EPF:一种基于进化、协议感知和覆盖率引导的网络协议模糊测试框架
本文系原创,转载请说明出处:from 信安科研人

本文将详细介绍一款基于python编写的,能够将代码插桩与覆盖率运用到对程序进行模糊测试的FUZZER: EPF。
该工具对应的论文发表在CCF-B级会议PST上,将从实验和原理分析两部分介绍此工具。实验部分将介绍epf的安装以及对工控协议IEC104库的fuzz,原理部分将依据论文介绍epf的实现。
实验
工具的安装
从源代码的目录结构中可以发现EPF的覆盖率主要基于AFL++的插桩工具afl-clang-fast,对于AFL++的介绍请参考我这篇关于AFL++的原理介绍的文章。
因此:
1、安装AFL++
安装步骤可参考:https://github.com/AFLplusplus/AFLplusplus/blob/stable/docs/INSTALL.md
这里,我选择的是在本机安装而非使用docker方式,我的操作系统是Ubuntu21.03
首先,安装依赖:
sudo apt-get update
sudo apt-get install -y build-essential python3-dev automake cmake git flex bison libglib2.0-dev libpixman-1-dev python3-setuptools
# try to install llvm 11 and install the distro default if that fails
sudo apt-get install -y lld-11 llvm-11 llvm-11-dev clang-11 || sudo apt-get install -y lld llvm llvm-dev clang
sudo apt-get install -y gcc-$(gcc --version|head -n1|sed 's/.* //'|sed 's/\..*//')-plugin-dev libstdc++-$(gcc --version|head -n1|sed 's/.* //'|sed 's/\..*//')-dev
sudo apt-get install -y ninja-build # for QEMU mode
接着,从github上下载AFLPlusPlus,因为github在部分地区被限制访问,这里推荐使用镜像网址,也就是 https://github.com.cnpmjs.org/,步骤如下:
git clone https://github.com.cnpmjs.org/AFLplusplus/AFLplusplus
cd AFLplusplus
make distrib
sudo make install
这里需要注意一点,如果对二进制文件的模糊测试不感兴趣,就可以将make distrib这一步改为:
make source-only
2、安装epf
首先,安装依赖:
sudo apt-get update && sudo apt get install python3 python3-pip python3-venv
接着,安装epf:
git clone https://github.com.cnpmjs.org/rhelmke/epf.git # clone
cd epf # workdir
python3 -m venv .env # setup venv
source .env/bin/activate # activate venv
pip3 install -r requirements.txt # dependencies
这里可能会出现matplotlib库安装问题,解决办法见我的另一篇文章
安装之后,输入:
python3 -m epf --help
若出现:
$ python3 -m epf --help
`-:-. ,-;"`-:-. ,-;"`-:-. ,-;"`-:-. ,-;"
`=`,'=/ `=`,'=/ `=`,'=/ `=`,'=/
y==/ y==/ y==/ y==/
,=,-<=`. ,=,-<=`. ,=,-<=`. ,=,-<=`.
,-'-' `-=_,-'-' `-=_,-'-' `-=_,-'-' `-=_
- Evolutionary Protocol Fuzzer -
positional arguments:
host target host
port target port
optional arguments:
-h, --help show this help message and exit
Connection options:
-p {tcp,udp,tcp+tls}, --protocol {tcp,udp,tcp+tls}
transport protocol
-st SEND_TIMEOUT, --send_timeout SEND_TIMEOUT
send() timeout
-rt RECV_TIMEOUT, --recv_timeout RECV_TIMEOUT
recv() timeout
Fuzzer options:
--fuzzer {iec104} application layer fuzzer
--debug enable debug.csv
--batch non-interactive, very quiet mode
--dtrace extremely verbose debug tracing
--pcap PCAP pcap population seed
--seed SEED prng seed
--alpha ALPHA simulated annealing cooldown parameter
--beta BETA simulated annealing reheat parameter
--smut SMUT spot mutation probability
--plimit PLIMIT population limit
--budget TIME_BUDGET time budget
--output OUTPUT output dir
--shm_id SHM_ID custom shared memory id overwrite
--dump_shm dump shm after run
Restart options:
--restart module_name [args ...]
Restarter Modules:
afl_fork: '<executable> [<argument> ...]' (Pass command and arguments within quotes, as only one argument)
--restart-sleep RESTART_SLEEP_TIME
Set sleep seconds after a crash before continue (Default 5)
则代表安装成功,当然,这里需要注意的是,每次启动epf都需要输入
source .env/bin/activate
以进入python虚拟环境,从而运行epf。
对IEC104协议库进行fuzz
实验准备
下载IEC104协议库:
git clone https://github.com/mz-automation/lib60870.git
cd lib60870/lib60870-C
下载IEC104协议PCAP数据包:
具体链接:https://github.com/automayt/ICS-pcap/raw/master/IEC 60870/iec104/iec104.pcap
使用AFL++中的编译器插桩
首先,本文测试IEC104协议实现库漏洞的样例是上文提到的IEC104协议库中的cs104_server_no_threads样例,该样例位于:lib60870-C/examples/cs104_server_no_threads/cs104_server_no_threads.c
接着,将编译器改为AFL++中的afl-clang-fast编译器:
echo "CC=~/AFLplusplus/afl-clang-fast" >> make/target_system.mk
这里需要注意的是,在lib60870库中,编译器已经在其make目录中的target_system.mk中指定,因此,我们只需要将mk中指定编译器代码写为你主机中AFL++中的afl-clang-fast的地址即可,这里的命令仅供参考。
make后得到程序,并将其复制到epf的文件夹下,同时也将iec104.pcap文件移入。

开始fuzz
在命令行依次输入:
cd ~/epf
source .env/bin/activate # activate virtualenv
python -m epf 127.0.0.1 2404 -p tcp --fuzzer iec104 --pcap iec104.pcap --seed 123456 --restart
afl_fork "./cs104_server_no_threads" --smut 0.2 --plimit 1000 --alpha 0.99999333 --beta 1.0 --budget 86400
上文中的命令参数的具体意义可以输入 python3 -m epf --help,在epf的初始界面查看
开始fuzz,效果甚好。

原理
问题提出
核心问题:不同的领域不同场景带来的不同难度的FUZZ
工具框架

框架图如上,EPF主要分为两个阶段,预处理和动态分析,预处理阶段针对待测协议处理。依据框架图依次介绍:
III-A:目标程序插桩
EPF中的插桩功能主要是调用AFL++的编译插件对程序进行编译,具体覆盖率矩阵计算详见AFL++或者AFL baseline 的实现细节,在我的另一篇AFL++的原理文章也有讲解。
论文中说到,EPF选择AFL++中的编译链作为程序插桩的实现的好处主要是能够继承AFL++的功能以及后续的拓展功能。
III-B:数据包建模
数据包建模是指FUZZER构建网络协议的输入的模型构建。
网络协议的模糊测试领域中的一个挑战是B/S两端可能会拒绝不符合该协议规则的数据包,这就意味着如果想要有效的对协议进行模糊测试,应是以符合协议规则布局的数据包为主要的FUZZ输入,从而能够改变产生协议的程序的状态,进而对整个协议的实现进行漏洞挖掘。

EPF通过python中的Scapy库实现数据包建模,主要原因是scapy支持的协议实在是太多^ _ ^,并且一直在更新扩展协议类型。
III-C:状态转换建模
网络协议的fuzz中,因为协议的通信是双向的,所以不仅仅需要产生与协议结构相似的数据,还需要考虑到协议状态的转换,从而能发掘协议的状态逻辑等更深层次的漏洞。EPF做出来一个API,主要使用无向有环图对协议状态图构建。
每一条路径包含一个特殊的FUZZ节点以调用特定的数据包类型(可以参考下图IEC104协议的状态图),然后,对于每一个测试用例,EPF都会开一个连接,并遍历协议状态图且发送所有预先设定好的payload到PUT模块(该模块相当于一个执行者),直到这个测试用例到达相对应的节点。在这个测试用例到达相应节点前,EPF还会继续发送下一个测试用例并遍历一直到下一个测试用例达到其对应的节点,终止信号是路径结束。
III-C部分的建模所得出的是协议的状态转换图,例如IEC608705-104协议的状态图如下,简要概括一下就是,发送两个U型payload才能让I型和S型对应的节点接收FUZZ的输入。

III-D 遗传种群构造器
这个遗传种群构造器是整个预处理流程的最后一步,整合前两个步骤所得到的包布局定义和FUZZ状态转移图,制造种子数据包语料库,这个语料库由追踪目标协议网络流产生。
种群是指同一时间生活在一定自然区域内,同种生物的所有个体,因此这里的种群就是指例如I型、U型、S型包含其对应其类型的数据包,以分别成组的群体。
具体的内容介绍如下图,依旧是以IEC104为例:

当用户将一种协议的PCAP数据包输入到这个组件中,对于每个数据包,这个组件都会启发式(基于经验)的区于Scapy库中的数据模型匹配,例如,我输入一个IEC104的数据包,如果我识别了其特征,与Scapy中的IEC104数据包模型相匹配,那么全局FUZZ模型就被认定为是IEC104,并进行实例化也就是按照这个模型产生数据包。
然后图中说到的协议过滤器,其过滤规则需要人工定义,例如定义IEC104的数据包类型,即S-,I-,U-APDU格式,这些规则在文章里被叫做白名单,然后这个过滤器就会把那些重复和不符合规则的的数据包。
接着,过滤出来的数据包将会按照类型(S,I,U)进行分类,分出来的组被称为种群,所谓的遗传就是在种群中变异出该类型数据包。正如图中所示,大圆圈(蓝色)是种群,小圆圈(例如绿色圆圈)是个体,chromosomes指的是具备相同的头部。
III-E 执行引擎

执行引擎是个与主循环交互的并发模块,分为两个部分,也就是如上图所示的覆盖率API和PUT模块,意如其名,API是获取程序覆盖率的接口,PUT可以从图中看出来是执行引擎中的核心,也就是执行者。
覆盖率API通过创建一个64KiB的共享内存,与基于AFL的插桩程序相对接。在运行时,PUT 将此内存映射到虚拟地址空间并插入覆盖数据。在运行时,PUT 将此内存映射到虚拟地址空间并插入覆盖数据。API 在发送每个测试用例的前后,对内存映射进行快照并转义覆盖率信息。 EPF中的覆盖率是映射中非零字节的总数。 这些字节的所代表的释义取决于用户选择的指标和插桩。 例如, 纯版AFL利用定向(directed)分支覆盖,而 N-Gram(一款fuzzer) 扩展引入了更敏感的路径覆盖。
执行器监控 PUT 的执行状态。 它通过 execve 方法 fork 出一个子进程。 执行器在每次模糊测试迭代中轮询子进程的状态。 当 PUT 进入故障状态时,将会获取返回码并记录崩溃。 故障状态是指意外的僵尸进程、失效和停止状态。 EPF将其fork到一个新的实例来恢复模糊测试。
基于 execve 的方法有缺点。 首先,如果目标在每次迭代中重新启动,每次fork都会带来初始化开销,从而减慢模糊测试的速度。 但是,EPF假设网络服务器应用程序通过继续执行来发出有效信号。 因此,EPF 仅在 PUT 崩溃时才会fork。
III-F 主循环

分块介绍,首先介绍各个操作对应的意义

Continue
就是说,t^budget 是EPF的计算预算,简洁的说就是,预期设定一次模糊测试迭代的秒数。那么这里的continue是指如果一轮模糊测试将这个时间用完,那么动态分析这部分就终止。在这个工具里对应的参数是:

Schedule:
这部分对应下图中的Schedule Population,population在上文已说过是不同类型数据包的种群。 设C 是种子语料库中的种群集合,按它们在种子文件中的出现顺序排列。 EPF 在 C 中分配 t^budget,从而提高覆盖率。 如果 C 种群发现新代码的潜力耗尽,EPF会调整并尝试另一个种群。 然而,EPF 面临着一个multi-armed bandit问题 ,可以使用模糊测试配置调度 (FCS) 算法 来解决这个问题。
设C 是种子语料库中的种群集合,按它们在种子文件中的出现顺序排列。 EPF 在 C 中分配 t^budget,从而提高覆盖率。 如果 C 种群发现新代码的潜力耗尽,EPF会调整并尝试另一个种群。 然而,EPF 面临着一个multi-armed bandit问题 ,可以使用模糊测试配置调度 (FCS) 算法 来解决这个问题。
EPF 使用模拟退火算法对 C 上的预算分布进行动态建模。模拟退火算法(Simulate Anneal Arithmetic,SAA)是一种通用概率演算法,用来在一个大的搜寻空间内找寻命题的最优解。它是基于Monte-Carlo迭代求解策略的一种随机寻优算法。 模拟退火算法是S.Kirkpatrick, C.D.Gelatt和M.P.Vecchi等人在1983年发明的,1985年,V.Černý也独立发明了此演算法。模拟退火算法是解决商旅问题(TSP)的有效方法之一。
TSP问题(Traveling Salesman Problem,旅行商问题),由威廉哈密顿爵士和英国数学家克克曼T.P.Kirkman于19世纪初提出。问题描述如下: 有若干个城市,任何两个城市之间的距离都是确定的,现要求一旅行商从某城市出发必须经过每一个城市且只在一个城市逗留一次,最后回到出发的城市,问如何事先确定一条最短的线路已保证其旅行的费用最少?
而对于模拟退火算法,这里引用数据魔术师的帖子中的一段话:
模拟退火算法以一定的概率来接受一个比当前解要差的解,因此有可能会跳出这个局部的最优解,达到全局的最优解。模拟退火算法在搜索到局部最优解B后,会以一定的概率接受向右的移动。也许经过几次这样的不是局部最优的移动后会到达BC之间的峰点D,这样一来便跳出了局部最优解B,继续往右移动就有可能获得全局最优解C。这里也有一个有趣的比喻:
普通贪心算法:兔子朝着比现在低的地方跳去。它找到了不远处的最低的山谷。但是这座山谷不一定最低的。
模拟退火:兔子喝醉了。它随机地跳了很长时间。这期间,它可能走向低处,也可能踏入平地。但是,它渐渐清醒了并朝最低的方向跳去。
设∈c (i) ∈ [0, 1] 为循环第 i次迭代中种群 c 的能量或潜力。 EPF将潜能的发展过程,建模为一系列与覆盖率相关的指数增长和衰减:
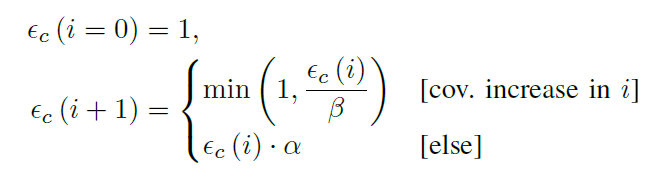
这里,α为损失值,范围为[0,1[,β为增长因子,范围为]0,1]。
- 一开始,EPF 选择第一个配置 c0 并设置∈c0 (0) = 1。FCS 返回并且对 c0 进行模糊测试。
- 对于下一次迭代 i + 1,FCS 继续选择 c0 进行模糊测试,并根据前一次迭代的结果重新计算∈c0 (i + 1):如果前一次迭代增加了覆盖率,则 c0 获得潜力,即: ∈c0 ( i + 1) ≥ ∈c0 (i)。 否则 c0 失去潜力,即:∈c0 (i + 1) < ∈c0 (i)。
- 一旦 ∈c0 (i) 达到阈值 ∈thresh范围为]0, 1[,潜力就会耗尽。 EPF 然后选择下一个集合c1(上文已经说到c是一个种群集合),设置∈c1 (i) = 1 并继续该过程。
- 当算法循环遍历所有 c ∈ C 时,调度程序重新启动,直到 t^budget 耗尽。

上图的不同颜色代表不同种群,随着时间的推移,覆盖率的不变,预示这个种群的潜力下降,当覆盖率升高,则这个种群的潜力上升。
Generate Input
在调度流程后,输入生成器选择父母用例并使用测试用例重组和测试用例变异创建子用例。
种群中的个体被组织在一个按其适应度排序的链表中。输入生成器使用两个概率函数随机选择两个父母节点:假设父用例 A 来自指数分布函数的选择,母用例 B 来自均匀分布函数的选择。
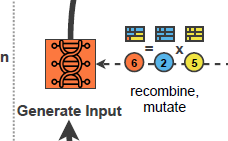
与 AFL的拼接算法类似,父母用例通过单点交叉进行复制:它们的数据包结构在左右部分随机切片。然后,A 的一部分与 B 的对应部分合并(见上图右部分)。哪个父母级别贡献哪个部分是随机选择的。这个想法是结合结构上有效的数据包的特征,这些特征在连接在一起时可能会或可能不会变得无效。
单独的重组不会产生遗传多样性。因此,EPF使用随机点突变。每次用例片段交叉后,EPF 随机选择具有用户定义概率 p^mut 的子数据包字段(如下图),并使用类型感知随机字节生成器改变其值。

Evaluate Input
从上一步的生成器中拿去生成的子用例作为输入:
- 如果输入到PUT的用例引起了PUT的crash,那么,这个用例就会被接上exit码,也就是被标为可能引起bug的用例。
- 如果覆盖率图的快照发生了变化,那么,这个用例就会被接上coverage increase的标签。
Update Population
该模块依据上一步生成的用例评估结果来更新种群集合。

如上图,从左往右看,右边为链表的末端,左边为链表的头端。如果没有覆盖率没有增加,则这个测试用例被认为是坏用例,并以p^add=∈c(i) (也就是上文Schedule部分说到的潜力值)的概率,添加到种群集合中。因此,每一轮迭代的种群潜力值决定了弱个体在基因库中生存的机会,这就是EPF标题中所谓的Evolution。
如果C用例增加了覆盖率,那么,它个人会被添加到链表首部,然后它的父母节点会被向前移动一位。如果没有就如上文所述按照概率插入到链表中,父母节点往后移动一位。这也意味着,当一个父母用例被指数分布选中时,选择最近增加覆盖率的个体的概率很高。
需要注意的是,当链表达到P^limit后,将会删除链表最后一个用例。这就是自然法则。
框架流程总结
介绍完EPF的所有小部分的实现,我再总结一下整个测试框架的流程,依旧是那幅图,即框架总图:

这幅图要从左往右看,分为两个部分即对应两个FUZZ阶段看。
预处理阶段:
- 对被测程序插桩
- 对用户输入的pcap数据包进行结构提取并与Scapy中的库匹配,确定好协议类型后,按照scapy中定义的协议数据布局,准备生成协议数据。
- 状态转移图生成
- 按照人工定义的规则对用户输入的pcap包中的种子用例进行种群划分
动态分析阶段:
总体上使用基于种群的模拟退火实现资源分布和覆盖最大化。
- 对划分好的种群进行调度,每个种群生成一个链表,使用模拟退火算法对每个种群中的个体分配t^budget以限制计算资源。
- 对每个种群划分潜力值,每一次迭代,种群潜力值将按照设定好的潜力值公式变化
- 按照两种分布函数选取同一种群中两个链表节点用例作为父母用例,拼接或者变异用例。
- 将生成的用例输入到执行引擎中执行
- 将覆盖率的变化情况分类并标签到测试用例的末尾
- 按照上一步的标签对种群进行用例的更新,一般是链表顺序更新
- 循环直到t^budget值用尽,也就是用户设定的fuzz时间


