场景之多数据源查询及数据下载问题
前言:本文将介绍常用后台功能中的数据获取以及下载的一些注意事项和实现。
承接上文数据分页查询
当通过分页查询到数据之后,接着还会遇到其他需求:
- 继续其他数据源查询:分页查询到的数据并非全部需要的数据,这个时候主要字段查出来了,需要去其他表或者其他服务调用再去获取信息。
- 数据获取整合之后进行下载
一、继续查询
1、需求
比如根据数据库查询出来商品的id,商品名等主要信息。但是要去查询商品的购买量以及原始售价,这些与商品基本信息不太相关的数据信息,通常考虑到业务数据量,系统中已经进行了分库或者分表,甚至一些成交数据是维护在数仓等其他业务服务中。
商品id | 商品名 | 商品主图 | 商品售价 | 商品购买量 | 商品售价 | .....
这个时候如果顺序的再去执行第三方服务和去查其他库,显然会导致请求的时延很大。既然商品基本信息已经批量查询出来了,并且购买量和原始售价分数不同的数据存储,就可以开线程或者协程去一块查询其他数据,最后合并汇总。或者本身第一次查询的数据量,这个时候可以分批量的去查第三方服务数据。
因此分为几种情况
- (1)同一批数据再去分别查询不同的数据源
- (2)去查询相同的数据源,但是原始数据太大,需要分批查询
- (3)对于从不同数据源二次查询到的数据,需要作进一步规则计算
下面来看下对于不同的情况的做法以及go语言实现和一些注意事项。
2、实现
2.1 封装waitgroup和业务对象
首先为了通用性,对sync.WaitGroup做一下简单封装,方便协程使用。
type waitGroup struct {
wg *sync.WaitGroup
}
func WaitGroup() *waitGroup {
return &waitGroup{&sync.WaitGroup{}}
}
func (wg *waitGroup) NewGoroutineStart(f func()) {
wg.wg.Add(1)
go func() {
defer func() {
if err := recover(); err != nil {
// 为了保证系统安全通常要做异常捕获,保证goroutine是有recover
fmt.Println("日志打印Goroutine处理失败")
}
wg.wg.Done()
}()
f()
}()
}
func (wg *waitGroup) Wait() {
wg.wg.Wait()
}
这里通常会对协程调用中可能出现的panic,进行异常捕获recover,为了保证系统的安全运行。
type Product struct {
ID int
Name string
}
type ProductRes struct {
ID int
Name string
Order int
Price int
}
同时为了更好的展示效果,定义了一个商品类Product,和一个商品ProductRes结果类用于整合数据。
2.2 第一种情况
用分页查询出来的数据整批再去其他多个数据源分别读取数据,比如用商品的id,去获取商品的成交量order以及商品的售价。
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
// 商品类定义 与 waitgroup定义省略
func main() {
var data []*Product
// 模拟从分页查询出来的商品
for i := 1; i <= 20; i++ {
data = append(data, &Product{
i,
fmt.Sprintf("%d th-Product", i),
})
}
// 用于保存商品id和商品单价以及商品订单关系
productPriceMp := make(map[int]int, 5)
productOrderMp := make(map[int]int, 5)
wg := WaitGroup()
wg.NewGoroutineStart(func() {
//模拟读取数据源1数据
fmt.Println("开始读取数据源1数据")
time.Sleep(time.Duration(rand.Intn(5)) * time.Second)
for i := 0; i < len(data); i++ {
productPriceMp[data[i].ID] = rand.Intn(100)
}
fmt.Println("数据源1数据获取成功")
})
wg.NewGoroutineStart(func() {
//模拟读取数据源2数据
fmt.Println("开始读取数据源2数据")
time.Sleep(time.Duration(rand.Intn(5)) * time.Second)
for i := 0; i < len(data); i++ {
productOrderMp[data[i].ID] = rand.Intn(100)
}
fmt.Println("数据源2数据获取成功")
})
// 阻塞等待
wg.Wait()
fmt.Println("数据同步读取完成,开始合并")
var res []*ProductRes
for _, product := range data {
res = append(res, &ProductRes{
product.ID,
product.Name,
productOrderMp[product.ID],
productPriceMp[product.ID],
})
}
// 展示商品数据
for _, productRes := range res {
fmt.Println(productRes)
}
}
说明:
- 这里首先模拟生成20条分页查询得到的商品记录,存放在data切片中
- 定义两个map分别保存商品与订单,商品与售价之间的关系,每个map设置为10,是一个预估容量,一般为了防止map在实际增加数据的时候容量上成倍扩增,可以根据情况初始化一个比较小的值。
- 然后用封装好得waitgroup开启两个协程去不同的数据源获取数据,这里我们用sleep以及rand来模拟
- 最后将整合好的结果放在res切片中,一般到这里在框架中的servers层,逻辑就处理完了,将res就可作为返回结果
来看下实际的运行结果

可以看到同时从两个数据源获取数据,并且整合成功,打印出来。
2.2 第二种情况
以上是所有分页查询得到的数据去不同数据源二次获取数据,下面这种情况更加常见,对于第一次分页查询的数据很多,要分批再去做其他数据源查询。因此就涉及到多个协程之间去读取统一切片,也就是并发数据读取问题。首先来看个错误demo。
func main() {
var data []*Product
for i := 1; i <= 1000; i++ {
data = append(data, &Product{
i,
fmt.Sprintf("%d th-Product", i),
})
}
wg := WaitGroup()
var newData []*Product
var startInd, endInd = 0, 0
for i := 0; i < len(data); i += 100 {
if i+100 < len(data) {
startInd, endInd = i, i+100
} else {
startInd, endInd = i, len(data)
}
newData = data[startInd:endInd]
wg.NewGoroutineStart(func() {
fmt.Println("开始分批去其他数据源获取")
time.Sleep(time.Duration(rand.Intn(3)) * time.Second)
fmt.Println(newData[0])
})
}
// 阻塞等待
wg.Wait()
}
说明:
- 用data切片模拟第一次查询出来的很多数据记录
- 为了分批传入go程,预先定义了一个newData切片,
- 用封装好得waitgroup开启go程,每100条记录,新开一个go程用time和rand模拟新数据源获取
- fmt.PrintLn(newData[0])来作为日志,打印goroutine处理的数据
来猜一下日志会输出什么
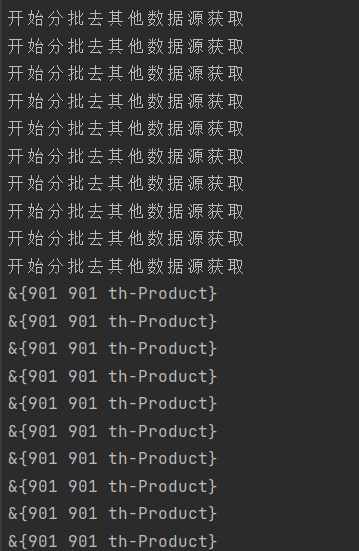
问题:从日志打印可以看出,虽然开启了10个go程,并且按照逻辑应该是每个go分别用的是从1-100,101-200.....分批次的数据,而实际是所有的go程序用的都是同一批数据也就是最后一批从901下标开始的数据。也就是说出现了多个执行单元使用的都是同一批数据。
原因就在于:newData作为一个切片是引用类型,而由于newData但是预先定义在for循环之外的,所有的goroutine用的同一个newData指针,也因此都是同一批数据。
鉴于上述原因,可以在每次循环内部重新定义一个新的newData作为协程的传入,这样就不会有数据冲突的问题发生。作如下修改
wg := WaitGroup()
var startInd, endInd = 0, 0
for i := 0; i < len(data); i += 100 {
if i+100 < len(data) {
startInd, endInd = i, i+100
} else {
startInd, endInd = i, len(data)
}
// 新定义newData作为部分数据切片,传入goroutine
newData := data[startInd:endInd]
wg.NewGoroutineStart(func() {
fmt.Println("开始分批去其他数据源获取")
time.Sleep(time.Duration(rand.Intn(3)) * time.Second)
fmt.Println(newData[0])
})
}
以上是基于已经封装好的waitgroup的使用,因为封装的时候是无参数的,如果使用go func的方式开启,也可传入参数避免以上问题。
接下来再来看一个demo,会有类似的问题。
for i := 0; i <= 9; i++ {
go func() {
time.Sleep(3 * time.Second)
fmt.Println("i =", i)
}()
}
time.Sleep(5 * time.Second)
说明:
- 连续开启10个协程执行不同的任务,fmt.Println模拟日志,打印处理的数据
- 用time.sleep阻塞等待所有的协程执行完毕
来看下结果
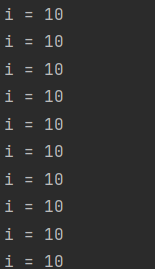
结果打印所有的i值都为10
原因是:同上面的多协程读取统一数据类似的,协程内读取到的是变量的指针,也就是统一值,而最后i的值变为10for循环才会结束,因此所有的协程内部日志打印的也都是10。
2.3 二次查询数据重新计算
2.2中实现了大数据量中不同批次的数据二次查询,如果有一个全局指标,比如商品的总成交量,而每个商品的成交量是开启多个goroutine二次查询的,二次查询之后还要做规则计算。也就是涉及到并发数据写入的问题。
func main() {
var data []*Product
for i := 1; i <= 1000; i++ {
data = append(data, &Product{
i,
fmt.Sprintf("%d th-Product", i),
})
}
wg := WaitGroup()
dataLock := sync.Mutex{}
var totalOrder int
var startInd, endInd = 0, 0
for i := 0; i < len(data); i += 100 {
if i+100 < len(data) {
startInd, endInd = i, i+100
} else {
startInd, endInd = i, len(data)
}
newData := data[startInd:endInd]
wg.NewGoroutineStart(func() {
fmt.Println("开始分批去其他数据源获取")
time.Sleep(time.Second * time.Duration(rand.Intn(3)))
var newDataOrder []int
for _, pro := range newData {
newDataOrder = append(newDataOrder, rand.Intn(10)*(pro.ID+1))
}
dataLock.Lock()
defer dataLock.Unlock()
for _, order := range newDataOrder {
totalOrder += order
}
})
}
// 阻塞等待
wg.Wait()
fmt.Println("总成交量:", totalOrder)
}
说明:
- 用data切片模拟第一次查询出来的很多数据记录,总共1000条
- 为了分批传入go程,为了避免goroutine读取数据问题,每个for循环开启goroutine之前预先定义一个新的newData切片
- 用封装好得waitgroup开启go程,为了保证数据同步的问题,预先互斥锁mutex
- 用time和rand模拟从其他数据源获取订单数据
- rand.Intn(10)*(pro.ID+1)表示用商品id+1乘以一个随机数模拟商品对应的订单量
- 用互斥锁控制并发流程下数据totalOrder的写入,并且使用defer保证了每次goroutine释放锁
执行结果如下

二、数据下载
虽然从底表分页查询,并且多数据源也合并到数据,有时候对于一些后台运营,是希望将这些数据以表格的形式导出。
1、数据导出实现
这里针对excel表格下载,可以使用开源工具
https://github.com/360EntSecGroup-Skylar/excelize
基本的包括
- excel格式定义
- 设置表名
- 设置第一行表头
- 数据写入写入文件
具体的步骤指南,不再做赘述,可以直接github查看。
2、数据下载限制
服务端数据以表格格式返回二进制格式表格数据,如果数据量很大的话,肯定需要做一些限制。
- 根据日期限制最近几个月生成的记录,入参的时候做校验。
- 对于下载数据的记录条数做限制。
但是两种限制条件都不够灵活,根据日期和记录数做限制无法适用于所有的用户,对于服务端我们希望的是对下载频率的限制而不仅仅是对下载数据量的限制。通用的方法可以在后台设置一把锁,这个锁是有失效时间,比如3秒,每发送一次下载请求就添加一把锁,使得规定时间限制之内的请求都无法获取到锁,也因此无法下载。
这个锁可以用redis中的setnx实现,setnx的意思就是指定的 key 不存在时,为 key 设置指定的值。
逻辑可以写成如下
lock := redis.setnx(key, value)
if !lock {
// 上锁失败,流程终止
return
}
// 设置失效时间
redis.expire(key, 3)
// 以下下载流程
download
说明
- 首先用setnx设置一把锁,key在业务中可以用项目名+用户id来实现,比如"project-product-download:user_id",因为对于下载操作来说,肯定是只暴露给已经认证登录的用户,value的设置可以不做限制
- 如果lock==1,说明设置成功,否则设置上锁失败,退出
- 为了控制下载频率,用expire对key设置有效时间为3s,3s之内进来的下载请求都会获取锁失败。
以上逻辑可以完成功能,但是在极端情况下确实可能出现问题,就是setnx获取锁和expire不是原子性操作,假设有一极端情况,一个请求发进来setnx获取到锁,还没来得及执行expire设置锁的过期时间,服务就宕机了,那是不是锁永远不会到失效时间而永远存在?用户也就无法再进行下载,这个问题可以使用set命令解决,我们先来看一下这个命令的语法
SET key value [EX seconds] [PX milliseconds] [NX|XX]
从 Redis 2.6.12 版本开始, SET 命令的行为可以通过一系列参数来修改:
- EX seconds : 将键的过期时间设置为 seconds 秒。 执行 SET key value EX seconds 的效果等同于执行 SETEX key seconds value 。
- PX milliseconds : 将键的过期时间设置为 milliseconds 毫秒。 执行 SET key value PX milliseconds 的效果等同于执行 PSETEX key milliseconds value 。
- NX : 只在键不存在时, 才对键进行设置操作。 执行 SET key value NX 的效果等同于执行 SETNX key value 。
- XX : 只在键已经存在时, 才对键进行设置操作。
那么在逻辑中,用set代替setnx如下
lock := redis.set(key,value,"NX","EX",3)
if !lock {
// 上锁失败,流程终止
return
}
// 以下为下载流程
download
也就是当redis中key不存在的时候,才能设置锁成功,如果设置成功,则设置失效时间为3s。
问题:有的场景下set可以作为分布式锁实现,多用户之间共享资源的问题,那么这里怎么解决锁被误删问题?
答:这里对于下载请求的时候,首先是只对登录过的用户开放,设置锁的时候是根据用户的id进行设置的key,不同的用户设置的也就是不同的key,因此不存在误删的问题。
三、总结
- 首先,在上篇文中通用的管理功能分页查询中,介绍了sql语句的实现和可能的查询优化方案。
- 在本文中,对分页首次查询获取到数据之后,接着进行二次查询的情况进行了介绍,涉及到了对锁的使用和waitgroup的封装,并发读数据和并发写数据的操作和一些注意事项。
- 接着对于数据整合之后的数据下载需求,限制用户操作频率,通过使用redis锁给出了实现。
posted on 2022-07-31 00:16 weilanhanf 阅读(855) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号