将脚本命名成一个有意义的名字,如:nginx_access_analyze.sh ;
2.写脚本时,合理利用缩进、空行、注释、备注等,便于后期维护及他人阅读;
3.脚本的输出结果,合理利用“echo " "”或“print " "”空行,输出到终端的颜色(如正确的用绿色或不用颜色,错误用红色标记等)利于脚本输出结果的排版,便于阅读;
4.脚本尽量用“模块”话“拼凑”,这里的“模块”即bash函数,每个函数尽量简单,最好只做一件事,如此下来,通篇脚本也会尽量简单,也会只做“一件事”,不建议写的太花哨;
5.脚本的变量尽量放在文件开头,尤其是容易改动的变量要放在前排;脚本主体或者函数尽量不出现常量(如:引用某个文件的路径),尽量用变量替代常量(如:用${file_log}代替某个日志文件),这样做利于他人修改。
光说不练,不如回家喝稀饭!下面是我执行脚本的截图,请大家参考:

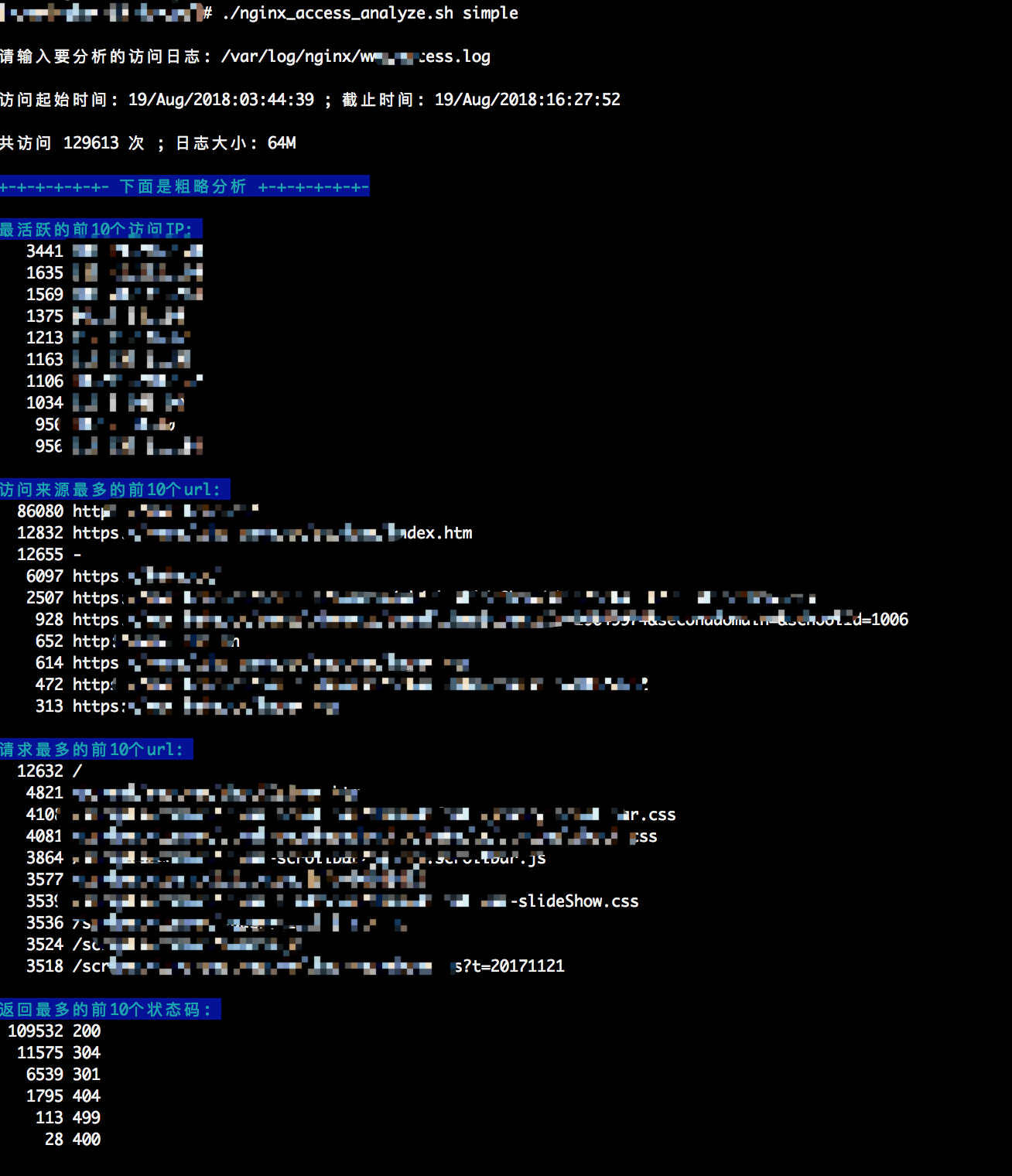
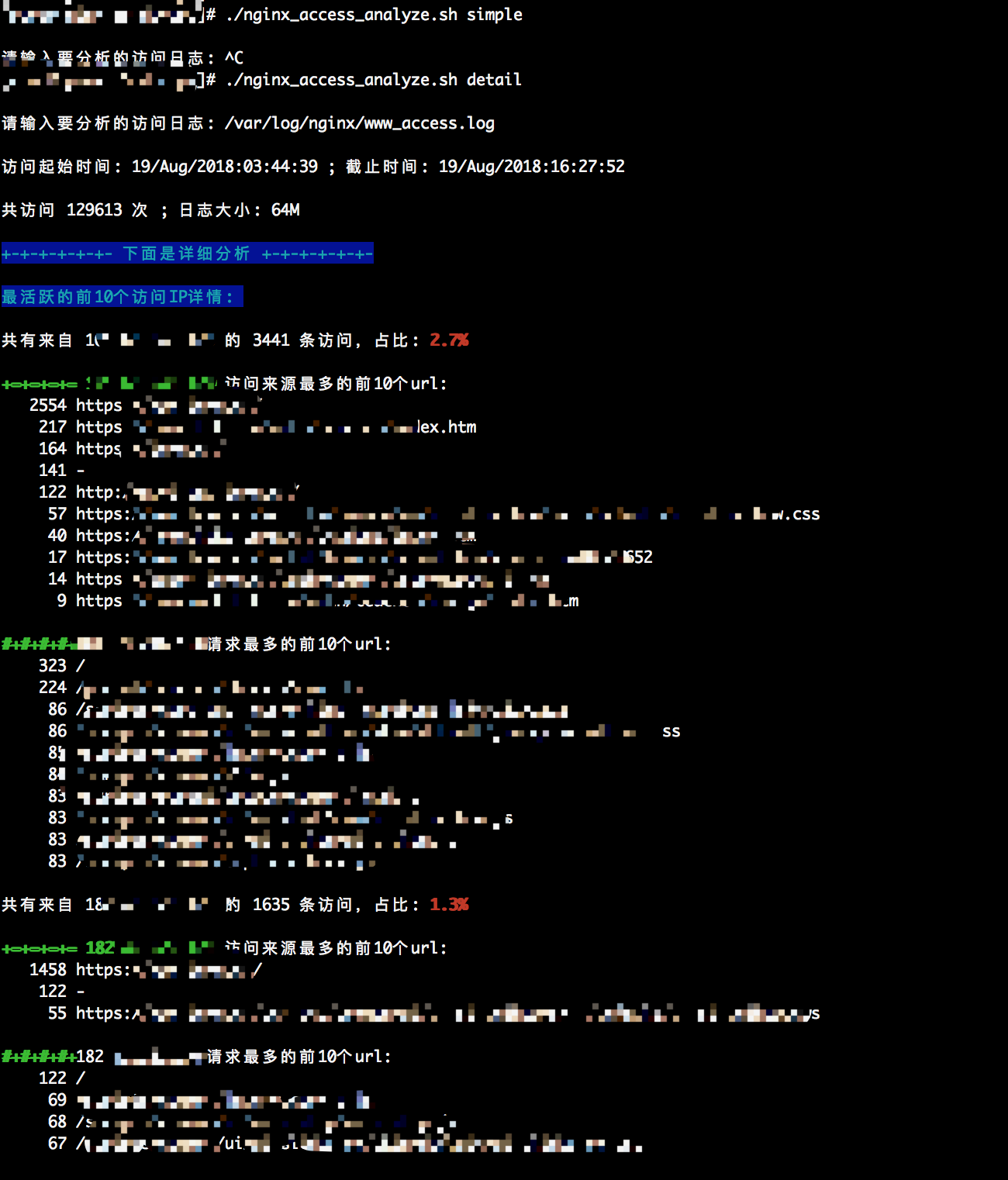
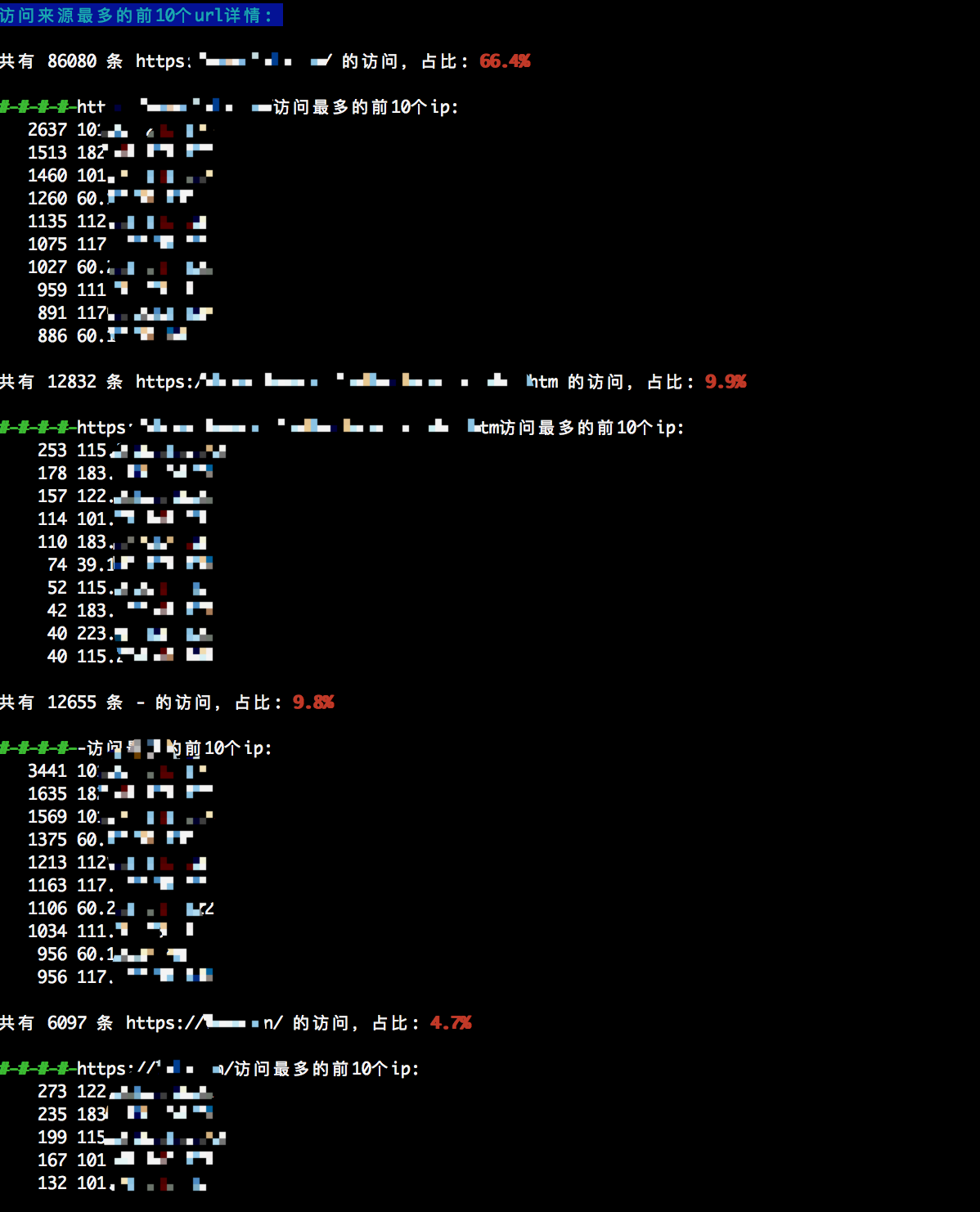
如果有更好观点的小伙伴欢迎留言讨论,感谢您的阅览,授人以鱼不如授人以渔!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号