一个新型的混音算法
针对传统经典的线性混音,路数多时音量变小的缺点;自创了一个新的混音算法,解决该问题,声音不会忽大忽小,而且该方法还能一定程度抑制噪声,突出人声,能实时计算量小,专利已经受理。
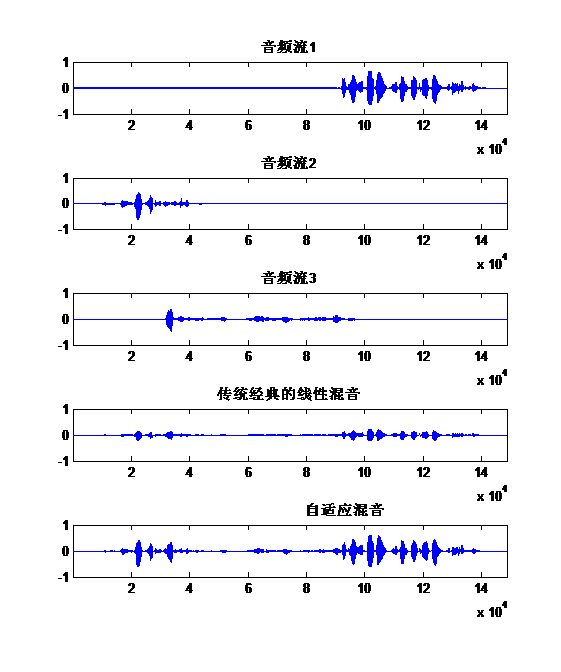
对于混音方法,网上和文献上流传许多方法。
1.平均权重
2.随幅值变化的权重
3.利用衰减因子缓慢规整
4.绝对值处理
5.A+B-A*B(书写不是很精确)
经过实验,方法做了比较了:
方法1.唯一的缺陷就是正反时抵消的情况
方法2.计算量大,忽重忽轻
方法3.小值的时候 比 线性的 声强要大,但是对于比较洪亮的歌曲,出现波形失真,会破音,也无法避免方法1的问题
放大4.能保证语义信息,但是丢失了相位信息,声音失真。
方法5.网上流传的经典算法 A+B-A*B,能克服1的问题,但是声音有些失真,其它情况,与方法1相当。
方法5的理解:
其实就是线性分量A+B与非线性分量A*B的一个叠加
(A+B)/A*B=1/A+1/B。 (-1<A<1,-1<B<1)
对于0<A<1,0<B<1时,平均算下,A与B都作0.5,A+B>4*A*B,也就是说A+B的分量远远大于A*B。为了进一步达到该目的,可以进一步做优化处理,目的就是使得
A和B都尽可能小,最后混音完后,再放大。
同样的,其他情况也是如此。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号