Python中开启线程和线程池的方法,
一.最佳线程数的获取:
1、通过用户慢慢递增来进行性能压测,观察QPS(即每秒的响应请求数,也即是最大吞吐能力。),响应时间
2、根据公式计算:服务器端最佳线程数量=((线程等待时间+线程cpu时间)/线程cpu时间) * cpu数量
3、单用户压测,查看CPU的消耗,然后直接乘以百分比,再进行压测,一般这个值的附近应该就是最佳线程数量。
二、为什么要使用线程池?
1. 多线程中,线程的数量并非越多越好
2.节省每次开启线程的开销
三、如何实现线程池?
1. threadpool模块
2.concurrent.futures
3.重写threadpool或者future的函数
4.vthread 模块
1、过去:
使用threadpool模块,这是个python的第三方模块,支持python2和python3,具体使用方式如下:

#! /usr/bin/env python
# -*- coding: utf-8 -*-
import threadpool
import time
def sayhello (a):
print("hello: "+a)
time.sleep(2)
def main():
global result
seed=["a","b","c"]
start=time.time()
task_pool=threadpool.ThreadPool(5)
requests=threadpool.makeRequests(sayhello,seed)
for req in requests:
task_pool.putRequest(req)
task_pool.wait()
end=time.time()
time_m = end-start
print("time: "+str(time_m))
start1=time.time()
for each in seed:
sayhello(each)
end1=time.time()
print("time1: "+str(end1-start1))
if __name__ == '__main__':
main()
运行结果如下:
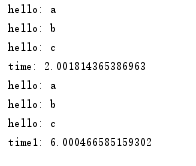
threadpool是一个比较老的模块了,现在虽然还有一些人在用,但已经不再是主流了,关于python多线程,现在已经开始步入未来(future模块)了
2、未来:
使用concurrent.futures模块,这个模块是python3中自带的模块,但是,python2.7以上版本也可以安装使用,具体使用方式如下:
#! /usr/bin/env python
# -*- coding: utf-8 -*-
from concurrent.futures import ThreadPoolExecutor
import time
def sayhello(a):
print("hello: "+a)
time.sleep(2)
def main():
seed=["a","b","c"]
start1=time.time()
for each in seed:
sayhello(each)
end1=time.time()
print("time1: "+str(end1-start1))
start2=time.time()
with ThreadPoolExecutor(3) as executor:
for each in seed:
executor.submit(sayhello,each)
end2=time.time()
print("time2: "+str(end2-start2))
start3=time.time()
with ThreadPoolExecutor(3) as executor1:
executor1.map(sayhello,seed)
end3=time.time()
print("time3: "+str(end3-start3))
if __name__ == '__main__':
main()
运行结果如下:
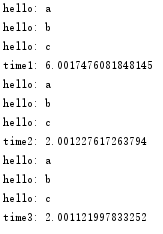
注意到一点:
concurrent.futures.ThreadPoolExecutor,在提交任务的时候,有两种方式,一种是submit()函数,另一种是map()函数,两者的主要区别在于:
2.1、map可以保证输出的顺序, submit输出的顺序是乱的
2.2、如果你要提交的任务的函数是一样的,就可以简化成map。但是假如提交的任务函数是不一样的,或者执行的过程之可能出现异常(使用map执行过程中发现问题会直接抛出错误)就要用到submit()
2.3、submit和map的参数是不同的,submit每次都需要提交一个目标函数和对应的参数,map只需要提交一次目标函数,目标函数的参数放在一个迭代器(列表,字典)里就可以。
3.现在?
这里要考虑一个问题,以上两种线程池的实现都是封装好的,任务只能在线程池初始化的时候添加一次,那么,假设我现在有这样一个需求,需要在线程池运行时,再往里面添加新的任务(注意,是新任务,不是新线程),那么要怎么办?
其实有两种方式:
3.1、重写threadpool或者future的函数:
这个方法需要阅读源模块的源码,必须搞清楚源模块线程池的实现机制才能正确的根据自己的需要重写其中的方法。
3.2、自己构建一个线程池:
这个方法就需要对线程池的有一个清晰的了解了,附上我自己构建的一个线程池:
#! /usr/bin/env python
# -*- coding: utf-8 -*-
import threading
import Queue
import hashlib
import logging
from utils.progress import PrintProgress
from utils.save import SaveToSqlite
class ThreadPool(object):
def __init__(self, thread_num, args):
self.args = args
self.work_queue = Queue.Queue()
self.save_queue = Queue.Queue()
self.threads = []
self.running = 0
self.failure = 0
self.success = 0
self.tasks = {}
self.thread_name = threading.current_thread().getName()
self.__init_thread_pool(thread_num)
# 线程池初始化
def __init_thread_pool(self, thread_num):
# 下载线程
for i in range(thread_num):
self.threads.append(WorkThread(self))
# 打印进度信息线程
self.threads.append(PrintProgress(self))
# 保存线程
self.threads.append(SaveToSqlite(self, self.args.dbfile))
# 添加下载任务
def add_task(self, func, url, deep):
# 记录任务,判断是否已经下载过
url_hash = hashlib.new('md5', url.encode("utf8")).hexdigest()
if not url_hash in self.tasks:
self.tasks[url_hash] = url
self.work_queue.put((func, url, deep))
logging.info("{0} add task {1}".format(self.thread_name, url.encode("utf8")))
# 获取下载任务
def get_task(self):
# 从队列里取元素,如果block=True,则一直阻塞到有可用元素为止。
task = self.work_queue.get(block=False)
return task
def task_done(self):
# 表示队列中的某个元素已经执行完毕。
self.work_queue.task_done()
# 开始任务
def start_task(self):
for item in self.threads:
item.start()
logging.debug("Work start")
def increase_success(self):
self.success += 1
def increase_failure(self):
self.failure += 1
def increase_running(self):
self.running += 1
def decrease_running(self):
self.running -= 1
def get_running(self):
return self.running
# 打印执行信息
def get_progress_info(self):
progress_info = {}
progress_info['work_queue_number'] = self.work_queue.qsize()
progress_info['tasks_number'] = len(self.tasks)
progress_info['save_queue_number'] = self.save_queue.qsize()
progress_info['success'] = self.success
progress_info['failure'] = self.failure
return progress_info
def add_save_task(self, url, html):
self.save_queue.put((url, html))
def get_save_task(self):
save_task = self.save_queue.get(block=False)
return save_task
def wait_all_complete(self):
for item in self.threads:
if item.isAlive():
# join函数的意义,只有当前执行join函数的线程结束,程序才能接着执行下去
item.join()
# WorkThread 继承自threading.Thread
class WorkThread(threading.Thread):
# 这里的thread_pool就是上面的ThreadPool类
def __init__(self, thread_pool):
threading.Thread.__init__(self)
self.thread_pool = thread_pool
#定义线程功能方法,即,当thread_1,...,thread_n,调用start()之后,执行的操作。
def run(self):
print (threading.current_thread().getName())
while True:
try:
# get_task()获取从工作队列里获取当前正在下载的线程,格式为func,url,deep
do, url, deep = self.thread_pool.get_task()
self.thread_pool.increase_running()
# 判断deep,是否获取新的链接
flag_get_new_link = True
if deep >= self.thread_pool.args.deep:
flag_get_new_link = False
# 此处do为工作队列传过来的func,返回值为一个页面内容和这个页面上所有的新链接
html, new_link = do(url, self.thread_pool.args, flag_get_new_link)
if html == '':
self.thread_pool.increase_failure()
else:
self.thread_pool.increase_success()
# html添加到待保存队列
self.thread_pool.add_save_task(url, html)
# 添加新任务,即,将新页面上的不重复的链接加入工作队列。
if new_link:
for url in new_link:
self.thread_pool.add_task(do, url, deep + 1)
self.thread_pool.decrease_running()
# self.thread_pool.task_done()
except Queue.Empty:
if self.thread_pool.get_running() <= 0:
break
except Exception, e:
self.thread_pool.decrease_running()
# print str(e)
break

 浙公网安备 33010602011771号
浙公网安备 33010602011771号