
kaldi实例脚本运行
Getting started, and prerequisites.
rm/s5/run.sh
Data preparation
如果有GridEngine,
train_cmd="queue.pl -q all.q@a*.clsp.jhu.edu" decode_cmd="queue.pl -q all.q@[ah]*.clsp.jhu.edu"
如果需要在本地运行
train_cmd="run.pl" decode_cmd="run.pl"
创建训练集和测试集
local/rm_data_prep.sh /export/corpora5/LDC/LDC93S3A/rm_comp
生成如下:
- local : Contains the dictionary for the current data. 包含当前数据的发音词典
- train : The data segmented from the corpora for training purposes. 训练数据的seg标注信息
- test_* : The data segmented from the corpora for testing purposes. 测试数据的seg标注信息
cd local/dict head lexicon.txt head nonsilence_phones.txt head silence_phones.txt
/train和/test结构相同
head text head spk2gender.map head spk2utt head utt2spk head wav.scp
wc train/text test_feb89/text 比较训练集和测试集的词数,文件大小
下一步创建原始的语言文件
utils/prepare_lang.sh data/local/dict '!SIL' data/local/lang data/lang
这将会产生一个lang的文件夹,里面包含一个FST描述语言文件,输出文件夹(data/lang).
words.txt and phones.txt(data/lang/)被会用到,它们是openfst格式的符号表,代表从一个字符串到整数
的映射,
suffix .csl (in data/lang/phones) non-silence, and silence, phones 整数id键值对列表
phones.txt (in data/lang/) 音素符号表,处理FST的歧义符号,这些符号会被替换成 #1, #2
L.fst是编译后的lexicon FST格式。
用下面的命令可以查看L.fst的内容
fstprint --isymbols=data/lang/phones.txt --osymbols=data/lang/words.txt data/lang/L.fst | head
如果没有找到fstpirnt命令,则需要将OPenFst添加到PATH环境,或者简单点执行../path.sh
下一步使用上一步创建的文件,创建一个FST描述语法
local/rm_prepare_grammar.sh,将会产生/data/lang/G.fst.
Feature extraction
Monophone training
输出文件夹:
exp/mono
nohup steps/train_mono.sh --nj 4 --cmd "$train_cmd" data/train.1k data/lang exp/mono &
tail nohup.out
data/lang/topo 立即创建,1个音素的内部状态转移topo
data/phones.txt 音素 音素id
查看生成的模型文件0.mdl
gmm-copy --binary=false exp/mono/0.mdl - | less
mdl file 包含两个对象,1个对象TransitionModel,它包含HMM拓扑信息;1个对象包含模型类型
查看tree文件
copy-tree --binary=false exp/mono/tree - | less
单音素的tree,它没有任何的splits。
exp/mono/ali.1.gz
copy-int-vector "ark:gunzip -c exp/mono/ali.1.gz|" ark,t:- | head -n 2
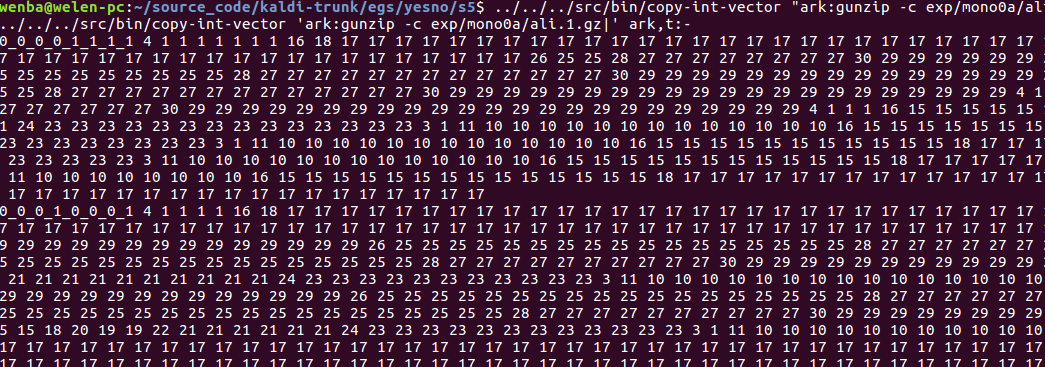
这是训练数据的维特比对其,对于每个训练文件都有1行。对齐文件里面有许多数字,都是特别大,它里面并不包含pdf的id,而是transition-id,它以音素的
topo原型,编码音素和transition,这是非常有用的,如果想查看transitions信息,则如下命令:
show-transitions data/lang/phones.txt exp/mono/0.mdl

为了更清晰的查看对齐,可以用下面的命令
show-alignments data/lang/phones.txt exp/mono/0.mdl "ark:gunzip -c exp/mono/ali.1.gz |" | less
查看训练过程;匹配log文件overall关键字行
grep Overall exp/mono/log/acc.{?,??}.{?,??}.log
当单音素训练完毕,可以进行解码测试,如下命令
utils/mkgraph.sh --mono data/lang exp/mono exp/mono/graph
which fstdeterminizestar
在图创建完后,开始解码
steps/decode.sh --config conf/decode.config --nj 20 --cmd "$decode_cmd" \ exp/mono/graph data/test exp/mono/decode
less exp/mono/decode/log/decode.2.log
从2.tra文件里查看真实的解码词序列,命令:
words.txt包含了词与int的关系
utils/int2sym.pl -f 2- data/lang/words.txt exp/mono/decode/scoring/2.tra
查看真实的解码词序列,然后再转换回整型:
utils/int2sym.pl -f 2- data/lang/words.txt exp/mono/decode/scoring/2.tra | \
utils/sym2int.pl -f 2- data/lang/words.txt 将符号转换成整数
tail exp/mono/decode/log/decode.2.log 查看decode.2.log结尾一些总结性信息
gmm-decode-faster
Decode features using GMM-based model.

